- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
脚本开发步骤
步骤一:新建文件夹
1. 进入开发空间,在开发空间目录树中单击
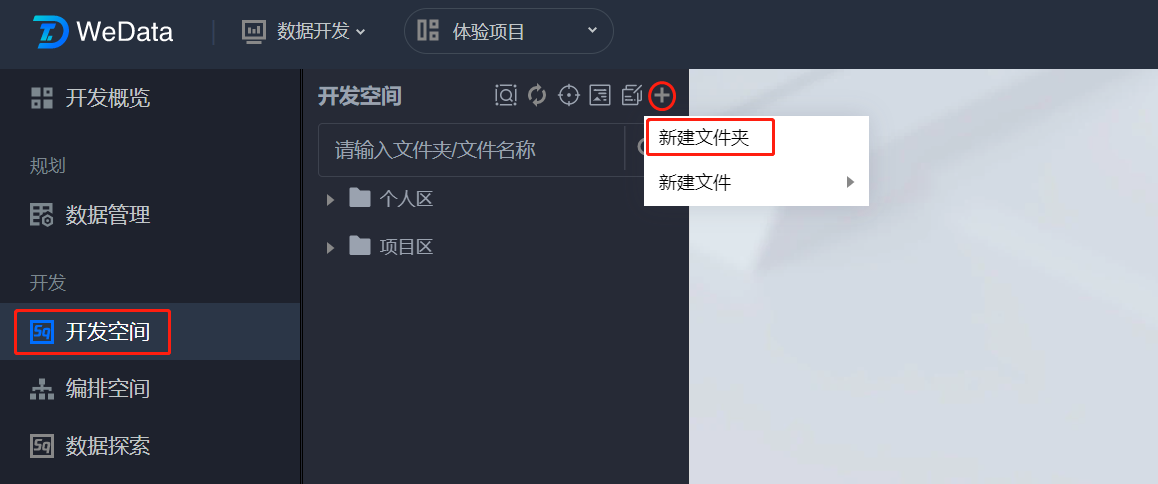
2. 输入文件夹名称并选择目标文件夹,并单击确认。
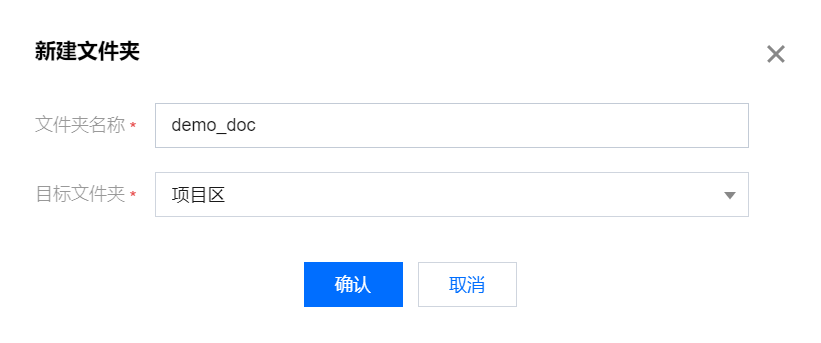
说明:
WeData 支持创建多级文件夹目录,可以保存新创建的文件夹至根目录,或其他已经创建好的文件夹中。
3. 用户可在开发空间下,自由选择将文件夹与文件创建并保存至个人区或项目区。
个人区:在个人区创建或存储的文件夹及文件只能由当前用户查看,其他用户无法查看或编辑管理。
项目区:在项目区创建或存储的文件夹及文件为项目共享文件,可由当前项目下全部用户查看,非项目成员无法查看。
步骤二:新建文件
1. 在临时查询页面右键文件夹名称或者单击目录树上方的 ,并选择要创建的文件类型。
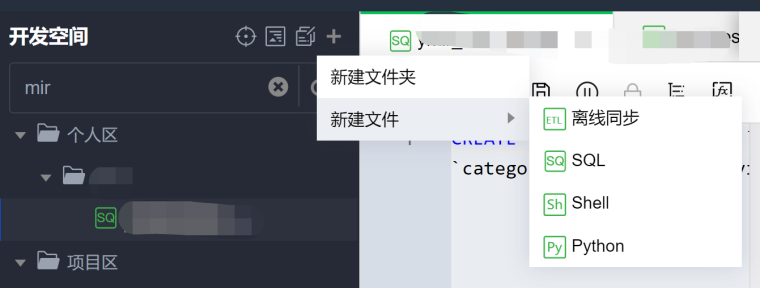
2. 在弹窗中填写脚本文件名称并选择目标文件夹,并单击确认。
说明:
文件命名仅支持大小写字母、数字和下划线,且最长可包括100个字符。
步骤三:编辑文件并运行
1. 在脚本的 Tab 页面中,输入相关的代码语句。如下图以 SQL 为例:
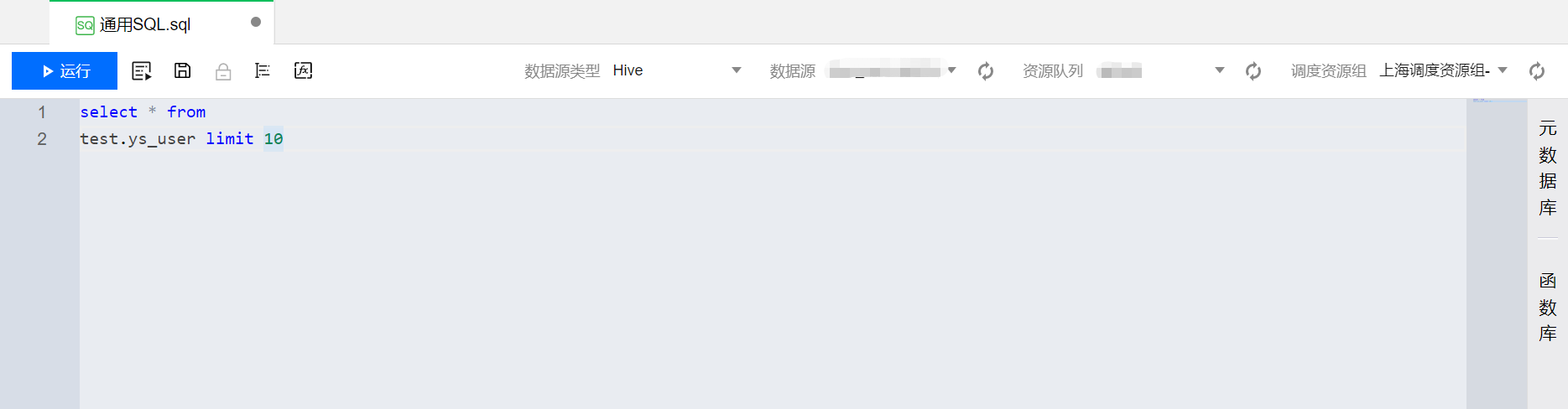
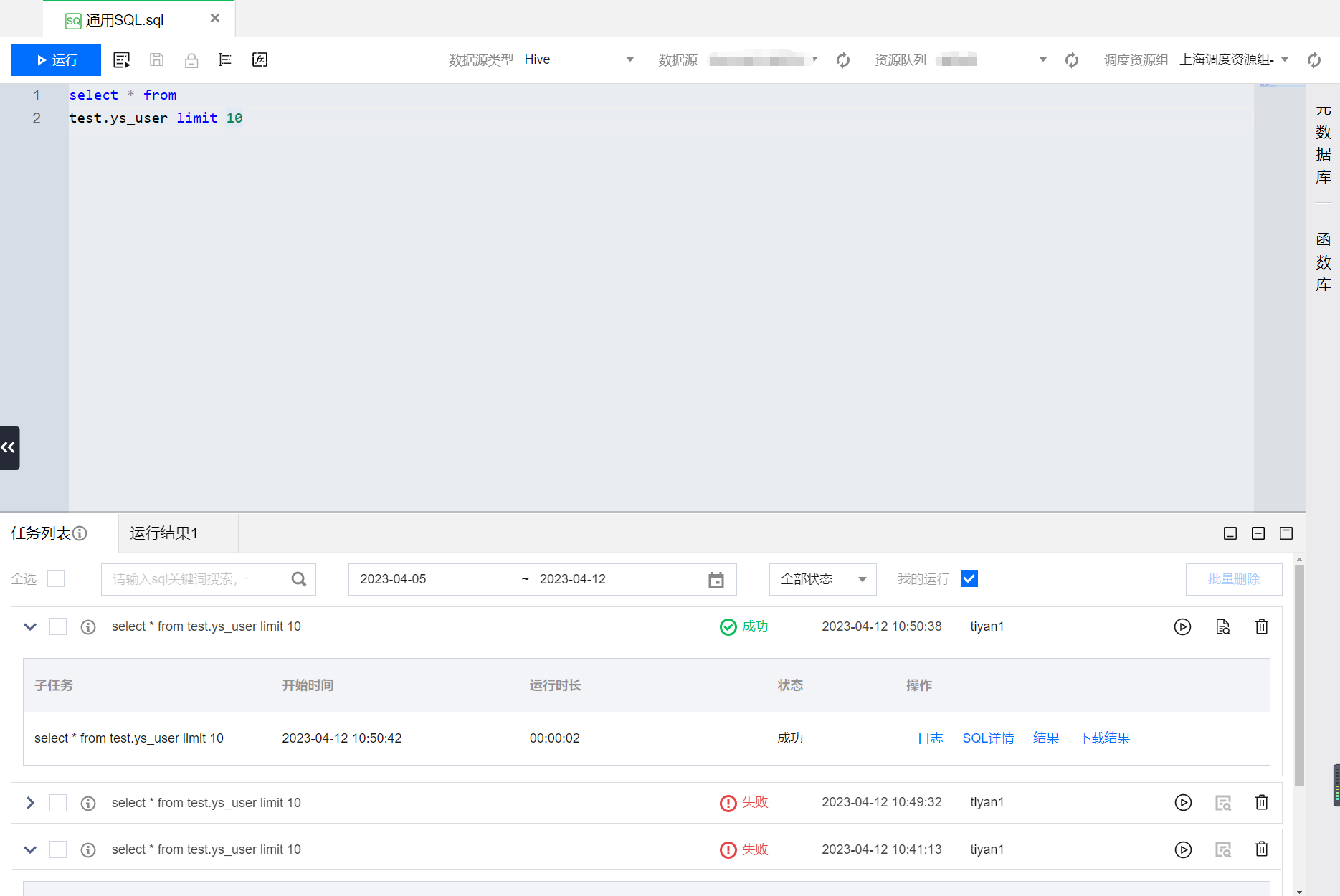
2. 单击运行按钮,运行代码并查看结果。
脚本文件类型
开发空间支持的文件类型为离线同步、SQL、Shell、Python、PySpark,支持新建、编辑、下载、删除等。
同步文件
说明:
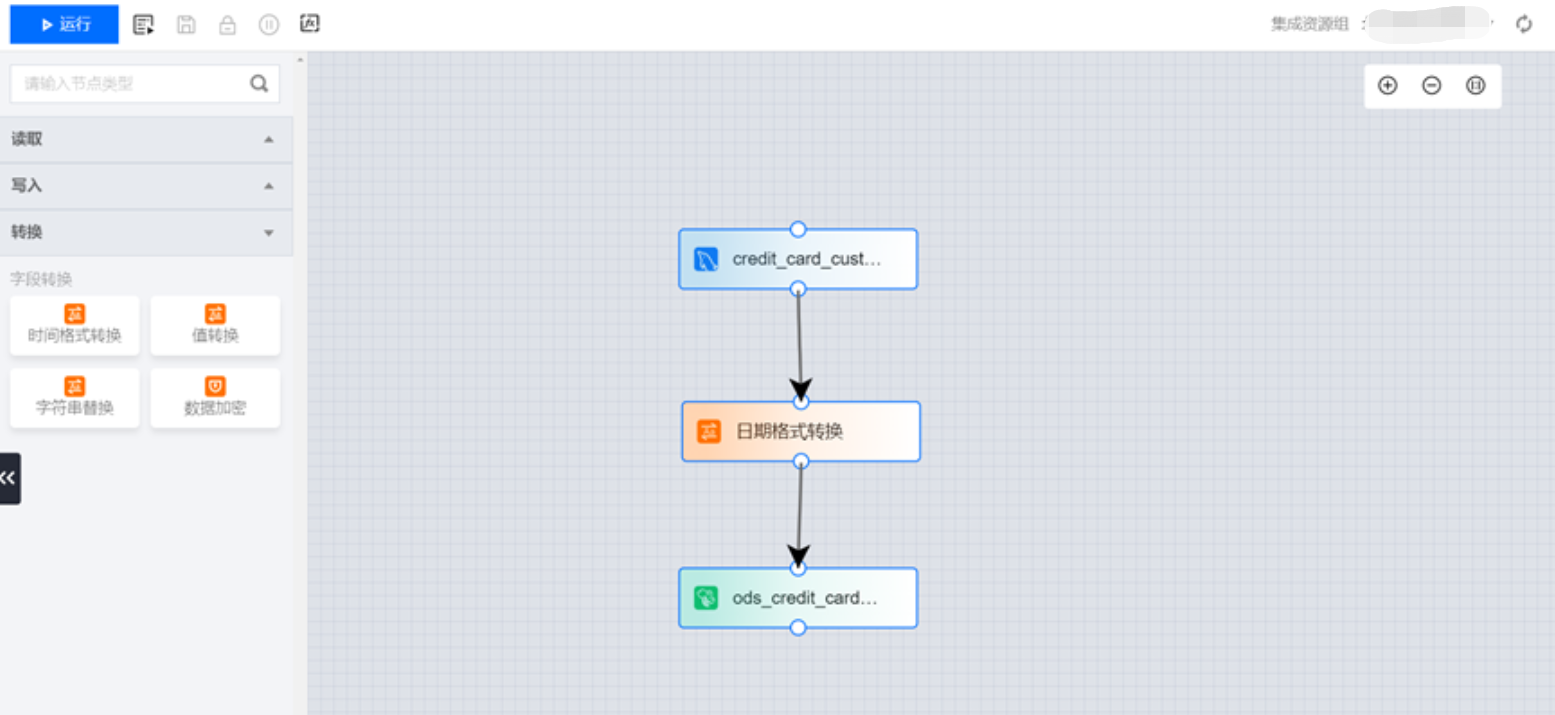
离线同步文件的后缀为“.dg”,支持新建和导入。可支持离线同步流程的配置,包括读取数据源、字段转换、写入数据源配置以及运行、高级运行、保存、格式化和变量查看。
SQL 文件
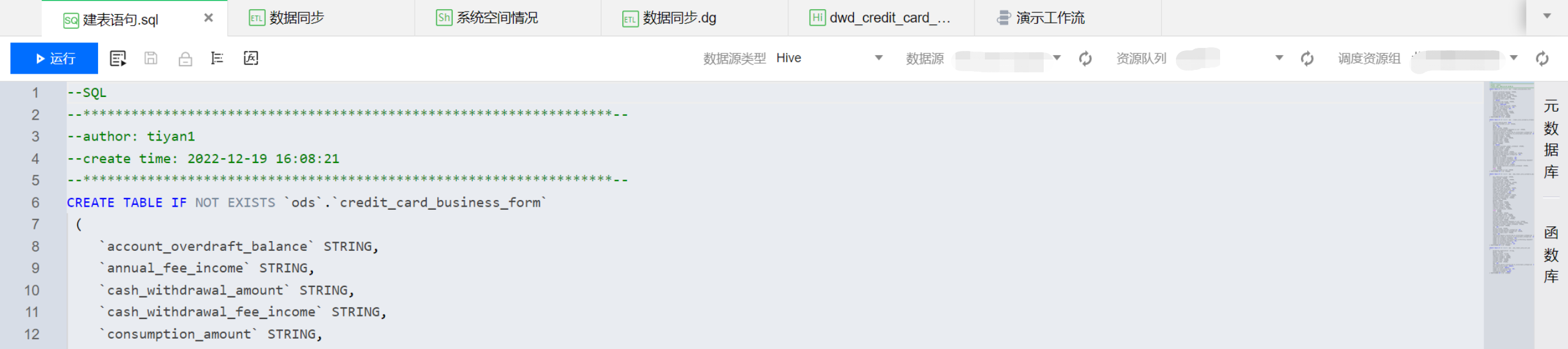
SQL 文件的后缀为“.sql”,支持新建和导入。可支持多种 SQL 的编辑和调试,包括 Hive SQL,Spark SQL,JDBC SQL、DLC SQL 等,支持 Hive、Oracle 和 Mysql 等数十种数据源选择以及运行、高级运行、保存、格式化和项目变量查看。
例如:当数据源类型为 Spark 时,提供“高级设置”,支持 Spark SQL 参数配置。
目前支持 SQL 操作的数据源类型如下:
任务类型 | 支持的数据源类型 | 数据源来源 |
SQL 任务 | Hive | 系统源&自定义源 |
| SparkSQL | 系统源 |
| Impala | 系统源&自定义源 |
| TCHouse-P | 系统源 |
| Graph Database | 自定义源 |
| TCHouse-X | 自定义源 |
| DLC | 系统源&自定义源 |
| Mysql | 自定义源 |
| PostgreSQL | 自定义源 |
| Oracle | 自定义源 |
| SQL Server | 自定义源 |
| Tbase | 自定义源 |
| IBM Db2 | 自定义源 |
| 达梦数据库 DM | 自定义源 |
| Greenplum | 自定义源 |
| SAP HANA | 自定义源 |
| Clickhouse | 自定义源 |
| DorisDB | 自定义源 |
| TDSQL-C | 自定义源 |
| StarRocks | 自定义源 |
| Trino | 系统源&自定义源 |
| Kyuubi | 系统源&自定义源 |
Shell 文件
Shell 文件的后缀为“.sh”,支持新建和导入。用于 Linux Shell 文件的在线开发。支持 Shell 文件运行、高级运行、项目变量查看引用、编辑和保存。
支持界面 Shell 脚本直接执行 hdfs 相关命令。需要在 shell 脚本中手动添加下环境变量:
export HADOOP_CONF_DIR=/usr/local/cluster-shim/v3/conf/emr-xxx/hdfs
emr-xxx 需要替换为用户自己的 emr 引擎 id。
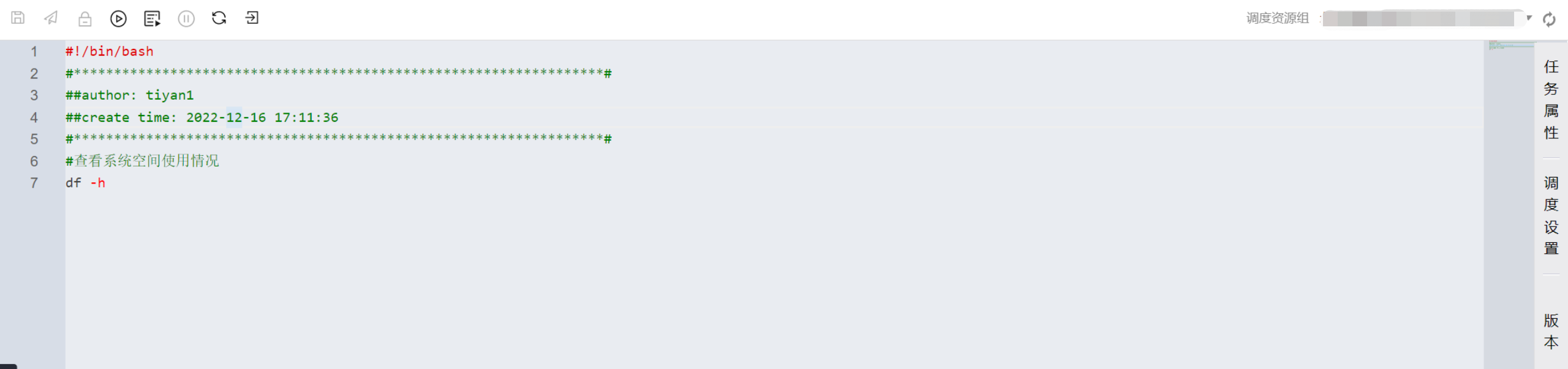
引用资源
Python 文件
Python 文件的后缀为“.py”,支持新建和导入。用于 Python 文件的在线开发。支持 Python 文件运行、高级运行、项目变量查看引用、编辑和保存,版本支持 Python2 和 Python3。

引用资源
PySpark 文件
PySpark 文件的后缀为“.py”,支持新建和导入。用于 Python 文件的在线开发。支持通过 Python 编写 Spark 应用程序。支持运行、高级运行、项目变量查看引用、编辑和保存,版本支持 Python2 和 Python3。
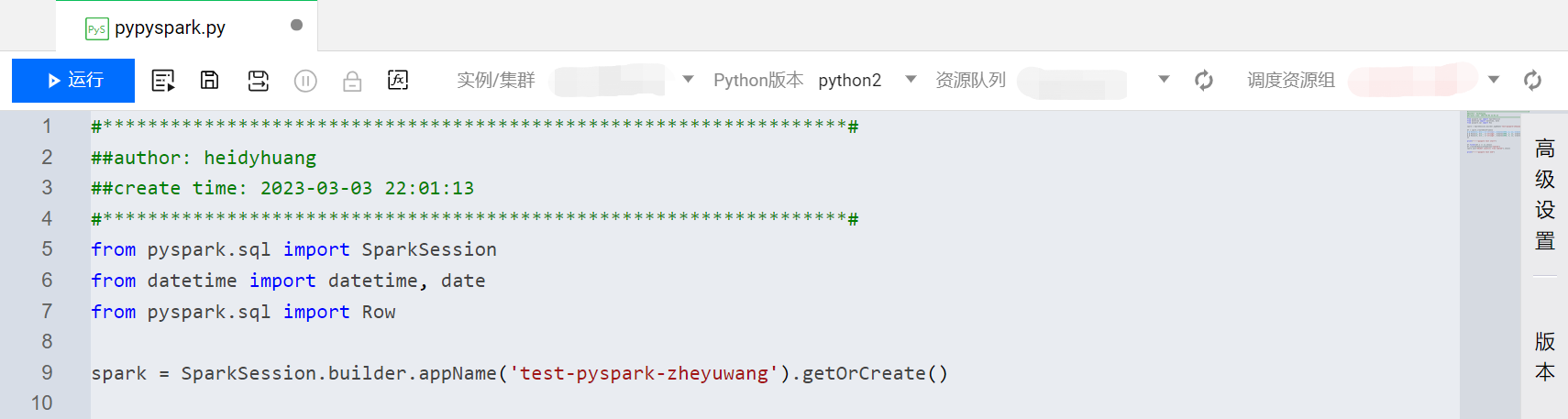
引用资源

 是
是
 否
否
本页内容是否解决了您的问题?