- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Cluster Operation APIs
- ModifyClusterConfigs
- ModifyInstanceKeyValConfigs
- ModifyNodeStatus
- RestartClusterForConfigs
- RestartClusterForNode
- CreateInstanceNew
- DestroyInstance
- ModifySecurityGroups
- ReduceInstance
- ResizeDisk
- ScaleOutInstance
- ScaleUpInstance
- DescribeClusterConfigsHistory
- ModifyInstance
- DescribeCreateTablesDDL
- DescribeInstanceOperationHistory
- Database and Table APIs
- Cluster Information Viewing APIs
- Hot-Cold Data Layering APIs
- Database and Operation Audit APIs
- CancelBackupJob
- CreateBackUpSchedule
- DeleteBackUpData
- DescribeBackUpJob
- DescribeBackUpJobDetail
- DescribeBackUpTables
- DescribeBackUpTaskDetail
- DescribeRestoreTaskDetail
- DescribeBackUpSchedules
- RecoverBackUpJob
- DescribeInstanceOperations
- DescribeDatabaseAuditDownload
- DescribeDatabaseAuditRecords
- DescribeSlowQueryRecords
- DescribeSlowQueryRecordsDownload
- DescribeQueryAnalyse
- User and Permission APIs
- Resource Group Management APIs
- Data Types
- Error Codes
- 云上生态
- 实践教程
- 性能测试
- 常见问题
- 联系我们
- 词汇表
- 产品协议
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Cluster Operation APIs
- ModifyClusterConfigs
- ModifyInstanceKeyValConfigs
- ModifyNodeStatus
- RestartClusterForConfigs
- RestartClusterForNode
- CreateInstanceNew
- DestroyInstance
- ModifySecurityGroups
- ReduceInstance
- ResizeDisk
- ScaleOutInstance
- ScaleUpInstance
- DescribeClusterConfigsHistory
- ModifyInstance
- DescribeCreateTablesDDL
- DescribeInstanceOperationHistory
- Database and Table APIs
- Cluster Information Viewing APIs
- Hot-Cold Data Layering APIs
- Database and Operation Audit APIs
- CancelBackupJob
- CreateBackUpSchedule
- DeleteBackUpData
- DescribeBackUpJob
- DescribeBackUpJobDetail
- DescribeBackUpTables
- DescribeBackUpTaskDetail
- DescribeRestoreTaskDetail
- DescribeBackUpSchedules
- RecoverBackUpJob
- DescribeInstanceOperations
- DescribeDatabaseAuditDownload
- DescribeDatabaseAuditRecords
- DescribeSlowQueryRecords
- DescribeSlowQueryRecordsDownload
- DescribeQueryAnalyse
- User and Permission APIs
- Resource Group Management APIs
- Data Types
- Error Codes
- 云上生态
- 实践教程
- 性能测试
- 常见问题
- 联系我们
- 词汇表
- 产品协议
数据分片
Doris 表按两层结构进行数据划分,分别是分区和分桶。示意如下:
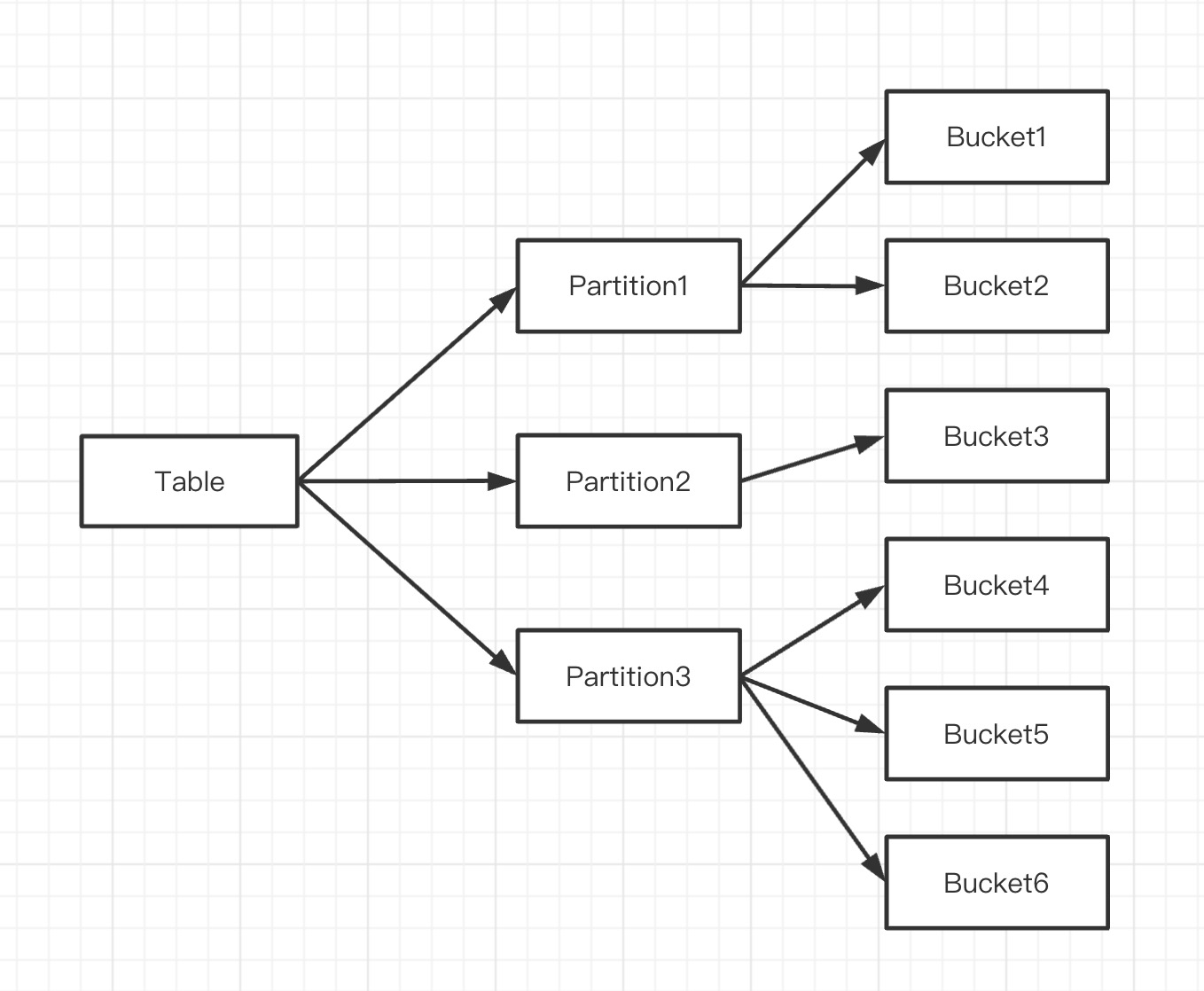
每个分桶文件就是一个数据分片(Tablet),Tablet是数据划分的最小逻辑单元。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
一个 Tablet 只属于一个 Partition,相应的多个 Tablet 在逻辑上归属于不同的分区(Partition)。而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立。Tablet 是数据移动、复制等操作的最小物理存储单元。
副本
为了提高保存数据的可靠性和计算时的性能,Doris 对每个表复制多份进行存储。数据的每份复制就叫做一个副本。Doris 按 Tablet 为基本单元对数据进行副本存储,默认一个分片有3个副本。建表时可在 PROPERTIES 中设置副本的数量:
PROPERTIES("replication_num" = "3");
下图示例,有两个表分别导入 Doris,表1导入后按3副本存储,表2导入后按2副本存储。
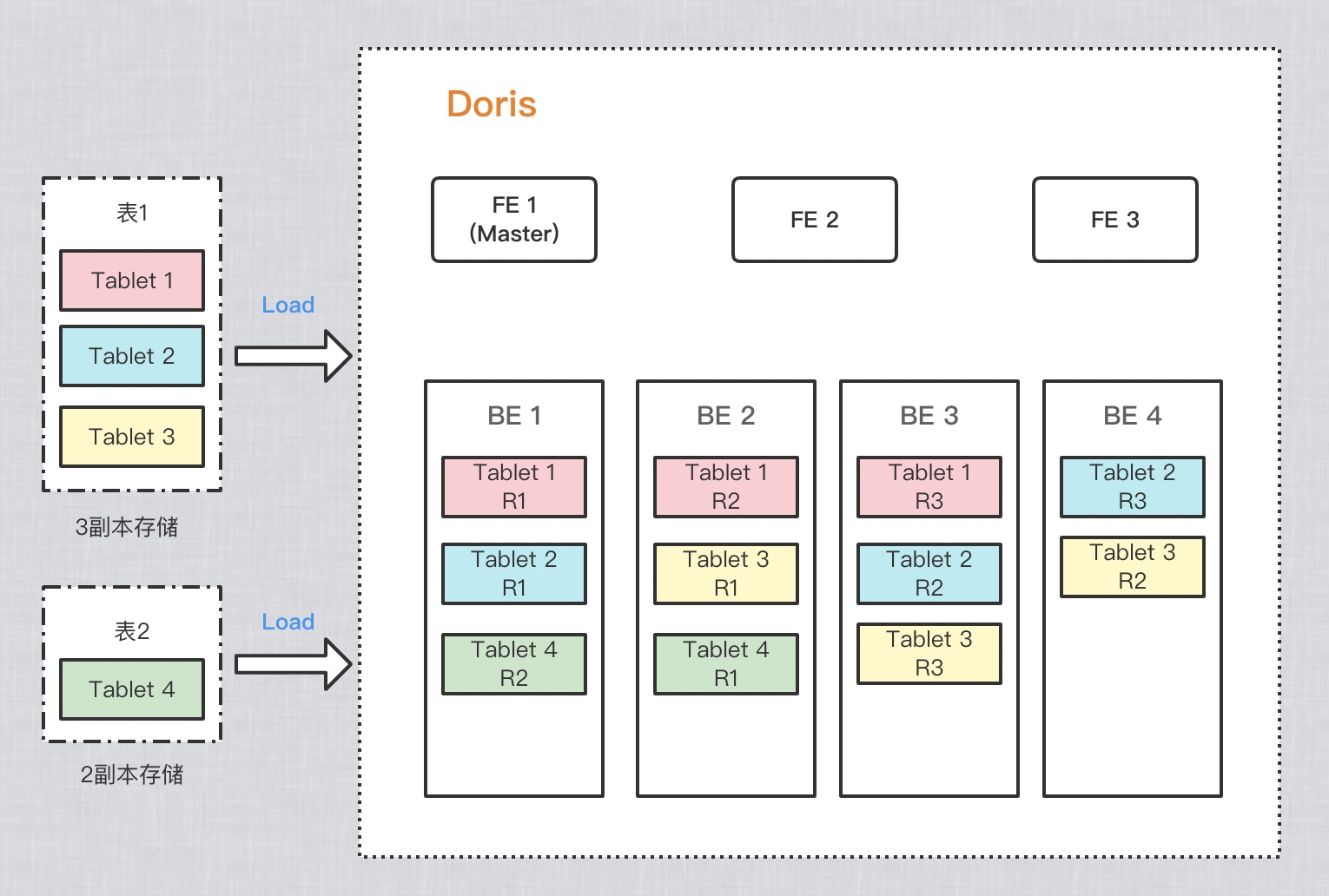
关于副本
每个分片的副本数量默认为3,建议保持默认即可。在建表语句中,所有 Partition 中的 Tablet 副本数量统一指定。而在增加新分区时,可以单独指定新分区中分片的副本数量。
最大副本数量取决于集群中部署BE服务的独立 IP 的数量(注意不是 BE 数量)。Doris 中副本分布的原则是:不允许同一个 Tablet 的副本分布在同一台物理机上,而识别物理机即通过 IP。所以,即使在同一台物理机上部署了 3 个或更多 BE 实例,如果这些 BE 的 IP 相同,则依然只能设置副本数为 1。
副本数量可以在运行时修改。
副本数量强烈建议保持为奇数。
Doris 负载均衡策略
在 FE 的 Master 中 tablet_rebalance_type 配置项中设置,值为 BeLoad、Partition。 如果类型解析失败,默认使用 BeLoad。
BeLoad:根据集群 BE 节点存储负载情况进行负载均衡,从负载高的 BE 节点上迁移 Replica 至负载低的节点。
Partition:均衡每个节点上 Partition 的 Replica 数量,从 Replica 数量高的BE节点上迁移 Replica 至 Replica 数量低的节点,不考虑磁盘使用情况。
横向扩容/缩容都会触发整个 Doris 集群进行负载均衡 Replica 迁移,消耗大量的 CPU 及 IO 资源,负载均衡完成前,对于系统查询/写入性能会有很大影响,需要谨慎评估处理。
最佳实践
查看数据表的数据分布信息
创建表
CREATE TABLE `example_tbl` (`user_id` varchar(128) NOT NULL COMMENT '用户id',`date` date NOT NULL COMMENT '数据灌入日期时间') ENGINE=OLAPDUPLICATE KEY(`user_id`)COMMENT 'OLAP'PARTITION BY RANGE(`date`)(PARTITION p_202306 VALUES [('2023-06-01'), ('2023-07-01')),PARTITION p_202307 VALUES [('2023-07-01'), ('2023-08-01')))DISTRIBUTED BY HASH(`user_id`) BUCKETS 2PROPERTIES ("replication_allocation" = "tag.location.default: 3","in_memory" = "false","storage_format" = "V2","disable_auto_compaction" = "false");
创建一个测试表,3个副本,2个分区,每个分区2个分桶。
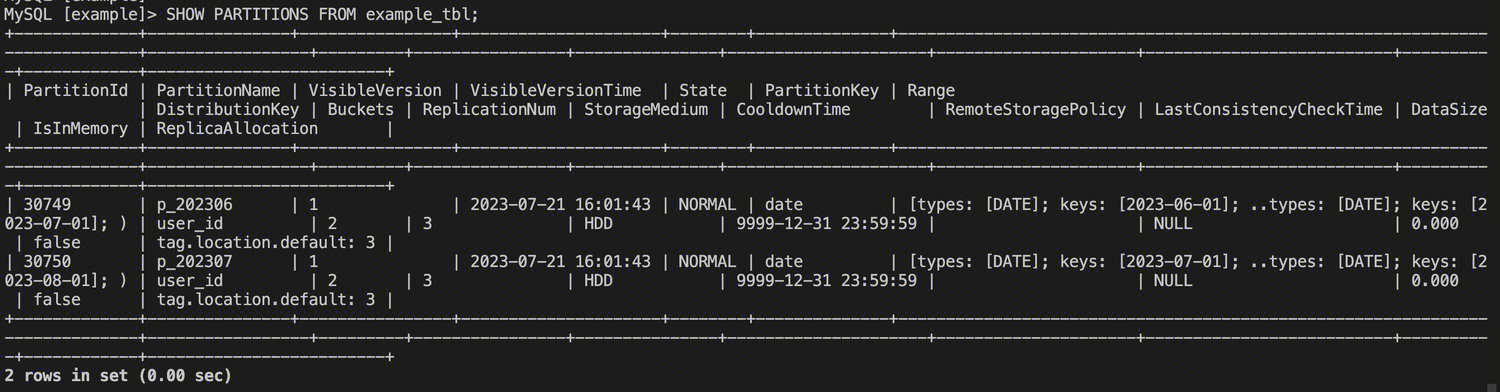
查看表的所有 Partition 信息
SHOW PARTITIONS FROM example_tbl;
可以看到表中两个 Partition 的具体信息。
查看表的所有 Tablet 信息
SHOW TABLETS FROM example_tbl;
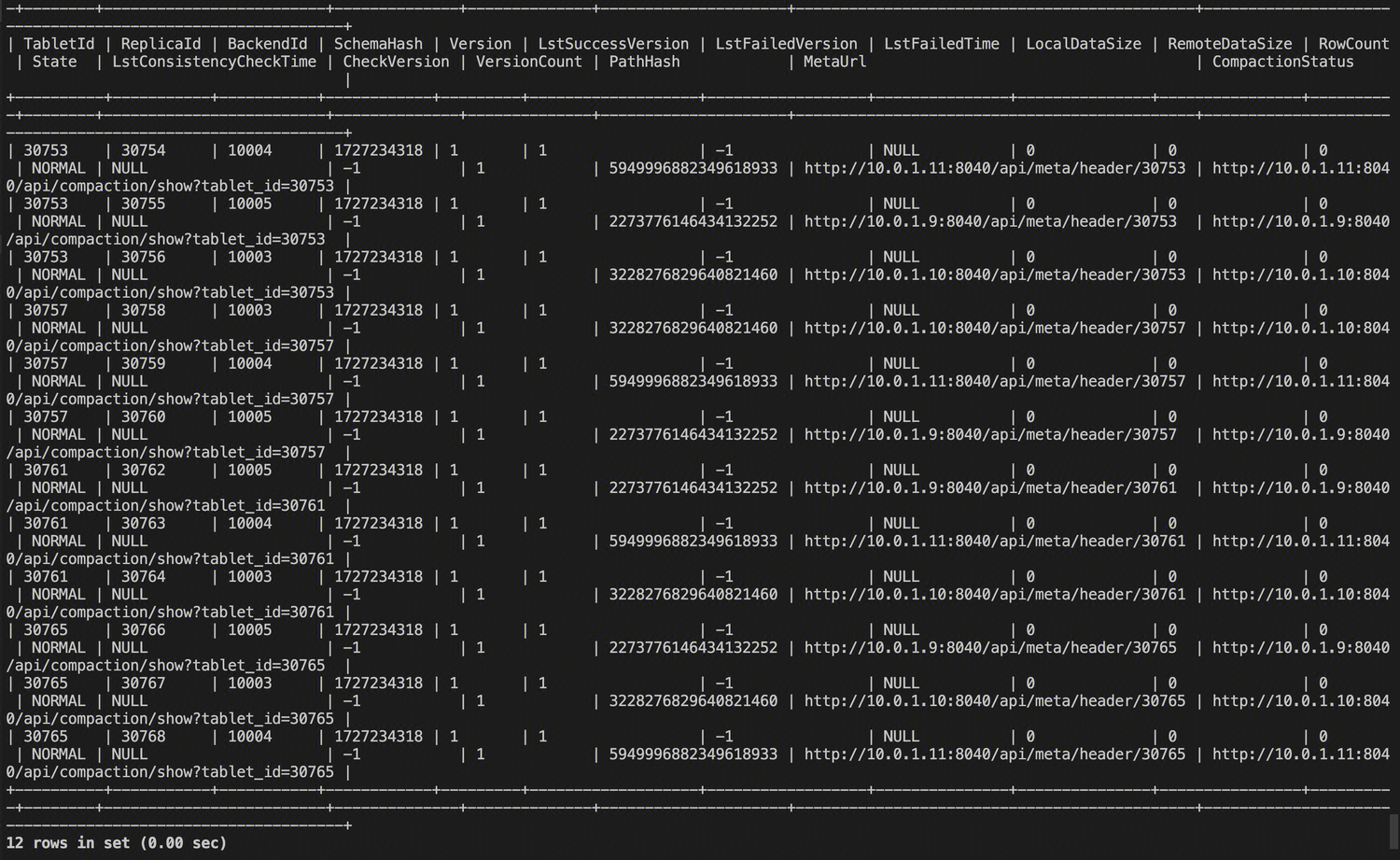
可以看到目前一共有2 2 3 = 12个 Tablet,通过 TabletId 和 ReplicaId 可以看出,ReplicaId 是唯一的,一个 TabletId 对应着3个 ReplicaId,即3个副本。
Tablet 信息中各列的具体含义如下:
列名 | 字段含义 |
TabletId | Tablet 的 ID |
ReplicaId | Tablet 副本 ID |
BackendId | Tablet 所在 BE 的 ID |
SchemaHash | 表的 schema 的哈希值,用于确保 schema 的一致性 |
Version | 版本 |
LstSuccessVersion | 上一次任务调度成功数据版本 |
LstFailedVersion | 上一次任务调度失败数据版本 |
LstFailedTime | 上一次任务调度失败时间 |
LocalDataSize | 本地数据大小 |
RemoteDataSize | 从远程节点获取的数据大小 |
RowCount | 副本中的行数 |
State | 副本的当前状态 |
LstConsistencyCheckTime | 上一次tablet副本一致性检查时间 |
CheckVersion | 上一次tablet副本一致性检查数据版本 |
VersionCount | Tablet 内的数据版本数量 |
PathHash | Tablet 存储路径的 hash 值 |
MetaUrl | 查看 Tablet 的 Meta 信息的 url 地址 |
CompactionStatus | 查看 Tablet 的 Compaction 信息的 url 地址 |
查看 Tablet 具体信息
SHOW TABLET {TabletId};

可以看到这个 Tablet 的一些信息,注意到 DetailCmd 字段,执行具体的命令。
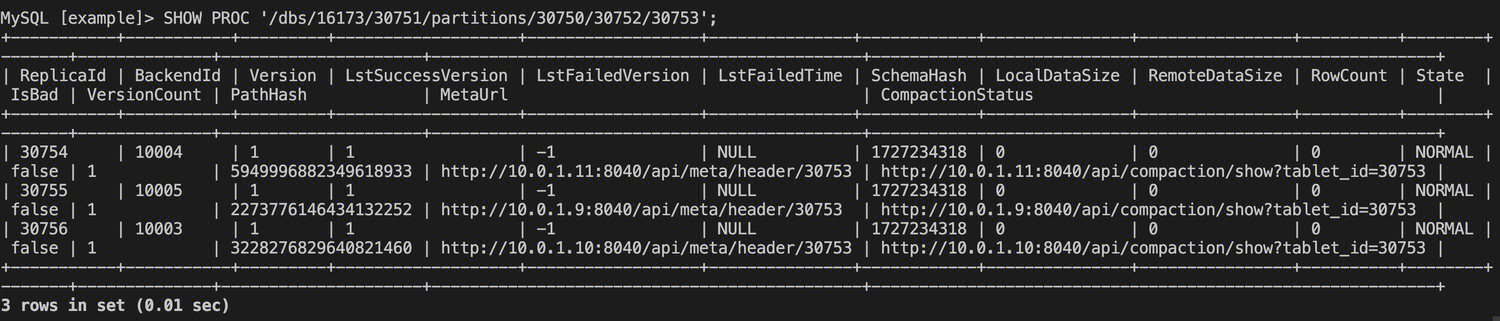
可以看到这个 Tablet 所有的 Replica 的具体信息。
查看 Tablet 健康状态
查看所有 db 的 Tablet 状态
SHOW PROC '/cluster_health/tablet_health'\\G
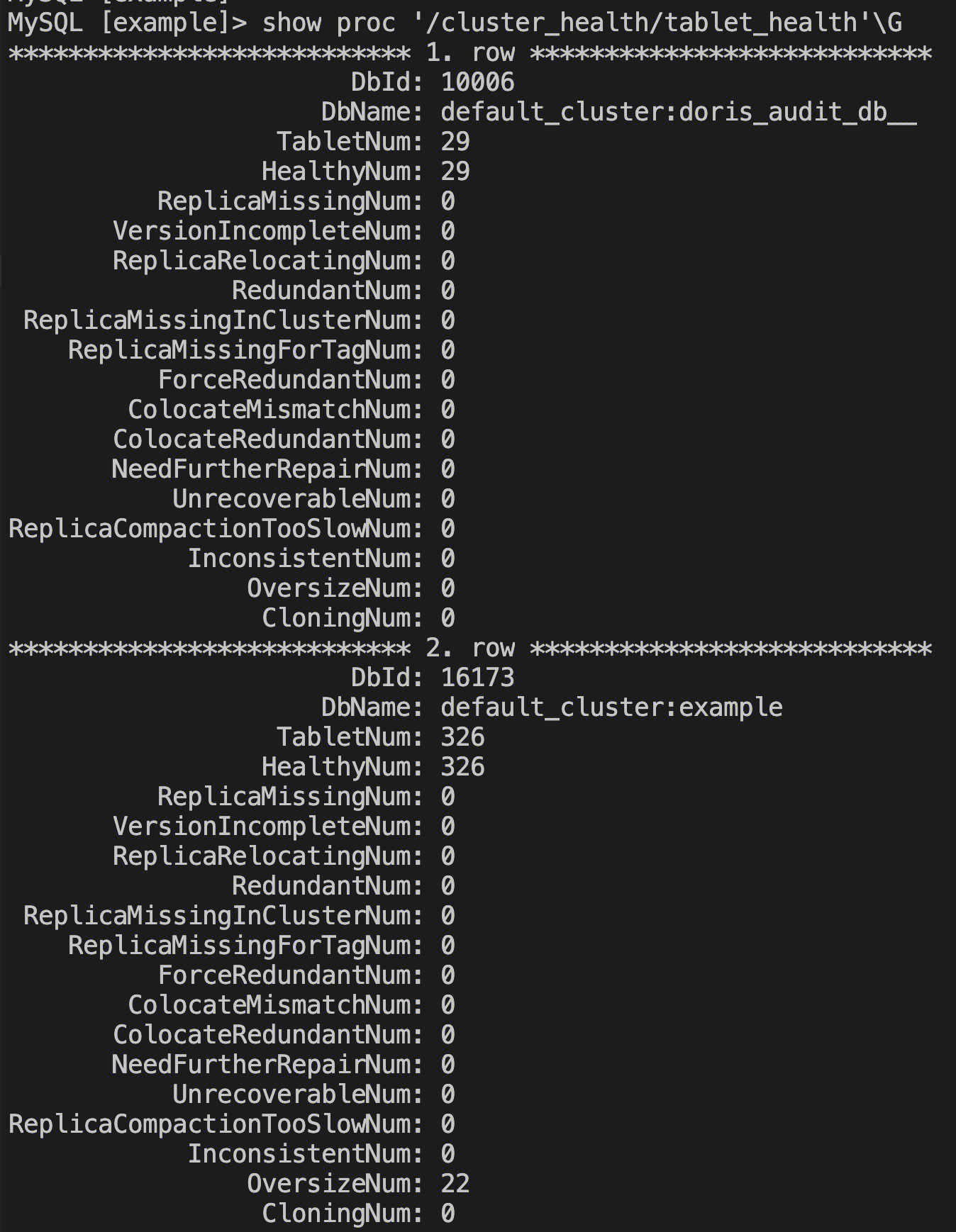
主要查看 TabletNum 和 HealthyNum 是否相等,在 db 健康的情况下,预期这两个值需要是相等的。
这里显示 example 库有22个 Tablet 是超出了预期大小。
查看 db 的 Tablet 具体状态
SHOW PROC '/cluster_health/tablet_health/{DbId}'\\G
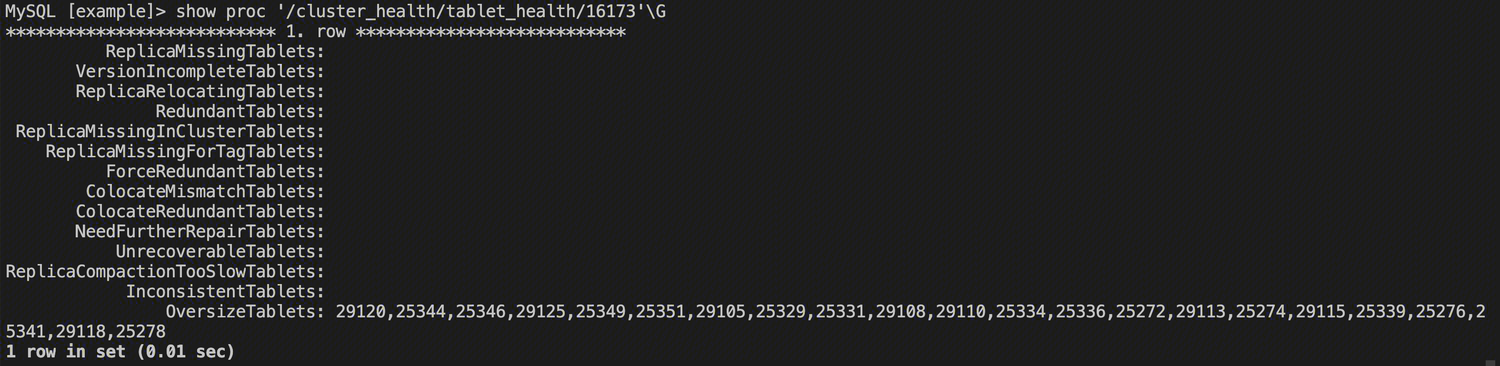
这里展示所有问题的 TabletId,知道 TabletId 后,可以通过上面展示过的 SHOW TABLTE 语句查看具体的 Tablet 信息,接着进行进一步的处理。

 是
是
 否
否
本页内容是否解决了您的问题?