腾讯云数据仓库 TCHouse-D
- 操作指南
- 开发指南
- 数据导入
- 导入方式
- 查询优化
- API 文档
- Making API Requests
- Cluster Operation APIs
- Database and Table APIs
- Cluster Information Viewing APIs
- Hot-Cold Data Layering APIs
- Database and Operation Audit APIs
- User and Permission APIs
- Resource Group Management APIs

BloomFilter 索引

最后更新时间:2024-06-27 11:10:19
BloomFilter 是由 Bloom 在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合,BloomFilter 有以下特点:
空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。
对于一个元素检测是否存在的调用,BloomFilter 会告诉调用者两个结果之一:可能存在或者一定不存在。
缺点是存在误判,告诉您可能存在,不一定真实存在。
布隆过滤器实际上是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处值置为1。
下图所示出一个 m=18,k=3 (m 是该 Bit 数组的大小,k 是 Hash 函数的个数)的 Bloom Filter 示例。集合中的 x、y、z 三个元素通过 3 个不同的哈希函数散列到位数组中。当查询元素 w 时,通过 Hash 函数计算之后因为有一个比特为0,因此 w 不在该集合中。
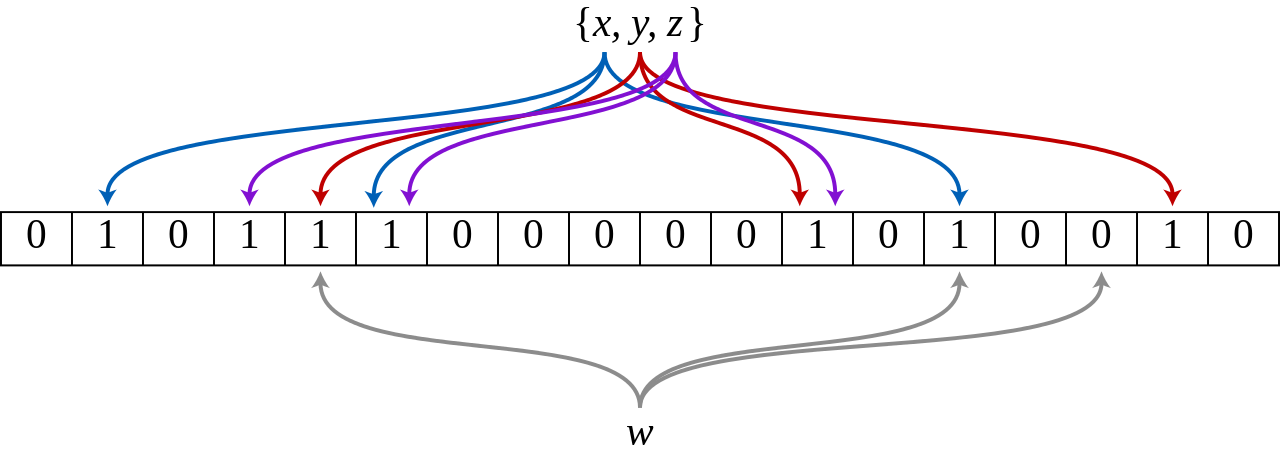
那么怎么判断某个元素是否在集合中呢?同样是这个元素经过哈希函数计算后得到所有的偏移位置,若这些位置全都为1,则判断这个元素在这个集合中,若有一个不为1,则判断这个元素不在这个集合中。就是这么简单。
Doris BloomFilter 索引及使用场景
举个例子:在 Hbase 中,如果要查找一个占用100字节存储空间大小的短行,一个64KB的 HFile 数据块应该包含(64 * 1024)/100 = 655.53 = ~700行,如果仅能在整个数据块的起始行键上建立索引,那么它是无法给您提供细粒度的索引信息的。因为要查找的行数据可能会落在该数据块的行区间上,也可能行数据没在该数据块上,也可能是表中根本就不存在该行数据,也或者是行数据在另一个 HFile 里,甚至在 MemStore 里。以上这几种情况,都会导致从磁盘读取数据块时带来额外的 IO 开销,也会滥用数据块的缓存,当面对一个巨大的数据集且处于高并发读时,会严重影响性能。
因此,HBase 提供了布隆过滤器,它允许您对存储在每个数据块的数据做一个反向测试。
当某行被请求时,通过布隆过滤器先检查该行是否不在这个数据块,布隆过滤器会回答“该行不在”/“不知道”。这就是为什么我们称它是反向测试。布隆过滤器同样也可以应用到行里的单元上,当访问某列时可以先使用同样的反向测试。
但布隆过滤器也不是没有代价。存储这个索引会占用额外的空间。布隆过滤器随着它们的索引对象数据增长而增长。当空间不是问题时,它们可以帮助您榨干系统的性能潜力。
Doris 的 BloomFilter 索引可以在建表的时候指定,或者通过表的 ALTER 操作来完成。Bloom Filter 本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回 false,则一定不在这个集合内。而如果范围true,则有可能不在这个集合内。
Doris 的 BloomFilter 索引也是以 Block 为粒度创建的。每个 Block 中,指定列的值作为一个集合生成一个 BloomFilter 索引条目,用于在查询时快速过滤不满足条件的数据。
创建 BloomFilter 索引
Doris BloomFilter 索引的创建是通过在建表语句的 PROPERTIES 里加上"bloom_filter_columns"="k1,k2,k3",这个属性,k1,k2,k3是您要创建的 BloomFilter 索引的 Key 列名称,例如下面我们对表里的 saler_id,category_id 创建了 BloomFilter 索引。
CREATE TABLE IF NOT EXISTS sale_detail_bloom (sale_date date NOT NULL COMMENT "销售时间",customer_id int NOT NULL COMMENT "客户编号",saler_id int NOT NULL COMMENT "销售员",sku_id int NOT NULL COMMENT "商品编号",category_id int NOT NULL COMMENT "商品分类",sale_count int NOT NULL COMMENT "销售数量",sale_price DECIMAL(12,2) NOT NULL COMMENT "单价",sale_amt DECIMAL(20,2) COMMENT "销售总金额")Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)PARTITION BY RANGE(sale_date)(PARTITION P_202111 VALUES [('2021-11-01'), ('2021-12-01')))DISTRIBUTED BY HASH(saler_id) BUCKETS 10PROPERTIES ("replication_num" = "3","bloom_filter_columns"="saler_id,category_id","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "MONTH","dynamic_partition.time_zone" = "Asia/Shanghai","dynamic_partition.start" = "-2147483648","dynamic_partition.end" = "2","dynamic_partition.prefix" = "P_","dynamic_partition.replication_num" = "3","dynamic_partition.buckets" = "3");
也可以对已经创建的表进行修改,指定列构建 Bloomfilter 索引。
alter table sale_detail_bloom set ("bloom_filter_columns" = "saler_id,category_id");
查看 BloomFilter 索引
查看我们在表上建立的 BloomFilter 索引是使用:
SHOW CREATE TABLE <table_name>;
删除 BloomFilter 索引
删除索引即为将索引列从 bloom_filter_columns 属性中移除:
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");
修改 BloomFilter 索引
修改索引即为修改表的 bloom_filter_columns 属性:
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");
Doris BloomFilter 使用场景
满足以下几个条件时可以考虑对某列建立 BloomFilter 索引:
1. 首先 BloomFilter 适用于非前缀过滤。
2. 查询会根据该列高频过滤,而且查询条件大多是 in 和 = 过滤。
3. 不同于 Bitmap,BloomFilter 适用于高基数列。例如 UserID。因为如果创建在低基数的列上,例如 “性别” 列,则每个 Block 几乎都会包含所有取值,导致 BloomFilter 索引失去意义。
Doris BloomFilter 使用注意事项
1. 不支持对 Tinyint、Float、Double 类型的列建 BloomFilter 索引。
2. BloomFilter 索引只对 in 和 = 过滤查询有加速效果。
3. 如果要查看某个查询是否命中了 BloomFilter 索引,可以通过查询的 Profile 信息查看。
4. 支持对一个表的多个列分别构建 bloomfilter index,但是某一列只能支持bitmap index/bloomfilter index 中的一个。
使用条件
支持的列类型:
SMALLINTINTUNSIGNEDINTBIGINTLARGEINTCHARVARCHARDATEDATETIMEDECIMAL其他类型暂不支持
查询生效的条件:
"=" ,例如:field = value
"is" ,例如:field IS NULL
"in" ,例如:field IN {value1, value2, ...}
最佳实践
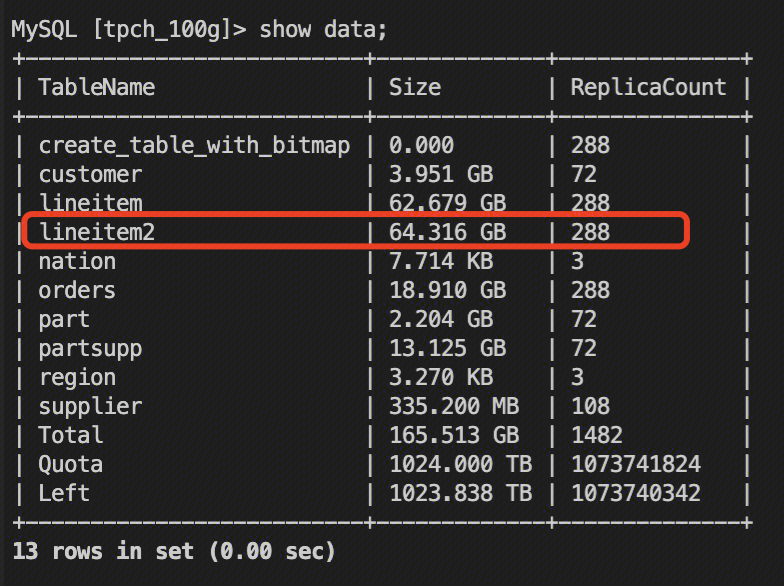
以下通过对 lineitem2 表的查询优化,展示 Bloomfilter 索引的最佳实践。lineitem2 表有6亿数据。
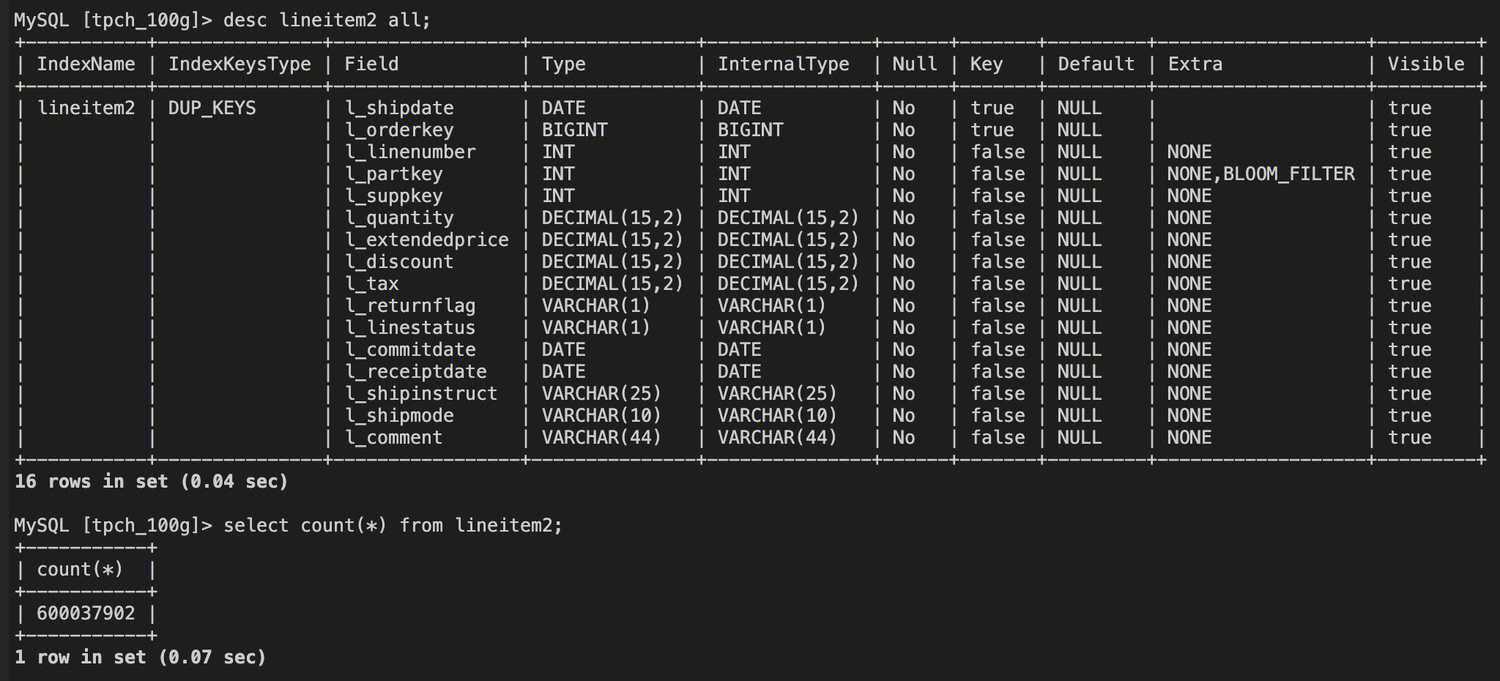
假设有以下查询 sql 需要进行优化:
select l_partkey,l_orderkey from lineitem2 where l_partkey =xxx;
分析查询 sql 是否可以使用 Bloomfilter index 进行优化
sql 的查询条件 l_partkey 对应的列取值为 2000W,识别度较高,字段类型为 INT,查询时使用等值条件,可以使用 Bloomfilter 进行优化。
创建和等待 Bloomfilter index 构建完成
创建 Bloomfilter index:
alter table lineitem2 set ("bloom_filter_columns" = "l_partkey");
通过 show alter table column 查看索引构建是否完成,注意如果未构建完成,查询过程时不会使用 Bloomfilter index 的。
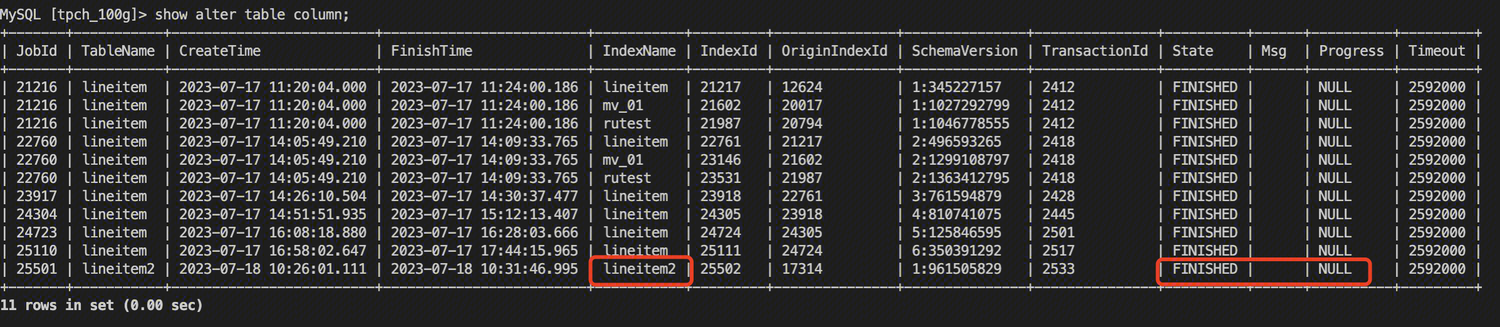
创建成功后,通过 show create table 语句可以看到。
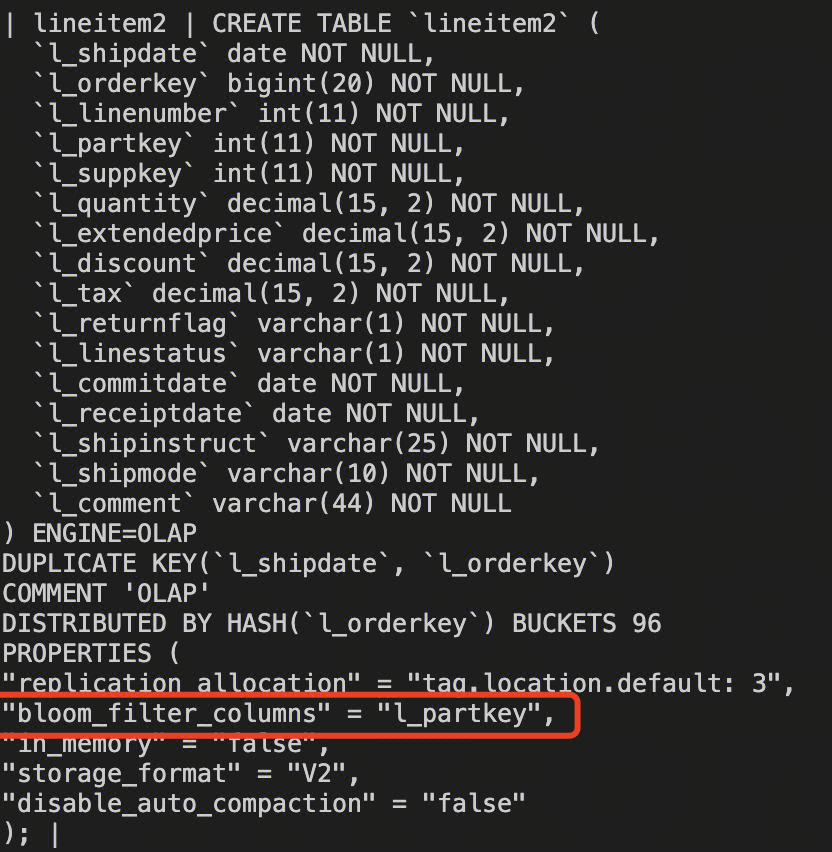
验证优化生效
对没有优化的表 lineitem,耗时490ms。
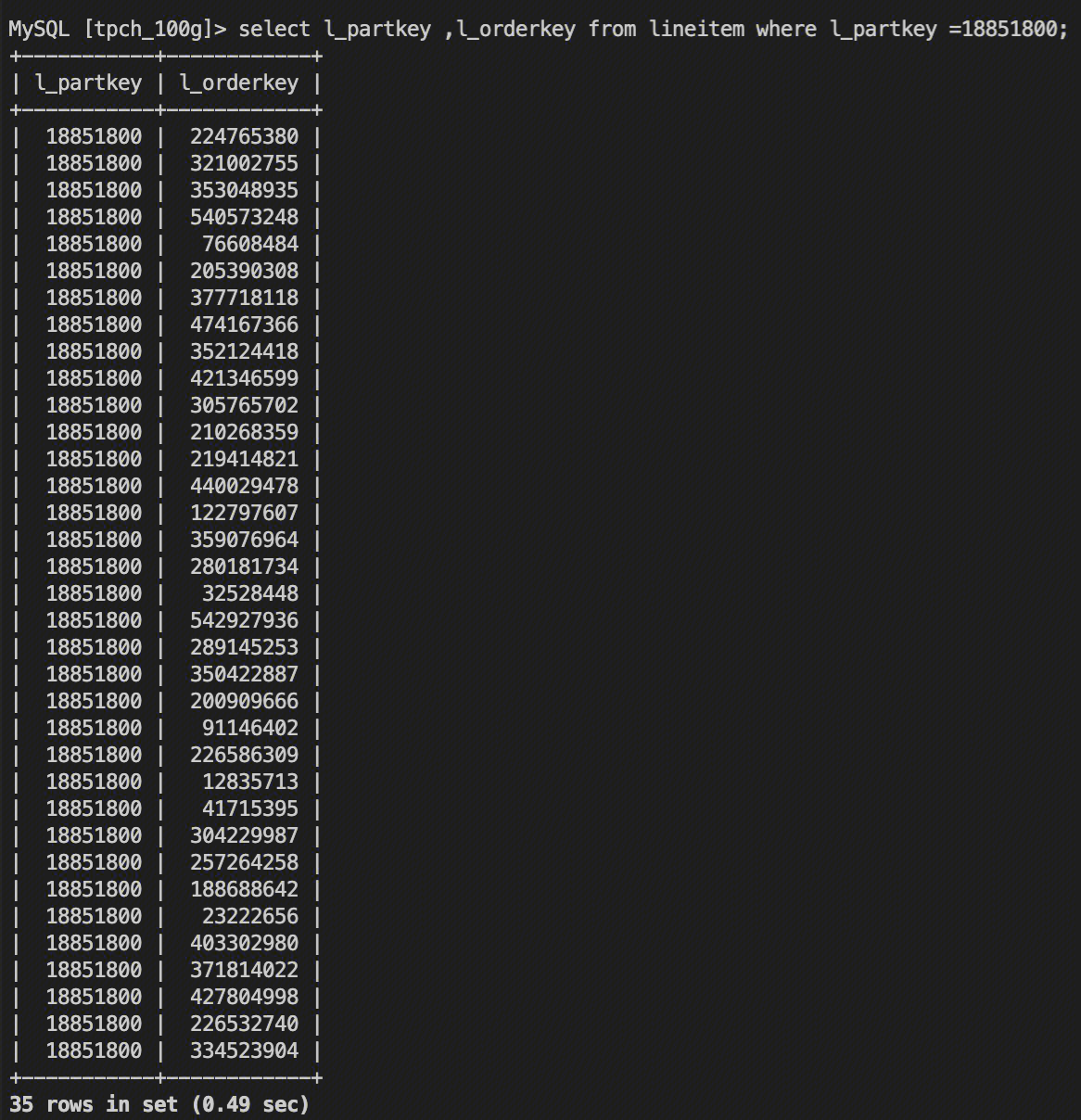
profile 看直接使用向量化能力过滤。
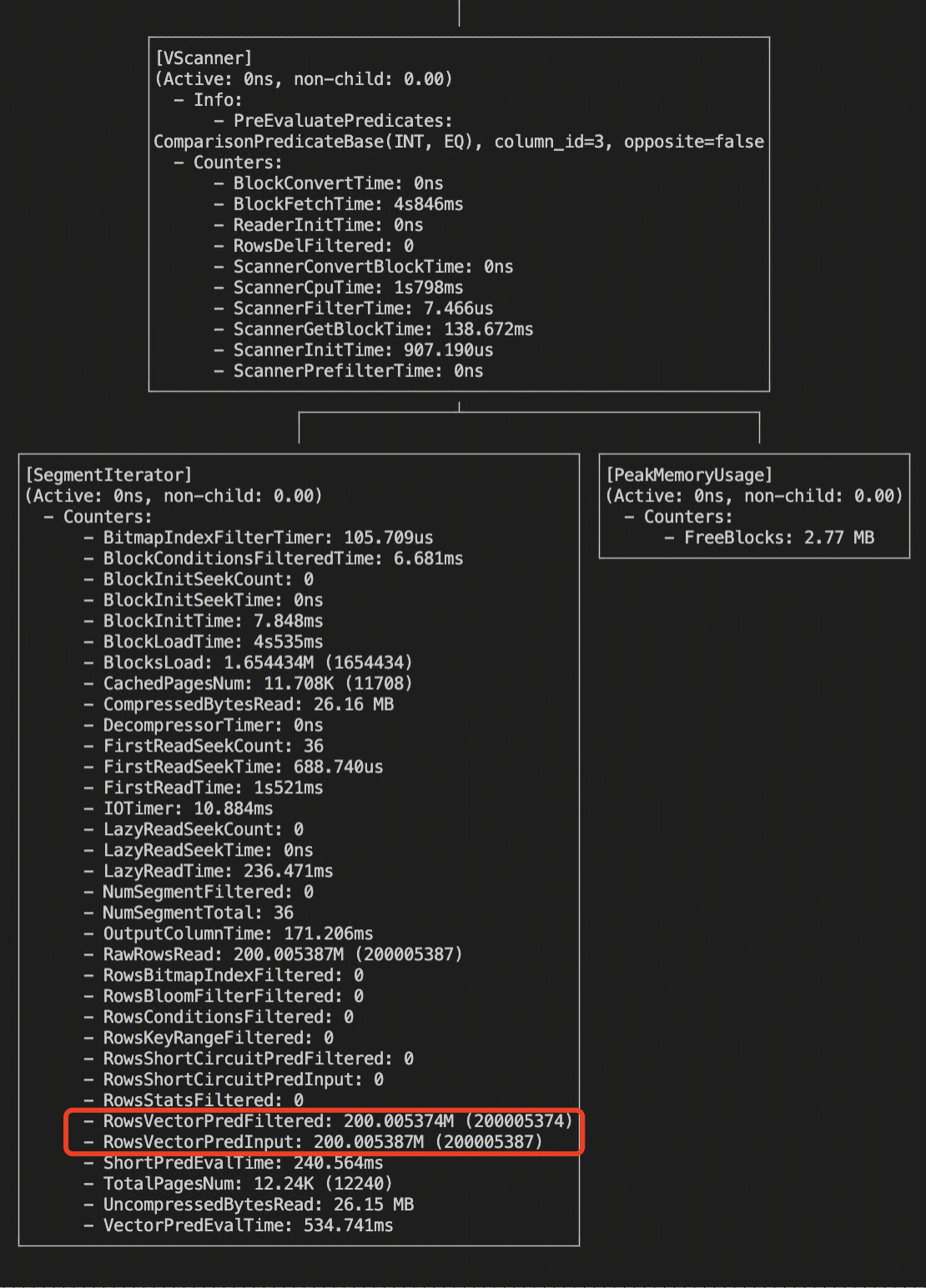
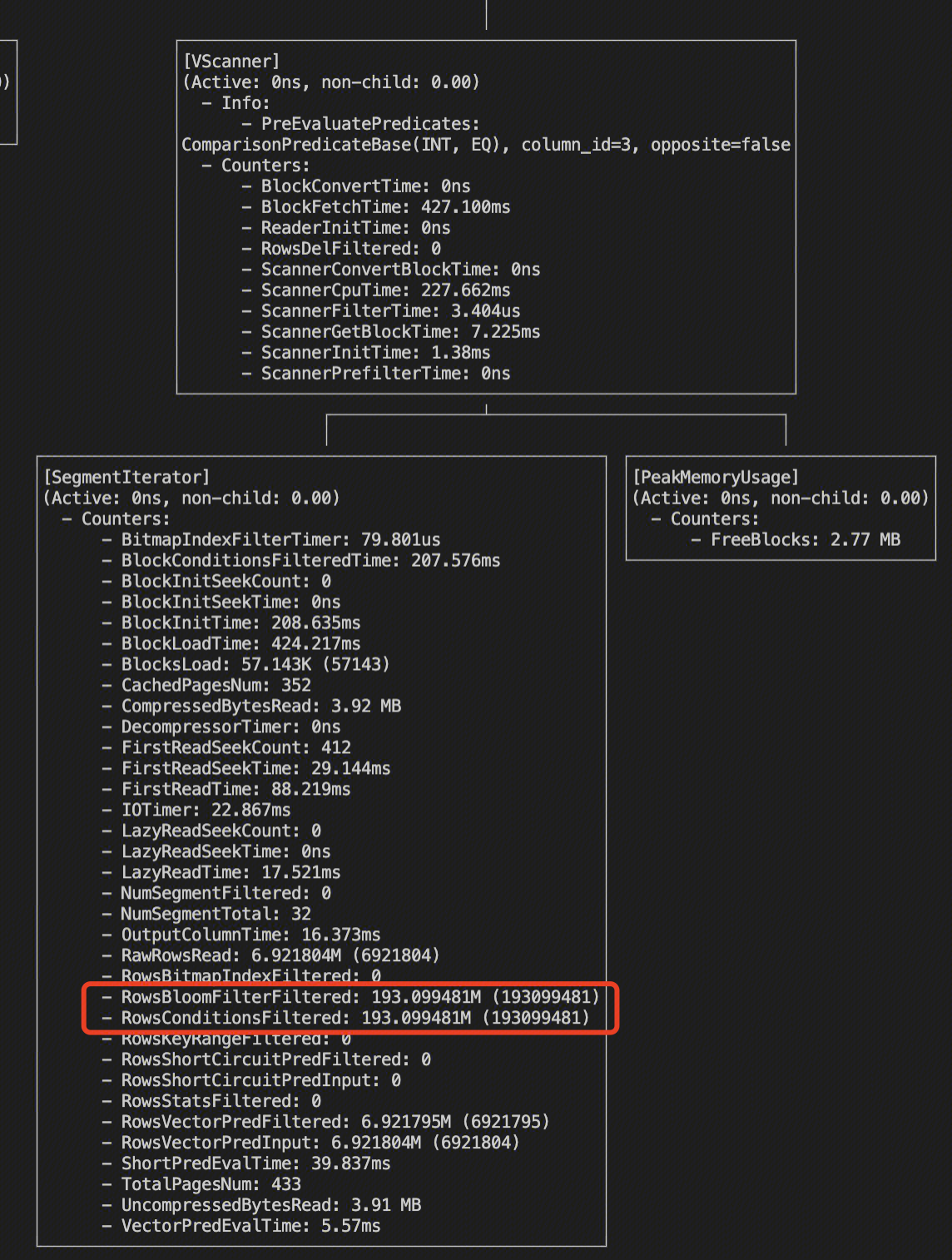
使用 Bloomfilter 优化的表 lineitem2,耗时50ms。
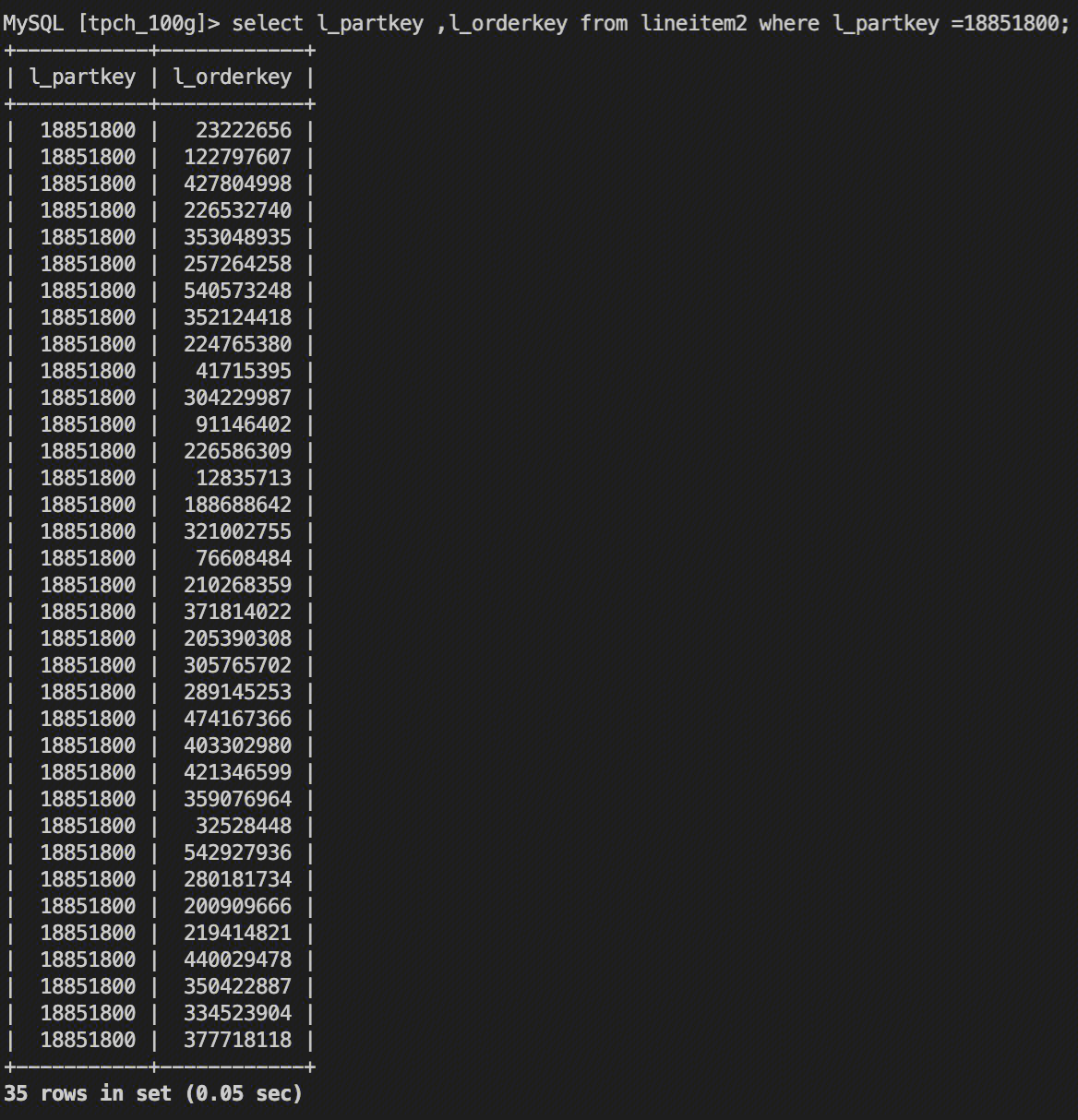
profile 看,使用了 Bloomfilter index 过滤 + 少量向量化能力过滤。
lineitem2 对比 lineitem 存储 增加了1.7G。