ROLLUP means "rolling up" in multidimensional analysis, specifically the further aggregation of data according to a certain specified granularity.
Concepts
In Doris, we call the tables created by users through the table creation statements as Base Tables, which store the underlying data stored as per the user's table creation statement.
Above Base table, we can create any number of ROLLUP tables. The data of these ROLLUP tables is based on the Base table and is independently stored physically.
The basic role of the ROLLUP table is to obtain coarser grain aggregate data based on the Base table.
We use some examples here to explain in detail the ROLLUP table and its function in different data models.
ROLLUP in Aggregate and Unique Model
Because Unique is just a special case of the Aggregate model, we don’t distinguish it here.
Example 1: obtaining the total consumption of each user
|
| | | |
| | | |
| | | Data import time, precise to the second |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
The data stored is as follows
On this basis, we create a ROLLUP, which contains only two columns: user_id and cost. After creation, the data stored in this ROLLUP is as follows:
It can be seen that the ROLLUP only retains the SUM result of each user_id in the cost column, so when we conduct the following query:
SELECT user_id, sum(cost) FROM table GROUP BY user_id;
Doris will automatically hit this ROLLUP table, scanning a very small amount of data to complete this aggregate query.
Example 2: Obtaining the total consumption of users in different cities, the longest and shortest page stay time by age segment
Create another ROLLUP on top of the Base table:
After it is created, the data stored in this ROLLUP is as follows
When we make the following queries:
mysql> SELECT city, age, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city, age;
mysql> SELECT city, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city;
mysql> SELECT city, age, sum(cost), min(min_dwell_time) FROM table GROUP BY city, age;
When Doris executes these sql, it will automatically hit this ROLLUP table.
ROLLUP in Duplicate model
Because the Duplicate model doesn't have the semantics of Aggregate, it's unable to create a rollup that contains Aggregate functions for the Duplicate table. Therefore, the ROLLUP in this model has lost its meaning of "rolling up". It only acts as adjusting the column order to hit the prefix index. We will explain in detail the prefix index and how to use ROLLUP to change the prefix index for better query efficiency in Index, Sorted Column and Prefix Index. Adjusting Prefix Index with ROLLUP
Because the column order is specified when creating a table, each table only has one type of prefix index. This may not be efficient enough for queries which use other columns that can't hit the prefix index. Therefore, we can adjust the column order artificially by creating ROLLUP. The following is an example:
The structure of the Base table is as follows:
We can create a ROLLUP table based on this:
It can be seen that the columns of the ROLLUP instance are exactly as those in the Base table, and the only difference is that the order of user_id and age was swapped. Therefore, when we make the following queries:
mysql> SELECT * FROM table where age=20 and message LIKE "%error%";
It can be seen that the ROLLUP table is preferentially selected as the prefix index of the ROLLUP has a higher match degree.
Usage Instructions for ROLLUP
The fundamental role of ROLLUP is to improve the efficiency of some queries, whether by reducing data volume through aggregate or rearranging columns to satisfy the prefix index requirement. Therefore, the meaning of ROLLUP goes beyond "rolling up". This is why it is named Materialized Index in our source code.
ROLLUP is subordinate to the Base table and it can be considered as an auxiliary data structure of Base table. Users can create or delete ROLLUP tables based on the Base table, but cannot explicitly specify a certain ROLLUP in the query. Whether a ROLLUP is used is entirely determined by Doris system.
The data in ROLLUP is independently and physically stored. Therefore, the more ROLLUP tables created, the more disk space consumed. It might also affect the import speed (as the import ETL stage will automatically generate data for all ROLLUP tables), but it doesn't decrease the query efficiency (but only makes it better ).
The data update in ROLLUP is completely synchronized with Base table. which users do not need to worry about.
The aggregate method in ROLLUP column is exactly the same as Base table. You do not need to specify it when creating ROLLUP, and it cannot be modified.
A necessary (but not sufficient) condition for a query to hit the ROLLUP is that all columns (including select list and columns in the where condition, etc.) involved in the query exist in the ROLLUP column. Otherwise, the query can only hit the Base table.
Certain types of queries (such as count(*) ) cannot hit ROLLUP under any circumstances. For details, see the following section on Limitations of the Aggregate Model.
You can use EXPLAIN your_sql; command to obtain the query execution plan, and check whether ROLLUP is hit in the plan.
You can display the Base table and all completed ROLLUPs by DESC tbl_name ALL; command.
Limitations for Usage of ROLLUP
When creating Rollup on Aggregate and Unique tables, it is not possible to specify Aggregate functions. Aggregation is automatically performed based on the Aggregate functions of the corresponding fields in the Base table.
Rollup can only operate on a single table, it does not support cross-table operations.
When performing Rollup on Unique tables, Rollup must include all Unique keys, otherwise the creation will fail. You can adjust the order of the Unique keys in the Base table to form different prefix indexes to accelerate queries.
When creating materialized views, it does not support multi-dimensional aggregate for the same key, that is, a key cannot appear multiple times.
Query
In Doris, Rollup acts as an aggregate materialized view, which can play two roles in queries:
Index
Aggregate data (only for aggregate model, i.e., aggregate key)
But to hit Rollup, certain conditions must be met, and you can judge whether Rollup can be hit and which Rollup table is hit by the PreAggregation value in ScanNode node in the execution plan.
Index
In previous query practice, we have introduced the prefix index of Doris, which means Doris will generate a sorted sparse index data (the data is also sorted, located by the index, and then binary search in the data) from the first 36 bytes (if there is varchar type, it may cause the prefix index to be less than 36 bytes, varchar will truncate the prefix index, and at most use varchar's 20 bytes) of the Base/Rollup table in the underlying storage engine. Then in the query, according to the conditions in the query, it will match the prefix index of each Base/Rollup and select the longest matching prefix index of Base/Rollup.
-----> Match from left to right
+----+----+----+----+----+----+
| c1 | c2 | c3 | c4 | c5 |... |
The conditions pushed down to ScanNode in the query's where and on clauses are matched starting from the first column of the prefix index. It checks whether these columns are in the conditions. If so, it accumulates the length of the match until it no longer matches or reaches 36 bytes (varchar type columns can only match 20 bytes, and matches less than 36 bytes will truncate the prefix index). Then, it selects the one with the longest matching length from Base/Rollup.
The following example explains, a Base table and four rollups were created:
+---------------+-------+--------------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+---------------+-------+--------------+------+-------+---------+-------+
| test | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index1 | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index2 | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index3 | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index4 | k4 | BIGINT | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
+---------------+-------+--------------+------+-------+---------+-------+
The prefix indexes of these five tables are:
Base(k1 ,k2, k3, k4, k5, k6, k7)
rollup_index1(k9)
rollup_index2(k9)
rollup_index3(k4, k5, k6, k1, k2, k3, k7)
rollup_index4(k4, k6, k5, k1, k2, k3, k7)
The conditions on the column that can use the prefix index need to be =<><=>=inbetween , and the parallel relationship is connected with and , for or,!= and so on cannot be hit, then look at the following query:
SELECT * FROM test WHERE k1 = 1 AND k2 > 3;.
There are conditions on k1 and k2, check that only the first column of Base contains the k1 in the condition, so the longest matching prefix index is test:
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k1` = 1, `k2` > 3
| partitions=1/1
| rollup: test
| buckets=1/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
Look at the following query:
SELECT * FROM test WHERE k4 = 1 AND k5 > 3;
There are conditions on k4 and k5, check that the first column of rollup_index3, rollup_index4 contains k4, but the second column of rollup_index3 contains k5, so the longest matching prefix index.
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k4` = 1, `k5` > 3
| partitions=1/1
| rollup: rollup_index3
| buckets=10/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
Now let's try to match the conditions on the varchar column, as follows:SELECT * FROM test WHERE k9 IN ("xxx", "yyyy") AND k1 = 10;.
There are two conditions, k9 and k1. The first columns of rollup_index1 and rollup_index2 both contain k9. It should be said that selecting these two rollups can hit the prefix index and the effect is the same. Select one at random (because here varchar exactly 20 bytes, the prefix index is truncated when it is less than 36 bytes), but the current strategy will continue to match k1 here, because the second column of rollup_index1 is k1, so rollup_index1 is selected, in fact, the following k1 condition will not play a role in acceleration. (If the condition outside the prefix index needs to speed up the query, you can accelerate it by establishing a Bloom Filter. Generally, you can establish it for the character string type, because Doris has a Min/Max index for the Block level type, date, and column). The explain result is as follows.
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k9` IN ('xxx', 'yyyy'), `k1` = 10
| partitions=1/1
| rollup: rollup_index1
| buckets=1/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
Finally, you can look at a query where multiple Rollups can hit: SELECT * FROM test WHERE k4 < 1000 AND k5 = 80 AND k6 >= 10000;.
There are three conditions, k4, k5, k6. The first three columns of rollup_index3 and rollup_index4 respectively contain these three columns, so the length of the prefix index matched by these two is the same, and the selection of these two can be done. The current default strategy is to select a rollup created earlier, and rollup_index3 is selected here.
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k4` < 1000, `k5` = 80, `k6` >= 10000.0
| partitions=1/1
| rollup: rollup_index3
| buckets=10/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
If we modify the above query to: SELECT * FROM test WHERE k4 < 1000 AND k5 = 80 OR k6 >= 10000;, this query cannot hit the prefix index. (Even any Min/Max, BloomFilter index in Doris storage engine cannot work).
Aggregate Data
Of course, the function of aggregate data is indispensable for normal aggregate materialized views, and such views are of great help to aggregate queries or reporting queries, and you need some preconditions to hit aggregate materialized views:
1. All columns involved in the query or subquery exist in an independent Rollup.
2. If there is a Join in the query or subquery, the Join type needs to be Inner join.
There are some kinds of aggregate queries that can hit Rollup, as follows.
If the above conditions are met, there are two stages when judging whether the aggregate model hits the Rollup:
1. Firstly, you need to match the Rollup table with the longest prefix index according to the conditions. See the above index strategy for specifics.
2. Secondly, you need to compare the number of rows in Rollup and choose the Rollup with the smallest number.
The following are the Base table and Rollup:
+-------------+-------+--------------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+-------------+-------+--------------+------+-------+---------+-------+
| test_rollup | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup2 | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup1 | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
+-------------+-------+--------------+------+-------+---------+-------+
See the following query:SELECT SUM(k11) FROM test_rollup WHERE k1 = 10 AND k2 > 200 AND k3 in (1,2,3);.
Firstly, judge whether the query can hit the aggregate's Rollup table. After checking the above diagram, it is positive. The conditions contain the three conditions k1, k2, k3, which are all contained in the first three columns of test_rollup, rollup1, rollup2, so the prefix index length is consistent, and then compare the number of rows. Obviously, rollup2 has the highest aggregate degree and the fewest number of rows, so you need to choose rollup2.
| 0:OlapScanNode |
| TABLE: test_rollup |
| PREAGGREGATION: ON |
| PREDICATES: `k1` = 10, `k2` > 200, `k3` IN (1, 2, 3) |
| partitions=1/1 |
| rollup: rollup2 |
| buckets=1/10 |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 0 |
ROLLUP Best Practice
In the usage of rollup, it is expected to accelerate the query, but in actual use, if it is used incorrectly, it can easily fail the optimization, or bring negative impact to the system.
It is recommended to follow the steps below when using rollup:
1. Plan rollup structure according to business scenarios.
2. Create rollup.
3. Confirm rollup construction completion.
4. Confirm that the business query statement hits rollup.
Based on the lineitem table of the TPC-H data test score, this is used as a case table to show the steps of using rollup. The following is the basic information of the lineitem table, which imported 62G of data, with a total of 60 million rows.
Based on the lineitem table, the business has the following query statements:
select l_partkey,l_suppkey,l_quantity from lineitem where l_partkey=xxxx;
For this SQL, it is expected that the query can be accelerated through rollup.
Because it currently does not hit the prefix index, it can be adjusted through rollup, adjusting the key, so that the where condition hits the prefix index. Create Rollup for the lineitem table with the following statement:
alter table lineitem add rollup rutest(l_partkey,l_suppkey,l_quantity);
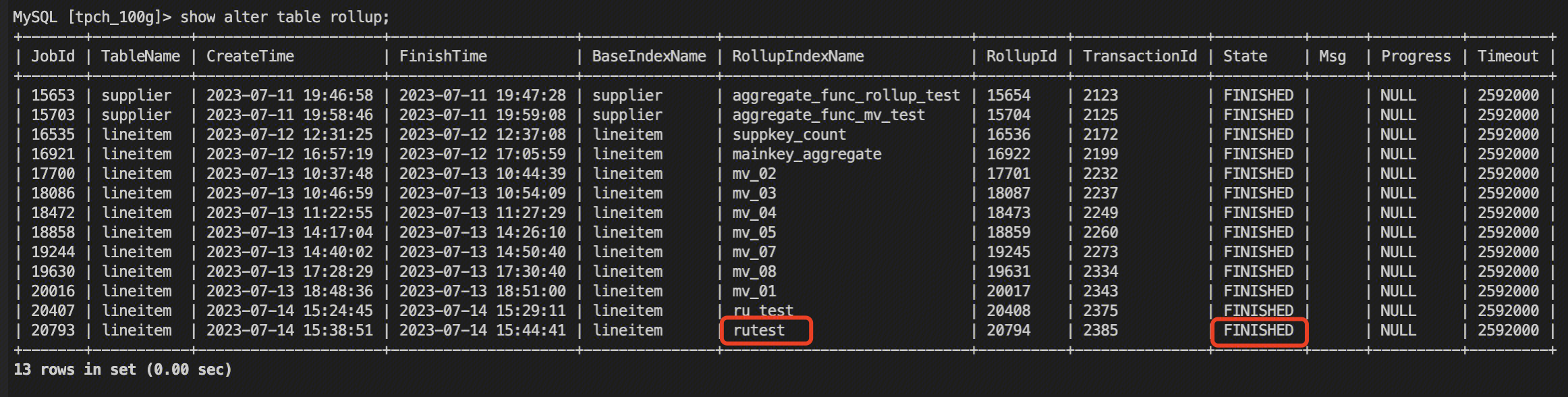
Execute rollup, view the progress of the materialized view construction by the command of show alter table rollup, and confirm that the construction task is completed.
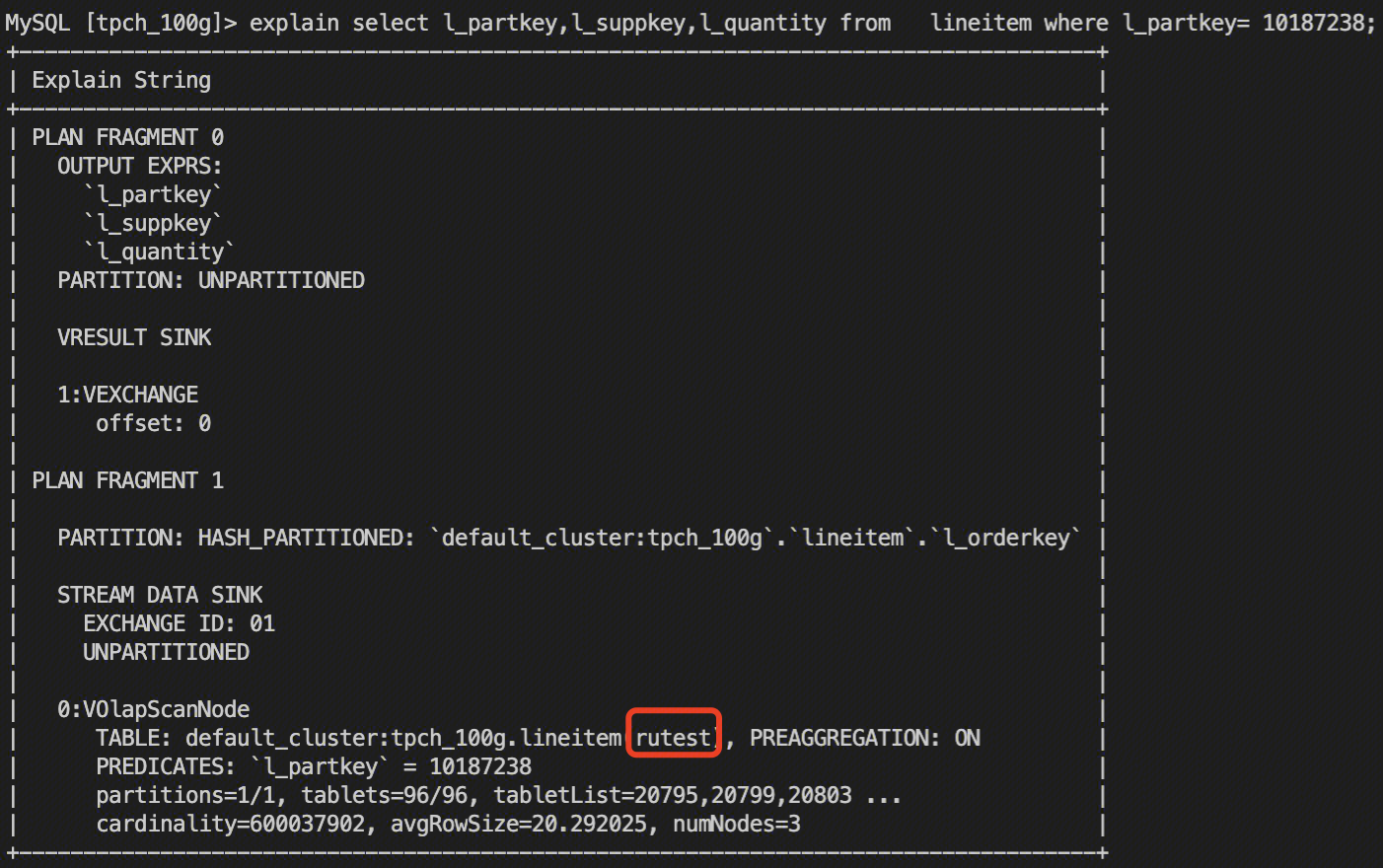
Confirm that the business query statement hits Rollup:
explain select l_partkey,l_suppkey,l_quantity from lineitem where l_partkey= 10187238;