Data Export is a feature provided by Doris to export data. This feature allows the data of a specified table or partition to be exported in text format through a Broker process to remote storage such as HDFS/BOS, etc. This document introduces the basics, usage, best practices, and precautions of Export.
Definition Of Terms
FE: Frontend, the frontend node of Doris. Responsible for metadata management and request access.
BE: Backend, the backend node of Doris. Responsible for query execution and data storage.
Broker: Doris can perform file operations on remote storage through the Broker process.
Tablet: Data sharding. A table will be divided into multiple data shards.
Principle
After a user submits an Export Job, Doris will calculate all the tablets involved in this job, then group them and generate a special query plan for each group. This query plan will read the data in the tablet then use the Broker to write the data to a specific path in distant storage or directly export it to remote storage that supports the S3 protocol.
The overall dispatch process works as follows:
+--------+
| Client |
+---+----+
| 1. Submit Job
|
+---v--------------------+
| FE |
| |
| +-------------------+ |
| | ExportPendingTask | |
| +-------------------+ |
| | 2. Generate Tasks
| +--------------------+ |
| | ExportExporingTask | |
| +--------------------+ |
| |
| +-----------+ | +----+ +------+ +---------+
| | QueryPlan +----------------> BE +--->Broker+---> |
| +-----------+ | +----+ +------+ | Remote |
| +-----------+ | +----+ +------+ | Storage |
| | QueryPlan +----------------> BE +--->Broker+---> |
| +-----------+ | +----+ +------+ +---------+
+------------------------+ 3. Execute Tasks
1. The user submits an Export job to the FE.
2. The Export scheduler of FE executes an Export job in two stages:
PENDING: FE generates an ExportPendingTask, sends a snapshot command to BE, takes a snapshot of all involved tablets, and generates multiple query plans.
EXPORTING: FE generates an ExportExportingTask and begins executing the query plan.
Splitting Query Plans
Each Export Job generates multiple query plans, each responsible for scanning a portion of tablets. The number of tablets scanned by each plan is specified by the FE's configuration parameter export_tablet_num_per_task. The default value is 5. Suppose there are 100 tablets, they will yield 20 query plans. Users might specify this value using the Job attribute tablet_num_per_task when submitting Jobs.
Multiple query plans of a job are executed sequentially.
Execute Query Plan
A query plan scans multiple fragments, organizes the read data in rows, and every 1,024 rows form a batch, which is written to remote storage by calling Broker.
If a query plan encounters an error, it will automatically retry as a whole 3 times. If a query plan still fails after 3 retries, the entire job fails.
Doris will first create a temporary directory named __doris_export_tmp_12345 in the specified remote storage path (where 12345 is the job id). The exported data will first be written to this temporary directory. Each query plan will generate a file, with an example filename: export-data-c69fcf2b6db5420f-a96b94c1ff8bccef-1561453713822. Where c69fcf2b6db5420f-a96b94c1ff8bccef is the query id of the query plan, and 1561453713822 is the timestamp when the file was created.
After all data is exported, Doris will rename these files to the user-specified path.
Broker Parameter
Export needs the help of the Broker process to access remote storage, and different Brokers need to provide different parameters.
Start Exporting
Export To HDFS
EXPORT TABLE db1.tbl1
PARTITION (p1,p2)
[WHERE [expr]]
TO "hdfs://host/path/to/export/"
PROPERTIES
(
"label" = "mylabel",
"column_separator"=",",
"columns" = "col1,col2",
"exec_mem_limit"="2147483648",
"timeout" = "3600"
)
WITH BROKER "hdfs"
(
"username" = "user",
"password" = "passwd"
);
Label: The identifier for this export job. You can use this identifier to check the job status later.
column_separator: Column delimiter. Default is \\t. Supports invisible characters, such as '\\x07'.
columns: The columns to export, separated by commas in English. If this parameter is not filled in, all columns of the table will be exported by default.
line_delimiter: Row delimiter. Default is . Supports invisible characters, such as '\\x07'.
exec_mem_limit: Represents the memory usage limit of a query plan on a single BE in the Export Job. Default is 2 GB. Unit: bytes.
timeout: Job timeout period. Default is 2 hours. Unit is seconds.
tablet_num_per_task: The maximum number of shards allocated for each query plan. Default is 5.
Export To Cloud Object Storage (COS)
Exporting directly to cloud storage, without going through a broker.
EXPORT TABLE db.table
TO "s3://your_bucket/xx_path"
PROPERTIES
(
"label"="your_label",
"line_delimiter"="\\n",
"column_separator"="\\001"
)
WITH S3
(
"AWS_ENDPOINT" = "http://cos.ap-beijing.myqcloud.com",
"AWS_ACCESS_KEY" = "AWS_ACCESS_KEY",
"AWS_SECRET_KEY"="AWS_SECRET_KEY",
"AWS_REGION"="AWS_REGION"
);
AWS_ACCESS_KEY/AWS_SECRET_KEY: These are the keys for accessing the OSS API.
AWS_ENDPOINT: Indicates the region where the OSS data center is located.
AWS_REGION: Endpoint represents the domain name for accessing OSS services externally.
View Export Status
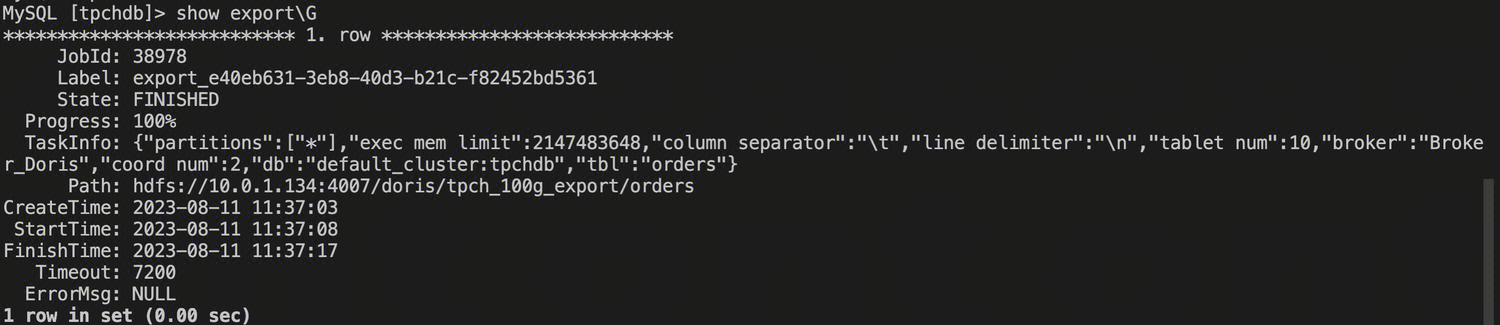
After submitting the job, you can query the status of the import job using the SHOW EXPORT command. Example results are as follows:
mysql> show EXPORT\\G;
*************************** 1. row ***************************
JobId: 14008
State: FINISHED
Progress: 100%
TaskInfo: {"partitions":["*"],"exec mem limit":2147483648,"column separator":",","line delimiter":"\\n","tablet num":1,"broker":"hdfs","coord num":1,"db":"default_cluster:db1","tbl":"tbl3"}
Path: hdfs:
CreateTime: 2019-06-25 17:08:24
StartTime: 2019-06-25 17:08:28
FinishTime: 2019-06-25 17:08:34
Timeout: 3600
ErrorMsg: NULL
1 row in set (0.01 sec)
JobId: The unique ID of the job.
Label: Custom job identifier.
State: Job status:
PENDING: Job pending scheduling.
EXPORTING: Data is being exported.
FINISHED: Job completed successfully.
CANCELLED: Job failed.
Progress: Job progress. This progress is measured in terms of query plans. Assuming there are a total of 10 query plans and 3 have been completed, the progress is 30%.
TaskInfo: Job information displayed in JSON format:
db: database name.
tbl: table name.
partitions: Specifies the partitions to export. * indicates all partitions.
exec mem limit: Memory usage limit for query plan. Unit is byte.
Column separator: The column separator for the exported file.
Line delimiter: The row separator for the exported file.
Tablet num: Total number of tablets involved.
Broker: The name of the broker used.
Coord num: Number of query plans.
Path: Export path on remote storage.
CreateTime/StartTime/FinishTime: The job's creation time, start scheduling time, and finish time.
Timeout: Job timeout period. Unit is seconds. This time is calculated from CreateTime.
ErrorMsg: If there is an error in the job, this will display the cause of the error.
Best Practices
Query Plan Splitting
The number of query plans that need to be executed for an export job depends on the total number of tablets, and how many tablets can be allocated to a single query plan. Multiple query plans are executed serially. Therefore, assigning more tablets to a query plan can reduce the job's runtime. However, if the query plan fails (for example, when calling the broker's RPC fails, or remote storage fluctuates), too many tablets will increase the retry cost for a query plan. Therefore, the number of query plans and the number of tablets each query plan scans need to be arranged reasonably in order to strike a balance between execution time and execution success rate. It is generally recommended that the amount of data scanned by a query plan is within 3-5 GB (the size and number of tablets of a table can be viewed by using SHOW TABLET FROM tbl_name; command).
Exec_mem_limit
Generally, a query plan for an Export Job only contains two parts: scanning - exporting, and does not need calculation logics that requires large memory. Therefore, the default memory limit of 2GB is usually able to meet the requirements. However, in some scenarios, such as when one query plan needs to scan too many tablets on the same BE or when there are too many versions of the tablet data, it could result in insufficient memory. In such cases, this parameter needs to be used to set larger memory, such as 4 GB or 8 GB.
Export To Tencent Cloud COS
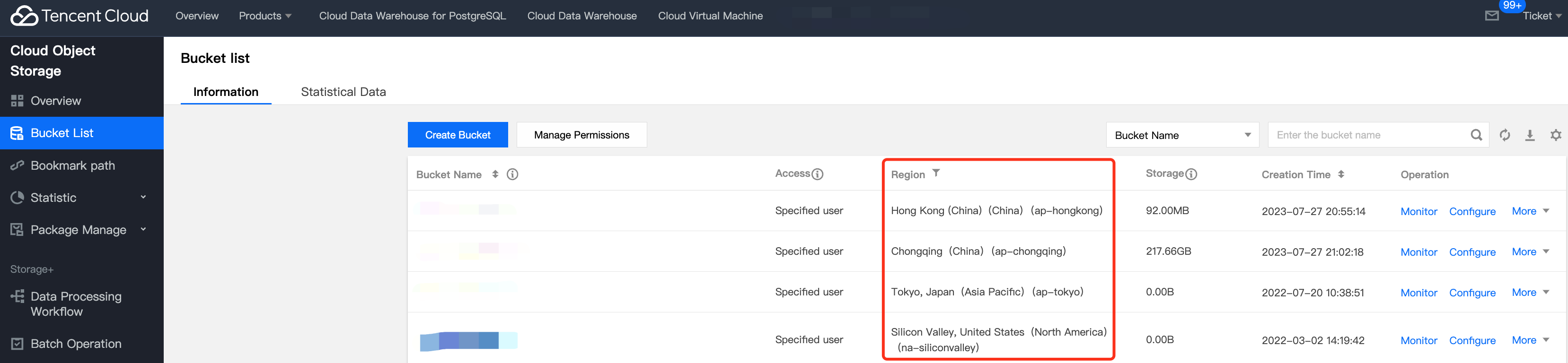
Obtain COS Domain Name
COS buckets have region attribute. When specifying COS upload address, it is necessary to include region ID. Detailed region ID can be viewed from Regions and Access Endpoints, or it can be found on the COS list page: When using the EXPORT statement, the AWS_ENDPOINT parameter must be specified. This is the domain name address of the COS, formatted as:
https://cos.[region_id].myqcloud.com
In which region_id is the name of the region where the COS is located, for example: ap-guangzhou in the above figure. Other fields remain unchanged.
Obtain COS SecretId and SecretKey
COS's SecretId corresponds to S3 protocol's ACCESS_KEY, and COS's SecretKey corresponds to S3 protocol's SECRET_KEY. Access to COS's SecretId and SecretKey can be obtained from Tencent Application Programming Interface Key Management. If there are existing keys, they can be used directly; or new keys need to be created. Start Export Task
Based on the information obtained, an EXPORT task can be created. Taking the export of a 62 GB lineitem_ep table containing 600 million rows of data as an example.
EXPORT TABLE lineitem TO "s3://doris-1301087413/doris-export/export_test"
WITH s3 (
"AWS_ENDPOINT" = "https://cos.ap-guangzhou.myqcloud.com",
"AWS_ACCESS_KEY" = "xxxSecretId",
"AWS_SECRET_KEY"="xxxSecretKey",
"AWS_REGION" = "ap-guangzhou"
);
In s3://doris-1301087413/doris-export/export_test.
S3 is a fixed prefix, indicating the target to Doris.
Doris-1301087413 is a COS bucket.
/doris-export/export_test is the path for the specified export location. If the path does not exist, Doris will automatically create it.
"AWS_ENDPOINT" = "https://cos.ap-guangzhou.myqcloud.com" is the COS server domain name filled in according to the bucket region.
"AWS_REGION" = "ap-guangzhou" is the bucket region.
View Export Task Progress and Information
By using the command 'show export;' you can view the progress and error information of the export task.
Pay attention to the 'State' and 'Progress' fields. If the task fails, the 'ErrorMsg' field will have the corresponding error information.
Import COS Data Files Into DORIS
Import directive:
LOAD LABEL test_db.exmpale_label_4(
DATA INFILE("s3://doris-1301087413/doris-export/export_test/*")
INTO TABLE test_tb COLUMNS TERMINATED BY "\\t"
)
WITH S3(
"AWS_ENDPOINT" = "https://cos.ap-guangzhou.myqcloud.com",
"AWS_ACCESS_KEY" = "xxxxx", "AWS_SECRET_KEY"="xxxx",
"AWS_REGION" = "ap-guangzhou"
)
PROPERTIES(
"timeout" = "7600"
);
Where:
LABEL test_db.example_label_4: test_db is the name of the import DB.
example_label_4 is the Tag for this import, uniquely marking an import task. DATA INFILE("s3://doris-1301087413/doris-export/export_test/*"): doris-1301087413/doris-export/export_test/ is the file path for import.
* indicates that all files under this path are imported, or a specific file name can be specified.
EXPORT To Tencent Cloud EMR'S HDFS
Network Confirmation
Confirm that Doris cluster and EMR cluster are in the same VPC network.
Create an Export Task
EXPORT TABLE orders TO "hdfs://hdfs_ip:hdfs_port/your_path"
PROPERTIES (
"column_separator"="\\t",
"line_delimiter" = "\\n"
)
WITH BROKER "Broker_Doris" (
"username"="-",
"password"="-"
)
Where:
Broker_Doris: Broker_Doris is the default name in Tencent Cloud Doris's Broker, there is no need to modify.
username: The username to access HDFS.
password: The password to access HDFS.
View Export Task Status
By using the command 'show export;' you can view the progress and error information of the export task.
Pay attention to the 'State' and 'Progress' fields. If the task fails, the 'ErrorMsg' field will have the corresponding error information.
Import HDFS Of Tencent Cloud EMR Into Doris
Import directive:
LOAD LABEL tpchdb.load_orders_recover(
DATA INFILE("hdfs://hdfs_ip:hdfs_port/your_path/*")
INTO TABLE orders_recover
COLUMNS TERMINATED BY "\\t"
)
WITH BROKER "Broker_Doris"(
"username" = "-",
"password" = "-!"
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
Where:
LABEL tpchdb.load_orders_recover: tpchdb is the name of the import database.
load_orders_recover is the tag for this import.
DATA INFILE("hdfs://hdfs_ip:hdfs_port/your_path/") : hdfs://hdfs_ip:hdfs_port/your_path/ is the import file path.
* indicates that all files under this path are imported, or a specific file name can be specified.
Common Issues
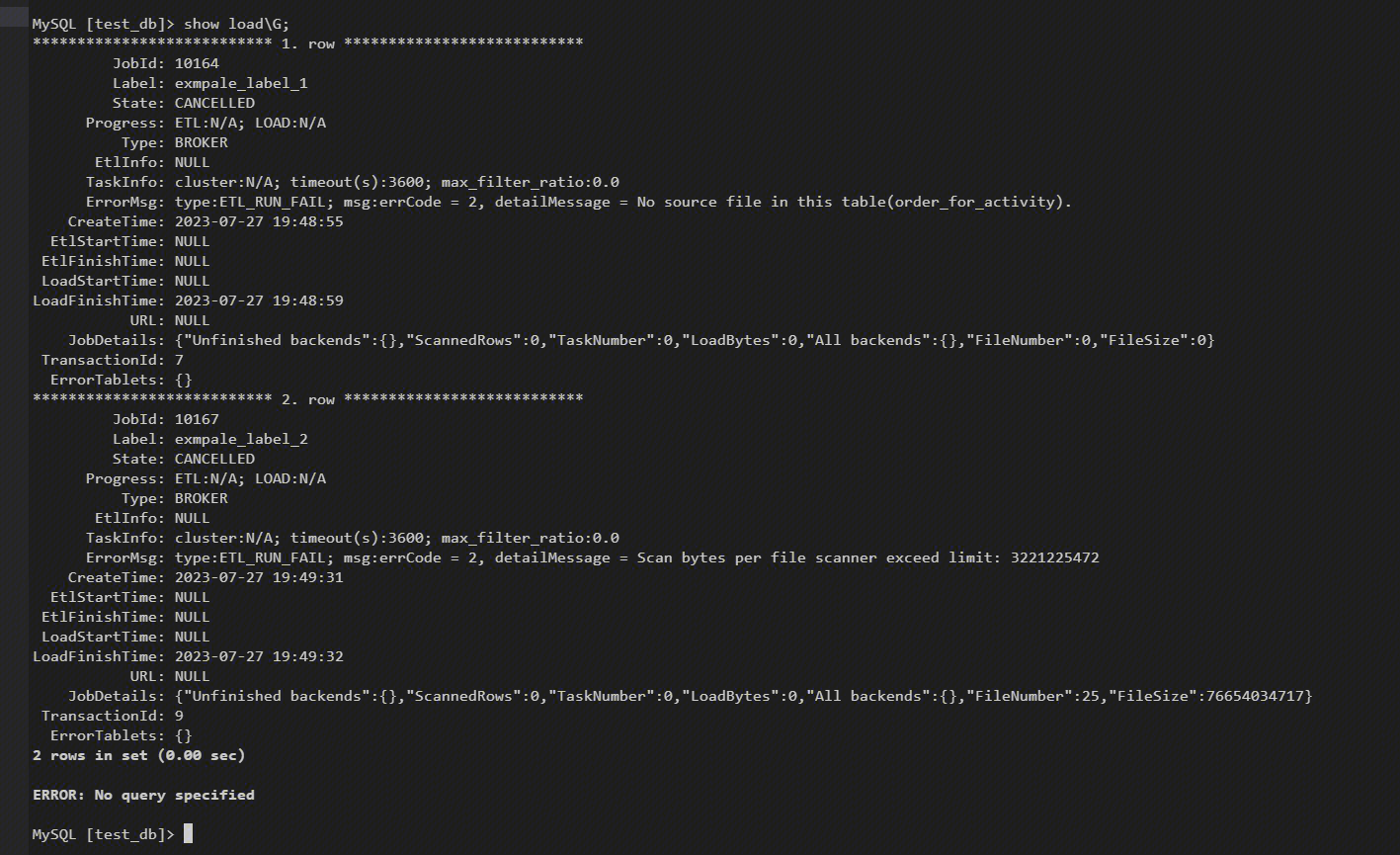
Import Error: Scan Bytes Per File Scanner Exceed Limit: Xxxxx
Findings: 'show load' command can be used to view the import task operation state, the 'ErrorMsg' shows error messages.
Reason: The size of the import file is larger than the maximum value in cluster settings.
Resolution: Change the configuration 'max_broker_concurrency' to 'BE amount' in fe.conf. The amount of data handled by a single BE in the current import task = original file size / max_broker_concurrencymax_bytes_per_broker_scanner should be >= the amount of data handled by a single BE in the current import task
Configuration Method:
ADMIN SET FRONTEND CONFIG ("max_bytes_per_broker_scanner" = "52949672960");
ADMIN SET FRONTEND CONFIG ("max_broker_concurrency" = "3");
Must-Knows
It is not recommended to export a large amount of data at once. The recommended maximum data volume for an export job is several tens of GB. Excessive exports can lead to more garbage files and higher retry costs.
If the table data volume is too large, it is recommended to export by partition.
During the running of an Export Job, if FE restarts or switches to the primary, the Export Job will fail and require the user to resubmit.
If an Export Job fails, the __doris_export_tmp_xxx temporary directory generated in the remote storage, as well as the already generated files, will not be deleted and need to be manually deleted by the user.
If the Export Job runs successfully, the __doris_export_tmp_xxx directory generated in the remote storage may be retained or cleared depending on the semantics of the remote storage file system. For example, in Baidu Cloud Object Storage (BOS), after the last file in a directory is moved away through a rename operation, the directory will also be deleted. If the directory is not cleared, the user can delete it manually.
When the Export finishes running (successfully or failed), if FE restarts or switches to the primary, some information of the job displayed by SHOW EXPORT will be lost and cannot be viewed.
The Export Job will only export the data of the base table and will not export the data of the Rollup Index.
The Export Job scans data and consumes IO resources, which may affect the system's query delay.
Related Configuration
FE
export_checker_interval_second: The scheduling interval of the Export Job scheduler, which defaults to 5 seconds. Restart FE is required after setting this parameter.
export_running_job_num_limit: Limit on the number of running Export Jobs. If exceeded, the job will wait and be in PENDING status. It defaults to 5 and can be adjusted during runtime.
export_task_default_timeout_second: The default timeout for the Export Job. It defaults to 2 hours and can be adjusted during runtime.
export_tablet_num_per_task: The maximum number of shards a query plan is responsible for. Default is 5.