- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
腾讯云 Elasticsearch 服务提供在用户 VPC 内通过私有网络 VIP 访问集群的方式,用户可通过 Elasticsearch REST Client 编写代码访问集群并将自己的数据导入到集群中,当然也可以通过官方提供的组件(如 logstash 和 beats)接入自己的数据。
本文以官方提供的组件 logstash 和 beats 为例,介绍不同类型的数据源接入 ES 的方式。
准备工作
因访问 ES 集群需要在用户 VPC 内进行,因此用户需要创建一台和 ES 集群相同 VPC 下的 CVM 实例或者 Docker 集群。
使用 logstash 接入 ES 集群
CVM 中访问 ES 集群
1. 安装部署 logstash 与 java8。
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.6.4.tar.gztar xvf logstash-5.6.4.tar.gzyum install java-1.8.0-openjdk java-1.8.0-openjdk-devel -y
注意:
请注意 logstash 版本,建议与 Elasticsearch 版本保持一致。
2. 根据数据源类型自定义配置文件
*.conf,配置文件内容可参考 数据源配置文件说明。3. 执行 logstash。
nohup ./bin/logstash -f ~/*.conf 2>&1 >/dev/null &
Docker 中访问 ES 集群
自建 Docker 集群
1. 拉取 logstash 官方镜像。
docker pull docker.elastic.co/logstash/logstash:5.6.9
2. 根据数据源类型自定义配置文件
*.conf,放置在 /usr/share/logstash/pipeline/目录下,目录可自定义。3. 运行 logstash。
docker run --rm -it -v ~/pipeline/:/usr/share/logstash/pipeline/ docker.elastic.co/logstash/logstash:5.6.9
使用腾讯云容器服务
腾讯云 Docker 集群运行于 CVM 实例上,所以需要先在容器服务控制台上创建 CVM 集群。
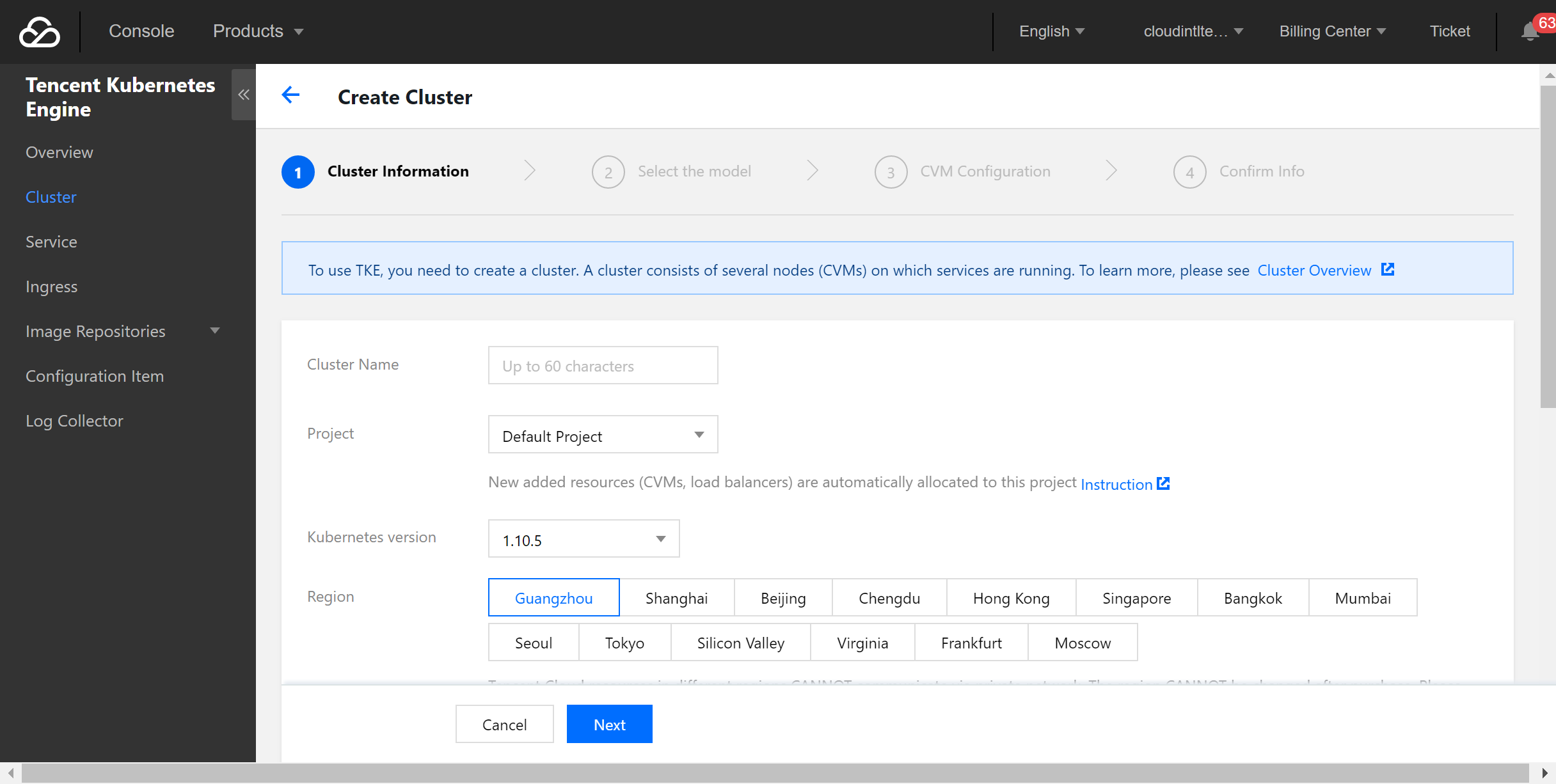
1. 登录 容器服务控制台,选择左侧菜单栏集群 > 新建创建集群。
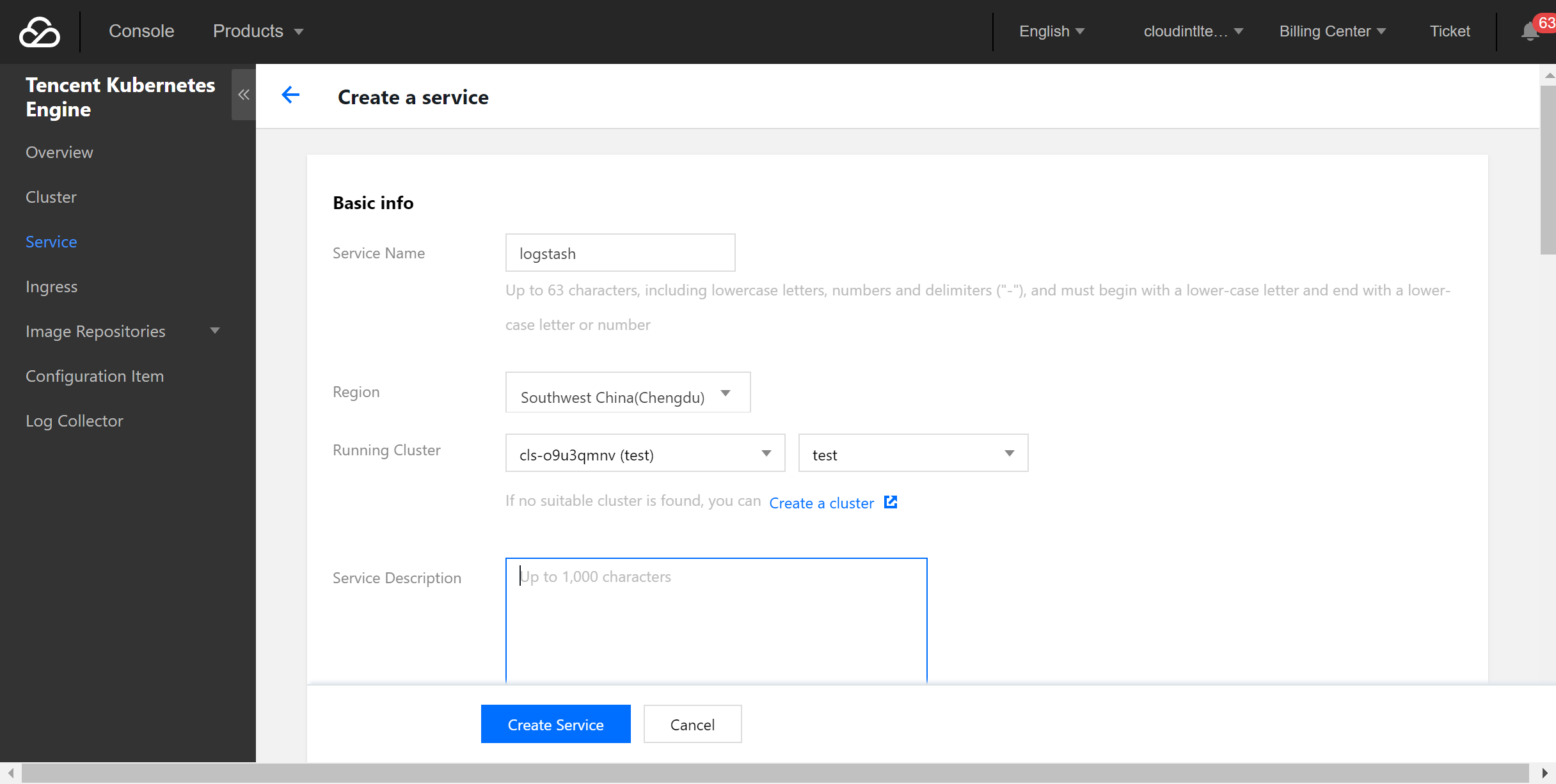
2. 选择左侧菜单栏服务,单击新建创建服务。
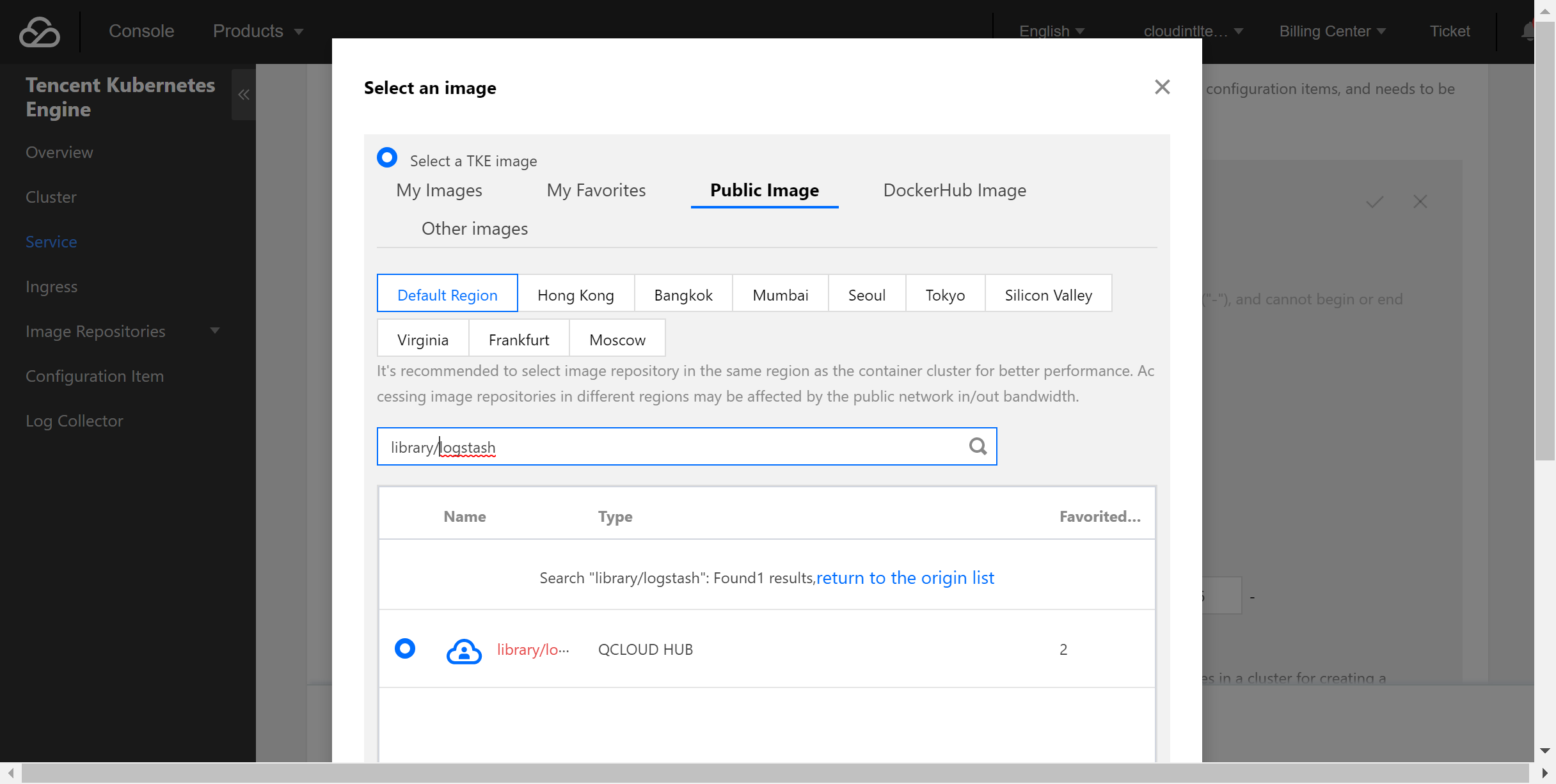
3. 选取 logstash 镜像。
本例中使用 TencentHub 镜像仓库提供的 logstash 镜像,用户也可以自行创建 logstash 镜像。
4. 创建数据卷。
创建存放 logstash 配置文件的数据卷,本例中在 CVM 的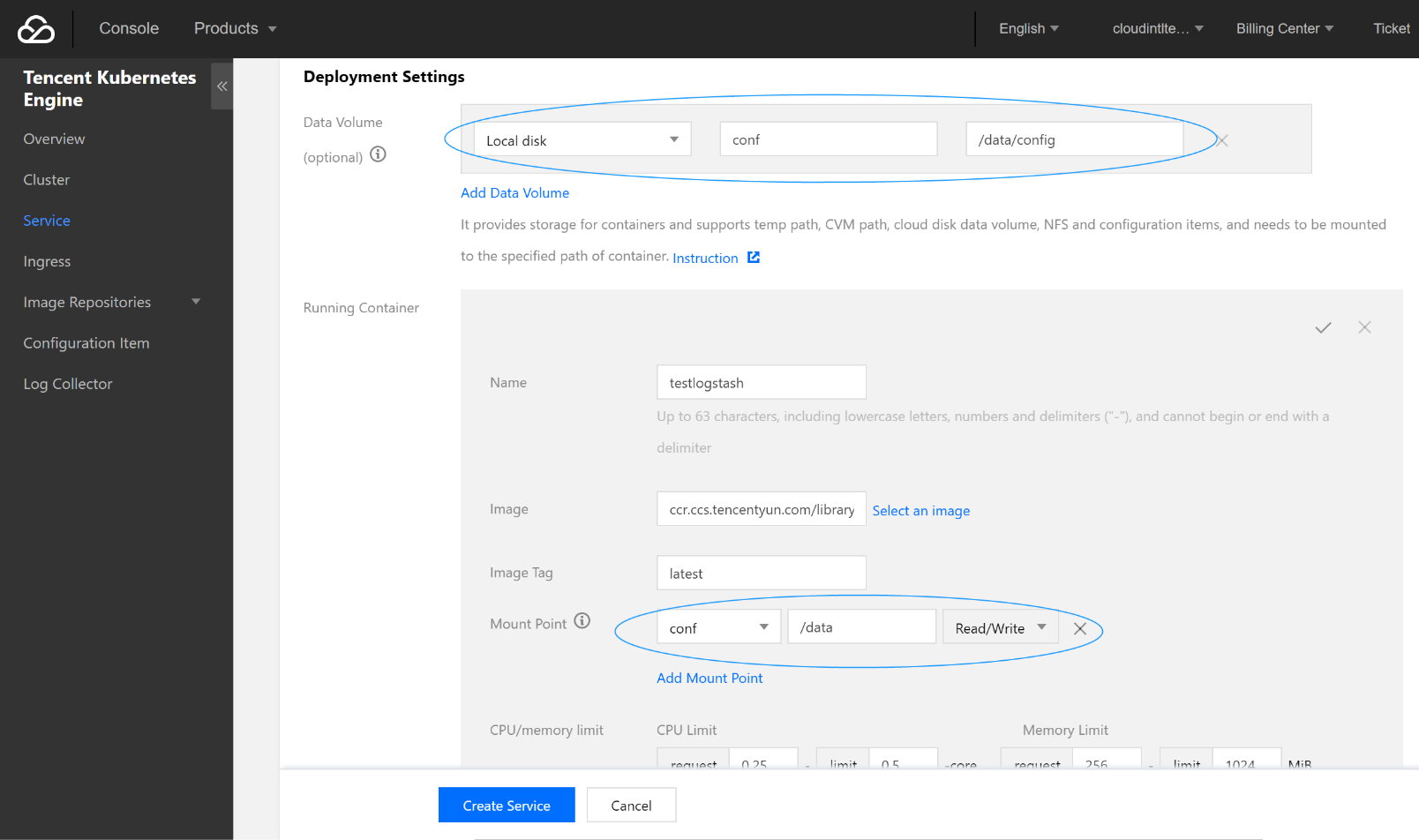
/data/config目录下添加了名为 logstash.conf 的配置文件,并将其挂在到 Docker 的/data目录下,从而使得容器启动时可以读取到 logstash.conf 文件。
5. 配置运行参数。
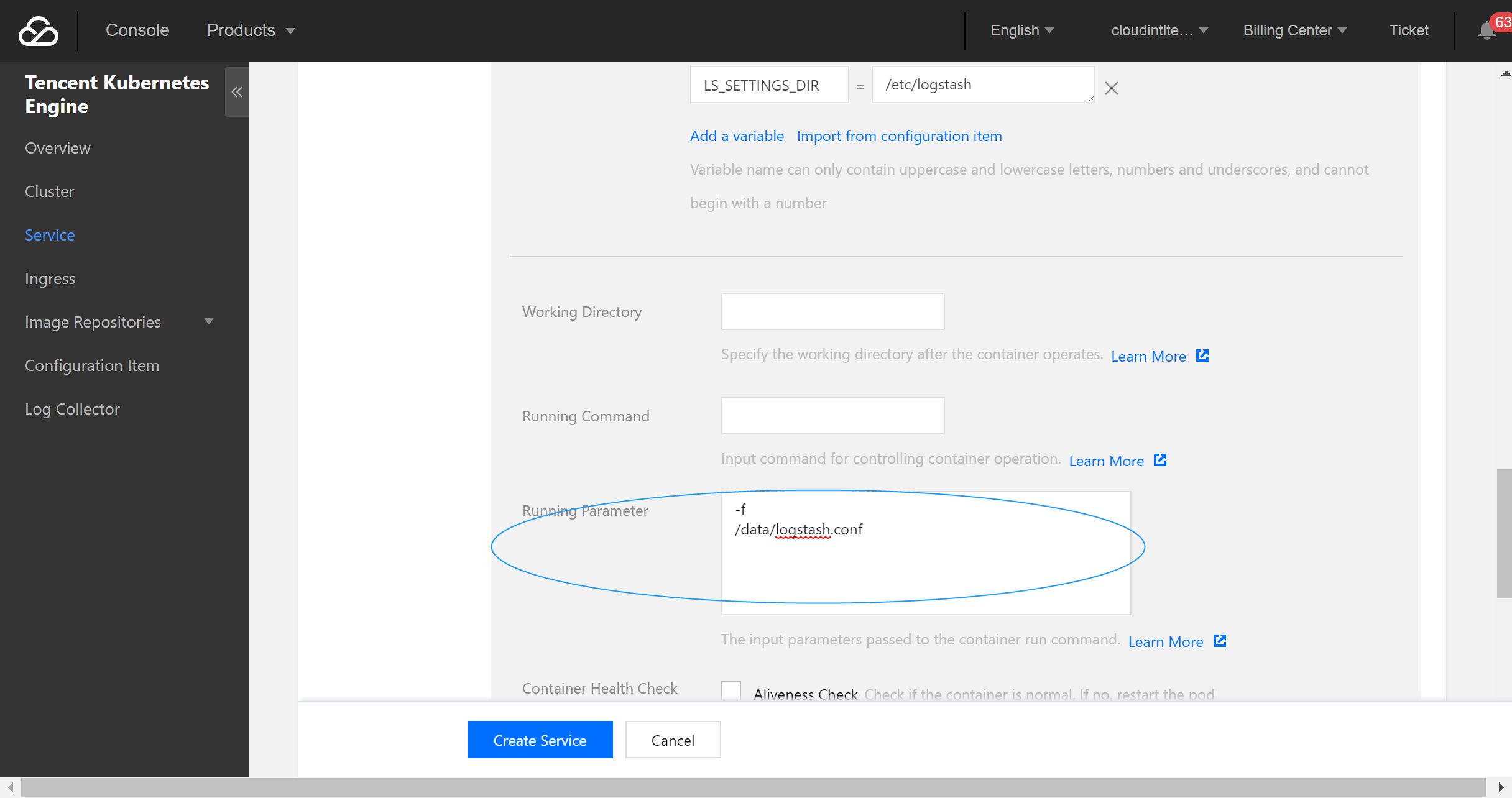
6. 根据需要配置服务参数并创建服务。

配置文件说明
File 数据源
input {file {path => "/var/log/nginx/access.log" # 文件路径}}filter {}output {elasticsearch {hosts => ["http://172.16.0.89:9200"] # Elasticsearch 集群的内网 VIP 地址和端口index => "nginx_access-%{+YYYY.MM.dd}" # 自定义索引名称,以日期为后缀,每天生成一个索引}}
Kafka 数据源
input{kafka{bootstrap_servers => ["172.16.16.22:9092"]client_id => "test"group_id => "test"auto_offset_reset => "latest" #从最新的偏移量开始消费consumer_threads => 5decorate_events => true #此属性会将当前 topic、offset、group、partition 等信息也带到 message 中topics => ["test1","test2"] #数组类型,可配置多个 topictype => "test" #数据源标记字段}}output {elasticsearch {hosts => ["http://172.16.0.89:9200"] # Elasticsearch 集群的内网 VIP 地址和端口index => "test_kafka"}}
JDBC 连接的数据库数据源
input {jdbc {# mysql 数据库地址jdbc_connection_string => "jdbc:mysql://172.16.32.14:3306/test"# 用户名和密码jdbc_user => "root"jdbc_password => "Elastic123"# 驱动 jar 包,如果自行安装部署 logstash 需要下载该 jar,logstash 默认不提供jdbc_driver_library => "/usr/local/services/logstash-5.6.4/lib/mysql-connector-java-5.1.40.jar"# 驱动类名jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_paging_enabled => "true"jdbc_page_size => "50000"# 执行的sql 文件路径+名称#statement_filepath => "test.sql"# 执行的sql语句statement => "select * from test_es"# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新schedule => "* * * * *"type => "jdbc"}}output {elasticsearch {hosts => ["http://172.16.0.30:9200"]index => "test_mysql"document_id => "%{id}"}}
使用 Beats 接入 ES 集群
Beats 包含多种单一用途的采集器,这些采集器比较轻量,可以部署并运行在服务器中收集日志、监控等数据,相对 logstashBeats 占用系统资源较少。
Beats 包含用于收集文件类型数据的 FileBeat、收集监控指标数据的 MetricBeat、收集网络包数据的 PacketBeat 等,用户也可以基于官方的 libbeat 库根据自己的需求开发自己的 Beats 组件。
CVM 中访问 ES 集群
1. 安装部署 filebeat。
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.4-linux-x86_64.tar.gztar xvf filebeat-5.6.4.tar.gz
2. 配置 filebeat.yml。
3. 执行 filebeat。
nohup ./filebeat 2>&1 >/dev/null &
Docker 中访问 ES 集群
自建 Docker 集群
1. 拉取 filebeat 官方镜像。
docker pull docker.elastic.co/beats/filebeat:5.6.9
2. 根据数据源类型自定义配置文件
*.conf, 放置在/usr/share/logstash/pipeline/ 目录下,目录可自定义。3. 运行 filebeat。
docker run docker.elastic.co/beats/filebeat:5.6.9
使用腾讯云容器服务
使用腾讯云容器服务部署 filebeat 的方式和部署 logstash 类似,镜像可以使用腾讯云官方提供的 filebeat 镜像。
配置文件说明
配置 filebeat.yml 文件,内容如下:
// 输入源配置filebeat.prospectors:- input_type: logpaths:- /usr/local/services/testlogs/*.log// 输出到 ESoutput.elasticsearch:# Array of hosts to connect to.hosts: ["172.16.0.39:9200"]

 是
是
 否
否
本页内容是否解决了您的问题?