- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
数据管理对 Elasticsearch Service 集群中的索引,提供了多项监控指标,用以监测索引的情况,如存储、写入、查询等。您可以根据这些指标实时了解索引的使用情况,针对可能存在的风险及时处理,保障索引的使用。本文为您介绍通过数据管理查看监控数据的操作。
操作步骤
1. 登录 Elasticsearch Service 控制台。
2. 在数据管理选择对应的集群,在索引列表单击索引名称,进入索引基础信息页面。
3. 选择监控数据页面,可以查看索引整体的使用情况。
监控数据
监控指标涵盖存储容量、总分片数、写入速度、写入延迟、查询速度、查询延迟六大维度。
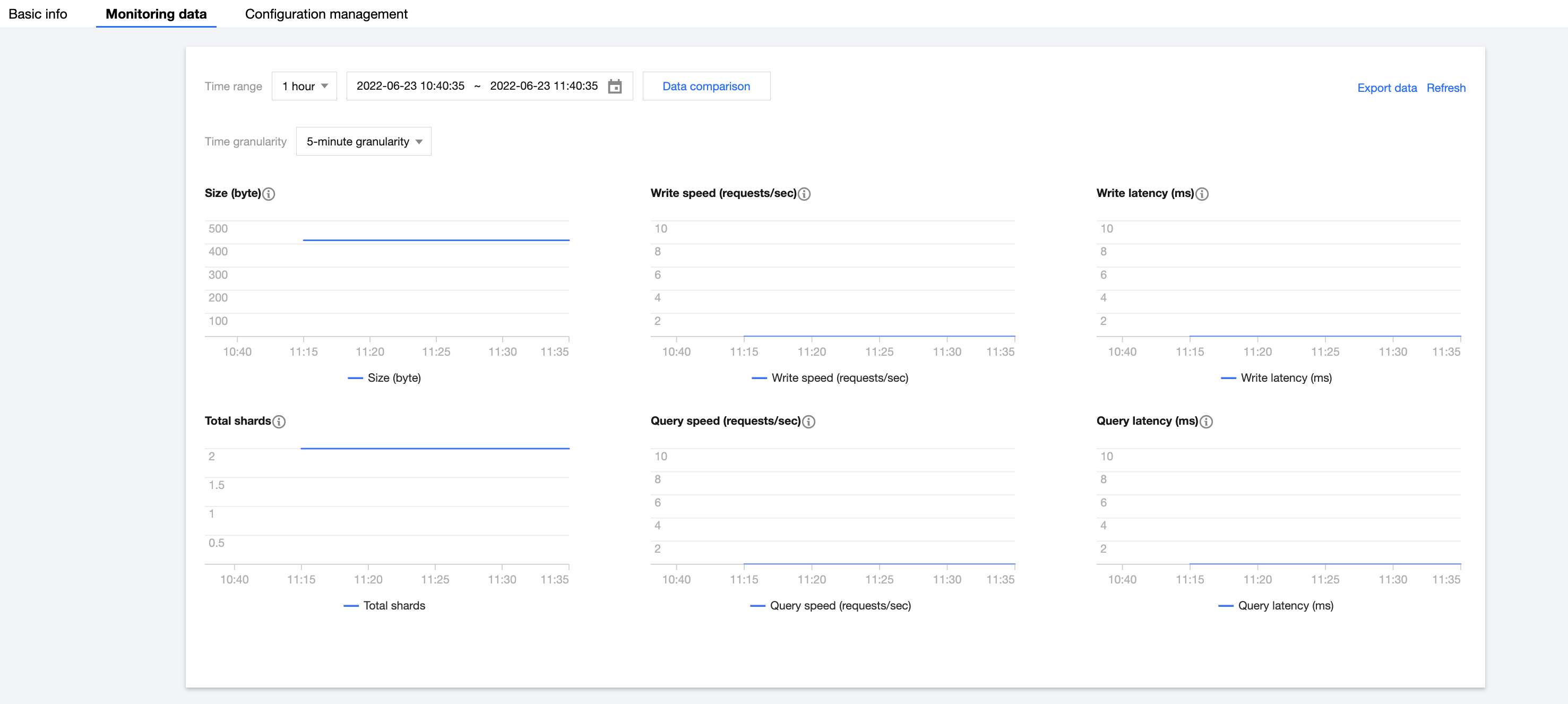
指标含义及说明
所有指标的统计周期均为5分钟,即每5分钟对索引的指标采集1次。具体各指标含义说明如下:
监控指标 | 统计方式 | 详情 |
存储容量 | 每单位统计周期内,索引存储容量的平均值。 | 该值为单个索引或者自治索引所有后备索引存储容量总和,您可根据该值查看索引存储量变化。 |
总分片数 | 每单位统计周期内,索引中分片数量的平均值。 | 该值为单个索引或者自治索引所有后备索引所有分片数总和,包含主副分片 |
写入速度 | 每单位统计周期内,索引或自治索引接收到的每秒 index 次数的平均值。索引每秒 index 请求次数计算规则:每隔一个统计周期(5分钟)记录一次索引历史所有分片 index 总次数(_cat/shard?h=indexing.index_total),取相邻两次索引 index 总次数的差值,即一个周期内的绝对值并进行计算:index 次数 / 300秒,得出统计周期内每秒 index 请求次数的平均值。 | - |
查询速度 | 每单位统计周期内,索引或自治索引接收到的每秒 search 次数的平均值。索引每秒 search 请求次数计算规则:每隔一个统计周期(5分钟)记录一次索引历史所有分片 search 总次数(_cat/shard?h=search.query_total),取相邻两次索引 search 总次数的差值,即一个周期内的绝对值并进行计算:search 次数 / 300秒,得出统计周期内每秒 search 查询次数的平均值。 | - |
写入延迟 | 写入延迟(index_latency),指单次 index 请求平均耗时(ms/次)。单次 index 请求平均耗时计算规则:每隔一个统计周期(5分钟)记录一次索引的两个指标,索引历史所有分片 index 总耗时(_cat/shard?h=indexing.index_time)和 索引历史所有分片 index 总次数(_cat/shard?h=indexing.index_total),取相邻两次记录的差值,即一个周期内的绝对值并进行计算:index 耗时 / index 次数,得出统计周期内单次 index 平均耗时。 | 写入延迟,是指单个文档写入平均耗时。写入延迟过高时,建议调大索引分片数或增加集群节点规格或节点个数。 |
查询延迟 | 查询延迟(search_latency),指单次 query 请求平均耗时(ms/次)。单次 search 请求平均耗时计算规则:每隔一个统计周期(5分钟)记录一次索引的两个指标,索引历史所有分片 search 总耗时(_cat/shard?h=search.query_time)和 索引历史所有分片 search 总次数(_cat/shard?h=search.query_total),取相邻两次记录的差值,即一个周期内的绝对值并进行计算:search 耗时 / search 次数,得出统计周期内单次 search 平均耗时。 | 查询延迟,是指单个查询平均耗时。查询延迟过高时,建议结合查询profile做查询优化或增加集群节点规格或节点个数。 |

 是
是
 否
否
本页内容是否解决了您的问题?