- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- DeleteIndex
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
- 新版介绍
- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- DeleteIndex
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
- 新版介绍
问题现象
集群所有节点 CPU 都很高,但读写都不是很高。具体表现可以从 kibana 端 Stack Monitoring 监控页面看到: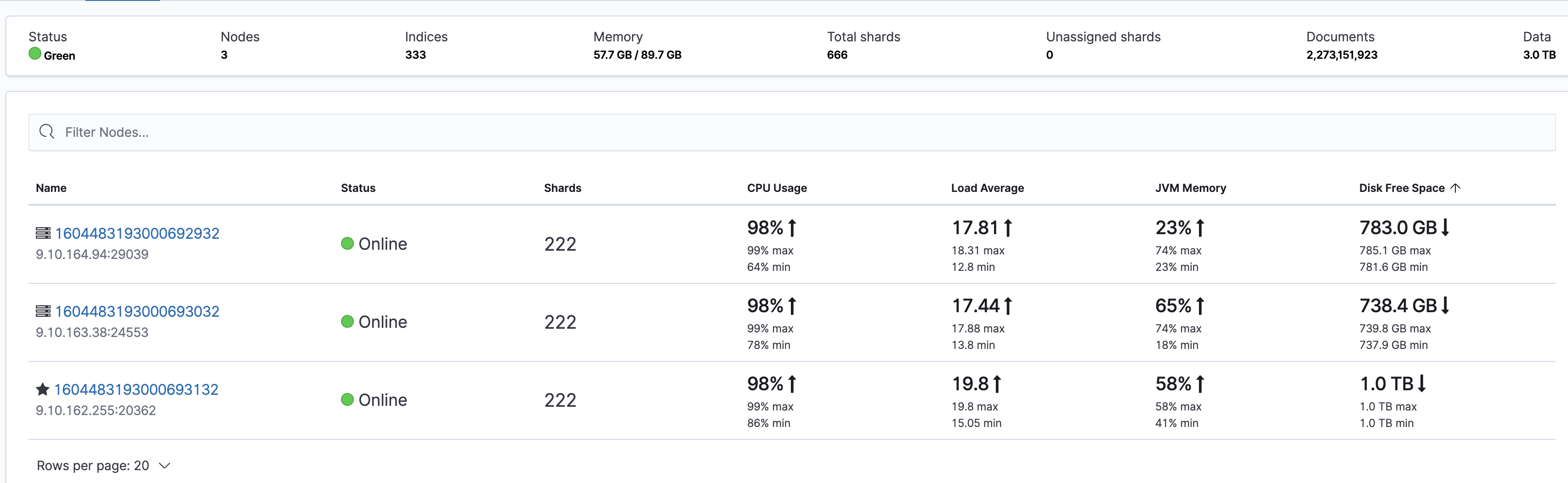
另外也可以从 ES 控制台 UI 的节点监控页面看到各节点的 CPU 使用率情况: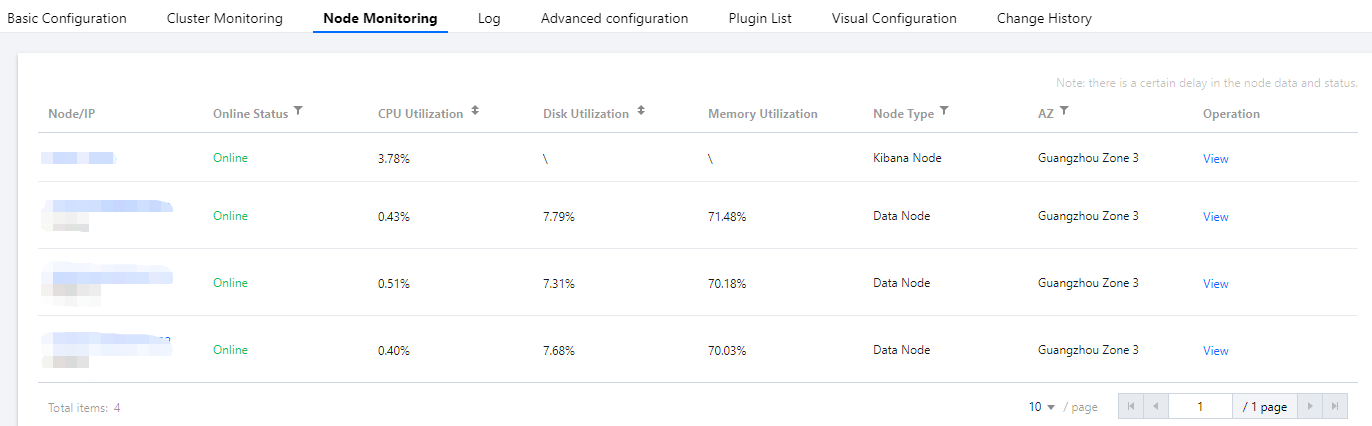
出现这种情况,由于表面上看集群读写都不高,导致很难快速从监控上找到根因。所以需要细心观察,从细节中找答案,下面我们介绍几种可能出现的场景以及排查思路。
说明:对于个别节点 CPU 使用率远高于其他节点,这种情况较为常见,多数是因为集群使用不当导致的负载不均,可参考 出现集群负载不均的问题如何解决。
问题定位和解决方案
查询请求较大导致 CPU 飙高
这种情况比较常见,可以从监控上找到线索。通过监控可以发现,查询请求量的波动与集群最大 CPU 使用率是基本吻合的。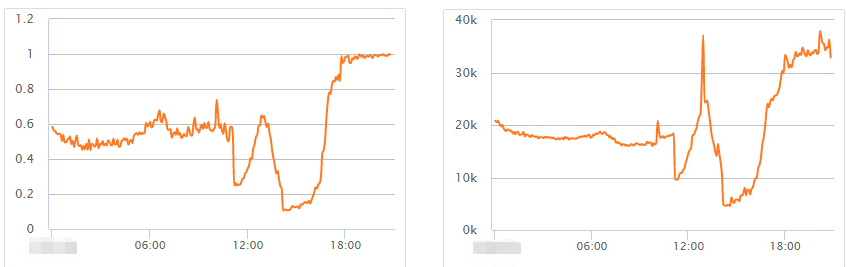
进一步确认问题需要开启集群的慢日志收集,具体可参考 查询集群日志。从慢日志中,可以得到更多信息,例如引起慢查询的索引、查询参数以及内容。
解决方案
- 尽量避免大段文本搜索,优化查询。
- 通过慢日志确认查询慢的索引,对于一些数据量不大的索引,设置少量分片多副本,例如1分片多副本,以此来提高查询性能。
写入请求导致 CPU 飙高
通过监控来观察到 CPU 飙高与写入相关,然后开启集群的慢日志收集,确认写入慢的请求,进行优化。也可以通过获取hot_threads信息来确认什么线程在消耗 CPU:
curl http://9.15.49.78:9200/_nodes/hot_threads
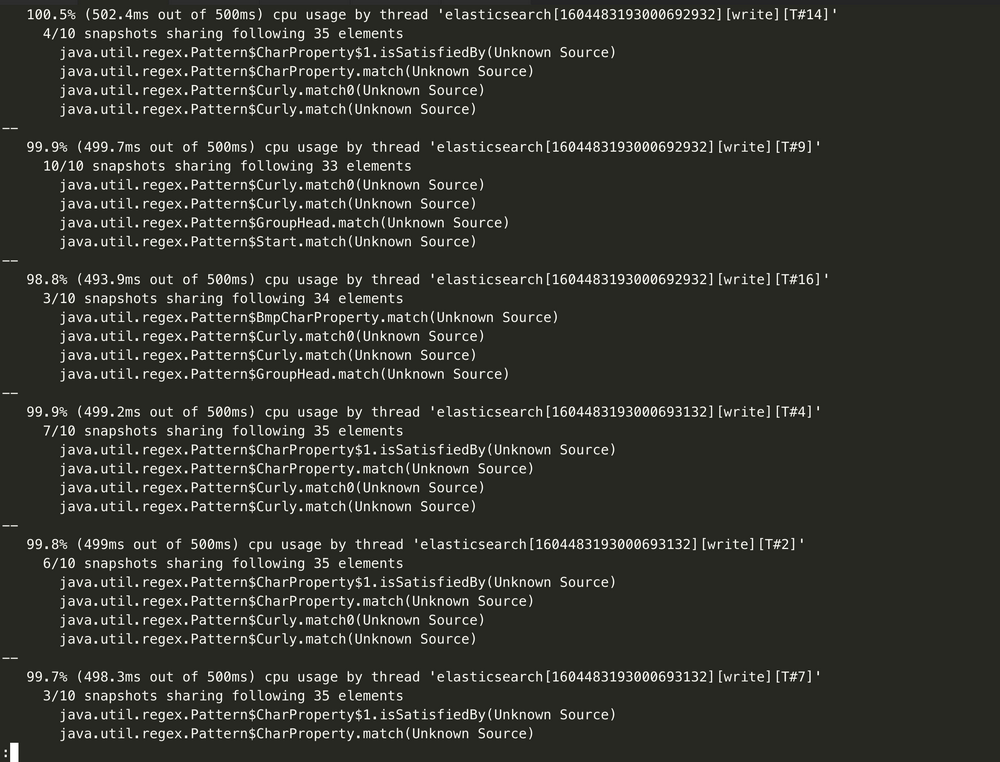
例如,这里发现的是有大量 ingest pipeline 操作,而 ingest 操作是十分消耗资源的。
解决方案
如遇到上面这种问题,则需要业务方根据实际情况来优化。排查该类问题的关键点,在于善用集群的监控指标来快速判断问题的方向,再配合集群日志来定位问题的根因,才能快速地解决问题。

 是
是
 否
否
本页内容是否解决了您的问题?