- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
集群状态为什么会异常?
集群状态在什么情况下发生 RED 和 YELLOW:
当集群存在未分配的主索引分片,集群状态会为 RED。该情况影响索引读写,需要重点关注。
当集群所有主索引分片都是已分配的,但是存在未分配的副本索引分片,集群状态则会 YELLOW。该情况不影响索引读写,一般会自动恢复。
查看集群状态
使用 kibana 开发工具,查看集群状态:
GET /_cluster/health
这里可以看到,当前集群状态为 red,有9个未分配的分片。
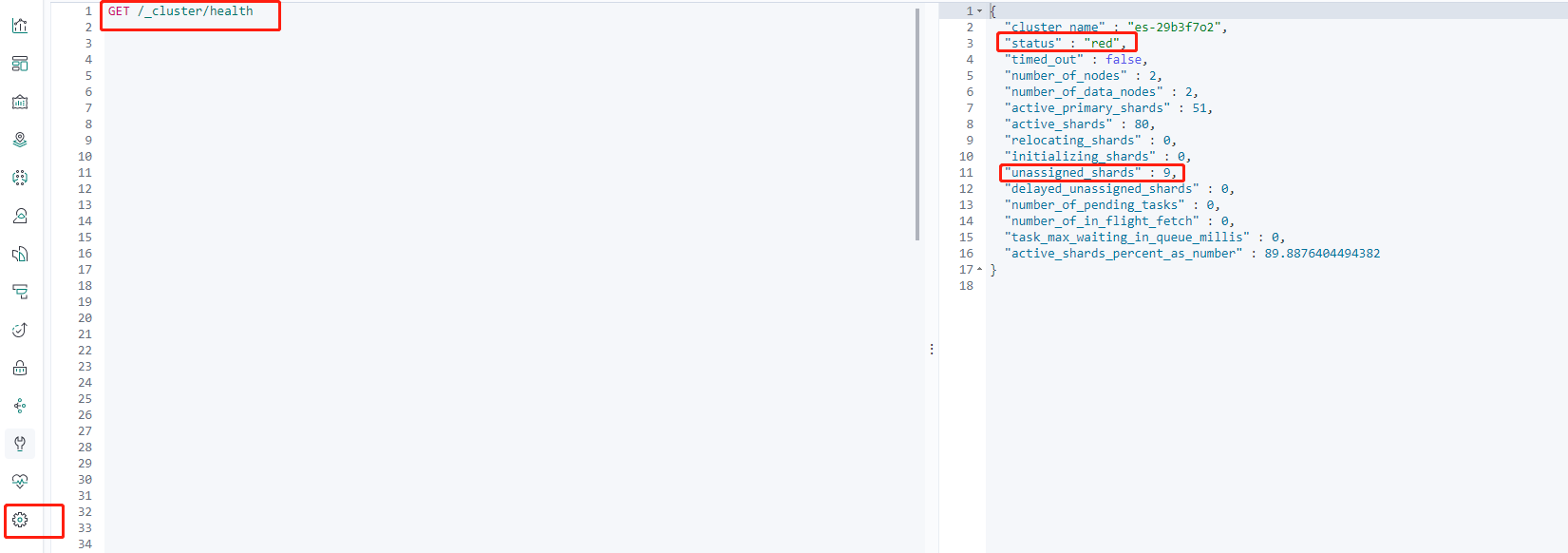
ES 健康接口返回内容官方解释:
指标 | 含义 |
cluster_name | 集群的名称 |
status | 集群的运行状况,基于其主要和副本分片的状态。状态为: green:所有分片均已分配 yellow:所有主分片均已分配,但未分配一个或多个副本分片。如果群集中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用 red:未分配一个或多个主分片,因此某些数据不可用。在集群启动期间,这可能会短暂发生,因为已分配了主要分片 |
timed_out | 如果 false 响应在 timeout 参数指定的时间段内返回(30s默认情况下) |
number_of_nodes | 集群中的节点数 |
number_of_data_nodes | 作为专用数据节点的节点数 |
active_primary_shards | 活动主分区的数量 |
active_shards | 活动主分区和副本分区的总数 |
relocating_shards | 正在重定位的分片的数量 |
initializing_shards | 正在初始化的分片数 |
unassigned_shards | 未分配的分片数 |
delayed_unassigned_shards | 其分配因超时设置而延迟的分片数 |
number_of_pending_tasks | 尚未执行的集群级别更改的数量 |
number_of_in_flight_fetch | 未完成的访存数量 |
task_max_waiting_in_queue_millis | 自最早的初始化任务等待执行以来的时间(以毫秒为单位) |
active_shards_percent_as_number | 群集中活动碎片的比率,以百分比表示 |
问题分析
当集群状态异常时,需要重点关注 unassigned_shards 没有正常分配的分片,这里举例说明其中一种场景。
找到异常索引
查看索引情况,并根据返回找到状态异常的索引。
GET /_cat/indices

查看详细的异常信息
GET /_cluster/allocation/explain
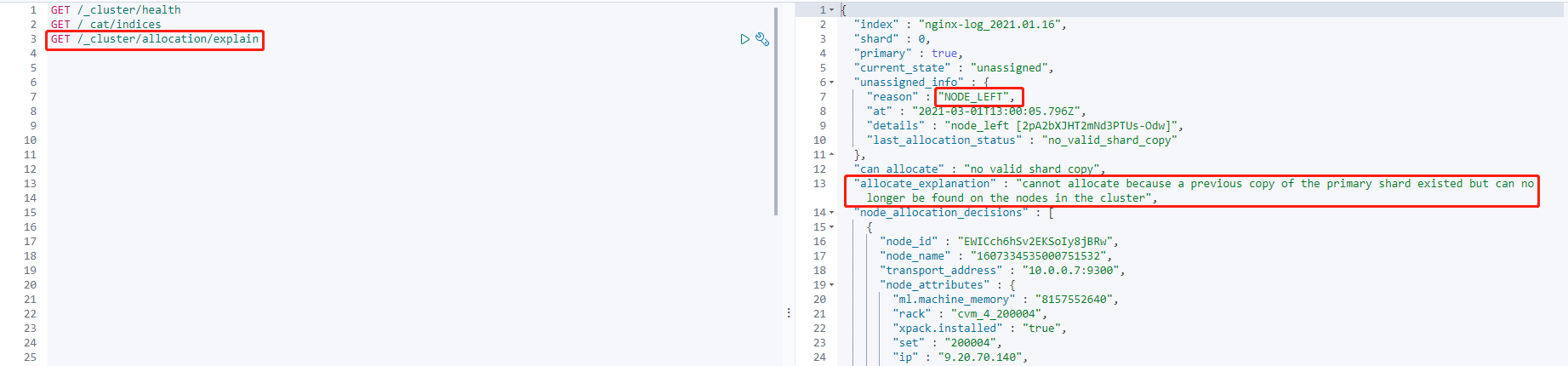
这里通过异常信息可以看出:
1. 主分片当前处于未分配状态(
current_state),发生这个问题的原因是因为分配了该分片的节点已从集群中离开(unassigned_info.reason)。2. 上述问题发生后,分片无法自动分配分片的原因是集群中没有该分片的可用副本(
can_allocate)。3. 同时也给出了更详细的信息(
allocate_explanation)。这种情况发生的原因是因为集群有节点下线,导致主分片已没有任何可用的分片数据,当前唯一能做的事就是等待节点恢复并重新加入集群。
注意:
某些极端场景,例如单副本集群的分片发生了损坏,或是文件系统故障导致该节点被永久移除,而此时只能接受数据丢失的事实,并通过 reroute commends 来重新分配空的主分片。为了尽量避免这种极端的场景,建议合理设计索引分片,不要给索引设置单副本。这里所谓的单副本,指的是索引有主分片,但没有副本分片,或称之为0副本。合理设计索引分片,可以将集群的总分片控制在一个很健康的规模,可以在保证高可用的情况下更加充分地利用集群分布式的特性,提高集群整体性能。
分片未分配(unassigned_info.reason)的所有可能
可通过如下分析方式初步判断集群产生未分配分片的原因,一般都可以在 allocation explain api 中得到想要的答案。
说明:
reason | 原因 |
INDEX_CREATED | 索引创建,由于 API 创建索引而未分配的 |
CLUSTER_RECOVERED | 集群恢复,由于整个集群恢复而未分配 |
INDEX_REOPENED | 索引重新打开 |
DANGLING_INDEX_IMPORTED | 导入危险的索引 |
NEW_INDEX_RESTORED | 重新恢复一个新索引 |
EXISTING_INDEX_RESTORED | 重新恢复一个已关闭的索引 |
REPLICA_ADDED | 添加副本 |
ALLOCATION_FAILED | 分配分片失败 |
NODE_LEFT | 集群中节点丢失 |
REROUTE_CANCELLED | reroute 命令取消 |
REINITIALIZED | 重新初始化 |
REALLOCATED_REPLICA | 重新分配副本 |

 是
是
 否
否
本页内容是否解决了您的问题?