- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
- 新手指引
- 产品动态
- 产品简介
- 购买指南
- ES 内核增强
- 快速入门
- ES Serverless 服务指南
- 数据应用指南
- ES 集群指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Instance APIs
- CreateIndex
- DeleteIndex
- DescribeInstanceLogs
- UpdateInstance
- RestartInstance
- DescribeInstances
- DeleteInstance
- CreateInstance
- DescribeInstanceOperations
- UpgradeLicense
- UpgradeInstance
- UpdatePlugins
- RestartNodes
- RestartKibana
- UpdateRequestTargetNodeTypes
- GetRequestTargetNodeTypes
- DescribeViews
- UpdateDictionaries
- UpdateIndex
- DescribeIndexMeta
- DescribeIndexList
- Making API Requests
- Data Types
- Error Codes
- 常见问题
- 词汇表
问题现象
集群在某些情况下会出现写入拒绝率(bulk reject)/查询拒绝率(search reject)增大的现象,具体表现为 bulk 写入/查询时,会有类似以下报错:
报错一:
[2019-03-01 10:09:58][ERROR]rspItemError: {"reason":"rejected execution of org.elasticsearch.transport.TransportService$7@5436e129 on EsThreadPoolExecutor[bulk, queue capacity = 1024, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@6bd77359[Running, pool size = 12, active threads = 12, queued tasks = 2390, completed tasks = 20018208656]]","type":"es_rejected_execution_exception"}
报错二:
[o.e.a.s.TransportSearchAction] [1590724712002574732] [31691361796] Failed to execute fetch phaseorg.elasticsearch.transport.RemoteTransportException: [1585899116000088832][10.0.134.65:22624][indices:data/read/search[phase/fetch/id]]Caused by: org.elasticsearch.common.util.concurrent.EsRejectedExecutionException: rejected execution of org.elasticsearch.common.util.concurrent.TimedRunnable@63779fac on QueueResizingEsThreadPoolExecutor[name = 1585899116000088832/search, queue capacity = 1000, min queue capacity = 1000, max queue capacity = 1000, frame size = 2000, targeted response rate = 1s, task execution EWMA = 2.8ms, adjustment amount = 50, org.elasticsearch.common.util.concurrent.QueueResizingEsThreadPoolExecutor@350da023[Running, pool size = 49, active threads = 49, queued tasks = 1000, completed tasks = 57087199564]]
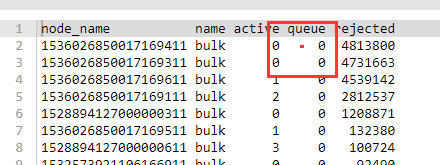
可在云监控中看到集群写入/查询拒绝率增大。
也可在 kibana 控制台,通过命令查看正在拒绝或者历史拒绝的个数。
GET _cat/thread_pool/bulk?s=queue:desc&vGET _cat/thread_pool/search?s=queue:desc&v
一般默认队列是1024,如果 queue 下有1024,说明这个节点有 reject 的现象。
问题定位
1. 检查 bulk 请求的 body 大小是否不合理。单个 bulk 请求的大小在10MB以内比较合适,如过大,则会导致单个 bulk 请求处理时间过长,导致队列排满;如过小,则会导致 bulk 请求数过多,导致队列排满。
2. 检查写入 QPS 和集群配置是否匹配,经验值为在4C16G 3节点集群上分片分布均衡时可以承担约2W - 3W QPS 的写入,但如果还有较多的查询请求时 QPS 会更低,具体可以通过压测确定集群最高能承受的 QPS 写入量,选择合适的配置。
3. 检查分片(shard)数据量是否过大。分片数据量过大,有可能引起 Bulk Reject,建议单个分片大小控制在20GB - 50GB左右。可在 kibana 控制台,通过命令查看索引各个分片的大小。
GET _cat/shards?index=index_name&v

检查分片数是否分布不均匀
集群中的节点分片分布不均匀,有的节点分配的 shard 过多,有的分配的 shard 少。
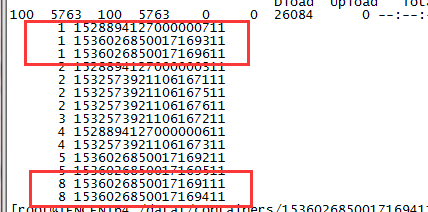
通过 ES API,查看集群各个节点的分片个数。
GET /_cat/shards?index={index_name}&s=node,store:desc
结果如下图(第一列为分片个数,第二列为节点 ID),有的节点分片为1,有的为8,分布极不均匀。
解决方案
1. 设置分片大小
分片大小可以通过 index 模版下的 number_of_shards 参数进行配置(模板创建完成后,再次新创建索引时生效,老的索引不能调整)。
2. 调整分片数据不均匀
临时解决方案
如果发现集群有分片分配不均的现象,可通过设置 routing.allocation.total_shards_per_node 参数,动态调整某个 index 解决,详情可参考 Total Shards Per Node。
注意:
total_shards_per_node 要留有一定的 buffer,防止机器故障导致分片无法分配(例如10台机器,索引有20个分片,则 total_shards_per_node 设置要大于2,可以取3)。
PUT {index_name}/_settings{"settings": {"index": {"routing": {"allocation": {"total_shards_per_node": "3"}}}}}
索引生产前设置:通过索引模板,设置其在每个节点上的分片个数。
PUT _template/{template_name}{"order": 0,"template": "{index_prefix@}*", //要调整的 index 前缀"settings": {"index": {"number_of_shards": "30", //指定 index 分配的 shard 数,可以根据一个 shard 30GB左右的空间来分配"routing.allocation.total_shards_per_node":3 //指定一个节点最多容纳的 shards 数}},"aliases": {}}

 是
是
 否
否
本页内容是否解决了您的问题?