You can usually roll over Elasticsearch indices to store time series data continuously generated by logging and monitoring components. This method implements basic data management features; however, to achieve complete index management, you still need to use it in combination with index template, index lifecycle management, and index alias features. In addition, it also incurs index maintenance costs. For example, to avoid the impact of insufficient shards on the write availability, the need to roll over a new index in case of a single-replica index node failure, and the impact of too many shards on the cluster stability, you must reasonably estimate the shard quantity before index creation.In order to solve these problems, the ES team has developed the autonomous index feature, a one-stop index management solution for time series data use cases such as log analysis and Ops monitoring. To use this feature, you only need to create an autonomous index in a few simple steps and specify a single autonomous index object for read and write requests. Automatic shard quantity fine-tuning and complete index lifecycle management are embedded to enhance the index usability and reduce the index maintenance costs. This document describes the use cases, strengths, and basic concepts of the autonomous index feature.
Use Cases
The autonomous index feature is suitable for log analysis, Ops monitoring, and other time series data use cases, such as log search and analysis, metric monitoring and analysis, as well as collection, monitoring, and analysis of smart IoT device data.
Strengths
Ease of use: An autonomous index can be created with a single command and can be used for read and write operations. It has many features, such as index rollover, cold/hot data migration, and deletion upon expiry, for you to configure, so you don't need to manage index lifecycle management (ILM) policies and index templates.
Ease of maintenance: The autonomous index feature can automatically adjust the number of index shards in response to the changes in the business write load and roll over a new index in case of a failure. This significantly reduces the index maintenance costs.
Prerequisites
The autonomous index feature is naturally applicable to clusters on v7.14.2 created after June 1, 2022 and is supported for older clusters on this version after a rolling cluster restart. To use this feature in clusters on earlier versions, upgrade them to v7.14.2 first.
Each document written to an autonomous index must contain a time-type field with the same field name as defined in the autonomous index. If not specified during autonomous index creation, the field name is @timestamp by default.
Basic Concepts
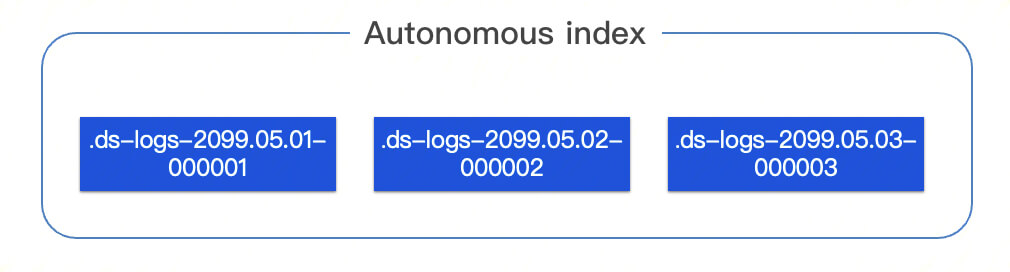
Autonomous index and backing index
An autonomous index is implemented through enhancements to the Elasticsearch DataStream kernel. It is internally associated with one or more hidden backing indices (i.e., general Elasticsearch indices), so you only need to focus on and manipulate it.
Write mode
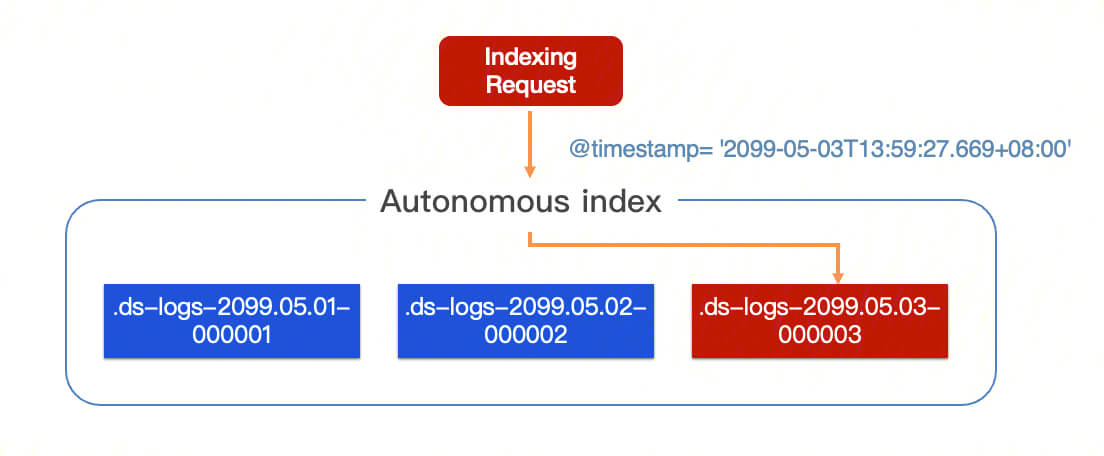
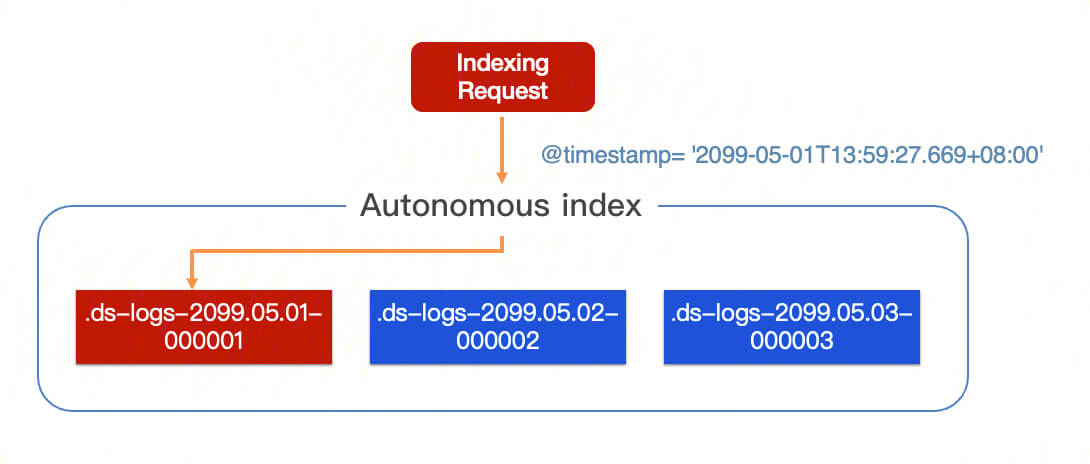
Autonomous indexing supports two data writing modes: append writing and time-partitioned writing. In the append writing mode, data is written to the latest backup index, making it suitable for log scenarios. In the time-partitioned writing mode, data is written to the corresponding backup index based on the time field, making it ideal for metric scenarios.
Write request
Write requests committed to an autonomous index will be routed to the latest backing index in append write mode or the backing index corresponding to the data time in shard-based write by time mode.
1.1 Append write
1.2 Shard-based write by time
Query request
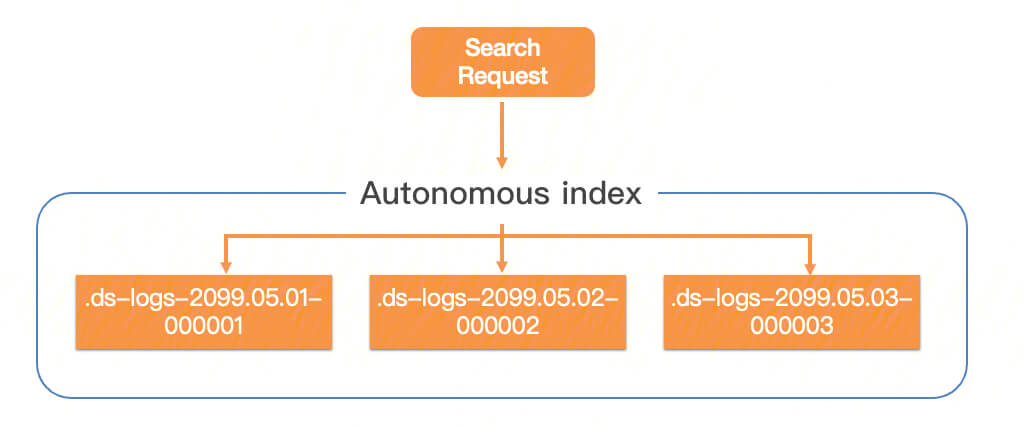
Query requests committed to an autonomous index will be forwarded to all backing indices.
Rolling update
A rolling update will create a new backing index for the autonomous index. Currently, two rolling update methods are supported:
1.1 Automatic rolling update: It is implemented through the built-in feature of the autonomous index. When the rollover cycle condition configured for the autonomous index is met, or when the node of the backing index currently providing the write service fails, the new backing index will be rolled over automatically.
1.2 Manual rolling update: It is implemented through the rollover API.
Index lifecycle management
This is implemented through Elasticsearch's ILM feature. You can directly configure ILM policies for an autonomous index with no need to manage policies and associated index templates. Elasticsearch's all ILM policies are supported.
Index shard quantity management
This is implemented through the built-in feature of the autonomous index. It promptly and stably adjusts the number of index shards in response to the changes in the real-time write load. You don't need to worry about the write availability issue caused by insufficient index shards as well as the issue caused by too many cluster shards.
Directions
ES allows you to use and manage autonomous indices on easy-to-use GUIs. For more information, see Creating Autonomous Index.
Common APIs
1. Autonomous index creation:
PUT /_data_stream/indexname
{
"mappings":{
"properties":{
}
},
"settings":{
},
"policy":{
"warm.actions.migrate":{},
"warm.min_age":"3d"
},
"options":{
"timestamp_field":"@timestamp",
"expire.max_age":"100d",
"expire.max_size":"1TB",
"pre_create.enable": true,
"rollover.max_age":"1h",
"rollover.dynamic": true,
"shard_num.dynamic": true,
"write_mode":"time_partition"
}
}
mappings
It is optional and used to set the ES index mapping like the mapping in an Elasticsearch index.
settings
It is optional and used to set the ES index settings like the settings in an Elasticsearch index.
policy
It is optional and used to set the ILM policy like the ILM in an Elasticsearch index, but in a simplified way.
options
Autonomous index attributes, including:
timestamp_field: Time field, which is customizable and optional and will be @timestamp by default if not specified.
expire.max_age: Retention period of time range shards. The unit can be set to h (hour) or d (day). The value can be one hour at the minimum and will be 0 (i.e., not to delete) by default if not specified.
expire.max_size: Maximum size of time range shards. When this value is exceeded, historical time range shards will be eliminated. The unit can be set to b, kb, mb, gb, tb, or pb. The value will be 0 (i.e., not to eliminate) by default if not specified.
precreate.enable: Whether to enable time range shard precreation. The value is true (yes) by default.
rollover.max_age: Rollover cycle of time range shards. The unit can be set to h (hour) or d (day). This value can be 1h at the minimum and is 1d by default. -1 indicates not to roll over time range shards.
rollover.dynamic: Whether to enable the dynamic adjustment of the time range shard rollover cycle. The value is true (i.e., yes) by default.
shard_num.dynamic: Whether to enable the dynamic adjustment of the time range shard quantity. The value is true (i.e., yes) by default.
write_mode: Write mode of time range shards. Valid values: append_only (default): append write, where data will be written to the latest time range shard; time_partition: shard-based write by time, where data will be written to the time range shard corresponding to the data time.
2. Autonomous Index Delete:
DELETE /_data_stream/index_name
3. Autonomous Index Modification:
POST _data_stream/indexname/_update
{
"options":{
"expire.max_age":"30d"
}
}
----
Apart from options.timestamp_field and options.write_mode, all other properties can be modified.
After the configuration is successfully modified, the lifecycle-related configurations will take effect in all backing indices. Other configurations, such as the number of shards, number of replicas, and field mappings, will take effect only in subsequent rolled-over backing indices and will not update existing ones.
4. Autonomous Index Inquiry, consistent with the usage of ordinary index inquiries:
GET indexname/_search
5. Write, consistent with the usage of ordinary index writes, supports both bulk and doc methods:
Among them, the include_define option means that the result includes the content of self-governing index attributes. If not specified, it will be consistent with the content returned by the community DataStream.