Elasticsearch Service
- Release Notes and Announcements
- Product Announcements
- Security Announcement
- Product Introduction
- Performance
- ES Kernel Enhancement
- Getting Started
- ES Serverless Guide
- Quick Start
- Index Management
- Data Application Guide
- Elasticsearch Guide
- Cluster Scaling
- Cluster Configuration
- Plugin Configuration
- Monitoring and Alarming
- Log Query
- Practical Tutorial
- Data Migration and Sync
- Use Case Construction
- Index Configuration
- API Documentation
- Instance APIs
- Making API Requests
- FAQs

CVM Log Access

Last updated: 2024-12-04 16:01:35
Prerequisites
A Tencent Cloud account has been created. For account creation, see Signing up for Tencent Cloud.
If logging in with a sub-account, ensure that the account has read and write permissions for ES.
Operation Steps
Logging in to the Console
1. Log in to the Elasticsearch Console.
2. In the top menu bar, select Region. Currently supported regions include Beijing, Shanghai, Guangzhou, Nanjing, and Hong Kong (China).
3. In the left sidebar, choose Log Analysis under the Serverless mode.
Creating a Project Space
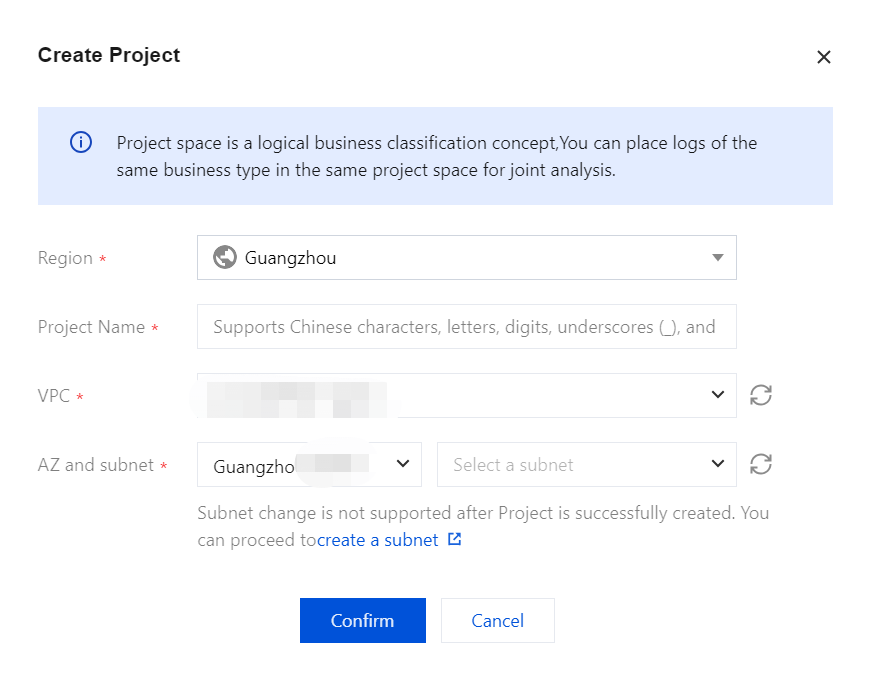
1. Click Create a project.
2. Enter a Project Name for the project, which can include 1–20 characters, consisting of Chinese characters, letters, digits, underscores, or delimiters (-).
3. Click Confirm. If the validation is successful, the project space will be created.
Note:
In ES Serverless Log Analysis, you can simply create an index, then use the API for data writing or access data sources such as CVM or TKE via the Data Access tab of the corresponding index. You can also set up data access during index creation for one-stop CVM and TKE log access. The following introduces the one-stop CVM log access process.
CVM Log Access
On the ES Serverless Log Analysis homepage, select CVM to enter the CVM Log Access page.
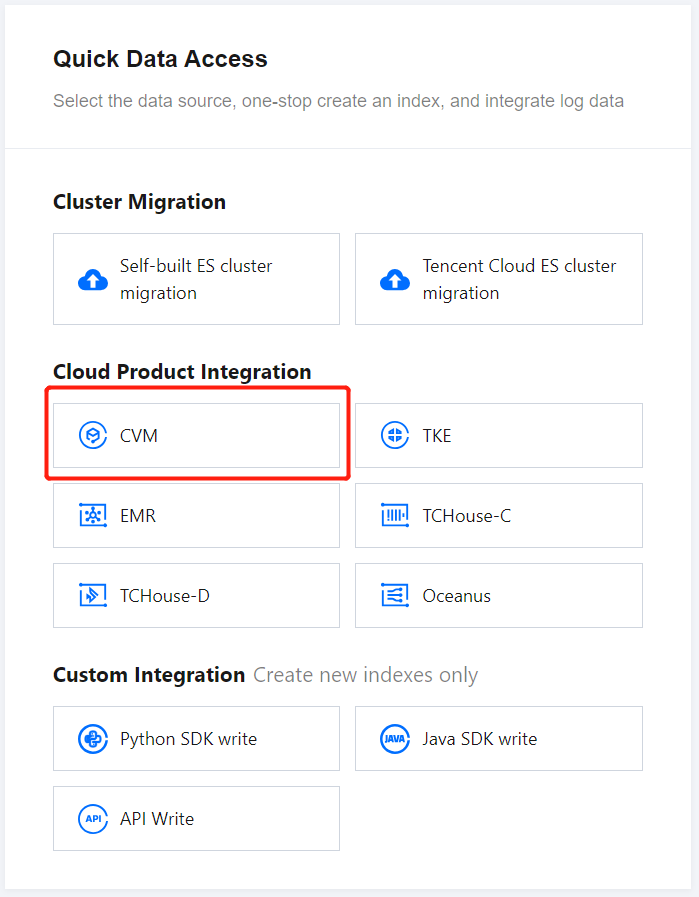
Data Source Settings
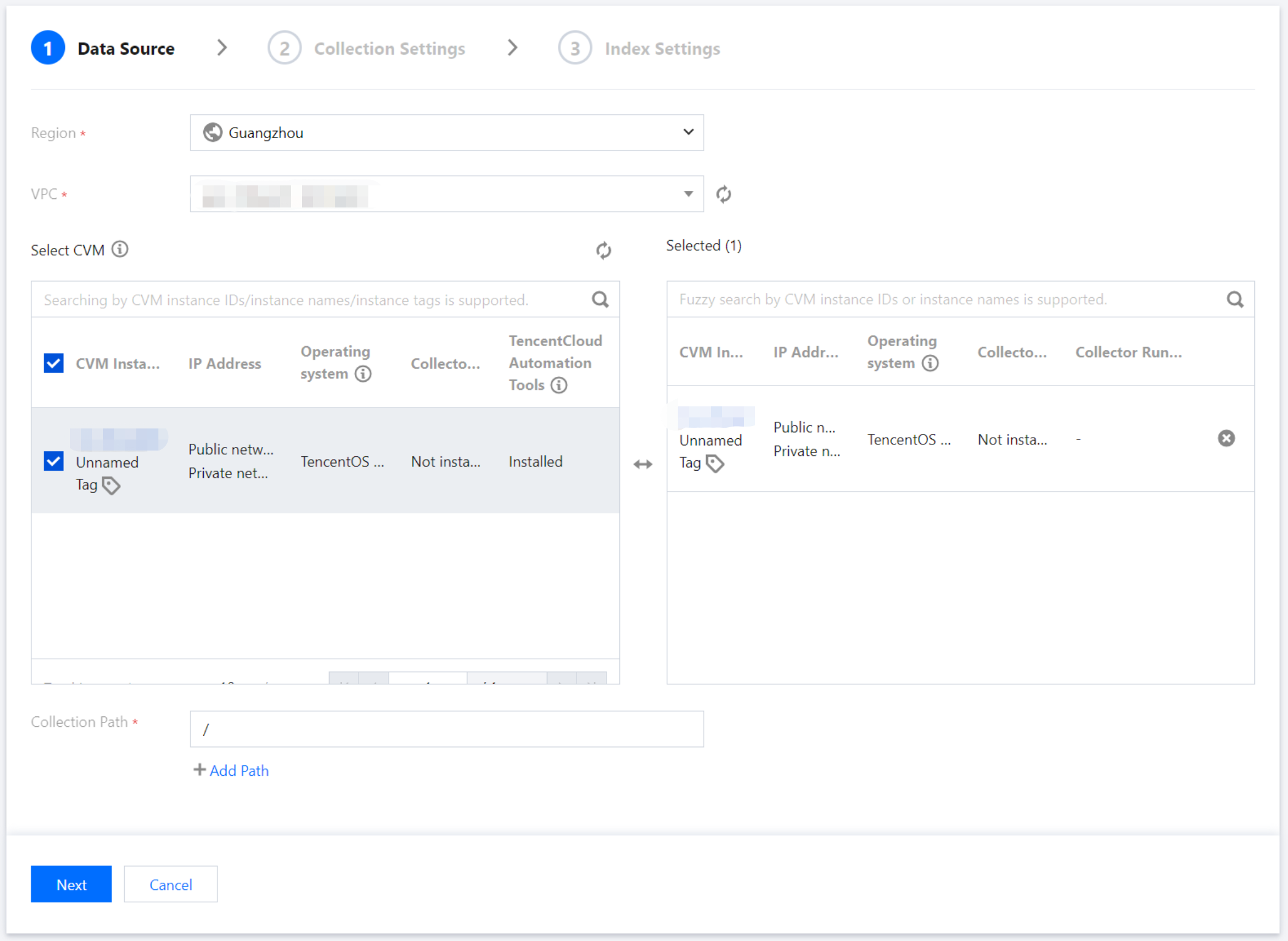
Region: Required. It represents the region where the CVM is located.
VPC: Required. It represents the private network where the CVM is located. After confirmation, the servers under this VPC will be pulled in.
Select CVM: Select the CVM instance for log collection. Currently, only Linux-based CVMs are supported, and data collection requires Installing TAT Agent.
Collection Path: Set the log directory and file names based on the location of logs on the server. Supports one or more paths. Directory and file names can be specified using exact names or wildcard patterns.
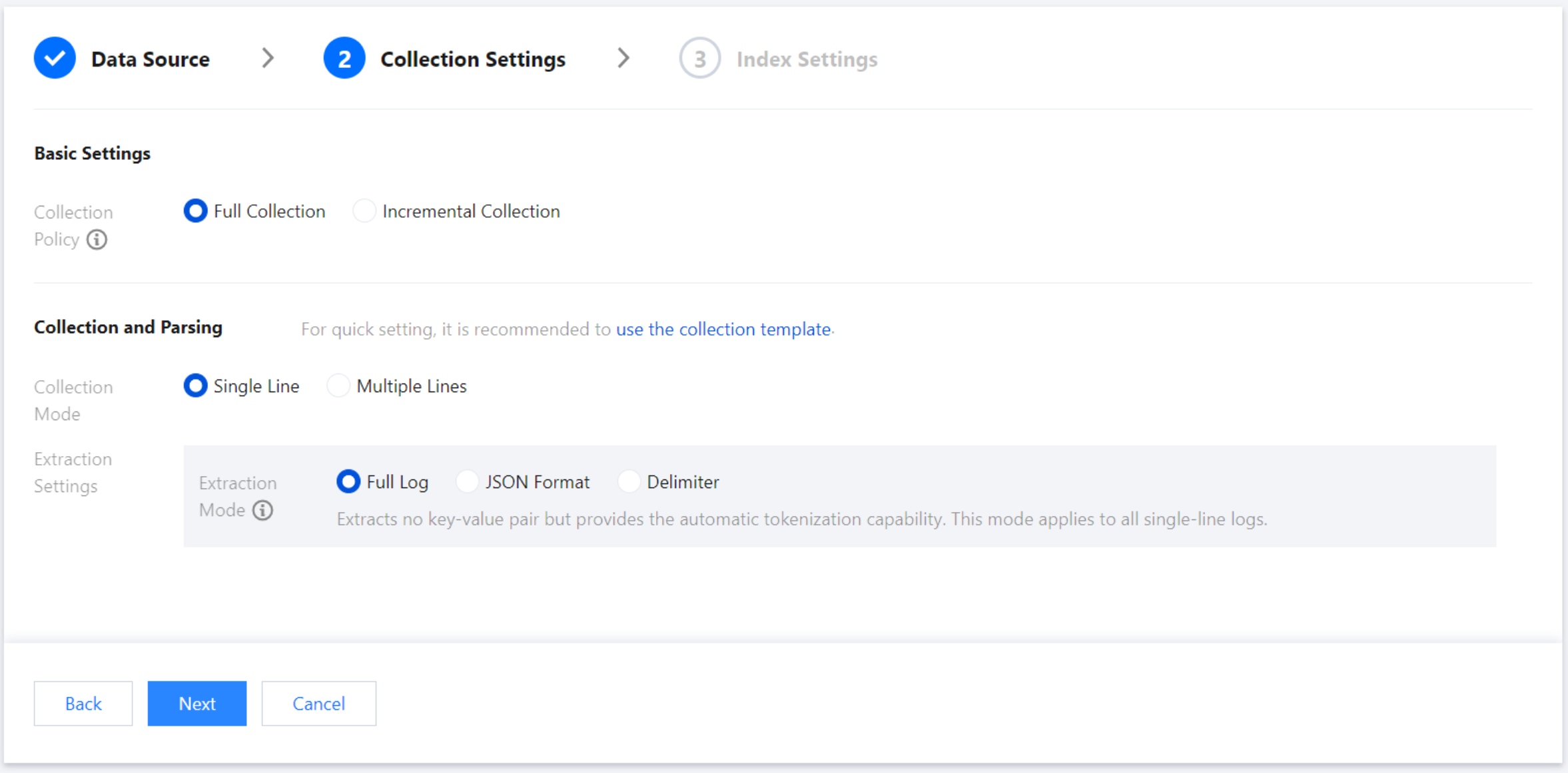
Collection Settings
Basic Settings
Collection policy: Supports both full and incremental collection. Once created, the collection policy cannot be modified. Full collection gathers historical log files as well as any logs generated after the Filebeat configuration takes effect; incremental collection only gathers logs generated after the Filebeat configuration takes effect.
Collection and Parsing
Collection Template: If you need a quick setup or trial, select a collection template based on your log output format. After confirming, you can return to the interface and replace the log sample with actual log data to quickly complete the collection parsing setup.
Collection Mode: Supports single-line and multi-line modes. Once created, the collection mode cannot be modified.
Single-line text log: Each line in the log file represents one log entry, with each log separated by a line break.
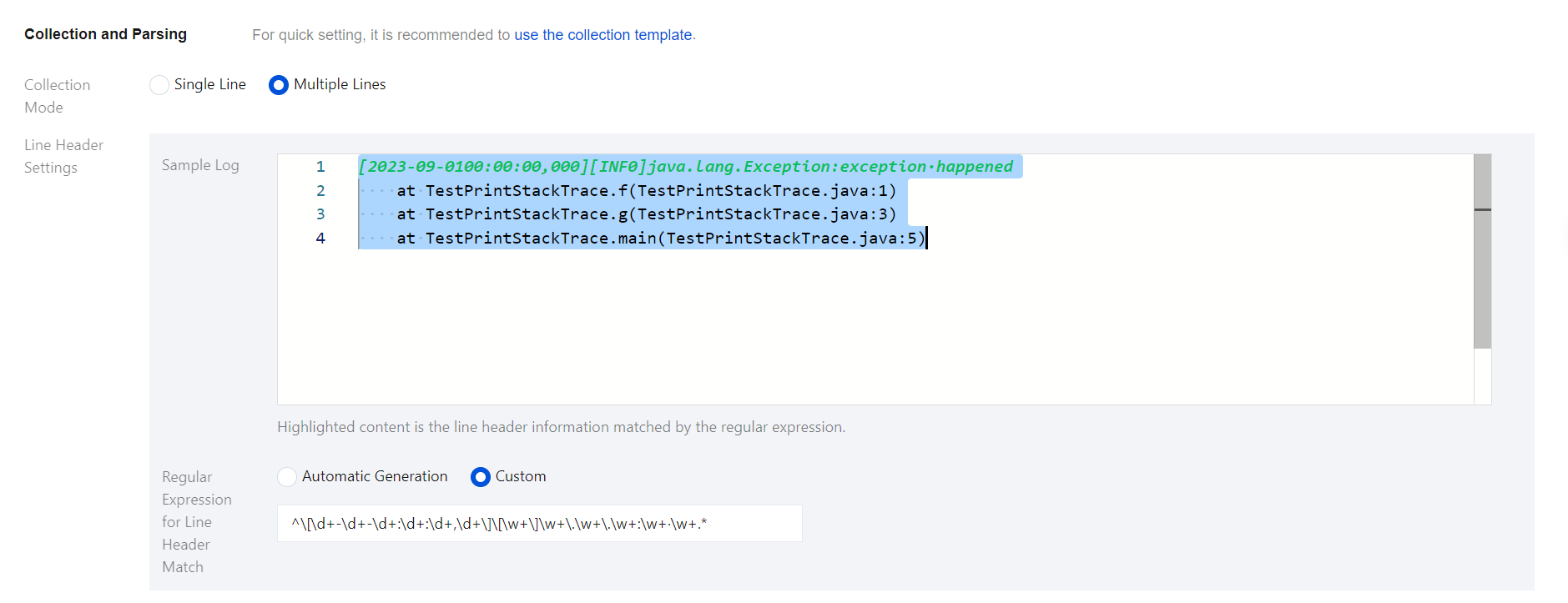
Multi-line text log: Each log entry consists of multiple lines, such as Java stack trace logs. In this mode, you need to configure a log sample and a line-start regular expression. Filebeat uses the line-start regular expression to identify the beginning of each log entry, treating unmatched parts as part of the current log until the next line start appears. After you enter a log sample, the system automatically generates a line-start regular expression by default. You can also customize the expression, with highlighted content in the input box indicating the matched line-start information.
Note:
Be sure to use logs from the actual scenarios to facilitate automatic extraction of the line-start regular expression.
Extraction Settings: You can set the extraction mode to full text log, JSON format, or delimiter. Once created, the extraction mode cannot be modified. Details are as follows:
No key-value extraction is performed on log data, and log content is stored in a field named message. You can perform retrieval and analysis using automatic word segmentation.
For example, a single-line log entry in its original format might be:
Tue Jan 01 00:00:00 CST 2023 Running: Content of processing something
The data collected in the index would be:
massage:Tue Tue Jan 01 00:00:00 CST 2023 Running: Content of processing something
For logs in standard JSON format, fields can be extracted based on the Key: Value pairs within the log.
Suppose your original JSON log entry is:
{"pid":321,"name":"App01","status":"WebServer is up and running"}
After structuring, this log entry will be transformed as follows:
{ "pid":321, "name":"App01", "status":"WebServer is up and running" }
For logs with content separated by a fixed delimiter, you can extract key-value pairs based on the specified delimiter. The delimiter can be a single character or a string and can be selected or entered in the console.
Suppose your original log entry is:
321 - App01 - WebServer is up and running
By specifying the delimiter as -, this log will be split into three fields. You can define a unique key to these fields in the extraction results, as shown below:
pid: pidname: App01status: WebServer is up and running
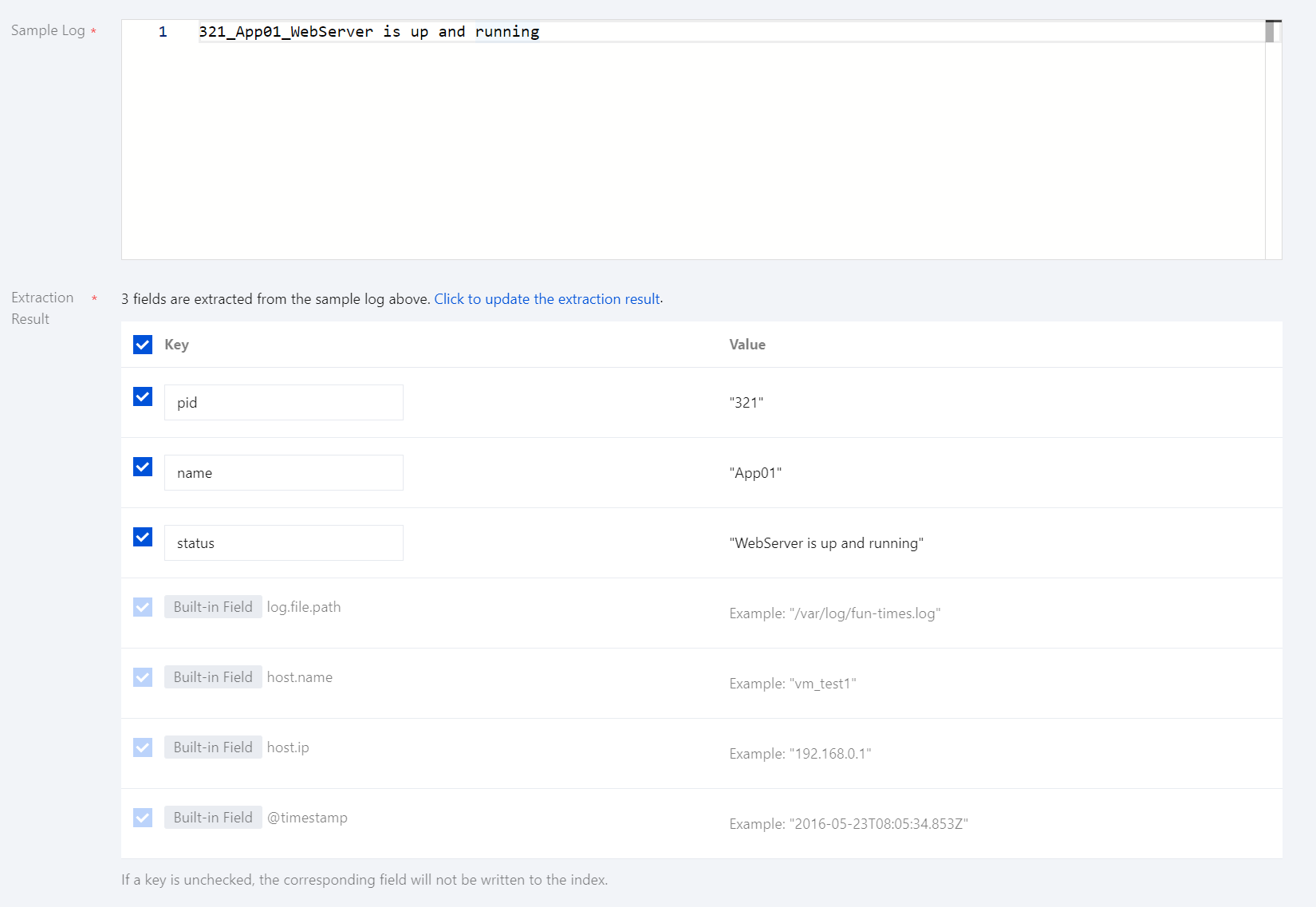
Extraction Results: If the extraction mode is set to JSON format or delimiter, you can enter a log sample, and the system will automatically extract information from it:
For JSON format, the system will automatically populate the extracted Key-Value pairs. If you deselect a field, it will not be written to the index.
For delimiter mode, the system will automatically populate the extracted Values. You can define a unique Key for each Value. If you deselect a field, it will not be written to the index.
Built-in fields: When you configure CVM log collection in the console, Filebeat writes information such as log source and timestamp into the logs as Key-Value pairs. These fields are considered built-in. If a Key name in your business log matches a built-in field name, the content from the business log field will take priority, and the corresponding built-in field will not be written to the index. The meanings of the built-in fields are as follows:
Built-in Field Name | Meaning |
log.file.path | Path where the log is stored |
host.name | Name of the server hosting the log |
host.ip | IP address of the server hosting the log |
@timestamp | Time when the log entry was collected |
Preserve original logs: When it is selected, the original log content prior to parsing will be retained in this field.
Record parsing errors: If the extraction mode is set to Delimiter, you can choose whether to log parsing errors. When it is selected, error messages will be uploaded to this field as values in case of parsing failures.
Index Settings
Project Space: You can assign indexes for the same business to a specific project space for easier management.
Index Name: Length of 1 - 100 characters. Lowercase letters, digits, and the following symbols: -, _, ;, @, &, =, !, ', %, $, ., +, (, ) are supported.
Field Map
Dynamic Generation: Enabled by default. When enabled, it automatically parses and generates field settings for the index based on written data.
Input Sample Auto-Configuration: When Dynamic Generation is disabled, you can use Input Sample Auto-Configuration to generate field mappings for the index by entering a JSON-formatted data sample. After confirmation, the platform will validate the input; if the validation is successful, the relevant fields will be mapped in the field mapping table.
Field mapping divides the original data into individual tokens based on fields (key:value) for indexing. Retrieval relies on this mapping, as detailed below:
Parameter | Description |
Field name | The field name in the written data. |
Field type | The data type of the field; the interface supports 9 types: text, date, boolean, keyword, long, double, integer, ip, and geo_point. Additional field types are supported in JSON Editing Pattern. For more details, see Official Documentation. |
Include Chinese | Enable this option if the field contains Chinese text and requires Chinese retrieval. When it is enabled, the ik_max_word tokenizer is applied to the text field by default. |
Enable indexing | When it is enabled, an index will be built for this field, allowing it to be searchable. |
Enable statistics | When it is enabled, statistical analysis can be performed on the field values, which will increase index storage. |
Time Field
The time field refers to a field with the date type in the actual data. Once the index is created, this field cannot be modified.
Note:
By default, the time field enables indexing and statistics, and these settings cannot be disabled.
Data Storage Duration:
1.1 You can set the data storage duration, with a default of 30 days, or select an option for permanent storage.
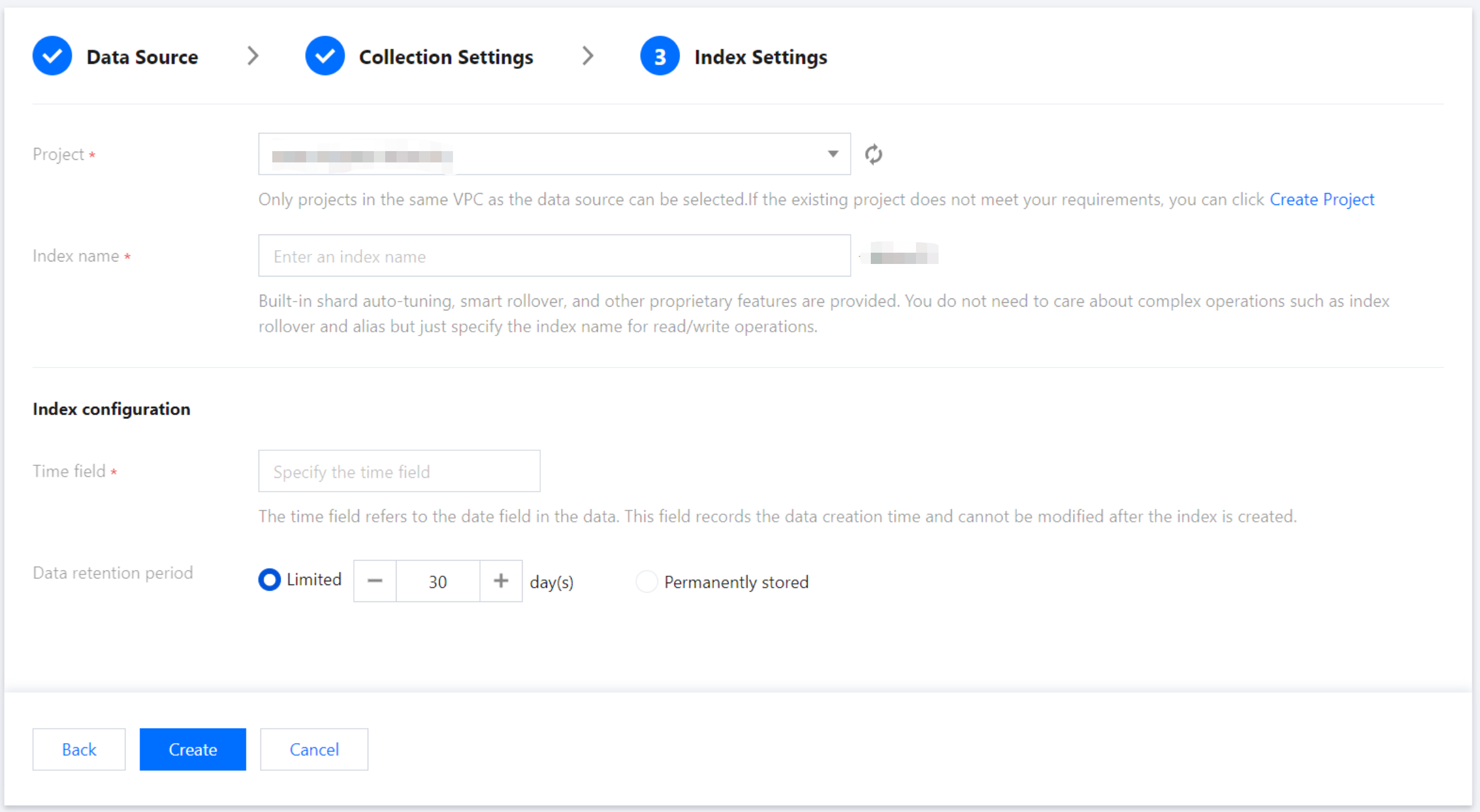
1.2 Once all information is correctly entered, click Create to complete CVM log collection.
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No