We use cookies that are necessary to provide the Tencent Cloud website. We would also like to use other cookies to improve your experience, optimise and analyse Tencent Cloud website features and usage. For more information, please refer to our Cookies Policy.
































14天试用边缘安全加速平台 EO 限时免费
- 新手指引
- 动态与公告
- 产品动态
- 公共镜像更新记录
- 公告
- 关于 CrowdStrike 安全软件导致的 Windows 蓝屏问题临时解决方法2024年07月19日
- 关于部分地域竞价实例弹性优惠公告
- 关于CentOS 7系列部分镜像pip包管理工具更新公告
- 关于 CentOS 8 终止维护公告
- 关于不再支持 SUSE 商业版镜像公告
- 关于多个可用区云服务器价格下调公告
- 关于 OrcaTerm 代理 IP 地址更替的公告
- 关于硅谷地域标准型 S3 价格调整的公告
- 腾讯云 Linux 镜像长期漏洞修复策略公告
- 关于 Ubuntu 10.04 镜像下线及存量软件源配置的公告
- 关于 Ubuntu14.04 无法启动 Tomcat 的解决方案
- 关于Windows云服务器升级Virtio网卡驱动的通知
- 关于安全组53端口配置的公告
- 关于不再支持 Windows Server 2003 系统镜像的公告
- 关于不再支持 Windows Server 2008 R2 企业版 SP1 64位系统镜像的公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 针对 CVM 的最佳实践
- 云服务器选型最佳实践
- 如何搭建网站
- 搭建环境
- 搭建网站
- 搭建应用
- 使用465端口发送邮件
- 搭建可视化界面
- 数据备份
- 本地文件上传到云服务器
- 其他场景相关操作
- 云服务器通过内网访问对象存储
- 启动模式 Legacy BIOS 和 UEFI 最佳实践
- Linux 实例数据恢复
- Windows 实例磁盘空间管理
- Linux 实例手动更换内核
- 云服务器搭建 Windows 系统 AD 域
- 网络性能测试
- 高吞吐网络性能测试
- Linux 系统使用 USB/IP 远程共享 USB 设备
- Windows 系统使用 RemoteFx 重定向 USB 设备
- 在 CVM 上通过 AVX512 加速人工智能应用
- 构建 Tencent SGX 机密计算环境
- M6p 实例配置持久内存
- 使用 Python 调用云 API 实现批量共享自定义镜像
- 如何在 Linux 实例中自定义 DNS 配置
- 运维指南
- 故障处理
- 实例相关故障
- 无法登录云服务器问题处理思路
- Windows 实例登录相关问题
- Linux 实例登录相关问题
- 无法登录 Linux 实例
- Linux 实例:无法通过 SSH 方式登录
- Linux 实例:CPU 或内存占用率高导致登录卡顿
- Linux 实例:端口问题导致无法登录
- Linux 实例:VNC 登录报错 Module is unknown
- Linux 实例:VNC 登录报错 Account locked due to XXX failed logins
- Linux 实例:VNC 登录输入正确密码后无响应
- Linux 实例:VNC 或 SSH 登录报错 Permission denied
- Linux 实例:/etc/fstab 配置错误导致无法登录
- Linux 实例:sshd 配置文件权限问题
- Linux 实例:/etc/profile 死循环调用问题
- 服务器被隔离导致无法登录
- 带宽占用高导致无法登录
- 安全组设置导致无法远程连接
- Linux 实例使用 VNC 及救援模式排障
- 关机和重启云服务器失败
- 无法创建 Network Namespace
- 内核及 IO 相关问题
- 系统 bin 或 lib 软链接缺失
- 云服务器疑似被病毒入侵问题
- 创建文件报错 no space left on device
- Linux 实例内存相关故障
- 网络相关故障
- 实例相关故障
- API 文档
- History
- Introduction
- API Category
- Region APIs
- Instance APIs
- RunInstances
- DescribeInstances
- DescribeInstanceFamilyConfigs
- DescribeInstancesOperationLimit
- InquiryPriceRunInstances
- InquiryPriceResetInstance
- InquiryPriceResetInstancesType
- StartInstances
- RebootInstances
- StopInstances
- ResizeInstanceDisks
- ResetInstancesPassword
- ModifyInstancesAttribute
- EnterRescueMode
- ExitRescueMode
- InquirePricePurchaseReservedInstancesOffering
- InquiryPriceResizeInstanceDisks
- TerminateInstances
- ModifyInstancesProject
- ResetInstancesType
- DescribeInstancesStatus
- DescribeReservedInstancesConfigInfos
- DescribeZoneInstanceConfigInfos
- PurchaseReservedInstancesOffering
- ResetInstance
- DescribeInstanceTypeConfigs
- DescribeInstanceVncUrl
- Cloud Hosting Cluster APIs
- Image APIs
- Instance Launch Template APIs
- Making API Requests
- Placement Group APIs
- Key APIs
- Security Group APIs
- Network APIs
- Data Types
- Error Codes
- 常见问题
- 相关协议
- 词汇表
- 新手指引
- 动态与公告
- 产品动态
- 公共镜像更新记录
- 公告
- 关于 CrowdStrike 安全软件导致的 Windows 蓝屏问题临时解决方法2024年07月19日
- 关于部分地域竞价实例弹性优惠公告
- 关于CentOS 7系列部分镜像pip包管理工具更新公告
- 关于 CentOS 8 终止维护公告
- 关于不再支持 SUSE 商业版镜像公告
- 关于多个可用区云服务器价格下调公告
- 关于 OrcaTerm 代理 IP 地址更替的公告
- 关于硅谷地域标准型 S3 价格调整的公告
- 腾讯云 Linux 镜像长期漏洞修复策略公告
- 关于 Ubuntu 10.04 镜像下线及存量软件源配置的公告
- 关于 Ubuntu14.04 无法启动 Tomcat 的解决方案
- 关于Windows云服务器升级Virtio网卡驱动的通知
- 关于安全组53端口配置的公告
- 关于不再支持 Windows Server 2003 系统镜像的公告
- 关于不再支持 Windows Server 2008 R2 企业版 SP1 64位系统镜像的公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 针对 CVM 的最佳实践
- 云服务器选型最佳实践
- 如何搭建网站
- 搭建环境
- 搭建网站
- 搭建应用
- 使用465端口发送邮件
- 搭建可视化界面
- 数据备份
- 本地文件上传到云服务器
- 其他场景相关操作
- 云服务器通过内网访问对象存储
- 启动模式 Legacy BIOS 和 UEFI 最佳实践
- Linux 实例数据恢复
- Windows 实例磁盘空间管理
- Linux 实例手动更换内核
- 云服务器搭建 Windows 系统 AD 域
- 网络性能测试
- 高吞吐网络性能测试
- Linux 系统使用 USB/IP 远程共享 USB 设备
- Windows 系统使用 RemoteFx 重定向 USB 设备
- 在 CVM 上通过 AVX512 加速人工智能应用
- 构建 Tencent SGX 机密计算环境
- M6p 实例配置持久内存
- 使用 Python 调用云 API 实现批量共享自定义镜像
- 如何在 Linux 实例中自定义 DNS 配置
- 运维指南
- 故障处理
- 实例相关故障
- 无法登录云服务器问题处理思路
- Windows 实例登录相关问题
- Linux 实例登录相关问题
- 无法登录 Linux 实例
- Linux 实例:无法通过 SSH 方式登录
- Linux 实例:CPU 或内存占用率高导致登录卡顿
- Linux 实例:端口问题导致无法登录
- Linux 实例:VNC 登录报错 Module is unknown
- Linux 实例:VNC 登录报错 Account locked due to XXX failed logins
- Linux 实例:VNC 登录输入正确密码后无响应
- Linux 实例:VNC 或 SSH 登录报错 Permission denied
- Linux 实例:/etc/fstab 配置错误导致无法登录
- Linux 实例:sshd 配置文件权限问题
- Linux 实例:/etc/profile 死循环调用问题
- 服务器被隔离导致无法登录
- 带宽占用高导致无法登录
- 安全组设置导致无法远程连接
- Linux 实例使用 VNC 及救援模式排障
- 关机和重启云服务器失败
- 无法创建 Network Namespace
- 内核及 IO 相关问题
- 系统 bin 或 lib 软链接缺失
- 云服务器疑似被病毒入侵问题
- 创建文件报错 no space left on device
- Linux 实例内存相关故障
- 网络相关故障
- 实例相关故障
- API 文档
- History
- Introduction
- API Category
- Region APIs
- Instance APIs
- RunInstances
- DescribeInstances
- DescribeInstanceFamilyConfigs
- DescribeInstancesOperationLimit
- InquiryPriceRunInstances
- InquiryPriceResetInstance
- InquiryPriceResetInstancesType
- StartInstances
- RebootInstances
- StopInstances
- ResizeInstanceDisks
- ResetInstancesPassword
- ModifyInstancesAttribute
- EnterRescueMode
- ExitRescueMode
- InquirePricePurchaseReservedInstancesOffering
- InquiryPriceResizeInstanceDisks
- TerminateInstances
- ModifyInstancesProject
- ResetInstancesType
- DescribeInstancesStatus
- DescribeReservedInstancesConfigInfos
- DescribeZoneInstanceConfigInfos
- PurchaseReservedInstancesOffering
- ResetInstance
- DescribeInstanceTypeConfigs
- DescribeInstanceVncUrl
- Cloud Hosting Cluster APIs
- Image APIs
- Instance Launch Template APIs
- Making API Requests
- Placement Group APIs
- Key APIs
- Security Group APIs
- Network APIs
- Data Types
- Error Codes
- 常见问题
- 相关协议
- 词汇表
在云原生场景中,Namespace 和 Cgroup 为资源隔离提供了基础支持,但容器的整体隔离能力仍然不完整。特别是,/proc 和 /sys 文件系统中的一些资源统计信息未被容器化,导致在容器内运行的一些常用命令(如 free、top)无法准确展示容器资源的使用情况。
针对这一问题,TencentOS 内核推出了 cgroupfs 解决方案,旨在改善容器资源展示。cgroupfs 实现了一个虚拟文件系统,包括业务所需的、从容器视角出发的 /proc 和 /sys 等文件,其目录结构与全局的 procfs 和 sysfs 保持一致,以确保与用户工具的兼容性。当实际读取这些文件时,cgroupfs 通过读者进程的上下文动态生成相应的容器信息视图。
挂载 cgroupfs 文件系统
1. 执行以下命令以挂载 cgroupfs 文件系统。
mount -t cgroupfs cgroupfs /cgroupfs/
截图如下:
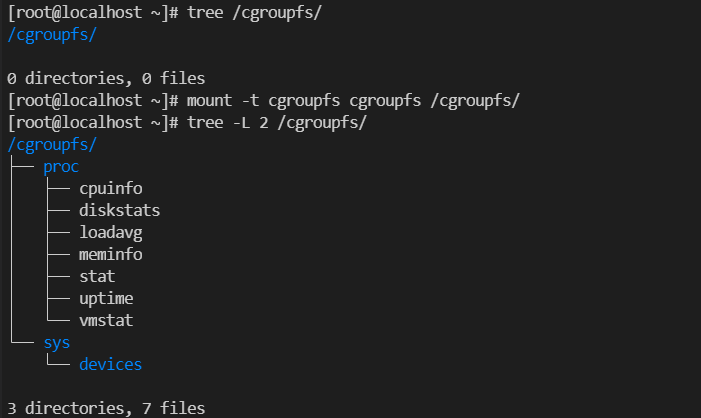
2. 使用
-v 选项按需挂载 cgroupfs 下的文件到指定容器中,针对 docker 的启动命令如下:docker run -itd --cpus 2 --cpuset-cpus 0,1,2,4 -v/cgroupfs/sys/devices/system/cpu/:/sys/devices/system/cpu -v/cgroupfs/proc/cpuinfo:/proc/cpuinfo -v/cgroupfs/proc/stat:/proc/stat -v/cgroupfs/proc/meminfo:/proc/meminfo <image-id> /bin/bash
3. 随后,在容器中查看到了仅属于容器视角的 cpuinfo、stat 以及 meminfo 信息。
pagecache 隔离
当进程文件页的使用过多时,会占用大量内存,导致其他业务的可用内存量减少。这种情况会使得机器的内存分配频繁地陷入低效路径,很容易触发内存不足(OOM)错误。在云原生场景中,我们对内核的页面缓存(page cache)进行了拓展,实现了对容器页面缓存使用量的限制(page cache limit),从而可以单独限制某个容器的页面缓存使用量。
整机 pagecache 限制:
sysctl -w vm.memory_qos=1sysctl -w vm.pagecache_limit_global=1
echo x > /proc/sys/vm/pagecache_limit_ratio#(0 < x < 100)开启 page cache limit限制。非 0时,比如30,表示限制 page cache占系统总内存的 30%。
脏页回收的过程相对耗时。
pagecache_limit_ignore_dirty 用于判断在计算 page cache 占用内存时是否忽略脏页。其位置如下:/proc/sys/vm/pagecache_limit_ignore_dirty。默认值是 1,表示忽略脏页。
设置 page cache 的回收方式:
/proc/sys/vm/pagecache_limit_async
1 表示异步回收 page cache,TencentOS 会创建一个 [kpclimitd] 内核线程,由这个线程负责 page cache 的回收。
0 表示同步回收,不会创建任何专用回收线程,直接在 page cache limit 触发的进程上下文回收,默认值为 0。
容器 pagecache 限制:
除了支持全局系统级 pagecache 限制外,TencentOS 还支持容器级别的 pagecache 限制,使用方式如下:
1. 开启内存 QOS:
sysctl -w vm.memory_qos=1
2. 关闭全局 pagecache 限制:
sysctl -w vm.pagecache_limit_global=0
3. 进入容器所在 memcg,并设置 memory 限制:
echo value > memory.limit_in_bytes
4. 设置 pagecache 最大用量为当前内存限额的百分比,例如设置10%:
echo 10 > memory.pagecache.max_ratio
5. 设置 pagecache 超额后的回收比例:
echo 5 > memory.pagecache.reclaim_ratio
读写统一限速
Linux 内核原有的 IO 限速方案按照读写分开的方式进行,这要求管理员根据业务模型将 IO 带宽按照读写分开划分并分别实施限速,从而存在带宽浪费的问题。例如,如果配置为读50MB/s,写50MB/s,而实际 IO 带宽为读20MB/s,写50MB/s,则会浪费30MB/s的读带宽。为了解决这一问题,TencentOS 推出了读写统一限速的方案。该方案在用户态为客户提供读写统一限速的配置接口,而在内核态则根据业务流量动态划分读写比例。使用方式如下:
进入业务对应的 blkio 所在的 cgroup,并使用以下配置:echo MAJ:MIN VAL > FILE。
其中 MAJ:MIN 代表设备号,FILE 及 VAL 如下表所示:
FILE | VAL |
blkio.throttle.readwrite_bps_device | 读写 Bps 总限制值 |
blkio.throttle.readwrite_iops_device | 读写 iops 总限制 |
blkio.throttle.readwrite_dynamic_ratio | 动态预测读写比例: 0:关闭。使用固定(读:写 - 3:1)比例 1~5:开启动态预测方案。 |
buffer io 限速支持
在 Linux 原生内核中,cgroup v1在限制 buffer IO 速度方面存在一定缺陷。Buffer IO 回写通常是一个异步过程,内核在进行异步刷脏操作时,无法确定该 IO 应该提交给哪个 blkio cgroup,因此无法应用相应的 blkio 限速策略。
基于此,TencentOS 对 cgroup v1 下的 buffer IO 限速功能进行了进一步完善,使其与基于 cgroup v2 的 buffer IO 限速功能保持一致。对于 cgroup v1,我们提供了一个用户态接口,允许将 page cache 所属的 mem_cgroup 与相应的 blkio cgroup 绑定,从而使内核能够根据绑定信息对 buffer IO 进行限速。
1. 要启用 buffer io 的限速功能,需要开启 kernel.io_qos 和 kernel.io_cgv1_buff_wb 两个特性。
sysctl -w kernel.io_qos=1 # 打开 IO QoS 特性 sysctl -w kernel.io_cgv1_buff_wb=1 # 打开 Buffer IO 特性(默认开启)
2. 为了实现容器的 buffer I/O 限速,需要显式地将容器对应的 memcg 与 blkcg 的 cgroup 进行绑定,操作如下:
echo /sys/fs/cgroup/blkio/A > /sys/fs/cgroup/memory/A/memory.bind_blkio
绑定之后,由 blkio cgroup 提供的对于容器的 buffer i/o 资源的限制机制将能够通过以下接口进行查看:
blkio.throttle.read_bps_device
blkio.throttle.write_bps_device
blkio.throttle.write_iops_device
blkio.throttle.read_iops_device
blkio.throttle.readwrite_bps_device
blkio.throttle.readwrite_iops_device
异步 fork
当大内存业务执行 fork 系统调用以创建子进程时,fork 调用过程的耗时会相对较长,导致业务可能长时间处于内核态而无法处理业务请求。因此,针对该场景优化内核的 fork 时间显得尤为必要。
在 Linux 下,内核处理 fork 的默认流程中,父进程需要将大量进程元数据复制到子进程,其中页表的复制是最耗时的部分,通常占据 fork 调用耗时的97%以上。异步 fork 的设计思想是将复制页表的工作从父进程转移到子进程,这样可以缩短父进程调用 fork 系统调用并陷入内核态的时间,使应用能够尽快返回用户态来处理业务请求,从而解决因 fork 导致的性能抖动问题。
本功能通过
cgroup 来进行开关控制,基本用法:echo 1 > <cgroup目录>/memory.async_fork #为当前cgroup目录开启异步fork功能 echo 0 > <cgroup目录>/memory.async_fork #关闭当前cgroup目录的异步fork功能
该接口默认值为0,即默认关闭。
文档章节

 是
是
 否
否
本页内容是否解决了您的问题?