In Pulsar, each message has its own ID, namely MessageID, which consists of four parts: ledgerId:entryID:partition-index:batch-index:
partition-index: Partition number, which is -1 for non-partitioned topics.
batch-index: -1 for non-batch messages.
The MessageID generation rules are determined by Pulsar's message storage mechanism as shown below:
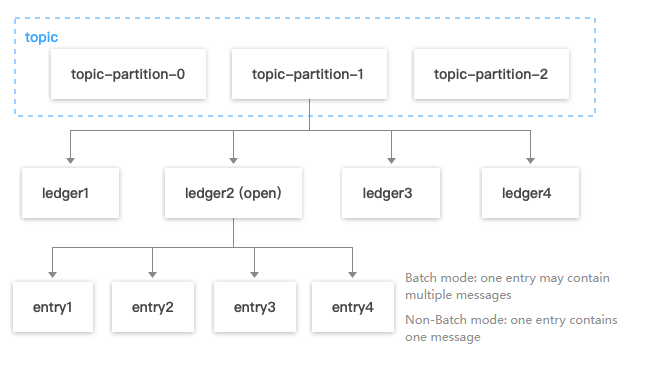
As shown above, each topic partition in Pulsar corresponds to a series of ledgers, with only one ledger is in open (i.e., writable) status and each ledger storing only messages in its corresponding partition.
When Pulsar stores a message, it will first find the ledger used by the current partition and then generate an entry ID for the message. Entry IDs are incremental in the same ledger. After the existence duration of a ledger or number of entries stored in it exceeds the threshold, new messages will be stored in the next ledger in the same partition.
In case of batch message production, one entry may contain multiple messages.
In case of non-batch message production, one entry contains one message (this parameter can be configured on the producer side, and batch production is used by default).
Ledger is just a logical dimension for data assembly and has no actual entity. Bookies write, find, and get data only by entry.
Ledger and Entry
Ledger
Pulsar stores message data in a ledger format on bookie nodes in a BookKeeper cluster. A ledger is an append-only data structure with a single writer that is assigned to multiple bookies. Ledger entries are replicated to multiple bookies, and relevant data is written to ensure data consistency.
The data that BookKeeper needs to save include:
Journal
A journal file stores BookKeeper transaction logs. Before any ledger update is made, its description information needs to be persisted to a journal file first.
BookKeeper provides a separate sync thread to roll the current journal file according to its size.
Entry log file
An entry log file stores real data. Entry data from different ledgers is cached in the memory buffer first and then batch flushed to an entry log file.
By default, data from all ledgers is aggregated and then sequentially written to the same entry log file to avoid random disk writes.
Index file
Entry data from all ledgers is written to the same entry log file. To accelerate data writes, a mapping from ledgerId + entryId to the file offset will be performed, which will be cached in the memory called "index cache".
When the index cache capacity reaches the upper limit, it will be flushed to the disk by the sync thread.
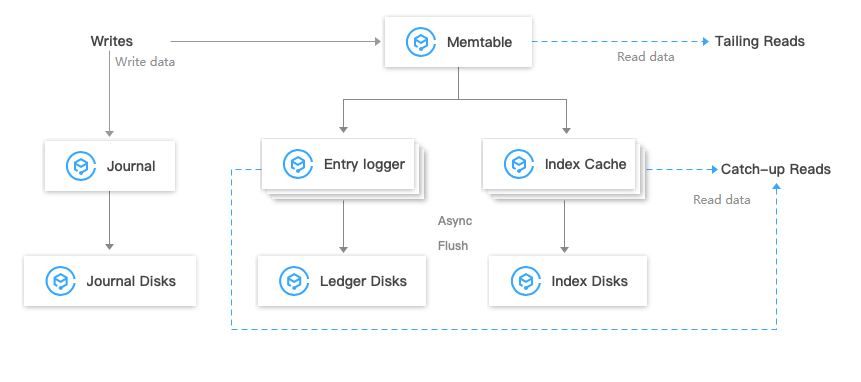
The read and write interactions of the three types of data files are as shown below:
Entry
Entry data write
1. Data will be first written to the journal (stored in the disk in real time) and memtable (read/write cache) at the same time.
2. After the data is written to the memtable, a response will be given to the write request.
3. After the memtable is full, data will be flushed to the entry logger (for data storage) and index cache (for data index information storage).
4. The backend thread will store the data in the entry logger and index cache to the disk.
Entry data read
Tailing read request: Entries will be read directly from the memtable.
Catch-up read (lagged consumption) request: The index information will be read first, and then the index will read entries from the entry logger file.
Data consistency guarantee: LastLogMark
The written entry log and index are cached in the memory first and then flushed to the disk periodically according to particular conditions, which causes an interval between memory caching and disk storage. If the BookKeeper process crashes during this interval, after it is restarted, the data needs to be recovered from the journal file. In this case, the LastLogMark marks the position in the journal from where to recover.
LastLogMark is actually stored in the memory. When the index cache is flushed to the disk, its value will be updated. It will also be persisted to the disk periodically for data recovery from the journal when the Bookkeeper process starts.
Once LastLogMark is persisted to the disk, the preceding index and entry log have been persisted to the disk, and the data in the journal before the LastLogMark can be cleared.