- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 云产品监控
- 应用性能监控
- 终端性能监控
- 前端性能监控
- 云拨测
- Prometheus 监控
- Grafana 服务
- Dashboard
- 告警管理
- 常见问题
- 事件总线
- 文档阅读指南
- 相关协议
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Alarm APIs
- DescribeAlarmPolicies
- DescribeAlarmMetrics
- DescribeAlarmHistories
- CreateAlarmPolicy
- DeleteAlarmPolicy
- DescribeAlarmPolicy
- ModifyAlarmPolicyStatus
- SetDefaultAlarmPolicy
- BindingPolicyObject
- UnBindingPolicyObject
- UnBindingAllPolicyObject
- ModifyAlarmPolicyCondition
- ModifyAlarmPolicyNotice
- ModifyAlarmPolicyTasks
- DescribeMonitorTypes
- DescribeAllNamespaces
- DescribeAlarmEvents
- DescribeBindingPolicyObjectList
- ModifyAlarmPolicyInfo
- DescribeConditionsTemplateList
- Notification Template APIs
- Monitoring Data Query APIs
- Legacy Alert APIs
- Prometheus Service APIs
- CreatePrometheusAgent
- CreatePrometheusMultiTenantInstancePostPayMode
- CreatePrometheusScrapeJob
- CreateRecordingRule
- CreateServiceDiscovery
- DeleteAlertRules
- DeleteExporterIntegration
- DeletePrometheusScrapeJobs
- DeleteRecordingRules
- DescribeAlertRules
- DescribeExporterIntegrations
- DescribePrometheusAgents
- DescribePrometheusInstanceUsage
- DescribePrometheusInstances
- DescribePrometheusScrapeJobs
- DescribeRecordingRules
- DescribeServiceDiscovery
- DestroyPrometheusInstance
- GetPrometheusAgentManagementCommand
- ModifyPrometheusInstanceAttributes
- TerminatePrometheusInstances
- UnbindPrometheusManagedGrafana
- UninstallGrafanaDashboard
- UpdateAlertRule
- UpdateAlertRuleState
- UpdateExporterIntegration
- UpdatePrometheusAgentStatus
- UpdatePrometheusScrapeJob
- UpdateRecordingRule
- UpgradeGrafanaDashboard
- DescribePrometheusZones
- CreateAlertRule
- CreateExporterIntegration
- BindPrometheusManagedGrafana
- Grafana Service APIs
- UpgradeGrafanaInstance
- UpdateSSOAccount
- UpdateGrafanaWhiteList
- UpdateGrafanaNotificationChannel
- UpdateGrafanaIntegration
- UpdateGrafanaEnvironments
- UpdateGrafanaConfig
- UpdateDNSConfig
- UninstallGrafanaPlugins
- ResumeGrafanaInstance
- ModifyGrafanaInstance
- InstallPlugins
- EnableSSOCamCheck
- EnableGrafanaSSO
- EnableGrafanaInternet
- DescribeSSOAccount
- DescribeInstalledPlugins
- DescribeGrafanaWhiteList
- DescribeGrafanaNotificationChannels
- DescribeGrafanaIntegrations
- DescribeGrafanaInstances
- DescribeGrafanaEnvironments
- DescribeGrafanaConfig
- DescribeDNSConfig
- DeleteSSOAccount
- DeleteGrafanaNotificationChannel
- DeleteGrafanaIntegration
- DeleteGrafanaInstance
- CreateSSOAccount
- CreateGrafanaNotificationChannel
- CreateGrafanaIntegration
- CreateGrafanaInstance
- CleanGrafanaInstance
- DescribeGrafanaChannels
- Event Center APIs
- TencentCloud Managed Service for Prometheus APIs
- CreatePrometheusAlertPolicy
- CreatePrometheusGlobalNotification
- CreatePrometheusTemp
- DeletePrometheusAlertPolicy
- DeletePrometheusClusterAgent
- DeletePrometheusTemp
- DeletePrometheusTempSync
- DescribeClusterAgentCreatingProgress
- DescribePrometheusAgentInstances
- DescribePrometheusGlobalNotification
- DescribePrometheusInstanceDetail
- DescribePrometheusInstanceInitStatus
- DescribePrometheusTargetsTMP
- DescribePrometheusTempSync
- ModifyPrometheusAgentExternalLabels
- ModifyPrometheusAlertPolicy
- ModifyPrometheusGlobalNotification
- ModifyPrometheusTemp
- RunPrometheusInstance
- SyncPrometheusTemp
- CreatePrometheusClusterAgent
- DescribePrometheusClusterAgents
- DescribePrometheusGlobalConfig
- DescribePrometheusRecordRules
- DescribePrometheusAlertPolicy
- DescribePrometheusInstancesOverview
- DescribePrometheusTemp
- Monitoring APIs
- Data Types
- Error Codes
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 云产品监控
- 应用性能监控
- 终端性能监控
- 前端性能监控
- 云拨测
- Prometheus 监控
- Grafana 服务
- Dashboard
- 告警管理
- 常见问题
- 事件总线
- 文档阅读指南
- 相关协议
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Alarm APIs
- DescribeAlarmPolicies
- DescribeAlarmMetrics
- DescribeAlarmHistories
- CreateAlarmPolicy
- DeleteAlarmPolicy
- DescribeAlarmPolicy
- ModifyAlarmPolicyStatus
- SetDefaultAlarmPolicy
- BindingPolicyObject
- UnBindingPolicyObject
- UnBindingAllPolicyObject
- ModifyAlarmPolicyCondition
- ModifyAlarmPolicyNotice
- ModifyAlarmPolicyTasks
- DescribeMonitorTypes
- DescribeAllNamespaces
- DescribeAlarmEvents
- DescribeBindingPolicyObjectList
- ModifyAlarmPolicyInfo
- DescribeConditionsTemplateList
- Notification Template APIs
- Monitoring Data Query APIs
- Legacy Alert APIs
- Prometheus Service APIs
- CreatePrometheusAgent
- CreatePrometheusMultiTenantInstancePostPayMode
- CreatePrometheusScrapeJob
- CreateRecordingRule
- CreateServiceDiscovery
- DeleteAlertRules
- DeleteExporterIntegration
- DeletePrometheusScrapeJobs
- DeleteRecordingRules
- DescribeAlertRules
- DescribeExporterIntegrations
- DescribePrometheusAgents
- DescribePrometheusInstanceUsage
- DescribePrometheusInstances
- DescribePrometheusScrapeJobs
- DescribeRecordingRules
- DescribeServiceDiscovery
- DestroyPrometheusInstance
- GetPrometheusAgentManagementCommand
- ModifyPrometheusInstanceAttributes
- TerminatePrometheusInstances
- UnbindPrometheusManagedGrafana
- UninstallGrafanaDashboard
- UpdateAlertRule
- UpdateAlertRuleState
- UpdateExporterIntegration
- UpdatePrometheusAgentStatus
- UpdatePrometheusScrapeJob
- UpdateRecordingRule
- UpgradeGrafanaDashboard
- DescribePrometheusZones
- CreateAlertRule
- CreateExporterIntegration
- BindPrometheusManagedGrafana
- Grafana Service APIs
- UpgradeGrafanaInstance
- UpdateSSOAccount
- UpdateGrafanaWhiteList
- UpdateGrafanaNotificationChannel
- UpdateGrafanaIntegration
- UpdateGrafanaEnvironments
- UpdateGrafanaConfig
- UpdateDNSConfig
- UninstallGrafanaPlugins
- ResumeGrafanaInstance
- ModifyGrafanaInstance
- InstallPlugins
- EnableSSOCamCheck
- EnableGrafanaSSO
- EnableGrafanaInternet
- DescribeSSOAccount
- DescribeInstalledPlugins
- DescribeGrafanaWhiteList
- DescribeGrafanaNotificationChannels
- DescribeGrafanaIntegrations
- DescribeGrafanaInstances
- DescribeGrafanaEnvironments
- DescribeGrafanaConfig
- DescribeDNSConfig
- DeleteSSOAccount
- DeleteGrafanaNotificationChannel
- DeleteGrafanaIntegration
- DeleteGrafanaInstance
- CreateSSOAccount
- CreateGrafanaNotificationChannel
- CreateGrafanaIntegration
- CreateGrafanaInstance
- CleanGrafanaInstance
- DescribeGrafanaChannels
- Event Center APIs
- TencentCloud Managed Service for Prometheus APIs
- CreatePrometheusAlertPolicy
- CreatePrometheusGlobalNotification
- CreatePrometheusTemp
- DeletePrometheusAlertPolicy
- DeletePrometheusClusterAgent
- DeletePrometheusTemp
- DeletePrometheusTempSync
- DescribeClusterAgentCreatingProgress
- DescribePrometheusAgentInstances
- DescribePrometheusGlobalNotification
- DescribePrometheusInstanceDetail
- DescribePrometheusInstanceInitStatus
- DescribePrometheusTargetsTMP
- DescribePrometheusTempSync
- ModifyPrometheusAgentExternalLabels
- ModifyPrometheusAlertPolicy
- ModifyPrometheusGlobalNotification
- ModifyPrometheusTemp
- RunPrometheusInstance
- SyncPrometheusTemp
- CreatePrometheusClusterAgent
- DescribePrometheusClusterAgents
- DescribePrometheusGlobalConfig
- DescribePrometheusRecordRules
- DescribePrometheusAlertPolicy
- DescribePrometheusInstancesOverview
- DescribePrometheusTemp
- Monitoring APIs
- Data Types
- Error Codes
- 词汇表
本文档介绍如何精简 Prometheus 监控服务的采集指标,避免不必要的费用支出。
前提条件
在配置监控数据采集项前,您需要完成以下操作:
已成功 创建 Prometheus 监控实例。
已将需要 监控的集群关联到相应实例 中。
精简指标
通过控制台精简指标
1. 登录 腾讯云可观测平台控制台,选择左侧导航栏中的 Prometheus 监控。
2. 在监控实例列表页,选择需要配置数据采集规则的实例名称,进入该实例详情页。
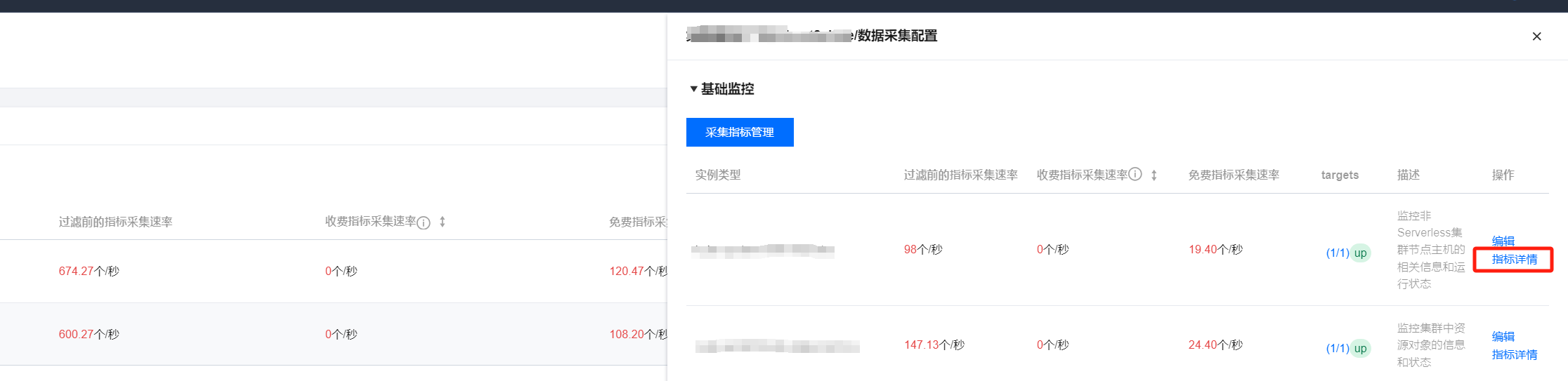
3. 在数据采集页面,选择集成容器服务,单击集群右侧的数据采集配置,如下图所示:

4. 进入采集配置列表页后,基础指标支持通过产品化的页面增加/减少采集对象,单击右侧的指标详情,如下图所示:
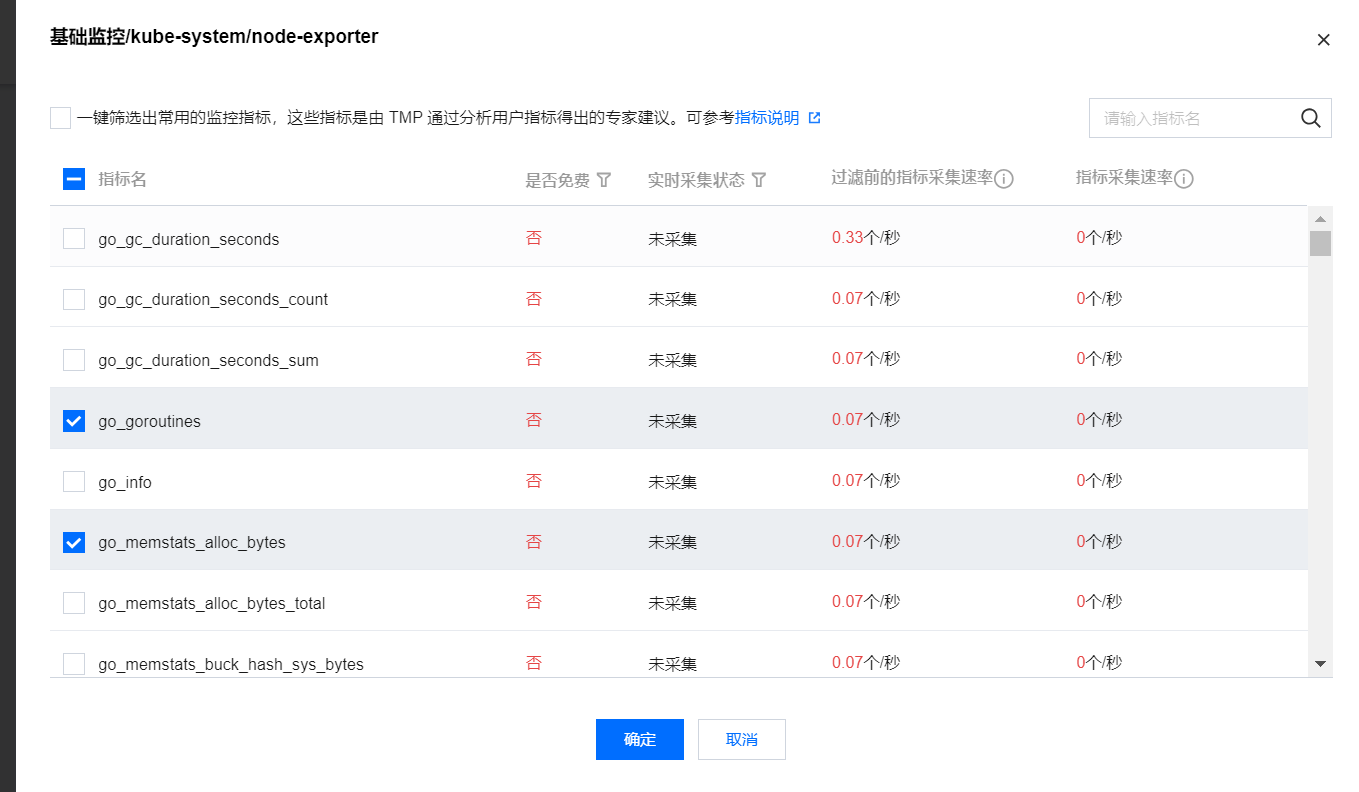
5. 在以下页面您可以查看到每个指标是否免费,指标勾选表示会采集这些指标,您可按需勾选使用。仅基础监控提供免费的监控指标,完整的免费指标详情请参见 按量付费免费指标。付费指标计算详情见 Prometheus 监控服务按量计费。
通过 YAML 精简指标
Prometheus 目前收费模式为按监控数据的点数收费,为了最大程度减少不必要的浪费,建议您针对采集配置进行优化,只采集需要的指标,过滤掉非必要指标,从而减少整体上报量。详细的计费方式和相关云资源的使用请查看 文档。
以下步骤将分别介绍如何在自定义指标的 ServiceMonitor、PodMonitor,以及原生 Job 中加入过滤配置,精简自定义指标。
1. 登录 腾讯云可观测平台控制台,选择左侧导航栏中的 Prometheus 监控。
2. 在监控实例列表页,选择需要配置数据采集规则的实例名称,进入该实例详情页。
3. 在数据采集页面,选择集成容器服务,单击集群右侧的数据采集配置。
4. 单击实例右侧的编辑查看指标详情。
ServiceMonitor 和 PodMonitor 的过滤配置字段相同,本文以 ServiceMonitor 为例。
ServiceMonitor 示例:
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: 1.9.7name: kube-state-metricsnamespace: kube-systemspec:endpoints:- bearerTokenSecret:key: ""interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量port: http-metricsscrapeTimeout: 15s # 该参数为采集超时时间,Prometheus 的配置要求采集超时时间不能超过采集间隔,即:scrapeTimeout <= intervaljobLabel: app.kubernetes.io/namenamespaceSelector: {}selector:matchLabels:app.kubernetes.io/name: kube-state-metrics
若要采集
kube_node_info 和 kube_node_role 的指标,则需要在 ServiceMonitor 的 endpoints 列表中,加入 metricRelabelings 字段配置。注意:是 metricRelabelings 而不是 relabelings。
添加 metricRelabelings 示例:apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: 1.9.7name: kube-state-metricsnamespace: kube-systemspec:endpoints:- bearerTokenSecret:key: ""interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量port: http-metricsscrapeTimeout: 15s# 加了如下四行:metricRelabelings: # 针对每个采集到的点都会做如下处理- sourceLabels: ["__name__"] # 要检测的label名称,__name__ 表示指标名称,也可以是任意这个点所带的labelregex: kube_node_info|kube_node_role # 上述label是否满足这个正则,在这里,我们希望__name__满足kube_node_info或kube_node_roleaction: keep # 如果点满足上述条件,则保留,否则就自动抛弃jobLabel: app.kubernetes.io/namenamespaceSelector: {}selector:
如果使用的是 Prometheus 原生的 Job,则可以参考以下方式进行指标过滤。
Job 示例:
scrape_configs:- job_name: job1scrape_interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量static_configs:- targets:- '1.1.1.1'
若只需采集
kube_node_info 和 kube_node_role 的指标,则需要加入 metric_relabel_configs 配置。注意:是 metric_relabel_configs 而不是 relabel_configs。
添加 metric_relabel_configs 示例:scrape_configs:- job_name: job1scrape_interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量static_configs:- targets:- '1.1.1.1'# 加了如下四行:metric_relabel_configs: # 针对每个采集到的点都会做如下处理- source_labels: ["__name__"] # 要检测的label名称,__name__ 表示指标名称,也可以是任意这个点所带的labelregex: kube_node_info|kube_node_role # 上述label是否满足这个正则,在这里,我们希望__name__满足kube_node_info或kube_node_roleaction: keep # 如果点满足上述条件,则保留,否则就自动抛弃
5. 单击确定。
屏蔽部分采集对象
屏蔽整个命名空间的监控
Prometheus 关联集群后,默认会纳管集群中所有 ServiceMonitor 和 PodMonitor,若您想屏蔽某个命名空间下的监控,可以为指定命名空间添加 label:
tps-skip-monitor: "true",关于 label 的操作请 参考。屏蔽部分采集对象
Prometheus 通过在用户的集群里面创建 ServiceMonitor 和 PodMonitor 类型的 CRD 资源进行监控数据的采集,若您想屏蔽指定 ServiceMonitor 和 PodMonitor 的采集,可以为这些 CRD 资源添加 label:
tps-skip-monitor: "true",关于 label 的操作请 参考。

 是
是
 否
否
本页内容是否解决了您的问题?