Tencent Cloud EMR supports a wide range of open-source components and application scenarios. This article introduces the main application scenarios of EMR.
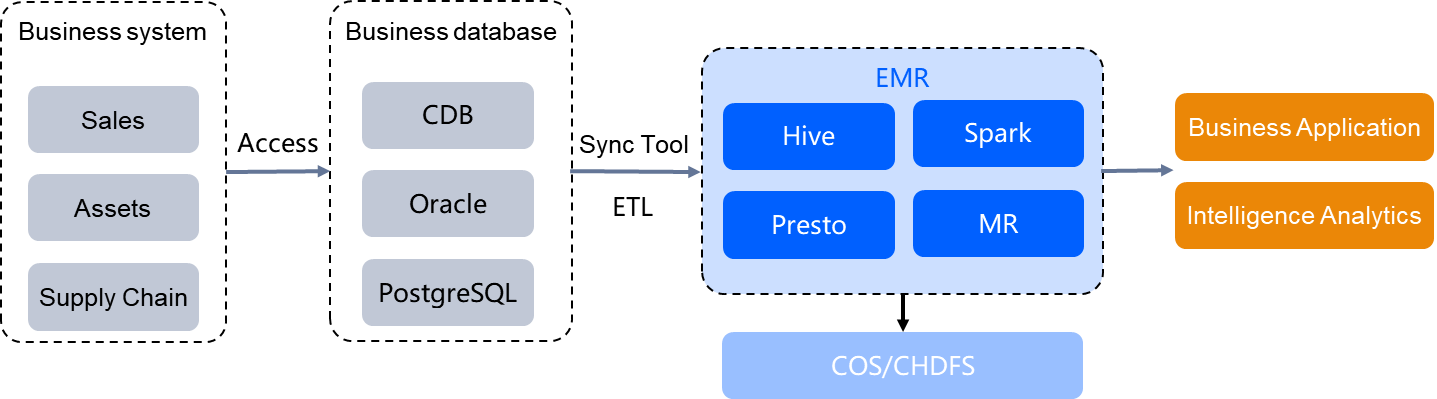
Enterprise Data Warehouse Construction
Summarizing and analyzing business data such as sales, assets, and the supply chain requires integrating different data sources and extracting data from various sources. With EMR's powerful petabyte-level data analysis capabilities and native support for Tencent Cloud COS and CHDFS storage, it provides a high-performance compute-storage separation solution for data warehouses, enabling the computation of massive data to uncover hidden business value for business decision-making.
Corporate Data Lake Construction
In the domain of continuously accumulating full business data, enterprises need to store various types of data and adapt to multiple scenario data analysis tasks. EMR's data lake format and caching acceleration capabilities help build a data lake, fully utilizing resources and fitting scenarios such as offline computing, stream computing, interactive analysis, and machine learning. This grants customers higher data agility and lower data analysis costs.
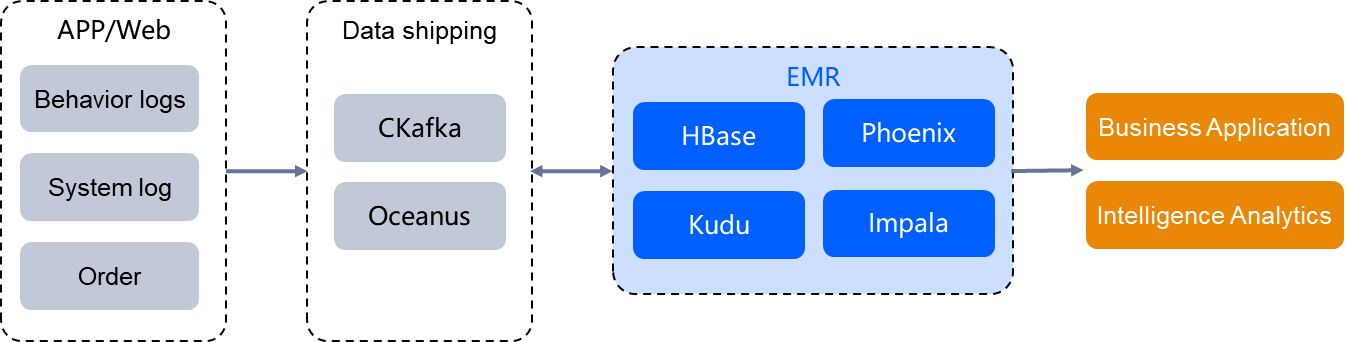
High Concurrency Online Data Query
Efficiently analyzing structured or semi-structured data such as user behavior, system logs, and orders requires collecting various business data from online websites, apps, and system user behaviors and logs. Through EMR's rich computing components, minute-level cluster construction, and horizontal scalability, it supports online business real-time queries, enhancing business response efficiency.
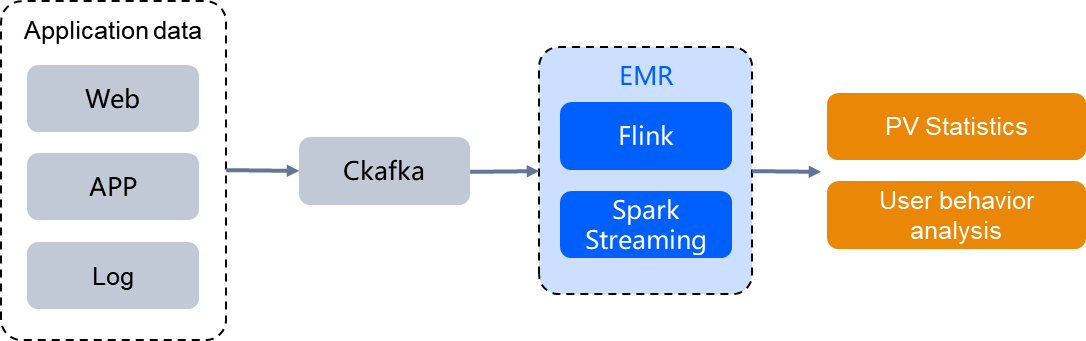
Real-time Stream Computing
In the domain of building real-time computing business, leveraging EMR cloud stream computing services enables real-time analysis construction within minutes. This facilitates real-time aggregation and analysis of user behavior data, helping improve user experience. By simultaneously setting up batch and stream processing systems, it realizes batch and stream integration, reduces resource investment, enhances data processing speed, timely analyzes business operation effectiveness, and quickly adjusts business strategies, supporting the better development of mainstream businesses.
Data Mining and Analysis
In scenarios requiring rapid computation and data mining capabilities, such as real-time risk control and real-time recommendation, EMR can provide efficient cloud stream computing services and data mining component support. This helps monitor abnormal transactions, quickly detect financial vulnerabilities, ensure funds security, and build user profiling models, enabling businesses to accurately and timely understand their user base.