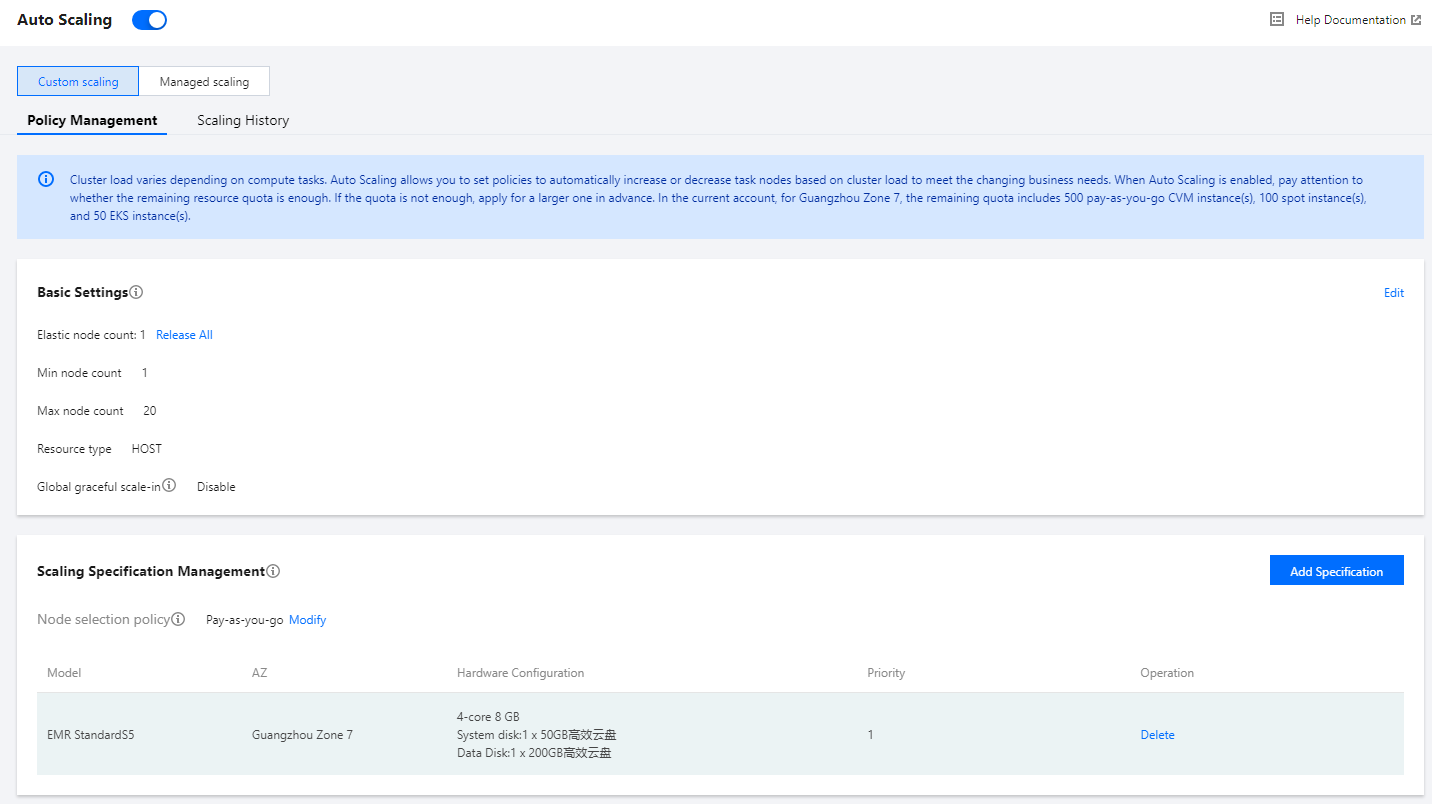
The Basic settings section allows you to set the node quantity range of the custom scaling feature, configure the elastic resource type, and configure whether to support graceful scale-in. It also displays the number of elastic node resources in the current cluster and supports quick release of elastic instances.
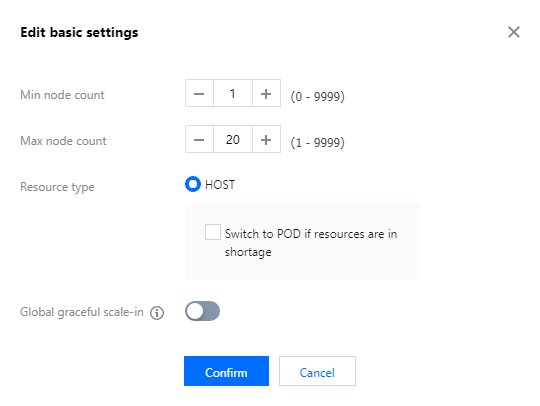
Min node count: The minimum number of elastic task nodes to be retained in the cluster after the auto scale-in policy is triggered.
Max node count: The maximum number of elastic task nodes to be retained in the cluster after the auto scale-out policy is triggered. The total number of nodes to be added based on one or more types of specifications cannot exceed the max node count.
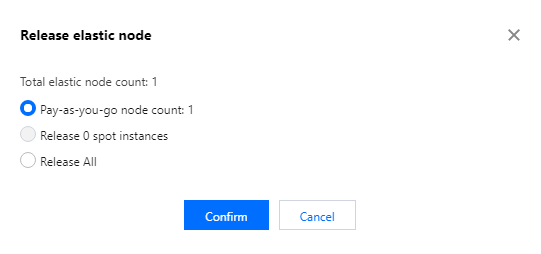
Release all: Clears all nodes added in an auto-scaling action with one click.
Release spot instances: Clears all spot instance nodes added in an auto-scaling action with one click.
Release pay-as-you-go instances: Clears all pay-as-you-go nodes added in an auto-scaling action with one click.
Global graceful scale-in: This feature is disabled by default. It applies to all scale-in rules and can be disabled for individual scale-in rules.
Resource type: HOST resources are billed on a pay-as-you-go or spot basis, whereas POD resources are billed on a pay-as-you-go basis and can only be used to assume the NodeManager role of YARN.
Caution
When you switch the resource type, the scaling specifications and node selection policy of the new resource type apply.
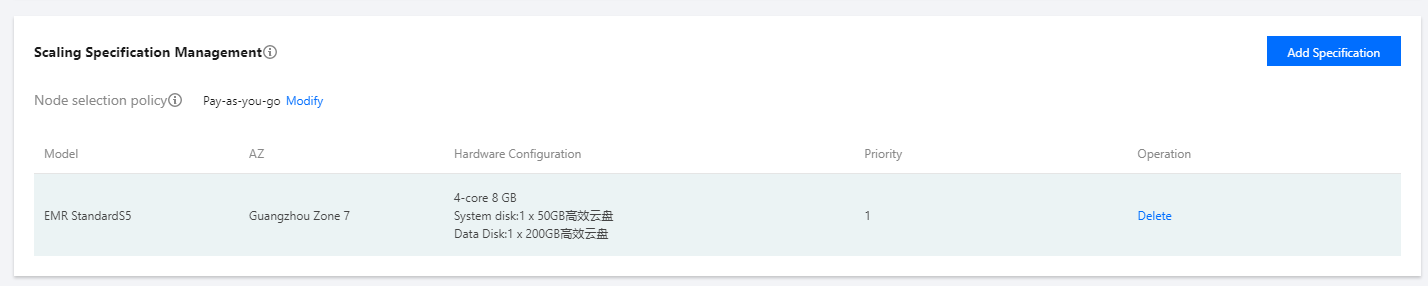
Scaling Specifications Management
Scaling specifications refer to node specifications for custom scaling. You can configure each cluster with up to five scaling specifications. When a scale-out rule is triggered, the scaling will be carried out according to the specification priority. When the high-priority specification has fewer resources than the number of resources to be added, the specification of the next priority will be used for supplement. In order to maintain the linear change of the cluster load, we recommend you keep the CPU and memory of the scaling specifications consistent.
Node selection policy: It can be Pay-as-you-go or Spot instances preferred. Pay-as-you-go: Only pay-as-you-go nodes are added to provide the required computing power when a scale-out rule is triggered.
Spot instances preferred: Spot instances will be preferred if they are available to provide the required computing power when a scale-out rule is triggered. Min proportion of pay-as-you-go nodes: The minimum proportion of pay-as-you-go nodes to the scale-out quantity.
Example:
If 10 nodes are to be added and the Min proportion of pay-as-you-go nodes is 20%, at least two pay-as-you-go nodes will be added when a scale-out rule is triggered, with the remaining eight being spot instance nodes. When spot instance nodes are insufficient, additional pay-as-you-go nodes will be added to make up the difference.
You can add, delete, change, and query the nodes in the scaling specifications, and adjust the priority of scaling specifications as needed.
The sequence of the five specifications for scale-out is as follows (same for pay-as-you-go and spot instances): When the resources are sufficient: 1 > 2 > 3 > 4 > 5.
Example:
If five preset specifications are available and the resources are sufficient, when a scale-out rule is triggered to add 10 nodes, 10 nodes with specification 1 will be added according to the sequence, and other preset specifications will not be selected.
If there are eight nodes with specification 1, four with specification 2, and three with specification 3, when a scale-out rule is triggered to add 13 nodes, eight nodes with specification 1, four with specification 2, and one with specification 3 will be added following the sequence.
When a resource specification is out of stock (take specification 2 as an example): 1 + 3 > 1 + 3 + 4 > 1 + 3 + 4 + 5.
Example:
If there are eight nodes with specification 1, no nodes with specification 2 (out of stock), and three nodes with specification 3, when a scale-out rule is triggered to add 10 nodes, eight nodes with specification 1 and two nodes with specification 3 will be added according to the sequence, while specification 2 will not be selected.
If there are eight nodes with specification 1 and nodes with other preset specifications are all out of stock, when a scale-out rule is triggered to add 10 nodes, eight nodes with specification 1 will be added, with the scale-out being partially successful.
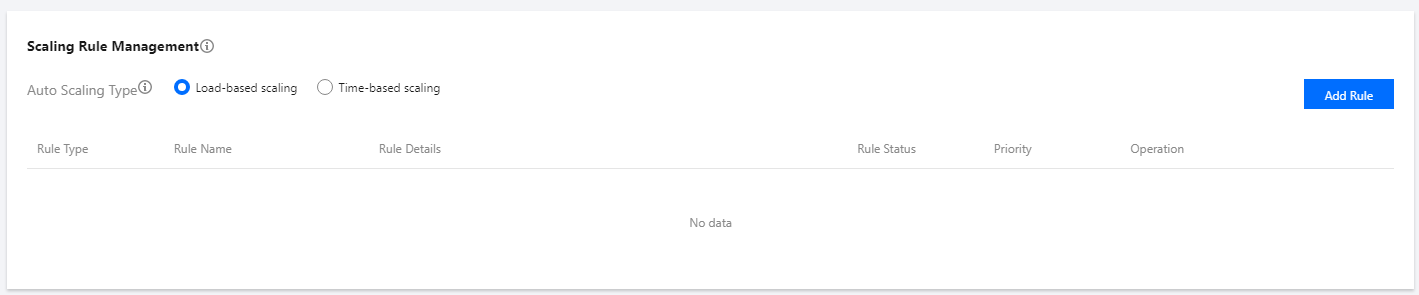
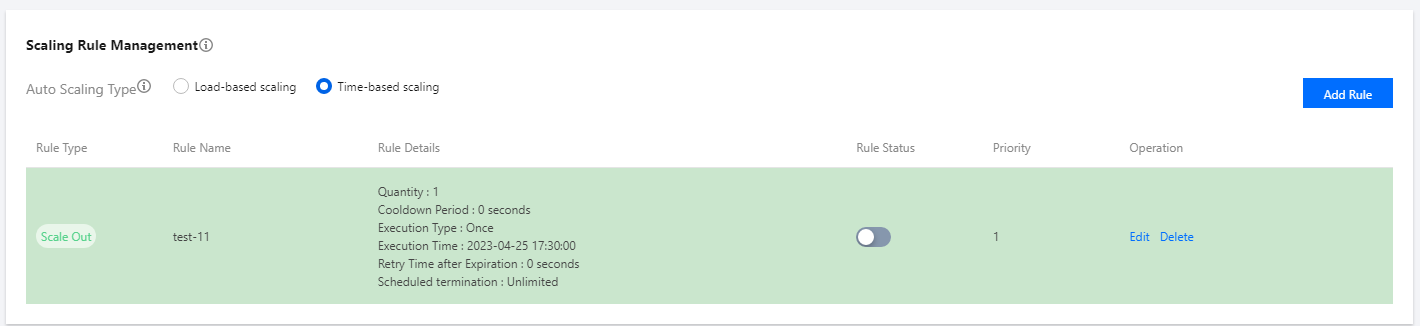
Scaling Rule Management
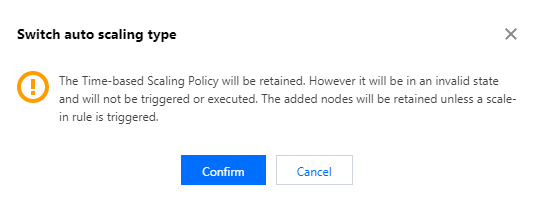
Scaling rules are business policies used to configure the trigger conditions of scaling actions and the number of nodes to be added or removed. Automatic scaling supports two types of policies: load-based scaling and time-based scaling. You can choose to use either type, but not both at the same time. When you switch the policies, the original scaling rules will be retained in an invalid state and will not be triggered. Those already added nodes will also be retained unless a scale-in rule is triggered. Each policy can be configured with up to 10 scaling rules. When two rules are triggered at the same time, the rule of the higher priority will be executed first.
To set a scaling rule, select Load-based scaling or Time-based scaling for Auto-scaling type in the Scaling rule management pane and click Add.
Load-based scaling
When it is impossible to accurately estimate the peaks and valleys of cluster computing, you can configure the scaling policy based on the load to ensure that important jobs are completed on time. The load is mainly based on the preset YARN metric statistics rules and the task nodes are automatically adjusted when the preset conditions are triggered.
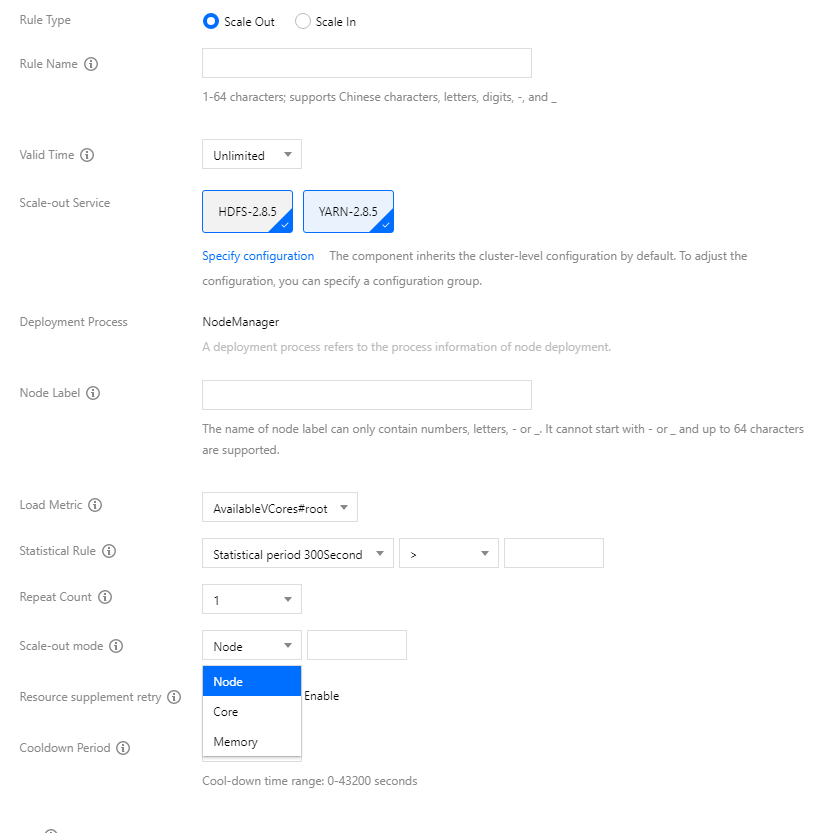
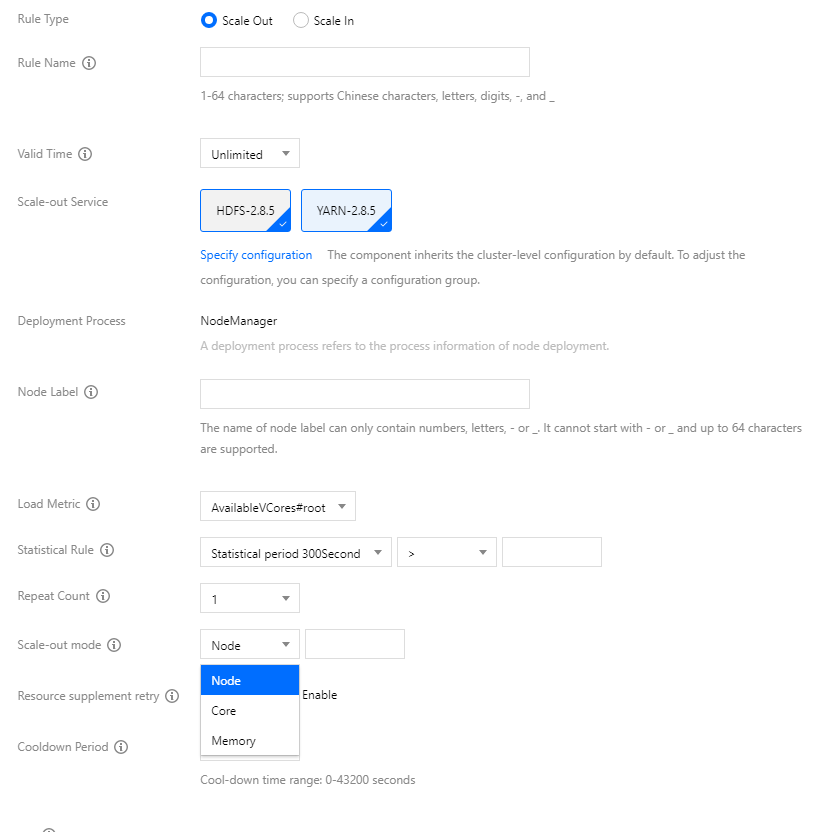
To add a load-based scaling rule, select Load-based scaling as the Auto-scaling type, click Add, and configure the following fields:
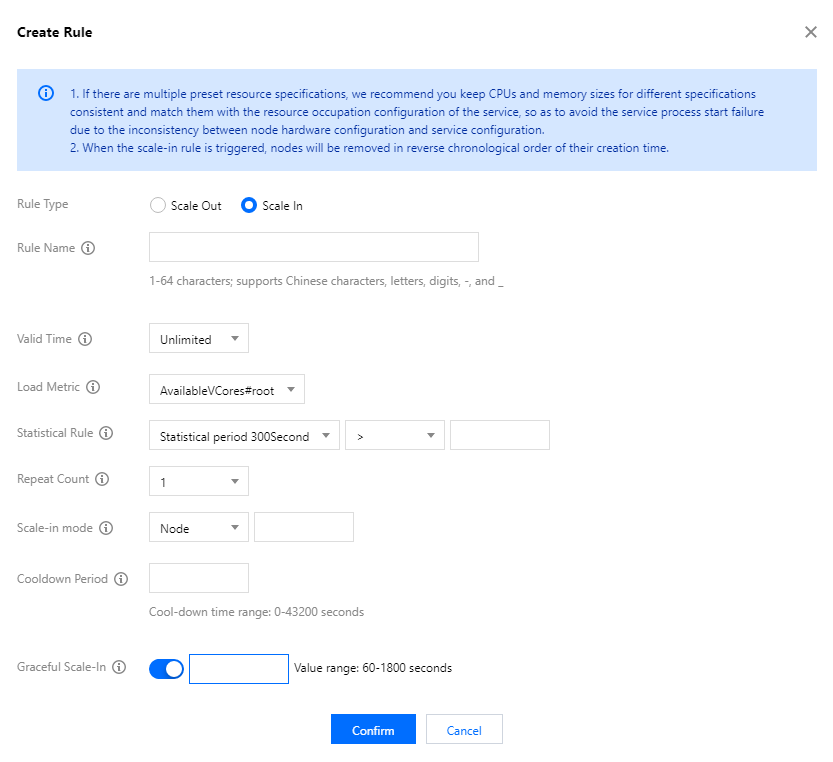
Rule status: Used to mark whether the rule is enabled. The default status of a rule is "Enabled". When you don't want a rule to be executed but still want to retain it, you can set the rule status to "Disabled".
Rule name: The name of the scaling rule. The scaling rule names in the same cluster must be unique (including scale-out and scale-in rules).
Validity: The load-based scaling rule can be triggered only within the validity. Unlimited is selected by default, and you can customize this field.
Target service: By default, the selected component will inherit the cluster-level configuration and fall into the default configuration group for that node type. You can also set the configuration of the target component through the Specify configuration parameter.
Node label: This field is empty by default, and the added nodes will be assigned the default label. If you have set a label, resources will be added to the node with this label.
Load metric: YARN load metric. You can set the condition rule for triggering the threshold based on the load metric selected here.
Category
Dimension
EMR Auto-Scaling Metric
Description
AvailableVCores
root
AvailableVCores#root
Number of virtual cores available in the root queue
root.default
AvailableVCores#root.default
Number of virtual cores available in the root.default queue
Custom subqueue
Example: AvailableVCores#root.test
Number of virtual cores available in the root.test queue
PendingVCores
root
PendingVCores#root
Number of virtual cores waiting to be available in the root queue
root.default
PendingVCores#root.default
Number of virtual cores waiting to be available in the root.default queue
Custom subqueue
Example: PendingVCores#root.test
Number of virtual cores waiting to be available in the root.test queue
AvailableMB
root
AvailableMB#root
Amount of memory available in the root queue, in MB
root.default
AvailableMB#root.default
Amount of memory available in the root.default queue, in MB
Custom subqueue
Example: AvailableMB#root.test
Amount of memory available in the root.test queue, in MB
PendingMB
root
PendingMB#root
Amount of memory waiting to be available in the root queue, in MB
root.default
PendingMB#root.default
Amount of memory waiting to be available in the root.default queue, in MB
Custom subqueue
Example: PendingMB#root.test
Amount of memory waiting to be available in the root.test queue, in MB
AvailableMemPercentage
Clusters
AvailableMemPercentage
Available memory in percentages
ContainerPendingRatio
Clusters
ContainerPendingRatio
Ratio of the number of containers to be allocated to the number of allocated containers
AppsRunning
root
AppsRunning#root
Number of running tasks in the root queue
root.default
AppsRunning#root.default
Number of running tasks in the root.default queue
Custom subqueue
Example: AppsRunning#root.test
Number of running tasks in the root.test queue
AppsPending
root
AppsPending#root
Number of pending tasks in the root queue
root.default
AppsPending#root.default
Number of pending tasks in the root.default queue
Custom subqueue
Example: AppsPending#root.test
Number of pending tasks in the root.test queue
PendingContainers
root
PendingContainers#root
Number of containers to be allocated in the root queue
root.default
PendingContainers#root.default
Number of containers to be allocated in the root.default queue
Custom subqueue
Example: PendingContainers#root.test
Number of containers to be allocated in the root.test queue
AllocatedMB
root
AllocatedMB#root
Amount of memory allocated in the root queue
root.default
AllocatedMB#root.default
Amount of memory allocated in the root.default queue
Custom subqueue
Example: AllocatedMB#root.test
Amount of memory allocated in the root.test queue
AllocatedMB
root
AllocatedVCores#root
Number of virtual cores allocated in the root queue
root.default
AllocatedVCores#root.default
Number of virtual cores allocated in the root.default queue
Custom subqueue
Example: AllocatedVCores#root.test
Number of virtual cores allocated in the root.test queue
ReservedVCores
root
ReservedVCores#root
Number of virtual cores reserved in the root queue
root.default
ReservedVCores#root.default
Number of virtual cores reserved in the root.default queue
Custom subqueue
Example: ReservedVCores#root.test
Number of virtual cores reserved in the root.test queue
AllocatedContainers
root
AllocatedContainers#root
Number of containers allocated in the root queue
root.default
AllocatedContainers#root.default
Number of containers allocated in the root.default queue
Custom subqueue
Example: AllocatedContainers#root.test
Number of containers allocated in the root.test queue
ReservedMB
root
ReservedMB#root
Amount of memory reserved in the root queue
root.default
ReservedMB#root.default
Amount of memory reserved in the root.default queue
Custom subqueue
Example: ReservedMB#root.test
Amount of memory reserved in the root.test queue
AppsKilled
root
AppsKilled#root
Number of tasks terminated in the root queue
root.default
AppsKilled#root.default
Number of tasks terminated in the root.default queue
Custom subqueue
Example: AppsKilled#root.test
Number of tasks terminated in the root.test queue
AppsFailed
root
AppsFailed#root
Number of tasks failed in the root queue
root.default
AppsFailed#root.default
Number of tasks failed in the root.default queue
Custom subqueue
Example: AppsFailed#root.test
Number of tasks failed in the root.test queue
AppsCompleted
root
AppsCompleted#root
Number of tasks completed in the root queue
root.default
AppsCompleted#root.default
Number of tasks completed in the root.default queue
Custom subqueue
Example: AppsCompleted#root.test
Number of tasks completed in the root.test queue
AppsSubmitted
root
AppsSubmitted#root
Number of tasks submitted in the root queue
root.default
AppsSubmitted#root.default
Number of tasks submitted in the root.default queue
Custom subqueue
Example: AppsSubmitted#root.test
Number of tasks submitted in the root.test queue
AvailableVCoresPercentage
Clusters
AvailableVCoresPercentage
Percentage of virtual cores available in the cluster
MemPendingRatio
root
MemPendingRatio#root
Percentage of memory waiting to be available in the root queue
root.default
MemPendingRatio#root.default
Percentage of memory waiting to be available in the root.default queue
Custom subqueue
Example: MemPendingRatio#root.test
Percentage of memory waiting to be available in the root.default queue
Statistical rule: The cluster load metric selected by the user is triggered once when the threshold is reached according to the selected aggregate dimension (average value) within a specific statistical period.
Statistical period: The statistical duration of the metric. Currently, three statistical periods are supported: 300s, 600s, and 900s.
Repeat count: The number of times that the threshold of the aggregated load metric is reached. When the repeat count is reached, the cluster will be automatically scaled.
Scale-out mode: You can select Node, Memory, or Core, and their values must be a positive integer.
In case of scale-out in the core or memory mode, the quantity of nodes guaranteeing the maximum computing power will be added.
Example:
1. In the core mode, if 10 cores are to be added, but the specification for auto-scaling is to add 8-core nodes in order of priority, then two 8-core nodes will be added when the rule is triggered.
2. In the memory mode, if 20 GB memory is to be added, but the specification for auto-scaling is to add 16 GB memory nodes in order of priority, then two 16 GB MEM nodes will be added when the rule is triggered.
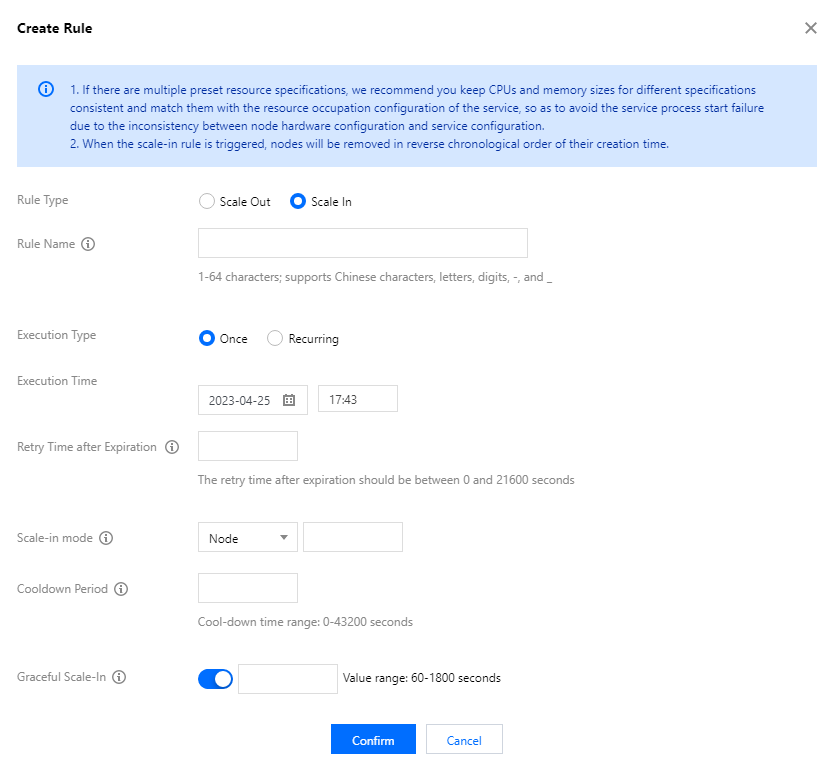
Scale-in mode: You can select Node, Memory, or Core, and their values must be a positive integer.
In case of scale-in in the core or memory mode, a minimum quantity of nodes will be released in reverse chronological order while keeping the business running properly, with at least one node released.
Example:
1. In the core mode, if 20 cores are to be released, and the cluster has three 8-core 16 GB MEM and two 4-core 8 GB MEM elastic nodes in reverse chronological order when a scale-in rule is triggered, then two 8-core 16 GB MEM nodes will be released.
2. In the memory mode, if 30 GB memory is to be released, and the cluster has three 8-core 16 GB MEM and two 4-core 8 GB MEM elastic nodes in reverse chronological order when a scale-in rule is triggered, then one 8-core 16 GB MEM node will be released.
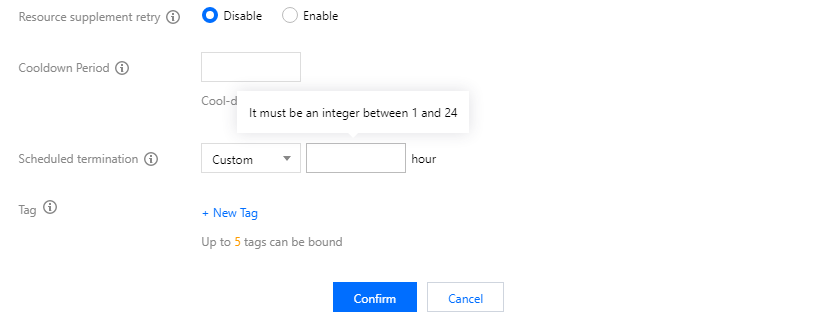
Resource supplement retry: When auto scale-out is performed during peak hours, the number of nodes added may be less than the target number due to the lack of resources. In such a case, if the resource supplement retry policy is enabled, the system will automatically retry to request resources when there are sufficient resources of the set scaling specifications until the target number is reached or approximated. If frequently encountering this situation, you can enable this feature. Please note that retry may extend the time of auto scale-out and this policy change may affect your business.
Cooldown period: The interval (60s to 43200s) before carrying out the next auto-scaling action after the rule is successfully executed.
Graceful scale-in: After this feature is enabled, if the scale-in action is triggered when a node is executing tasks, the node will not be released immediately. Instead, the scale-in action will be executed after the tasks are completed. However, the scale-in action will still be executed if the tasks are not completed within the specified time.
Time-based scaling
If there are obvious peaks and valleys in your cluster computing workload during a certain period, you can configure time-based scaling policies to ensure that important jobs are completed on time. Time-based scaling policies allows you to automatically add or remove task nodes daily, weekly, or monthly during a set time period.
To add a time-based scaling rule, select Time-based scaling as the Auto-scaling type, click Add, and configure the following fields:
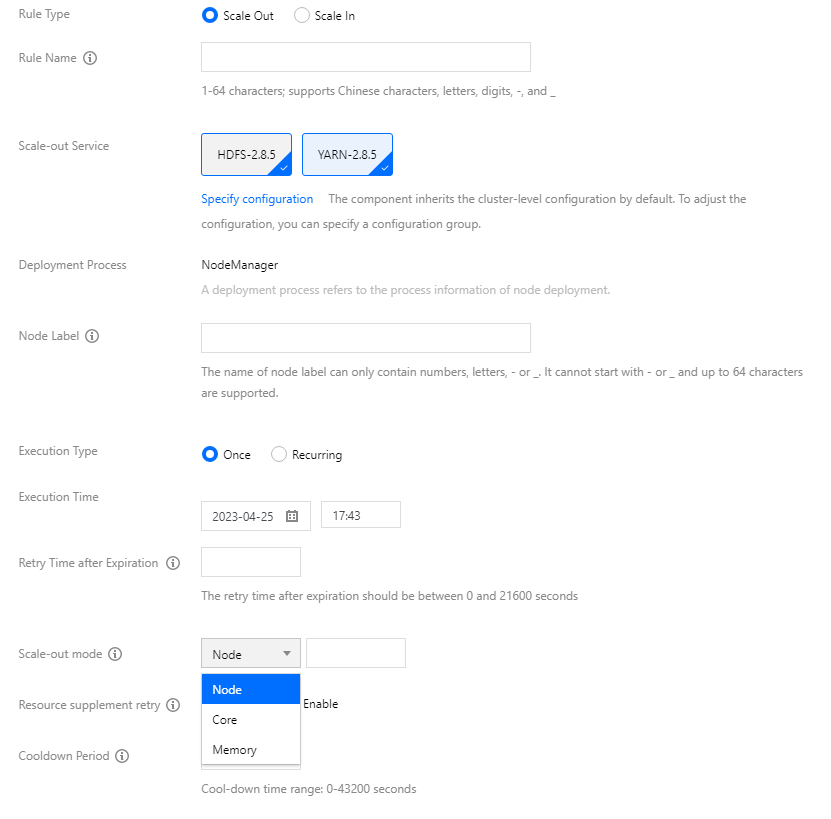
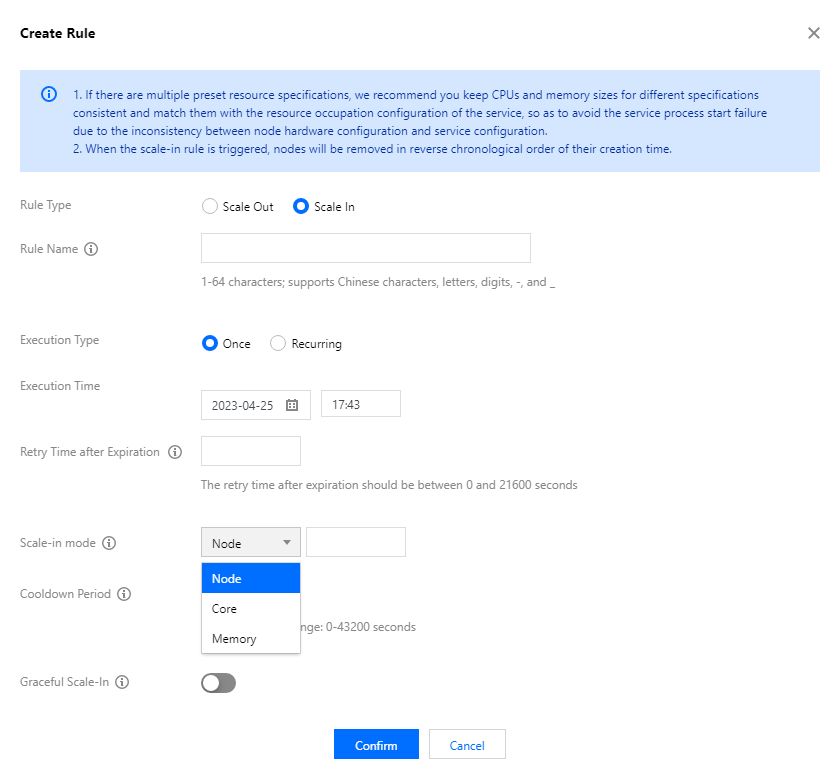
Rule name: The name of the scaling rule. The scaling rule names in the same cluster must be unique (including scale-out and scale-in rules).
Target service: By default, the selected component will inherit the cluster-level configuration and fall into the default configuration group for that node type. You can also set the configuration of the target component through the Specify configuration parameter.
Once: Triggers a scaling action once at a specific time, accurate to the minute.
Recurring: Triggers a scaling action daily, weekly, or monthly at a specific time or time period.
Retry period: Auto-scaling may not be executed for various reasons at the specified time. After you set the retry period, the system will try to execute the scaling at a certain interval within the period until it is executed when the conditions are met.
Rule expiration: The time-based scaling rule is valid until the end of the date specified here.
Scale-out mode: You can select Node, Memory, or Core, and their values must be an integer other than 0.
In case of scale-out in the core or memory mode, the quantity of nodes guaranteeing the maximum computing power will be added.
Example:
1. In the core mode, if 10 cores are to be added, but the specification for auto-scaling is to add 8-core nodes in order of priority, then two 8-core nodes will be added when the rule is triggered.
2. In the memory mode, if 20 GB memory is to be added, but the specification for auto-scaling is to add 16 GB memory nodes in order of priority, then two 16 GB MEM nodes will be added when the rule is triggered.
Scale-in mode: You can select Node, Memory, or Core, and their values must be an integer other than 0.
In case of scale-in in the core or memory mode, a minimum quantity of nodes will be released in reverse chronological order while keeping the business running properly, with at least one node released.
Example:
1. In the core mode, if 20 cores are to be released, and the cluster has three 8-core 16 GB MEM and two 4-core 8 GB MEM elastic nodes in reverse chronological order when a scale-in rule is triggered, then two 8-core 16 GB MEM nodes will be released.
2. In the memory mode, if 30 GB memory is to be released, and the cluster has three 8-core 16 GB MEM and two 4-core 8 GB MEM elastic nodes in reverse chronological order when a scale-in rule is triggered, then one 8-core 16 GB MEM node will be released.
Resource supplement retry: When auto scale-out is performed during peak hours, the number of nodes added may be less than the target number due to the lack of resources. In such a case, if the resource supplement retry policy is enabled, the system will automatically retry to request resources when there are sufficient resources of the set scaling specifications until the target number is reached or approximated. If frequently encountering this situation, you can enable this feature. Please note that retry may extend the time of auto scale-out and this policy change may affect your business.
Cooldown period: The interval (60s to 43200s) before carrying out the next auto-scaling action after the rule is successfully executed.
Scheduled termination: You can specify the usage duration for the added nodes, so that the nodes will not be affected when a scale-in rule is triggered. Unlimited is selected by default. You can enter an integer between 1–24 (in hours) here.
Use cases:
This feature is suitable when you need more computing resources for a specified period of time (within one day) and the resources should not be affected by other scale-in rules.
Rule status: Used to mark whether the rule is enabled. The default status of a rule is "Enabled". When you don't want a rule to be executed but still want to retain it, you can set the rule status to "Disabled".
Graceful scale-in: After this feature is enabled, if the scale-in action is triggered when a node is executing tasks, the node will not be released immediately. Instead, the scale-in action will be executed after the tasks are completed. However, the scale-in action will still be executed if the tasks are not completed within the specified time.