When consuming data within a consumer group, the server manages the consumption tasks for all consumers within the group. It automatically balances these tasks based on the correlation between the number of topic partitions and the number of consumers. Moreover, it records the consumption progress for each partition in the topic to guarantee that different consumers can consume data without any duplication. The detailed process of consumption within a consumer group proceeds as follows:
1. Create a consumer group.
2. Every consumer periodically sends heartbeats to the server.
3. The consumer group automatically assigns topic partitions to consumers according to the load balancing situation of the topic partitions.
4. Consumers retrieve the partition offsets and consume the data according to the list of allocated partitions.
5. Consumers periodically update their consumption progress for each partition to the consumer group, facilitating the next round of task allocation by the group.
6. Repeat steps 2 through 6 until consumption is completed.
Consumption Balancing
The consumer group will dynamically adjust the consumption tasks of each consumer according to the number of active consumers and topic partitions to ensure balanced consumption. At the same time, consumers can save the consumption progress in each topic partition to ensure that they can continue to consume data after fault recovery and avoid repeated consumption.
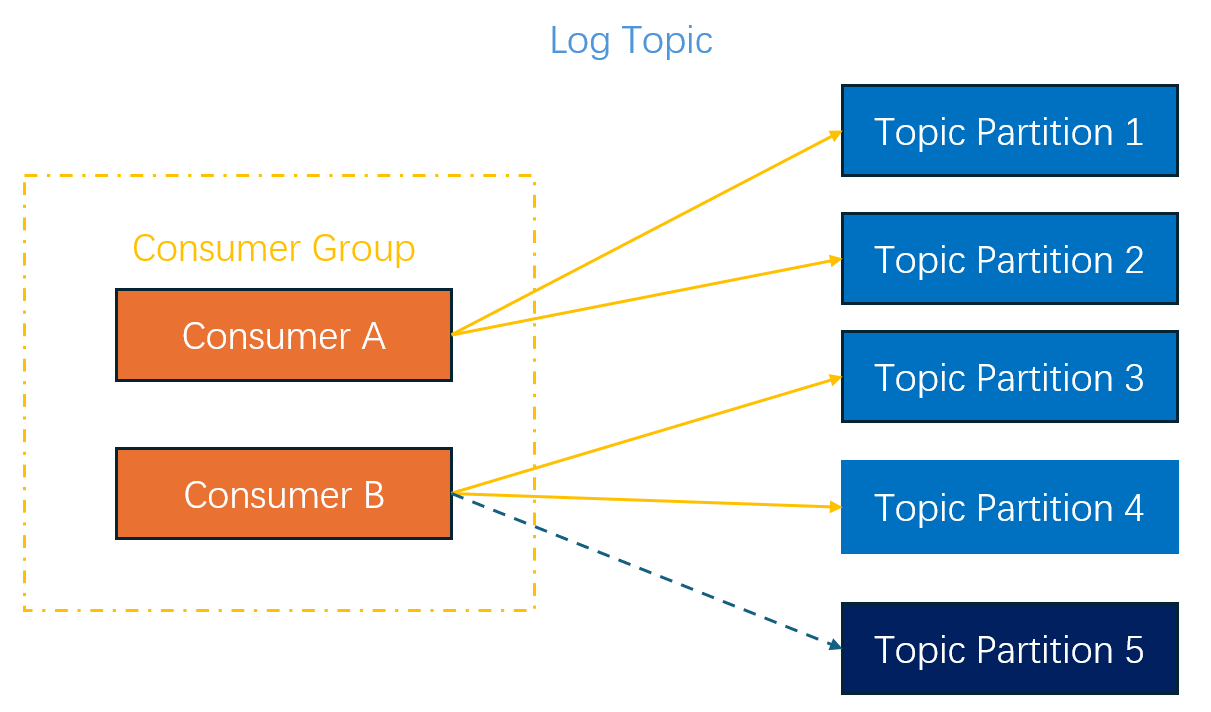
Example 1: Topic Partition Change
For example, a log topic has two consumers. Consumer A consumes data in partitions 1 and 2, and consumer B in partitions 3 and 4. After partition 5 is added through partition splitting, the consumer group will automatically allocate partition 5 to consumer B for consumption, as shown in the figure below:
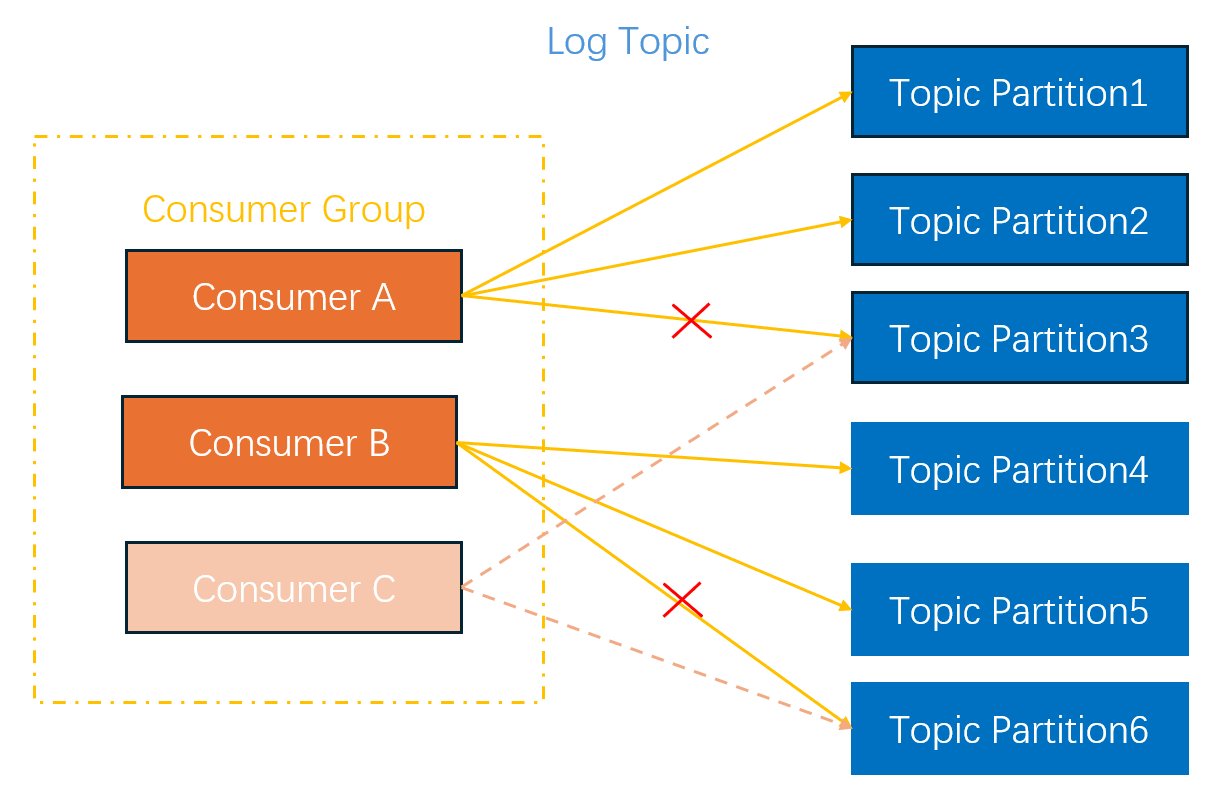
Example 2: Consumer Change
For example, a log topic has two consumers. Consumer A consumes data in partitions 1, 2, and 3, and consumer B in partitions 4, 5, and 6. To ensure that the consumption speed is equal to the generation speed, consumer C is added. The consumer group will reallocate partitions. Then, partitions 3 and 6 will be allocated to consumer C for consumption, as shown in the figure below:
Consumption Demo (Python)
Note:
For the complete Demo, see tencentcloud-cls-sdk-python, It is recommended to use Python version 3.5 or above for data consumption.
The usage and instructions of the Demo are as follows:
Topic's region. For example, ap-beijing, ap-guangzhou, ap-shanghai. For more details, see Regions and Access Domains.
-
Supported regions: Beijing, Shanghai, Guangzhou, Nanjing, Hong Kong (China), Tokyo, Eastern United States, Singapore, and Frankfurt.
logset_id
Logset ID. Only one logset is supported.
-
-
topic_ids
Log topic ID. For multiple topics, use , to separate.
-
-
consumer_group_name
Consumer Group Name
-
-
internal
Private network: TRUE
Public network: FALSE
Note:
For private network/public network read traffic cost, see Product Pricing.
FALSE
TRUE/FALSE
consumer_name
Consumer name. Within the same consumer group, consumer names must be unique.
-
A string consisting of 0-9, aA-zZ, '-', '_', '.'.
heartbeat_interval
The interval of heartbeats. If consumers fail to report a heartbeat for two intervals, they will be considered offline.
20
0-30 minutes
data_fetch_interval
The interval of consumer data pulling. Cannot be less than 1 second.
2
-
offset_start_time
The start time for data pulling. The string type of unix Timestamp , with second-level precision. For example, 1711607794. It can also be directly configured as "begin" and "end".
begin: The earliest data within the log topic lifetime.
end: The latest data within the log topic lifetime.
"end"
"begin"/"end"/unix Timestamp
max_fetch_log_group_size
The data size for a consumer in a single pulling. Defaults to 2 M and up to 10 M.
2097152
2M - 10M
offset_end_time
The end time for data pulling. Supports a string-type unix Timestamp , with second-level precision. For example, 1711607794. Not filling this field represents continuous pulling.
-
-
defsample_consumer_group():
# CLS Access Point. Fill in according to the actual situation.

 예
예
 아니오
아니오
문제 해결에 도움이 되었나요?