You can consume a log topic as a Kafka topic over the Kafka protocol. In practice, collected log data can be consumed through the Kafka Consumer or Kafka connectors provided by open-source communities, such as flink-connector-kafka and Kafka-connector-jdbc, to downstream big data components or data warehouses, including Spark, HDFS, Hive, Flink, and Tencent Cloud products like Oceanus and EMR.
This document provides demos for how to consume log topics with Flink and Flume.
Prerequisites
You have activated CLS, created a logset and a log topic, and collected log data.
Make sure that the current account has the permission to enable Consumption over Kafka. For more information, see Access Policy Templates.
Use Limits
Supported Kafka protocol versions: 1.1.1 and earlier.
Supported compression modes: Snappy and LZ4.
User authentication mode: SASL_PLAINTEXT.
You can consume only current but not historical data.
Data in topics are retained for two hours.
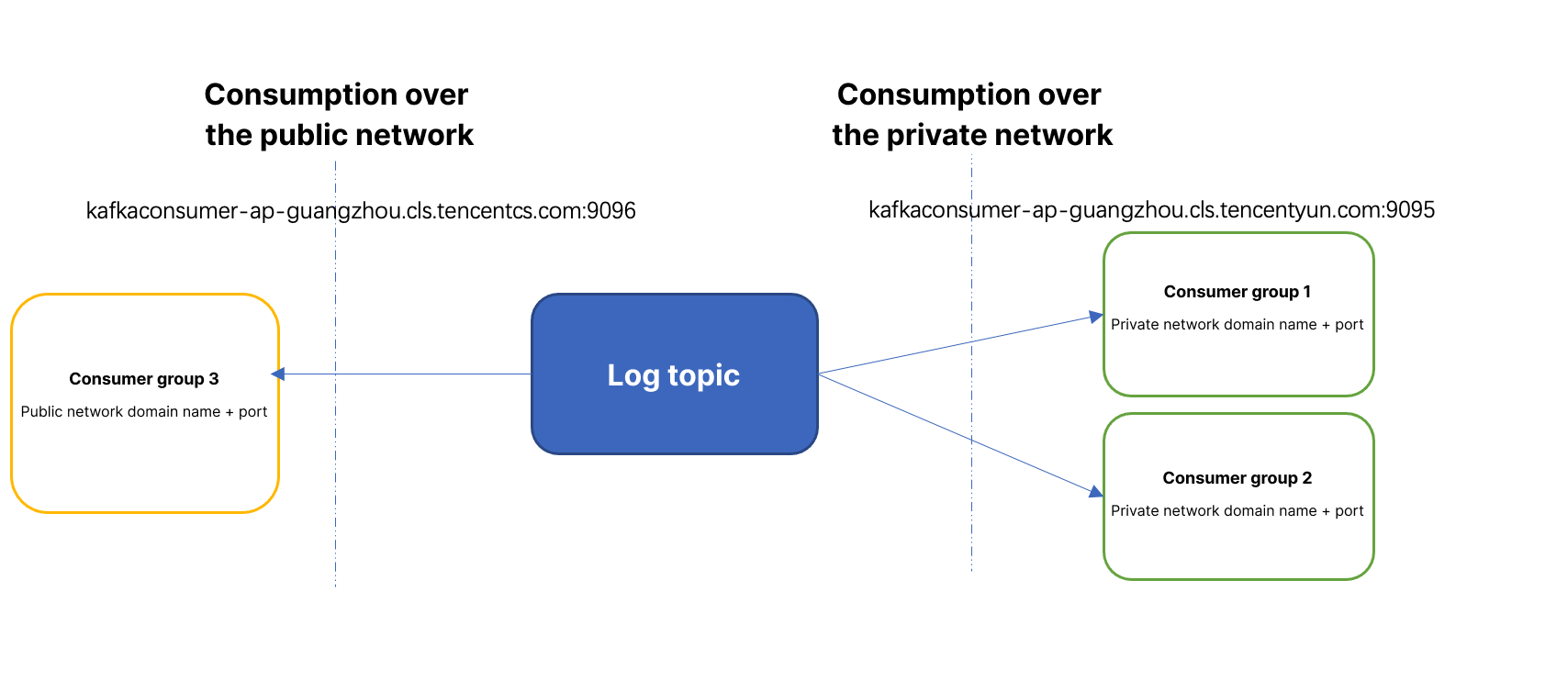
Consumption over private or public network
Consumption over the private network: A private network domain name is used to consume logs, and the traffic price is 0.032 USD/GB. If your raw log is 100 GB and you choose Snappy for compression, around 50 GB will be billable, and the private network read traffic fees will be 50 GB * 0.032 USD/GB = 1.6 USD. In general, you can consume logs over the private network if your consumer and log topic are in the same VPC or region.
Consumption over the public network: A public network domain name is used to consume logs, and the traffic price is 0.141 USD/GB. If your raw log is 100 GB and you choose Snappy for compression, around 50 GB will be billable, and the public network read traffic fees will be 50 GB * 0.141 USD/GB = 7.05 USD. In general, you need to consume logs over the public network if your consumer and log topic are in different VPCs or regions.
Directions
1. Log in to the CLS console and select Log Topic on the left sidebar.
2. On the Log Topic page, click the target Log Topic ID/Name to enter the log topic management page.
3. On the log topic management page, click the Consumption over Kafka tab.
4. Click Edit on the right, set Current Status to Enable, and click OK.
5. The console displays the topic and host+port information, which can be copied for constructing the consumer SDK.
Consumer Parameter Description
The parameters of the consumer over Kafka are described as follows:
Parameter
Description
User authentication mode
Currently, only SASL_PLAINTEXT is supported.
hosts
Consumption over the private network: `kafkaconsumer-${region}.cls.tencentyun.com:9095`.Consumption over the public network: `kafkaconsumer-${region}.cls.tencentcs.com:9096`. For more information, see Available Regions.
topic
Topic name provided in the CLS console for consumption over Kafka, which can be copied by clicking the button next to it, such as `XXXXXX-633a268c-XXXX-4a4c-XXXX-7a9a1a7baXXXX`.
username
Configure it as `${logsetID}`, i.e., logset ID, such as `0f8e4b82-8adb-47b1-XXXX-XXXXXXXXXXXX`. You can copy the logset ID in the log topic list.
password
Configure it as ${SecretId}#${SecretKey}, such as `XXXXXXXXXXXXXX#YYYYYYYY`. Log in to the CAM console and click Access Key on the left sidebar to get the key information. You can use either the API key or project key. We recommend that you use a sub-account key and follow the principle of least privilege when authorizing a sub-account, that is, configure the minimum permission for `action` and `resource` in the access policy of the sub-account.
Note:
Be sure not to omit the ; after the ${SecretId}#${SecretKey} of the jaas.config in the following sample code; otherwise, an error will be reported.
SDK for Python
import uuid
from kafka import KafkaConsumer,TopicPartition,OffsetAndMetadata
consumer = KafkaConsumer(
#Topic name provided in the CLS console for consumption over Kafka, which can be copied in the console, such as `XXXXXX-633a268c-XXXX-4a4c-XXXX-7a9a1a7baXXXX`.
'Your consumption topic',
group_id = uuid.uuid4().hex,
auto_offset_reset='earliest',
# Service address + port (9096 for the public network and 9095 for the private network). In this example, consumption is performed over the private network. Enter this field accordingly.
# The username is the logset ID, such as `ca5cXXXXdd2e-4ac0af12-92d4b677d2c6`.
sasl_plain_username ="${logsetID}",
#The password is a string of your `SecretId#SecretKey`, such as `AKIDWrwkHYYHjvqhz1mHVS8YhXXXX#XXXXuXtymIXT0Lac`. Note that `#` is required. We recommend that you use a sub-account key and follow the principle of least privilege when authorizing a sub-account, that is, configure the minimum permission for `action` and `resource` in the access policy of the sub-account.
`partition_id` BIGINT METADATA FROM 'partition' VIRTUAL, -- Kafka partition
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector'='kafka',
#Topic name provided in the CLS console for consumption over Kafka, which can be copied in the console, such as `XXXXXX-633a268c-XXXX-4a4c-XXXX-7a9a1a7baXXXX`.
'topic'='Your consumption topic',
# Service address + port (9096 for the public network and 9095 for the private network). In this example, consumption is performed over the private network. Enter this field accordingly.
'properties.group.id'='The name of your consumer group',
'scan.startup.mode'='earliest-offset',
'format'='json',
'json.fail-on-missing-field'='false',
'json.ignore-parse-errors'='true' ,
# The username is the logset ID, such as `ca5cXXXXdd2e-4ac0af12-92d4b677d2c6`.
#The password is a string of your `SecretId#SecretKey`, such as `AKIDWrwkHYYHjvqhz1mHVS8YhXXXX#XXXXuXtymIXT0Lac`. Note that `#` is required. We recommend that you use a sub-account key and follow the principle of least privilege when authorizing a sub-account, that is, configure the minimum permission for `action` and `resource` in the access policy of the sub-account. Be sure not to omit the `;` at the end of the `jaas.config`; otherwise, an error will be reported.
#Topic name provided in the CLS console for consumption over Kafka, which can be copied in the console, such as `XXXXXX-633a268c-XXXX-4a4c-XXXX-7a9a1a7baXXXX`.
'topic'='Your consumption topic',
# Service address + port (9096 for the public network and 9095 for the private network). In this example, consumption is performed over the private network. Enter this field accordingly.
'properties.group.id'='The name of your consumer group',
'scan.startup.mode'='earliest-offset',
'format'='json',
'json.fail-on-missing-field'='false',
'json.ignore-parse-errors'='true',
# The username is the logset ID, such as `ca5cXXXXdd2e-4ac0af12-92d4b677d2c6`.
#The password is a string of your `SecretId#SecretKey`, such as `AKIDWrwkHYYHjvqhz1mHVS8YhXXXX#XXXXuXtymIXT0Lac`. Note that `#` is required. We recommend that you use a sub-account key and follow the principle of least privilege when authorizing a sub-account, that is, configure the minimum permission for `action` and `resource` in the access policy of the sub-account. Be sure not to omit the `;` at the end of the `jaas.config`; otherwise, an error will be reported.
# Service address + port (9096 for the public network and 9095 for the private network). In this example, consumption is performed over the private network. Enter this field accordingly.
#Topic name provided in the CLS console for consumption over Kafka, which can be copied in the console, such as `XXXXXX-633a268c-XXXX-4a4c-XXXX-7a9a1a7baXXXX`.
a1.sources.source_kafka.kafka.topics = Your consumption topic
#Replace it with the name of your consumer group
a1.sources.source_kafka.kafka.consumer.group.id = The name of your consumer group
# The username is the logset ID, such as `ca5cXXXXdd2e-4ac0af12-92d4b677d2c6`.
#The password is a string of your `SecretId#SecretKey`, such as `AKIDWrwkHYYHjvqhz1mHVS8YhXXXX#XXXXuXtymIXT0Lac`. Note that `#` is required. We recommend that you use a sub-account key and follow the principle of least privilege when authorizing a sub-account, that is, configure the minimum permission for `action` and `resource` in the access policy of the sub-account. Be sure not to omit the `;` at the end of the `jaas.config`; otherwise, an error will be reported.

 예
예
 아니오
아니오
문제 해결에 도움이 되었나요?