- Release Notes and Announcements
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Instance Management
- Creating Instance
- Naming with Consecutive Numeric Suffixes or Designated Pattern String
- Viewing Instance
- Upgrading Instance
- Downgrading Instance Configuration
- Terminating/Returning Instances
- Change from Pay-as-You-Go to Monthly Subscription
- Upgrading Instance Version
- Adding Routing Policy
- Public Network Bandwidth Management
- Connecting to Prometheus
- AZ Migration
- Setting Maintenance Time
- Setting Message Size
- Topic Management
- Consumer Group
- Monitoring and Alarms
- Smart Ops
- Permission Management
- Tag Management
- Querying Message
- Event Center
- Migration to Cloud
- Data Compression
- Instance Management
- CKafka Connector
- Practical Tutorial
- Practical Tutorial of CKafka Client
- Connector Practical Tutorial
- Connecting Flink to CKafka
- Connecting Schema Registry to CKafka
- Connecting Spark Streaming to CKafka
- Connecting Flume to CKafka
- Connecting Kafka Connect to CKafka
- Connecting Storm to CKafka
- Connecting Logstash to CKafka
- Connecting Filebeat to CKafka
- Multi-AZ Deployment
- Log Access
- Replacing Supportive Route (Old)
- Practice Tutorial for Cluster Bandwidth in High CPU Utilization Scenarios
- Practice Tutorial for Cluster Capacity Planning
- Troubleshooting
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- DescribeTopicProduceConnection
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK Documentation
- General References
- Conducting Production and Consumption Pressure Testing on CKafka
- Configuration Guide for Common Parameters in CKafka
- Connecting to Legacy Self-Built Kafka
- Suggestions for CKafka Version Selection
- CKafka Data Reliability Description
- Connector
- FAQs
- Service Level Agreement
- Contact Us
- Glossary
- Release Notes and Announcements
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Instance Management
- Creating Instance
- Naming with Consecutive Numeric Suffixes or Designated Pattern String
- Viewing Instance
- Upgrading Instance
- Downgrading Instance Configuration
- Terminating/Returning Instances
- Change from Pay-as-You-Go to Monthly Subscription
- Upgrading Instance Version
- Adding Routing Policy
- Public Network Bandwidth Management
- Connecting to Prometheus
- AZ Migration
- Setting Maintenance Time
- Setting Message Size
- Topic Management
- Consumer Group
- Monitoring and Alarms
- Smart Ops
- Permission Management
- Tag Management
- Querying Message
- Event Center
- Migration to Cloud
- Data Compression
- Instance Management
- CKafka Connector
- Practical Tutorial
- Practical Tutorial of CKafka Client
- Connector Practical Tutorial
- Connecting Flink to CKafka
- Connecting Schema Registry to CKafka
- Connecting Spark Streaming to CKafka
- Connecting Flume to CKafka
- Connecting Kafka Connect to CKafka
- Connecting Storm to CKafka
- Connecting Logstash to CKafka
- Connecting Filebeat to CKafka
- Multi-AZ Deployment
- Log Access
- Replacing Supportive Route (Old)
- Practice Tutorial for Cluster Bandwidth in High CPU Utilization Scenarios
- Practice Tutorial for Cluster Capacity Planning
- Troubleshooting
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- DescribeTopicProduceConnection
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK Documentation
- General References
- Conducting Production and Consumption Pressure Testing on CKafka
- Configuration Guide for Common Parameters in CKafka
- Connecting to Legacy Self-Built Kafka
- Suggestions for CKafka Version Selection
- CKafka Data Reliability Description
- Connector
- FAQs
- Service Level Agreement
- Contact Us
- Glossary
Logstash is an open-source log processing tool that can be used to collect data from multiple sources, filters it, and then stores it for other uses.
Logstash is highly flexible and has powerful syntax analysis capabilities. With a variety of plugins, it supports multiple types of inputs and outputs. In addition, as a horizontally scalable data pipeline, it has powerful log collection and retrieval features that work with Elasticsearch and Kibana.
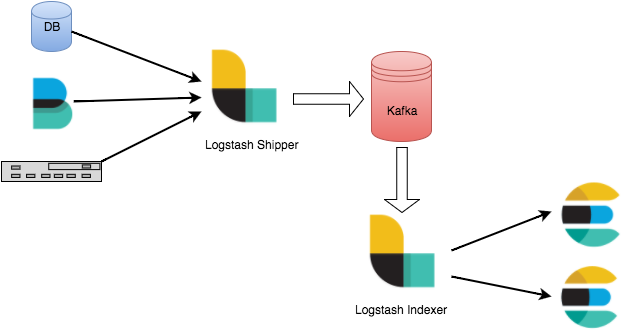
How Logstash Works
The Logstash data processing pipeline can be divided into three stages: inputs → filters → outputs.
1. Inputs: Collect data from multiple sources like file, syslog, redis, and beats.
2. Filters: Modify and filter the collected data. Filters are intermediate processing components in the Logstash data pipeline. They can modify events based on specific conditions. Some commonly used filters are grok, mutate, drop, and clone.
3. Outputs: Transfer the processed data to other destinations. An event can be transferred to multiple outputs, and the event ends when the transfer is completed. Elasticsearch is the most commonly-used output.
In addition, Logstash supports encoding and decoding data, so you can specify data formats on the input and output ends.
Strengths of Connecting Logstash to Kafka
Data can be asynchronously processed to prevent traffic spikes.
Components are decoupled, so when an exception occurs in Elasticsearch, the upstream work will not be affected.
Note:
Logstash consumes resources when processing data. If you deploy Logstash on a production server, the performance of the server may be affected.
Directions
Preparations
Download and install Logstash as instructed in Installing Logstash.
Download and install JDK 8 as instructed in Java SE Development Kit 8u341.
Create a CKafka instance as instructed in Creating Instance.
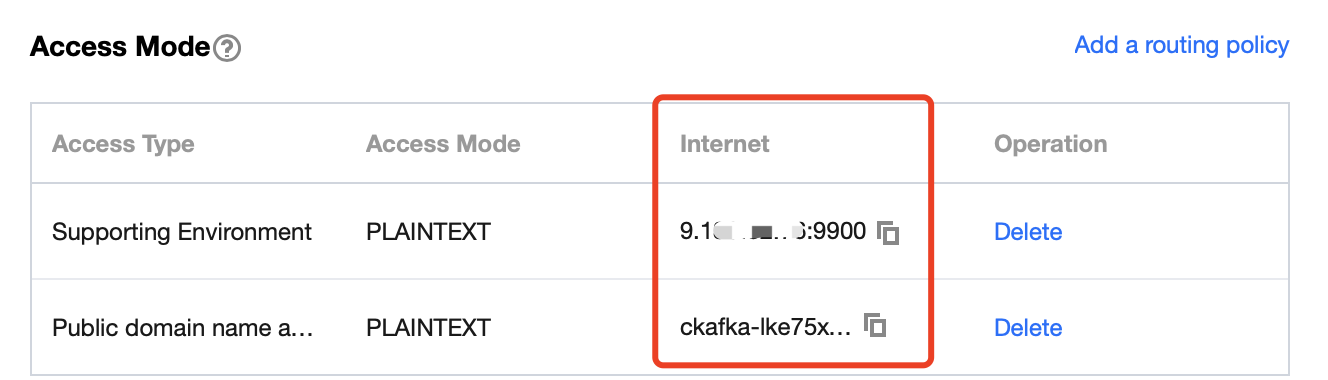
Step 1. Get the CKafka instance access address
1. Log in to the CKafka console.
2. Select Instance List on the left sidebar and click the ID of the target instance to enter its basic information page.
3. On the instance's basic information page, get the instance access address in the Access Mode module.
Step 2. Create a topic
1. On the instance's basic information page, select the Topic Management tab at the top.
2. On the topic management page, click Create to create a topic named
logstash_test.
Step 3. Connect to CKafka
Note:
You can click the following tabs to view the detailed directions for using CKafka as
inputs or outputs.1. Run
bin/logstash-plugin list to check whether logstash-input-kafka is included in the supported plugins.
2. Write the configuration file
input.conf in the .bin/ directory.In the following example, Kafka is used as the data source, and the standard output is taken as the data destination.
input {kafka {bootstrap_servers => "xx.xx.xx.xx:xxxx" // CKafka instance access addressgroup_id => "logstash_group" // CKafka group IDtopics => ["logstash_test"] // CKafka topic nameconsumer_threads => 3 // Number of consumer threads, which is generally the same as the number of CKafka partitionsauto_offset_reset => "earliest"}}output {stdout{codec=>rubydebug}}
3. Run the following command to start Logstash and consume messages.
./logstash -f input.conf
The returned result is as follows:
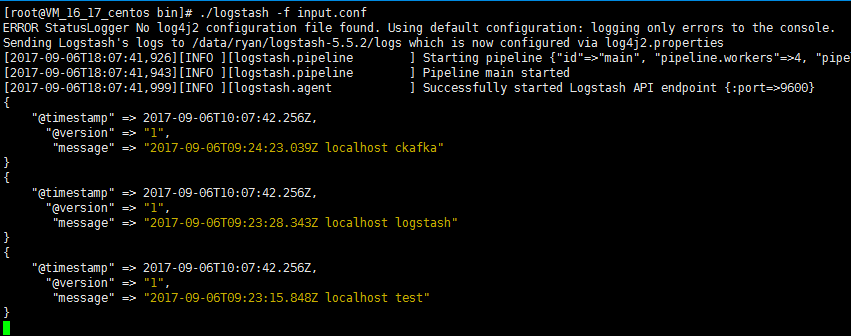
You can see that the data in the topic above has been consumed now.
1. Run
bin/logstash-plugin list to check whether logstash-output-kafka is included in the supported plugins.
2. Write the configuration file
output.conf in the .bin/ directory.In the following example, the standard input is taken as the data source, and Kafka is used as the data destination.
input {stdin{}}output {kafka {bootstrap_servers => "xx.xx.xx.xx:xxxx"topic_id => "logstash_test"}}
3. Run the following command to start Logstash and send messages to the created topic:
./logstash -f output.conf
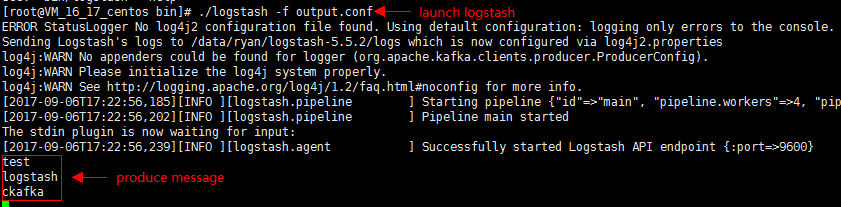
4. Start the CKafka consumer and verify the production data from the previous step.


 예
예
 아니오
아니오
문제 해결에 도움이 되었나요?