- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
温馨提示
若您的 Dynamic Scheduler 之前使用 TPS 作为数据源并没有调整,调度器将失效。若您需要使用 TMP 作为数据源,由于 TMP 新增了对接口的鉴权能力,您需要 升级 调度器才能关联 TMP 实例。
若您的 Dynamic Scheduler 使用的是自建 Prometheus 服务,TPS 下线对您的组件没有影响,但需要自行保证自建 Prometheus 的稳定性和可靠性。
简介
组件介绍
Dynamic Scheduler 是容器服务 TKE 基于 Kubernetes 原生 Kube-scheduler Extender 机制实现的动态调度器插件,可基于 Node 真实负载进行预选和优选。在 TKE 集群中安装该插件后,该插件将与 Kube-scheduler 协同生效,有效避免原生调度器基于 request 和 limit 调度机制带来的节点负载不均问题。
该组件依赖 Prometheus 监控组件以及相关规则配置,可参见本文 依赖部署 进行操作,避免遇到插件无法正常工作的情况。
部署在集群内的 Kubernetes 对象
Kubernetes 对象名称 | 类型 | 请求资源 | 所属 Namespace |
node-annotator | Deployment | 每个实例 CPU:100m,Memory:100Mi ,共1个实例 | kube-system |
dynamic-scheduler | Deployment | 每个实例 CPU:400m,Memory:200Mi,共3个实例 | kube-system |
dynamic-scheduler | Service | - | kube-system |
node-annotator | ClusterRole | - | kube-system |
node-annotator | ClusterRoleBinding | - | kube-system |
node-annotator | ServiceAccount | - | kube-system |
dynamic-scheduler-policy | ConfigMap | - | kube-system |
restart-kube-scheduler | ConfigMap | - | kube-system |
probe-prometheus | ConfigMap | - | kube-system |
应用场景
集群负载不均
Kubernetes 原生调度器大部分基于 Pod Request 资源进行调度,并不具备根据 Node 当前和过去一段时间的真实负载情况进行相关调度的决策,因此可能会导致如下问题:
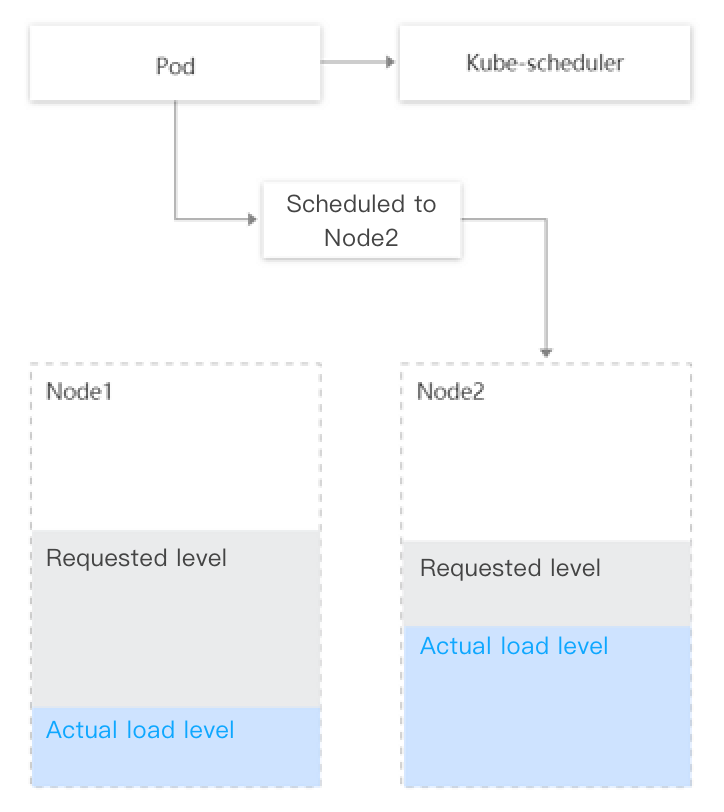
集群内部分节点的剩余可调度资源较多(根据节点上运行的 Pod 的 request 和 limit 计算出的值)但真实负载却比较高,而另外节点的剩余可调度资源比较少但真实负载却比较低,此时 Kube-scheduler 会优先将 Pod 调度到剩余资源比较多的节点上(根据 LeastRequestedPriority 策略)。
如下图所示,Kube-Scheduler 会将 Pod 调度到 Node2 上,但明显调度到 Node1(真实负载水位更低)是更优的选择。
防止调度热点
为防止低负载的节点被持续调度 Pod,Dynamic Scheduler 支持设置防调度热点策略(统计节点过去几分钟调度 Pod 的数量,并相应减小节点在优选阶段的评分)。
当前采取策略如下:
如果节点在过去1分钟调度了超过2个 Pod,则优选评分减去1分。
如果节点在过去5分钟调度了超过5个 Pod,则优选评分减去1分。
风险控制
该组件已对接 TKE 的监控告警体系。
推荐您为集群开启事件持久化,以便更好的监控组件异常以及故障定位。
该组件卸载后,只会删除动态调度器有关调度逻辑,不会对原生 Kube-Scheduler 的调度功能有任何影响。
限制条件
TKE 版本建议 ≥ v1.10.x
如果需要升级 Kubernetes master 版本:
对于托管集群无需再次设置本插件。
对于独立集群,master 版本升级会重置 master 上所有组件的配置,从而影响到 Dynamic Scheduler 插件作为 Scheduler Extender 的配置,因此 Dynamic Scheduler 插件需要卸载后再重新安装。
组件原理
动态调度器基于 scheduler extender 扩展机制,从 Prometheus 监控数据中获取节点负载数据,开发基于节点实际负载的调度策略,在调度预选和优选阶段进行干预,优先将 Pod 调度到低负载节点上。该组件由 node-annotator 和 Dynamic-scheduler 构成。
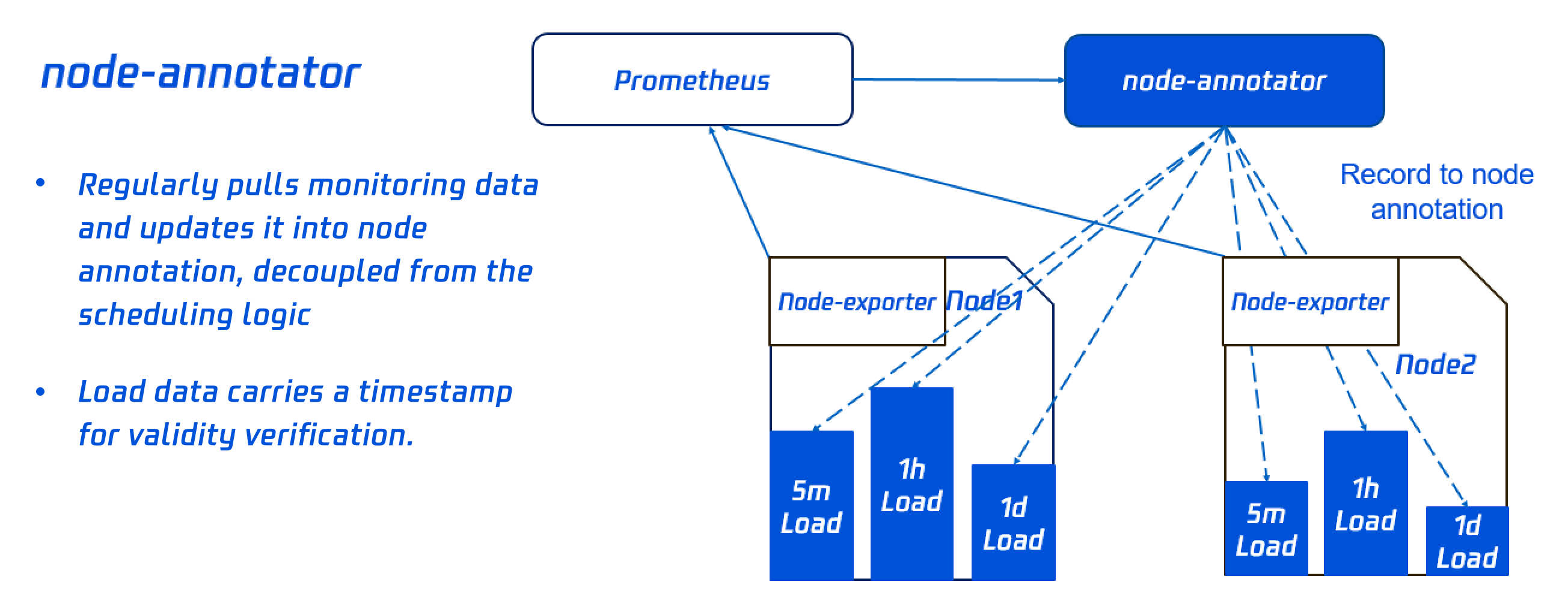
node-annotator
node-annotator 组件负责定期从监控中拉取节点负载 metric,同步到节点的 annotation。如下图所示:
注意:
组件删除后,node-annotator 生成的 annotation 并不会被自动清除。您可根据需要手动清除。
Dynamic-scheduler
Dynamic-scheduler 是一个 scheduler-extender,根据 node annotation 负载数据,在节点预选和优选中进行过滤和评分计算。
预选策略
为了避免 Pod 调度到高负载的 Node 上,需要先通过预选过滤部分高负载的 Node(其中过滤策略和比例可以动态配置,具体请参见本文 组件参数说明)。
如下图所示,Node2 过去5分钟的负载,Node3 过去1小时的负载均超过对应的域值,因此不会参与接下来的优选阶段。

优选策略
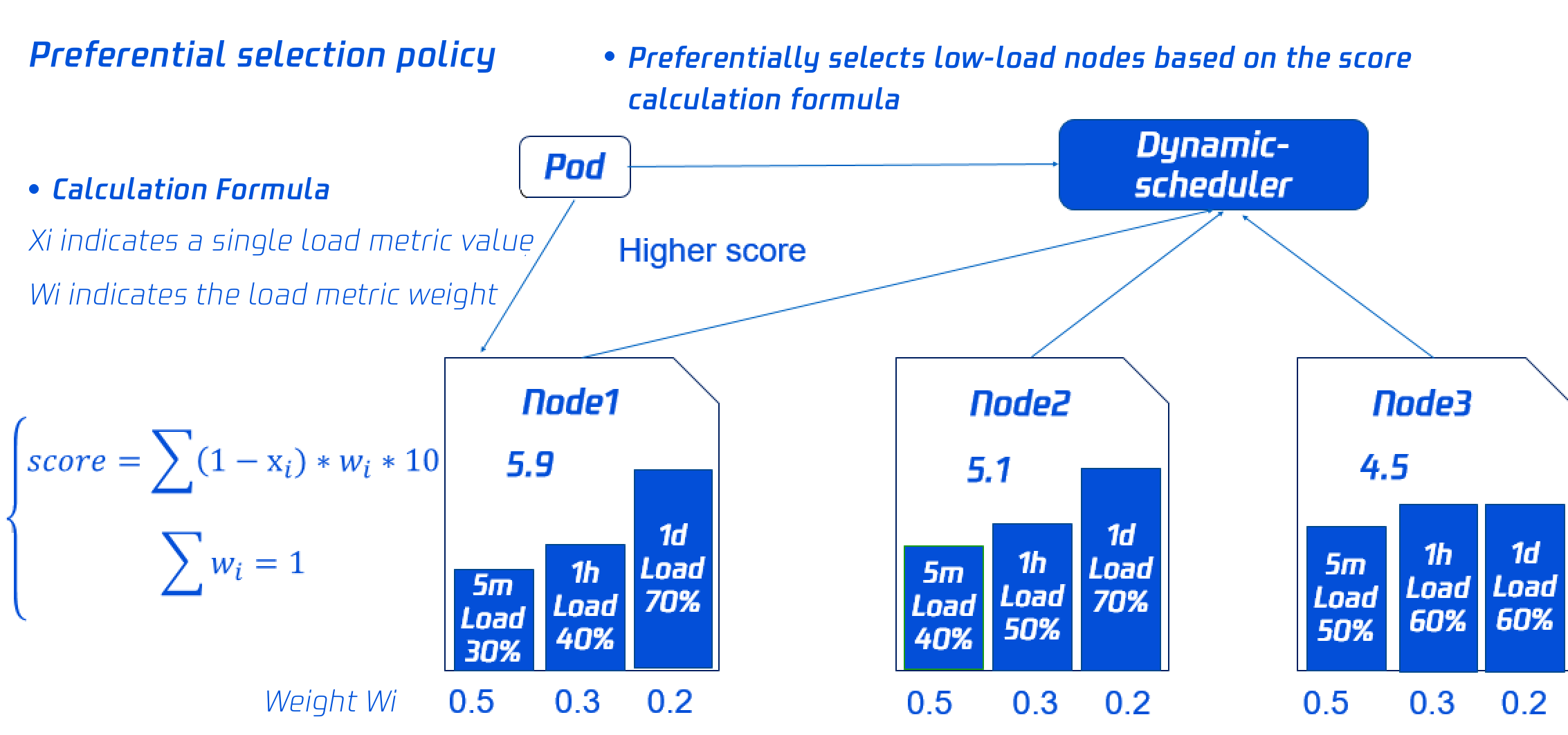
同时为了使集群各节点的负载尽量均衡,Dynamic-scheduler 会根据 Node 负载数据进行打分,负载越低打分越高。
如下图所示,Node1 的打分最高将会被优先调度(其中打分策略和权重可以动态配置,具体请参见本文 组件参数说明)。
组件参数说明
Prometheus 数据查询地址
如果使用自建 Prometheus,直接填入数据查询 URL(HTTP/HTTPS)即可。
如果使用托管 Prometheus,选择托管实例 ID 即可,系统会自动解析实例对应的数据查询 URL。
预选参数
预选参数默认值 | 说明 |
5分钟平均 CPU 利用率阈值 | 节点过去5分钟平均 CPU 利用率超过设定阈值,不会调度 Pod 到该节点上。 |
1小时最大 CPU 利用率阈值 | 节点过去1小时最大 CPU 利用率超过设定阈值,不会调度 Pod 到该节点上。 |
5分钟平均内存利用率阈值 | 节点过去5分钟平均内存利用率超过设定阈值,不会调度 Pod 到该节点上。 |
1小时最大内存利用率阈值 | 节点过去1小时最大内存利用率超过设定阈值,不会调度 Pod 到该节点上。 |
优选参数
优选参数默认值 | 说明 |
5分钟平均 CPU 利用率权重 | 该权重越大,过去5分钟节点平均 CPU 利用率对节点的评分影响越大。 |
1小时最大 CPU 利用率权重 | 该权重越大,过去1小时节点最大 CPU 利用率对节点的评分影响越大。 |
1天最大 CPU 利用率权重 | 该权重越大,过去1天内节点最大 CPU 利用率对节点的评分影响越大。 |
5分钟平均内存利用率权重 | 该权重越大,过去5分钟节点平均内存利用率对节点的评分影响越大。 |
1小时最大内存利用率权重 | 该权重越大,过去1小时节点最大内存利用率对节点的评分影响越大。 |
1天最大内存利用率权重 | 该权重越大,过去1天内节点最大内存利用率对节点的评分影响越大。 |
操作步骤
依赖部署
Dynamic Scheduler 动态调度器依赖于 Node 当前和过去一段时间的真实负载情况来进行调度决策,需通过 Prometheus 等监控组件获取系统 Node 真实负载信息。在使用动态调度器之前,需要部署 Prometheus 等监控组件。在容器服务 TKE 中,您可按需选择采用自建的 Prometheus 监控服务或采用 TKE 推出的云原生监控。
部署 node-exporter 和 prometheus
通过 node-exporter 实现对 Node 指标的监控,用户可以根据业务需求部署 node-exporter 和 prometheus。
聚合规则配置
在 node-exporter 获取节点监控数据后,需要通过 Prometheus 对原始的 node-exporter 采集数据进行聚合计算。为了获取动态调度器中需要的
cpu_usage_avg_5m、cpu_usage_max_avg_1h、cpu_usage_max_avg_1d、mem_usage_avg_5m、mem_usage_max _avg_1h、mem_usage_max_avg_1d 等指标,需要在 Prometheus 的 rules 规则进行如下配置:apiVersion: monitoring.coreos.com/v1kind: PrometheusRulemetadata:name: example-recordspec:groups:- name: cpu_mem_usage_activeinterval: 30srules:- record: cpu_usage_activeexpr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[30s])) * 100)- record: mem_usage_activeexpr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)- name: cpu-usage-5minterval: 5mrules:- record: cpu_usage_max_avg_1hexpr: max_over_time(cpu_usage_avg_5m[1h])- record: cpu_usage_max_avg_1dexpr: max_over_time(cpu_usage_avg_5m[1d])- name: cpu-usage-1minterval: 1mrules:- record: cpu_usage_avg_5mexpr: avg_over_time(cpu_usage_active[5m])- name: mem-usage-5minterval: 5mrules:- record: mem_usage_max_avg_1hexpr: max_over_time(mem_usage_avg_5m[1h])- record: mem_usage_max_avg_1dexpr: max_over_time(mem_usage_avg_5m[1d])- name: mem-usage-1minterval: 1mrules:- record: mem_usage_avg_5mexpr: avg_over_time(mem_usage_active[5m])
Prometheus 文件配置
1. 上述定义了动态调度器所需要的指标计算的 rules,需要将 rules 配置到 Prometheus 中,参考一般的 Prometheus 配置文件。示例如下:
global:evaluation_interval: 30sscrape_interval: 30sexternal_labels:rule_files:- /etc/prometheus/rules/*.yml # /etc/prometheus/rules/*.yml就是定义的rules文件
2. 将 rules 配置复制到一个文件(例如 dynamic-scheduler.yaml),文件放到上述 prometheus 容器的
/etc/prometheus/rules/ 目录下。3. 加载 Prometheus server,即可从 Prometheus 获取到动态调度器需要的指标。
说明:
通常情况下,上述 Prometheus 配置文件和 rules 配置文件都是通过 configmap 存储,再挂载到 Prometheus server 容器,因此修改相应的 configmap 即可。
1. 登录容器服务控制台,在左侧菜单栏中选择 Prometheus 监控,进入 Prometheus 监控页面。
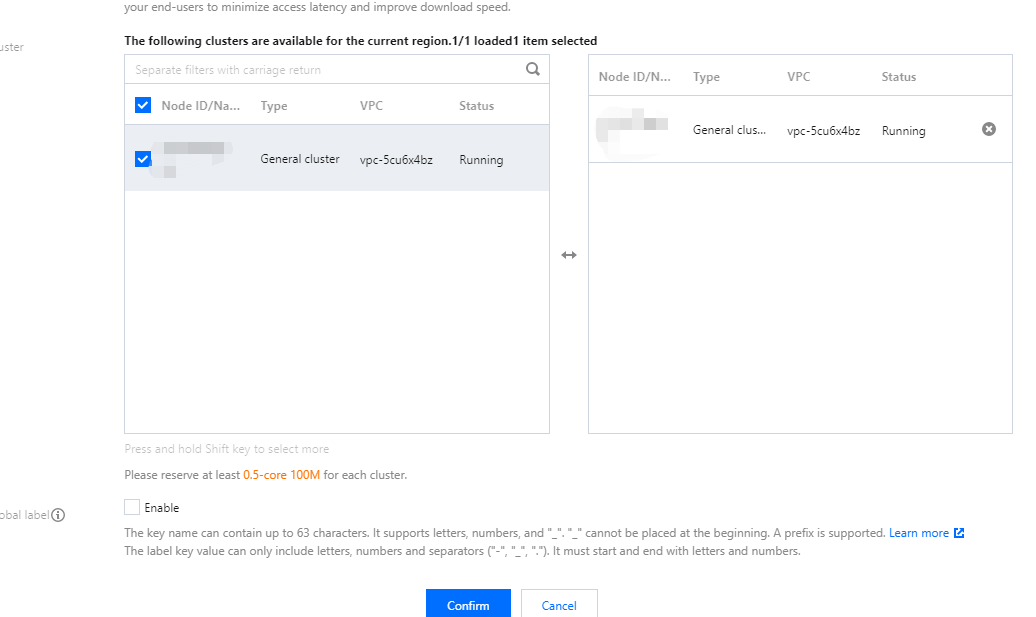
2. 创建与 Cluster 处于同一 VPC 下的 Prometheus 实例,并 关联集群。如下图所示:
3. 与原生托管集群关联后,可以在用户集群查看到每个节点都已安装 node-exporter。如下图所示:
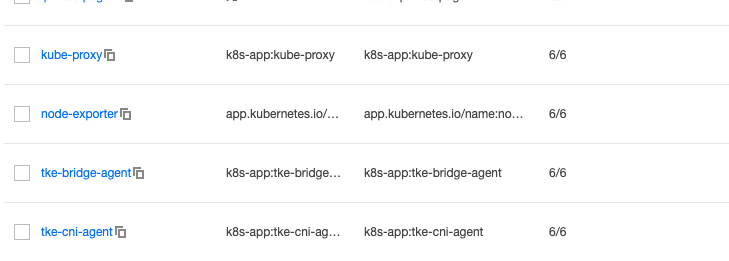
4. 设置 Prometheus 聚合规则,具体规则内容与上述 自建Prometheus监控服务 中的“聚合规则配置”相同。如下所示:
apiVersion: monitoring.coreos.com/v1kind: PrometheusRulemetadata:name: example-recordspec:groups:- name: cpu_mem_usage_activeinterval: 30srules:- record: cpu_usage_activeexpr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[30s])) * 100)- record: mem_usage_activeexpr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)- name: cpu-usage-5minterval: 5mrules:- record: cpu_usage_max_avg_1hexpr: max_over_time(cpu_usage_avg_5m[1h])- record: cpu_usage_max_avg_1dexpr: max_over_time(cpu_usage_avg_5m[1d])- name: cpu-usage-1minterval: 1mrules:- record: cpu_usage_avg_5mexpr: avg_over_time(cpu_usage_active[5m])- name: mem-usage-5minterval: 5mrules:- record: mem_usage_max_avg_1hexpr: max_over_time(mem_usage_avg_5m[1h])- record: mem_usage_max_avg_1dexpr: max_over_time(mem_usage_avg_5m[1d])- name: mem-usage-1minterval: 1mrules:- record: mem_usage_avg_5mexpr: avg_over_time(mem_usage_active[5m])
安装组件
1. 登录 容器服务控制台 ,选择左侧导航栏中的集群。
2. 在集群管理页面单击目标集群 ID,进入集群详情页。
3. 选择左侧菜单栏中的组件管理,进入组件列表页面。
4. 在组件列表页面中选择新建,并在新建组件页面中勾选 DynamicScheduler(动态调度器插件)。
5. 单击参数配置,按照 参数说明 填写组件所需参数。
6. 单击完成即可创建组件。安装成功后,Dynamic Scheduler 即可正常运行,无需进行额外配置。

 是
是
 否
否
本页内容是否解决了您的问题?