- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 集群
- 集群迁移
- Serverless 集群
- 调度
- 安全
- 服务部署
- 网络
- 发布
- 日志
- 监控
- 运维
- Terraform
- DevOps
- 弹性伸缩
- 容器化
- 微服务
- 成本管理
- 混合云
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 集群
- 集群迁移
- Serverless 集群
- 调度
- 安全
- 服务部署
- 网络
- 发布
- 日志
- 监控
- 运维
- Terraform
- DevOps
- 弹性伸缩
- 容器化
- 微服务
- 成本管理
- 混合云
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
简介
组件介绍
GPU Manager 提供一个 All-in-One 的 GPU 管理器,基于 Kubernetes DevicePlugin 插件系统实现,该管理器提供了分配并共享 GPU、GPU 指标查询、容器运行前的 GPU 相关设备准备等功能,支持用户在 Kubernetes 集群中使用 GPU 设备。
组件功能
拓扑分配:提供基于 GPU 拓扑分配功能,当用户分配超过1张 GPU 卡的应用,可以选择拓扑连接最快的方式分配 GPU 设备。
GPU 共享:允许用户提交小于1张卡资源的任务,并提供 QoS 保证。
应用 GPU 指标的查询:用户可以访问主机端口(默认为 5678)的
/metric 路径,可以为 Prometheus 提供 GPU 指标的收集功能,访问 /usage 路径可以进行可读性的容器状况查询。部署在集群内的 Kubernetes 对象
Kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
gpu-manager-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
gpu-quota-admission | Deployment | 每节点1核 CPU, 1Gi内存 | kube-system |
使用场景
在 Kubernetes 集群中运行 GPU 应用时,可以解决 AI 训练等场景中申请独立卡造成资源浪费的情况,让计算资源得到充分利用。
限制条件
该组件基于 Kubernetes DevicePlugin 实现,可直接在 Kubernetes 1.10 以上版本的集群使用。
每张 GPU 卡一共有100个单位的资源,仅支持0 - 1的小数卡,以及1的倍数的整数卡设置。显存资源是以256MiB为最小的一个单位的分配显存。
使用 GPU-Manager 要求集群内包含 GPU 机型节点。
使用方法
组件安装
1. 登录 容器服务控制台,在左侧导航栏中选择集群。
2. 在集群管理页面单击目标集群 ID,进入集群详情页。
3. 选择左侧菜单栏中的组件管理,进入组件列表页面。
4. 在组件列表页面中选择新建,并在新建组件页面中勾选 GpuManager。
5. 单击完成即可创建组件。
创建细粒度的 GPU 工作负载
当 GpuManager 组件成功安装后,您可通过以下两种方式创建细粒度的 GPU 工作负载。
方式一:通过 TKE 控制台创建
1. 登录容器服务控制台,选择左侧导航栏中的 集群。
2. 选择需要创建 GPU 应用的集群,进入工作负载管理页,并单击新建。
3. 在新建 Workload 页面根据实际需求进行配置,可在 GPU 资源配置细粒度的 GPU 工作负载。如下图所示:
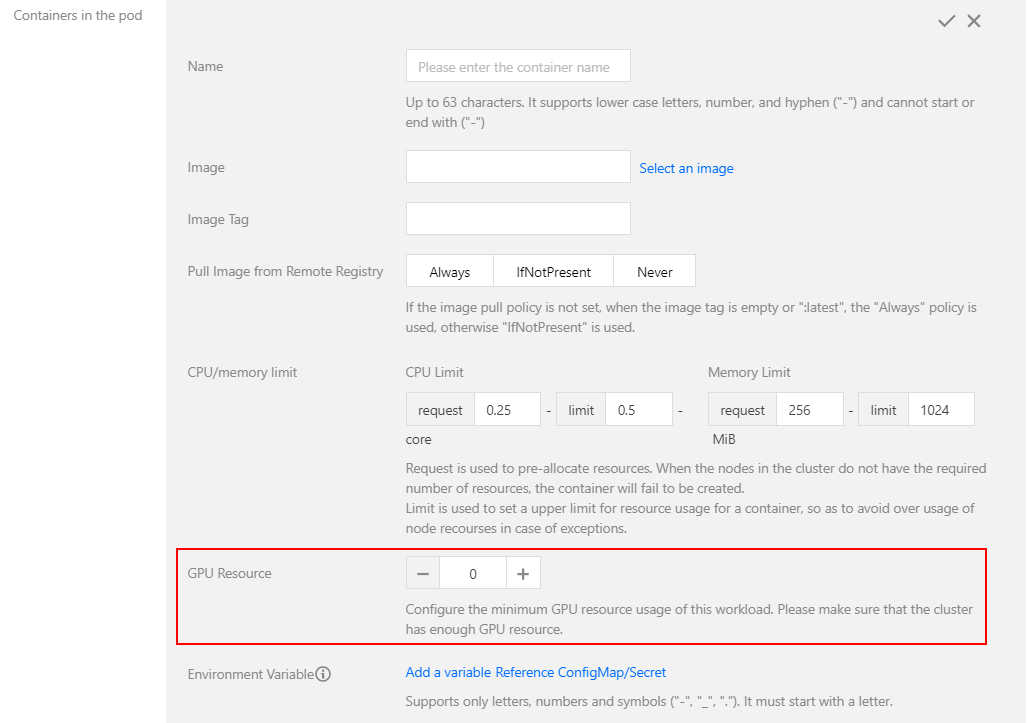
方式二:通过 yaml 创建
说明:
在提交时通过 yaml 为容器设置 GPU 的使用资源,核资源需要在 resource 上填写
tencent.com/vcuda-core,显存资源需要在 resource 上填写 tencent.com/vcuda-memory。下面给出 yaml 示例:
使用1张卡的 P4 设备:
apiVersion: v1kind: Pod...spec:containers:- name: gpuresources:tencent.com/vcuda-core: 100
使用0.3张卡,5GiB 显存的应用:
apiVersion: v1kind: Pod...spec:containers:- name: gpuresources:tencent.com/vcuda-core: 30tencent.com/vcuda-memory: 20

 是
是
 否
否
本页内容是否解决了您的问题?