- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
总述
DNS 作为 Kubernetes 集群中服务访问的第一环节,其稳定性和性能至关重要,如何以更优的方式配置和使用 DNS,涉及到方方面面,本文档将总结这些最佳实践。
选择最佳 CoreDNS 版本
下表列出了随各个版本 TKE 集群默认部署的 CoreDNS 版本:
由于历史原因,可能会有 v1.18 及以上版本的集群仍然部署 v1.6.2 版本的 CoreDNS,如果当前 CoreDNS 版本不满足需求,可以按如下指引手动升级:
配置合适的 CoreDNS 副本数
1. TKE 默认设置 CoreDNS 副本数为2,且配置了
podAntiAffinity 使两副本部署在不同节点。2. 针对节点数大于80的集群,建议安装 NodeLocal DNSCache,详情参见:在 TKE 集群中使用 NodeLocal DNS Cache。
3. 一般根据集群内业务访问 DNS 的 QPS 来确定 CoreDNS 合理的副本数,也可以根据节点数以及总核数来确定,在安装 NodeLocal DNSCache 后,建议 CoreDNS 最大副本数为10,可以按照如下方式配置:
副本数 = min ( max ( ceil (QPS/10000), ceil (集群节点数/8) ), 10 )
示例:
集群节点数为 10,DNS 服务请求 QPS 为 22000,则副本数为 3。
集群节点数为 30,DNS 服务请求 QPS 为 15000,则副本数为 4。
集群节点数为 100,DNS 服务请求 QPS 为 50000,则副本数为 10(已部署 NodeLocal DNSCache)
4. 可以通过在控制台 安装 DNSAutoScaler 组件,来实现自动调整 CoreDNS 副本数(要注意提前配置好平滑升级),组件的默认配置如下:
data:ladder: |-{"coresToReplicas":[[ 1, 1 ],[ 128, 3 ],[ 512,4 ],],"nodesToReplicas":[[ 1, 1 ],[ 2, 2 ]]}
使用 NodeLocal DNSCache
在 TKE 集群中部署 NodeLocal DNSCache 可以提升服务发现的稳定性和性能,其通过在节点上作为 DaemonSet 运行 DNS 缓存代理来提高集群 DNS 性能。
关于更多 NodeLocal DNSCache 的介绍及如何在 TKE 集群中部署 NodeLocal DNSCache 的具体步骤,参见:在 TKE 集群中使用 NodeLocal DNS Cache。
配置 CoreDNS 平滑升级
当重启节点或者升级 CoreDNS 时,可能导致 CoreDNS 部分副本在一段时间不可用,可以通过以下配置,最大程度保证 DNS 服务的可用性,实现平滑升级。
kube-proxy 为 iptables 模式,无需配置
iptables模式下,kube-proxy会在同步iptables规则后及时清理遗留的conntrack表项,不存在会话保持问题,无需配置。
kube-proxy 为 IPVS 模式,配置 IPVS UDP 协议的会话保持超时时间
IPVS 模式下,如果业务自身没有 UDP 服务,可以通过降低 IPVS UDP 协议的会话保持超时时间来尽量减少服务不可用的时间。
1. 集群版本大于等于1.18,kube-proxy 提供参数
--ipvs-udp-timeout,默认为0s,也即使用系统默认值:300s,推荐配置为--ipvs-udp-timeout=10s。按如下方式配置 kube-proxy DaemonSet:spec:containers:- args:- --kubeconfig=/var/lib/kube-proxy/config- --hostname-override=$(NODE_NAME)- --v=2- --proxy-mode=ipvs- --ipvs-scheduler=rr- --nodeport-addresses=$(HOST_IP)/32- --ipvs-udp-timeout=10scommand:- kube-proxyname: kube-proxy
2. 集群版本小于等于1.16,kube-proxy 不支持该参数,可以使用
ipvsadm工具批量在节点侧修改:yum install -y ipvsadmipvsadm --set 900 120 10
3. 配置完成后,可以按如下方式验证:
ipvsadm -L --timeoutTimeout (tcp tcpfin udp): 900 120 10
注意:
配置 CoreDNS 优雅退出
已经收到退出信号的副本,可以通过配置 lameduck 使其能在一段时间内继续提供服务,按如下方式配置 CoreDNS 的 configmap(仅展示 CoreDNS 1.6.2版本的部分配置,其它版本配置参见 手动升级 CoreDNS):
.:53 {health {lameduck 30s}kubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecureupstreamfallthrough in-addr.arpa ip6.arpa}}
配置 CoreDNS 服务就绪确认
新副本启动后,需确认其服务就绪,再加入 DNS 服务的后端列表。
1. 打开 ready 插件,按如下方式配置 CoreDNS 的 configmap(仅展示 CoreDNS 1.6.2版本的部分配置,其它版本配置参见 手动升级 CoreDNS):
.:53 {readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecureupstreamfallthrough in-addr.arpa ip6.arpa}}
2. 为 CoreDNS 增加配置 ReadinessProbe:
readinessProbe:failureThreshold: 5httpGet:path: /readyport: 8181scheme: HTTPinitialDelaySeconds: 30periodSeconds: 10successThreshold: 1timeoutSeconds: 5
配置 CoreDNS 使用 UDP 访问上游 DNS
当 CoreDNS 需要与上游 DNS Server 通信时,它将默认使用客户端请求的协议(UDP 或者 TCP),而 TKE 中 CoreDNS 的上游默认为 VPC 内的 DNS 服务,该服务对 TCP 的支持在性能上比较有限,因此推荐做如下配置,显式指定 UDP(尤其在安装了 NodeLocal DNSCache 时):
.:53 {forward . /etc/resolv.conf {prefer_udp}}
配置 CoreDNS 过滤 HINFO 请求
VPC 内的 DNS 服务不支持 HINFO 类型的 DNS 请求,因此推荐做如下配置,在 CoreDNS 侧过滤此类请求(尤其在安装了 NodeLocal DNSCache 时):
.:53 {template ANY HINFO . {rcode NXDOMAIN}}
配置 CoreDNS 对 IPv6 类型的 AAAA 记录查询返回域名不存在
当业务不需要做 IPv6 的域名解析时,可以通过该配置降低通信成本:
.:53 {template ANY AAAA {rcode NXDOMAIN}}
注意:
IPv4/IPv6 双栈集群不能做此配置。
配置自定义域名解析
详情参见:在 TKE 中实现自定义域名解析
手动升级
升级到1.7.0
1. 编辑 coredns configmap
kubectl edit cm coredns -n kube-system
修改为以下内容:
.:53 {template ANY HINFO . {rcode NXDOMAIN}errorshealth {lameduck 30s}readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}prometheus :9153forward . /etc/resolv.conf {prefer_udp}cache 30reloadloadbalance}
2. 编辑 coredns deployment
kubectl edit deployment coredns -n kube-system
替换镜像为
image: ccr.ccs.tencentyun.com/tkeimages/coredns:1.7.0
升级到1.8.4
1. 编辑 coredns clusterrole
kubectl edit clusterrole system:coredns
修改为以下内容:
rules:- apiGroups:- '*'resources:- endpoints- services- pods- namespacesverbs:- list- watch- apiGroups:- discovery.k8s.ioresources:- endpointslicesverbs:- list- watch
2. 编辑 coredns configmap
kubectl edit cm coredns -n kube-system
修改为以下内容:
.:53 {template ANY HINFO . {rcode NXDOMAIN}errorshealth {lameduck 30s}readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}prometheus :9153forward . /etc/resolv.conf {prefer_udp}cache 30reloadloadbalance}
3. 编辑 coredns deployment
kubectl edit deployment coredns -n kube-system
替换镜像为
image: ccr.ccs.tencentyun.com/tkeimages/coredns:1.8.4
配置业务建议
除了 DNS 服务的最佳实践外,在业务侧,也可以做适当的优化配置,来提升 DNS 的使用体验。
1. 默认情况下,Kubernetes 集群中的域名解析往往需要经过多次请求才能解析到。查看 pod 内 的
/etc/resolv.conf 可以知道 ndots 选项默认为 5。例如,在 debug 命名空间查询 kubernetes.default.svc.cluster.local 这个 service:域名中有 4 个
. ,小于 5,尝试拼接上第一个 search 进行查询,即kubernetes.default.svc.cluster.local.debug.svc.cluster.local ,查不到该域名。继续尝试
kubernetes.default.svc.cluster.local.svc.cluster.local ,查不到该域名。继续尝试
kubernetes.default.svc.cluster.local.cluster.local ,仍然查不到该域名。尝试不加后缀,即
kubernetes.default.svc.cluster.local ,查询成功,返回响应的 ClusterIP。2. 上面一个简单的 service 域名解析需要经过 4 轮解析才能成功,集群中充斥着大量无用的 DNS 请求。因此需要根据业务配置的访问方式来为其设置合理的 ndots 来降低查询次数:
spec:dnsConfig:options:- name: ndotsvalue: "2"containers:- image: nginximagePullPolicy: IfNotPresentname: diagnosis
3. 同时,可以优化业务访问服务的域名配置:
Pod 访问本命名空间的 Service,使用
<service-name> 访问。Pod 访问其它命名空间的 Service,使用
<service-name>.<namespace-name> 访问。Pod 访问外部域名,使用 FQDN 类型域名访问,在域名最后添加
. 以减少无效搜索。相关内容
配置介绍
errors
输出错误信息。
health
上报健康状态,用于配置健康检查,如
livenessProbe,默认监听 8080 端口,路径为 http://localhost:8080/health注意:
如果有多 Server 块,health 只能配置一次,或者配置在不同端口。
com {whoamihealth :8080}net {erratichealth :8081}
lameduck
用于配置优雅退出的时间,实现方式是 hook 在 CoreDNS 收到退出信号时,在其中执行 sleep,以保证时限内可以继续提供服务。
ready
上报插件状态,用于配置服务就绪检查,如
readinessProbe,默认监听 8181 端口,路径为http://localhost:8181/readykubernetes
Kubernetes 插件,支持集群内服务解析。
prometheus
metrics 数据接口,用于获取监控数据,路径为
http://localhost:9153/metricsforward(proxy)
将无法处理的请求转发到上游 DNS 服务器。默认使用宿主机的
/etc/resolv.conf 配置。根据 forward aaa bbb 的配置,内部会维护一个 udns 的列表 [aaa,bbb]
当有请求到来时,根据预设的策略(random|round_robin|sequential,默认 random)在列表 [aaa,bbb] 中找一个 udns 发请求,如果失败,则找出下一个 udns 进行尝试,同时针对失败的 udns 启动周期性的健康监测,直到其变为健康,停止健康监测。
在健康监测的过程中,如果连续几次(默认两次)监测失败,则将该 udns 状态置为 down,后面从列表中选 udns 时将跳过状态为 down 的 udns。
当所有的 udns 都 down 时,随机选一个 udns 做转发。
因此,可以认为 coredns 有在多个 upstream 间智能切换的能力,forward 列表里只要有一个可用的 udns,则请求可以成功。
cache
DNS 缓存。
reload
热加载 Corefile,修改 ConfigMap 后,会在两分钟内加载新配置。
loadbalance
提供基于 DNS 的负载均衡功能,随机响应记录的顺序。
CoreDNS 资源占用
主要取决于集群内 Pod 数和 Service 数。
受打开缓存大小的影响。
受 QPS 的影响。
以下数据来自于 CoreDNS 官方:
MB required (default settings) = (Pods + Services) / 1000 + 54
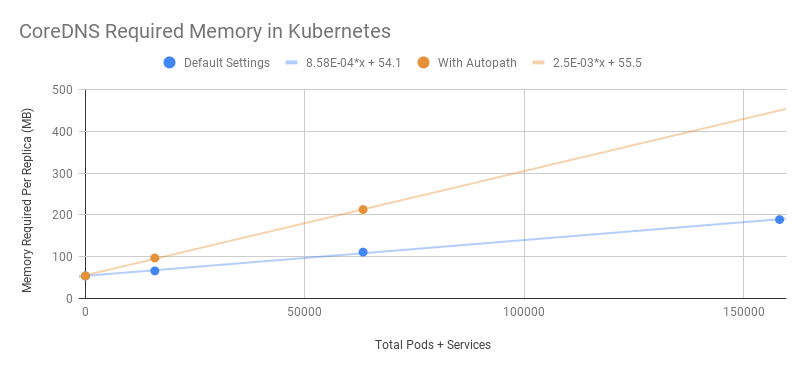
主要受 QPS 的影响。
以下数据来自于 CoreDNS 官方:
单副本 CoreDNS,运行节点规格:2 vCPUs, 7.5 GB memory。
Query Type | QPS | Avg Latency (ms) | Memory Delta (MB) |
external | 6733 | 12.02 | +5 |
internal | 33669 | 2.608 | +5 |

 是
是
 否
否
本页内容是否解决了您的问题?