- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
概述
Kubernetes Pod 垂直自动扩缩(Vertical Pod Autoscaler,以下简称 VPA)可以自动调整 Pod 的 CPU 和内存预留,帮助提高集群资源利用率并释放 CPU 和内存供其它 Pod 使用。本文介绍如何在腾讯云容器服务 TKE 上使用社区版 VPA 功能实现 Pod 垂直扩缩容。
使用场景
VPA 自动伸缩特性使容器服务具有非常灵活的自适应能力。应对业务负载急剧飙升的情况,VPA 能够在用户设定范围内快速扩大容器的 Request。在业务负载变小的情况下,VPA 可根据实际情况适当缩小 Request 节省计算资源。整个过程自动化无须人为干预,适用于需要快速扩容、有状态应用扩容等场景。此外,VPA 可用于向用户推荐更合理的 Request,在保证容器有足够使用的资源的情况下,提升容器的资源利用率。
VPA 优势
VPA 扩容不需要调整 Pod 副本数量,扩容速度更快。
VPA 可为有状态应用实现扩容,HPA 则不适合有状态应用的水平扩容。
Request 设置过大,使用 HPA 水平缩容至一个 Pod 时集群资源利用率仍然很低,此时可以通过 VPA 进行垂直缩容提高集群资源利用率。
VPA 限制
注意:
社区版 VPA 功能当前处于试验阶段,请谨慎使用。推荐您将 “updateMode” 设置为 “Off”,以确保 VPA 不会自动为您更换 Request 数值。您仍然可以在 VPA 对象中查看已绑定负载的 Request 推荐值。
自动更新正在运行的 Pod 资源是 VPA 的一项实验功能。当 VPA 更新 Pod 资源时,会导致 Pod 的重建和重启,并且有可能被调度到其他节点上。
VPA 不会驱逐不在控制器下运行的 Pod。对于此类 Pod,
Auto 模式等效于 Initial。VPA 与 HPA 不可同时在 CPU 和内存预留上运行。如需同时运行 VPA 与 HPA,则 HPA 需使用除 CPU 和内存以外的指标,详情可参见 在 TKE 上使用自定义指标进行弹性伸缩。
VPA 使用 Admission Webhook 作为其准入控制器。如果集群中存在其他的 Admission Webhook,需要确保它们不会与 VPA 的 Admission Webhook 发生冲突。准入控制器的执行顺序定义在 API Server 的配置参数中。
VPA 会处理大多数 OOM(Out Of Memory)事件。
VPA 性能尚未在大型群集中进行测试。
VPA 对 Pod 资源 Request 的建议值可能会超出可用资源(例如节点资源上限、空闲资源或资源配额),并导致 Pod 处于 Pending 状态无法被调度。同时使用 VPA 与 Cluster Autoscaler 可以部分解决此问题。
与同一个 Pod 匹配的多个 VPA 资源具有未定义的行为。
前提条件
已创建容器服务 TKE 集群。
已使用命令行工具 Kubectl 连接集群。如果您还未连接集群,请参考 连接集群。
操作步骤
部署 VPA
1. 登录集群中的云服务器。
2. 通过命令行工具 Kubectl 从本地客户端机器连接到 TKE 集群。
3. 执行以下命令,克隆 kubernetes/autoscaler GitHub Repository。
git clone https://github.com/kubernetes/autoscaler.git
4. 执行以下命令,切换至
vertical-pod-autoscaler 目录。cd autoscaler/vertical-pod-autoscaler/
5. (可选)如果您已经部署其他版本的 VPA,执行以下命令将其删除。否则将会产生异常影响。
./hack/vpa-down.sh
6. 执行以下命令,将 VPA 相关组件部署到您的集群。
./hack/vpa-up.sh
7. 执行以下命令,验证是否成功创建 VPA 组件。
kubectl get deploy -n kube-system | grep vpa
成功创建 VPA 组件后,您可在 kube-system 命名空间中查阅三个 Deployment,分别为 vpa-admission-controller、vpa-recommender、vpa-updater。如下图所示:

示例1:使用 VPA 获取 Request 推荐值
说明:
不建议在生产环境中使用 VPA 自动更新 Request。
您可以利用 VPA 查看 Request 推荐值,在合适条件下手动触发更新。
在本示例中,您将创建
updateMode 为 Off 的 VPA 对象,并创建具有两个 Pod 的 Deployment,每个 Pod 各有一个容器。在创建 Pod 后,VPA 会分析容器的 CPU 和内存需求,并在 status 字段中记录 Request 推荐值。VPA 不会自动更新正在运行的容器的资源请求。在终端中执行以下命令,生成一个名为
tke-vpa 的 VPA 对象,指向一个名为 tke-deployment 的 Deployment:cat <<EOF | kubectl apply -f -apiVersion: autoscaling.k8s.io/v1kind: VerticalPodAutoscalermetadata:name: tke-vpaspec:targetRef:apiVersion: "apps/v1"kind: Deploymentname: tke-deploymentupdatePolicy:updateMode: "Off"EOF
执行以下命令,生成一个名为
tke-deployment 的 Deployment 对象:cat <<EOF | kubectl apply -f -apiVersion: apps/v1kind: Deploymentmetadata:name: tke-deploymentspec:replicas: 2selector:matchLabels:app: tke-deploymenttemplate:metadata:labels:app: tke-deploymentspec:containers:- name: tke-containerimage: nginxEOF
生成的 Deployment 对象如下图所示:

注意:
上述操作创建 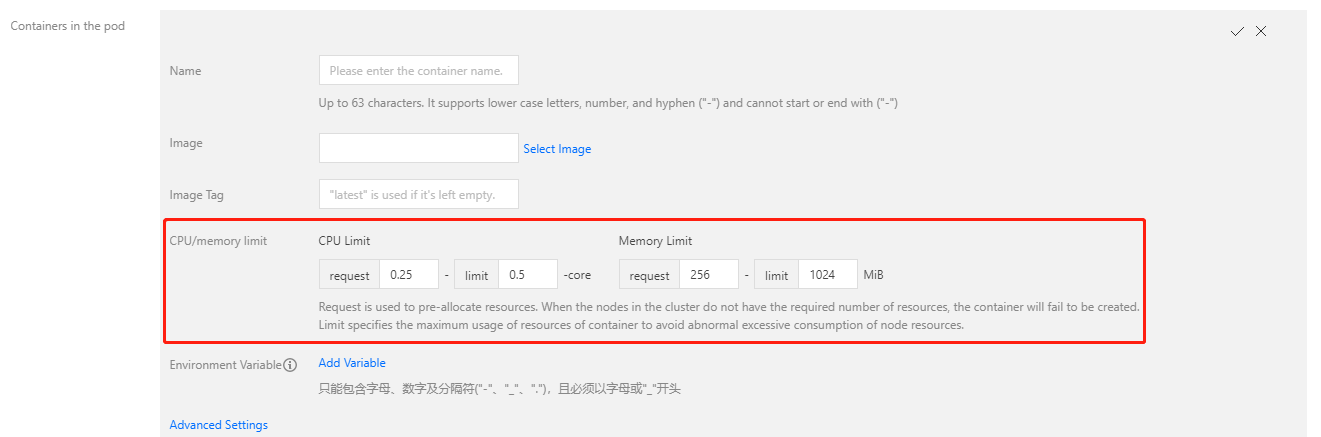
tke-deployment 时并没有设置 CPU 或内存的 Request,Pod 中的 Qos 为 BestEffort,此时 Pod 容易被驱逐。建议您在创建业务的 Deployment 时设置 Request 及 Limit。如果您通过容器服务控制台创建工作负载,控制台将自动为每个容器的 Request 和 Limits 设置默认值。
执行以下命令,您可以查看 VPA 推荐的 CPU 和内存 Request:
kubectl get vpa tke-vpa -o yaml
执行结果如下所示:
...recommendation:containerRecommendations:- containerName: tke-containerlowerBound:cpu: 25mmemory: 262144ktarget: # 推荐值cpu: 25mmemory: 262144kuncappedTarget:cpu: 25mmemory: 262144kupperBound:cpu: 1771mmemory: 1851500k
其中
target 对应的 CPU 和内存为推荐 Request。您可以选择删除之前的 Deployment,并使用推荐的 Request 值创建新的 Deployment。字段 | 释义 |
lowerBound | 推荐的最小值。使用小于该值的 Request 可能会对性能或可用性产生重大影响。 |
target | 推荐值。由 VPA 计算出最合适的 Request。 |
uncappedTarget | 最新建议值。仅基于实际资源使用情况,不考虑 .spec.resourcePolicy.containerPolicies 中设置的容器可以被推荐的数值范围。uncappedTarget 可能与推荐上下界限不同。该字段仅用作状态指示,不会影响实际的资源分配。 |
upperBound | 推荐的最大值。使用高于该值的 Request 可能造成浪费。 |
示例2:停用特定容器
如果您的 Pod 中有多个容器,例如一个是真正的业务容器,另一个是辅助容器。为了节省集群资源,您可以选择停止为辅助容器推荐 Request。
在示例中,您将创建一个停用了特定容器的 VPA,并创建一个 Deployment。Deployment 中包含一个 Pod,该 Pod 内包含两个容器。在创建 Pod 后,VPA 仅为一个容器创建并计算推荐值,另外一个容器被停用 VPA 的推荐能力。
在终端中执行以下命令,生成一个名为
tke-opt-vpa 的 VPA 对象,指向一个名为 tke-opt-deployment 的 Deployment:cat <<EOF | kubectl apply -f -apiVersion: autoscaling.k8s.io/v1kind: VerticalPodAutoscalermetadata:name: tke-opt-vpaspec:targetRef:apiVersion: "apps/v1"kind: Deploymentname: tke-opt-deploymentupdatePolicy:updateMode: "Off"resourcePolicy:containerPolicies:- containerName: tke-opt-sidecarmode: "Off"EOF
注意:
该 VPA 的
.spec.resourcePolicy.containerPolicies 中,指定了 tke-opt-sidecar 的 mode 为 “Off”,VPA 将不会为 tke-opt-sidecar 计算和推荐新的 Request。执行以下命令,生成一个名为
tke-deployment 的 Deployment 对象:cat <<EOF | kubectl apply -f -apiVersion: apps/v1kind: Deploymentmetadata:name: tke-opt-deploymentspec:replicas: 1selector:matchLabels:app: tke-opt-deploymenttemplate:metadata:labels:app: tke-opt-deploymentspec:containers:- name: tke-opt-containerimage: nginx- name: tke-opt-sidecarimage: busyboxcommand: ["sh","-c","while true; do echo TKE VPA; sleep 60; done"]EOF
生成的 Deployment 对象如下图所示:

执行以下命令,您可以查看 VPA 推荐的 CPU 和内存 Request:
kubectl get vpa tke-opt-vpa -o yaml
执行结果如下所示:
...recommendation:containerRecommendations:- containerName: tke-opt-containerlowerBound:cpu: 25mmemory: 262144ktarget:cpu: 25mmemory: 262144kuncappedTarget:cpu: 25mmemory: 262144kupperBound:cpu: 1595mmemory: 1667500k
在执行结果中,仅有
tke-opt-container 的推荐值,没有 tke-opt-sidecar 的推荐值。示例3:自动更新 Request
注意:
自动更新正在运行的 Pod 资源是 VPA 的一项实验功能,建议不要在生产环境中使用该功能。
在本示例中,您将创建一个自动调整 CPU 和内存请求的 VPA,并创建具有两个 Pod 的 Deployment。每个 Pod 都会设置资源的 Request 和 Limits。
在终端中执行以下命令,生成一个名为
tke-auto-vpa 的 VPA 对象,指向一个名为 tke-auto-deployment 的 Deployment:cat <<EOF | kubectl apply -f -apiVersion: autoscaling.k8s.io/v1kind: VerticalPodAutoscalermetadata:name: tke-auto-vpaspec:targetRef:apiVersion: "apps/v1"kind: Deploymentname: tke-auto-deploymentupdatePolicy:updateMode: "Auto"EOF
注意:
该 VPA 的
updateMode 字段的值为 Auto,表示 VPA 可以在 Pod 的生命周期内更新 CPU 和内存请求。VPA 可以删除 Pod,调整 CPU 和内存请求,然后启动一个新 Pod。执行以下命令,生成一个名为
tke-auto-deployment 的 Deployment 对象:cat <<EOF | kubectl apply -f -apiVersion: apps/v1kind: Deploymentmetadata:name: tke-auto-deploymentspec:replicas: 2selector:matchLabels:app: tke-auto-deploymenttemplate:metadata:labels:app: tke-auto-deploymentspec:containers:- name: tke-containerimage: nginxresources:requests:cpu: 100mmemory: 100Milimits:cpu: 200mmemory: 200MiEOF
注意:
上述操作创建 Deployment 时设置了资源的 Request 和 Limits,VPA 此时不仅会推荐 Request 值,还会按照 Request 和 Limits 的初始比例自动推荐 Limits 值。例如,YAML 中 CPU 的 Request 和 Limits 的初始比例为 100m:200m = 1:2,那么 VPA 推荐的 Limits 数值则是 VPA 对象中推荐的 Request 数值的两倍。
生成的 Deployment 对象如下图所示:

执行以下命令,获取正在运行中的 Pod 的详细信息:
kubectl get pod pod-name -o yaml
执行结果如下所示。VPA 修改了原来设置的 Request 和 Limits,更新为 VPA 的推荐值,并维持了初始的 Request 和 Limits 比例。同时生成一个记录更新的 Annotation:
apiVersion: v1kind: Podmetadata:annotations:...vpaObservedContainers: tke-containervpaUpdates: Pod resources updated by tke-auto-vpa: container 0: memory request, cpu request...spec:containers:...resources:limits: # 新的 Request 和 Limits 会维持初始设置的比例cpu: 50mmemory: 500Mirequests:cpu: 25mmemory: 262144k...
执行以下命令,获取相关 VPA 的详细信息:
kubectl get vpa tke-auto-vpa -o yaml
执行结果如下所示:
...recommendation:containerRecommendations:- containerName: tke-containerLower Bound:Cpu: 25mMemory: 262144kTarget:Cpu: 25mMemory: 262144kUncapped Target:Cpu: 25mMemory: 262144kUpper Bound:Cpu: 101mMemory: 262144k
其中
target 表示容器请求 25m CPU 和 262144k 的内存时将以最佳状态运行。VPA 使用
lowerBound 和 upperBound 推荐值来决定是否驱逐 Pod 并将其替换为新 Pod。如果 Pod 的请求小于下限或大于上限,则 VPA 将删除 Pod 并将其替换为具有目标推荐值的 Pod。故障处理
1. 执行 vpa-up.sh 脚本时报错
报错信息
ERROR: Failed to create CA certificate for self-signing. If the error is "unknown option -addext", update your openssl version or deploy VPA from the vpa-release-0.8 branch.
解决方案
2. 如出现继续报错的情况,请检查是否存在以下问题:
检查集群 CVM 的
openssl 版本是否大于 1.1.1。是否使用 Autoscaler 项目的
vpa-release-0.8 分支。2. VPA 相关负载无法启动
报错信息
如果您的 VPA 相关负载无法启动,并产生如下图所示信息:

解决方案
VPA 相关负载无法启动的原因是位于 GCR 的镜像无法被下载,为解决问题您可尝试以下步骤:
1. 下载镜像。
访问 “k8s.gcr.io/” 镜像仓库,下载 vpa-admission-controller、vpa-recommender、vpa-updater 的镜像。
2. 更换标签及推送。
将 vpa-admission-controller、vpa-recommender、vpa-updater 的镜像更换标签后推送到您的镜像仓库中。上传镜像操作详情可参见 容器镜像服务个人版快速入门。
3. 更改 YAML 镜像地址。
在 YAML 文件中将 vpa-admission-controller、vpa-recommender、vpa-updater 的镜像地址更新为您设定的新地址。

 是
是
 否
否
本页内容是否解决了您的问题?