- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 集群
- 集群迁移
- Serverless 集群
- 调度
- 安全
- 服务部署
- 网络
- 发布
- 日志
- 监控
- 运维
- Terraform
- DevOps
- 弹性伸缩
- 容器化
- 微服务
- 成本管理
- 混合云
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 集群
- 集群迁移
- Serverless 集群
- 调度
- 安全
- 服务部署
- 网络
- 发布
- 日志
- 监控
- 运维
- Terraform
- DevOps
- 弹性伸缩
- 容器化
- 微服务
- 成本管理
- 混合云
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
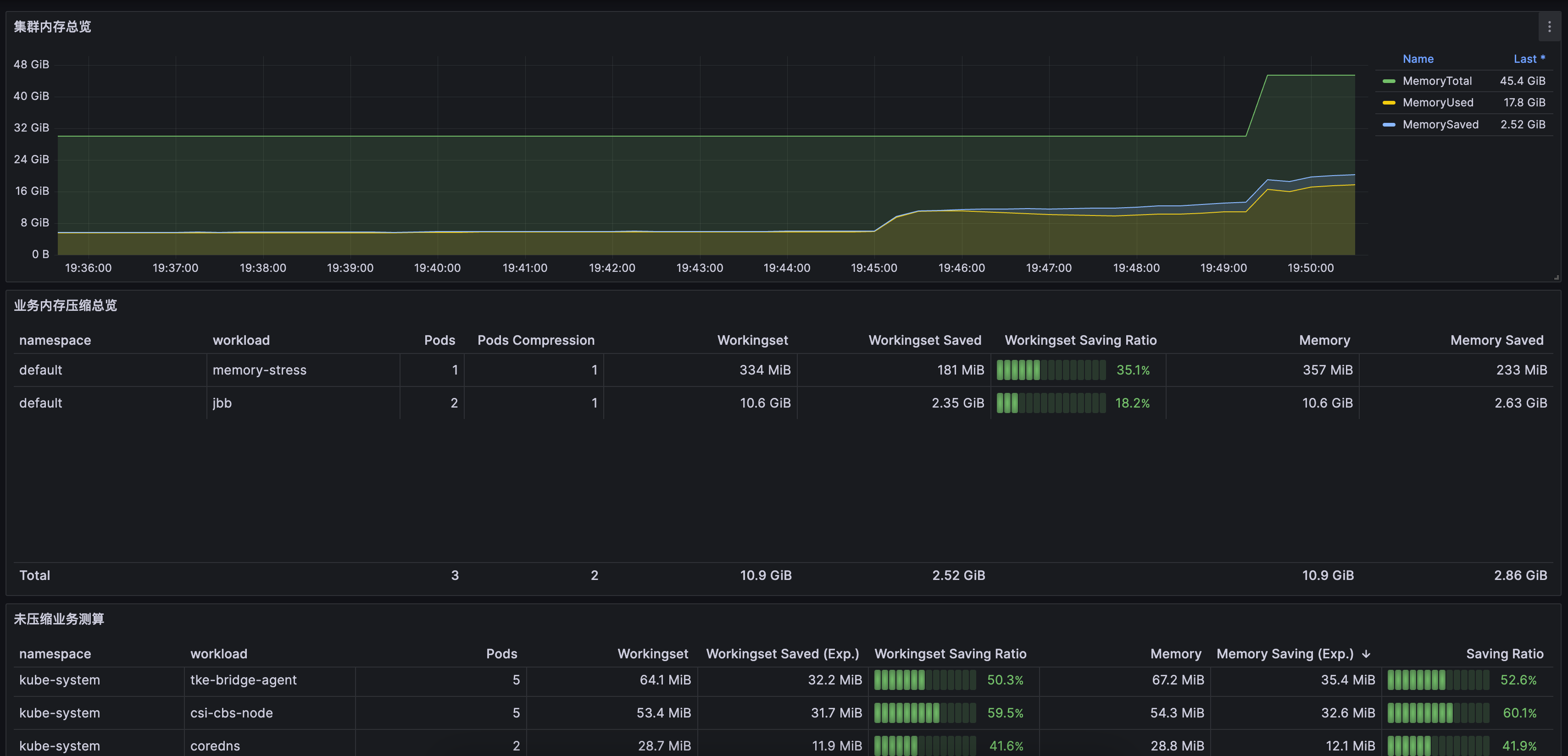
QosAgent 在端口 8084 上提供了一系列指标,用于监控节点和 Pod 内存压缩情况,以及内存和 CPU 的压力情况。用户可以自行配置 Prometheus 和 Grafana 来进行监控。此外,我们还提供了 Grafana 的监控面板模板,方便业务快速查看内存压缩效果(请 提交工单 咨询获取)。
关键指标介绍
对象 | 指标名称 | 含义 |
Pod | pod_pressure_total | Pod 级别 PSI,可以显示每个 Pod 由于缺少 CPU、内存、IO 等资源而产生的等待时长情况。 |
| pod_memory_info | Pod 的内存情况,包括对 Pod 和容器的以下内存指标进行统计:RSS、匿名内存、文件页、活跃内存和非活跃内存。 |
| pod_memory_page_fault_info | Pod 的缺页情况(包含文件页、匿名页缺页情况,major、minor 缺页情况)。 |
| pod_memory_oom_kill | Pod 的 OOM 统计。 |
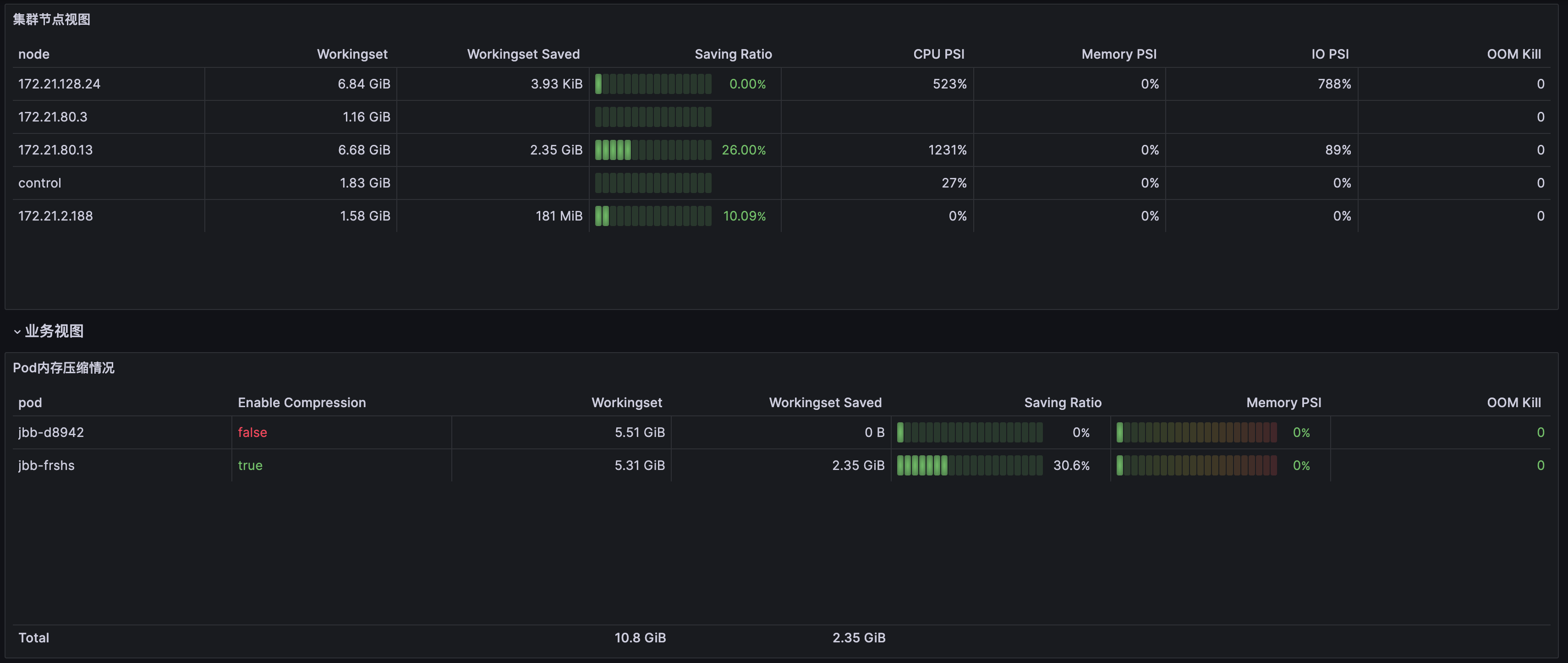
Node | node_pressure_total | 节点 CPU、IO 和 memory 的 PSI 指标(表明是否某种资源受到限制)。 |
| node_memory_page_fault_distance | refault 频率,表明“热”页面被换出去的情况。 |
| node_memory_page_fault_major | 发生磁盘读取的缺页次数。 |
| node_disk_io_time_seconds_total | 节点磁盘 IO 总时间(通过 zram0 设备的指标,可以观察到换出、换入到 zram0 的情况)。 |
| node_disk_read_bytes_total | 磁盘、zram0 设备 IO 读带宽。 |
| node_disk_reads_completed_total | 磁盘、zram0 设备 IO 读取次数(间接表明了内存压缩导致匿名内存缺页的情况)。 |
| node_disk_writes_completed(time_seconds)_total | 磁盘/zram0 设备写入次数、总耗时。 |
| node_memory_oom_kill | 磁盘、zram0 设备的写入情况。 |
哪些业务可以被压缩
支持采集业务“冷”页占比作为预估可压缩值,“冷”页包含冷匿名页和冷文件页。根据预估的压缩值和业务属性,可以判断哪些业务可以进行压缩,以及预估压缩量。
Workingset Saved:kubelet 视角观察 “Inactive anon” 的节约值。
Memory Saved:监控视角观察 “Inactive anon + Inactive File” 节约值。
节约多少内存量
每个 Pod 节约的内存大小 = zram 压缩前的大小 - zram 压缩后的大小
内存回收是否准确
观察 “node_memory_page_fault_major” 和 PSI 指标,node_memory_page_fault_major 和 Memory PSI 指标低代表回收较为准确。
业务是否稳定
可关注 Pod/Node 的 OOM 次数、PSI、Zram0 设备的 IO(如 “node_disk_read_bytes_total ”、“node_disk_reads_completed_total ”、“node_disk_writes_completed(time_seconds)_total”)变化情况,OOM 次数、PSI、Zram0 IO 升高均代表不够稳定。
对接腾讯云 Prometheus 监控
1. 登录 Prometheus 监控服务控制台。
2. 在 Prometheus 实例列表中,单击新建的实例 ID/名称 。
3. 进入 Prometheus 管理中心,在顶部导航栏中单击数据采集。
4. 在集成容器服务页面单击关联集群,将集群和 Prometheus 实例关联,详情见 关联集群。
5. 在集群列表中单击集群右侧的数据采集配置,选择新建自定义监控,并填写配置信息。
监控类型: 工作负载监控
命名空间:kube-system
工作负载类型: DaemonSet
工作负载:qos-agent
targetPort:8084
metricsPath:/metrics
6. 单击确定。
7. 在 grafana 中导入如下两个面板:
集群维度面板,请 提交工单 获取,如下图所示:
节点维度面板,请 提交工单 获取。如下图所示:
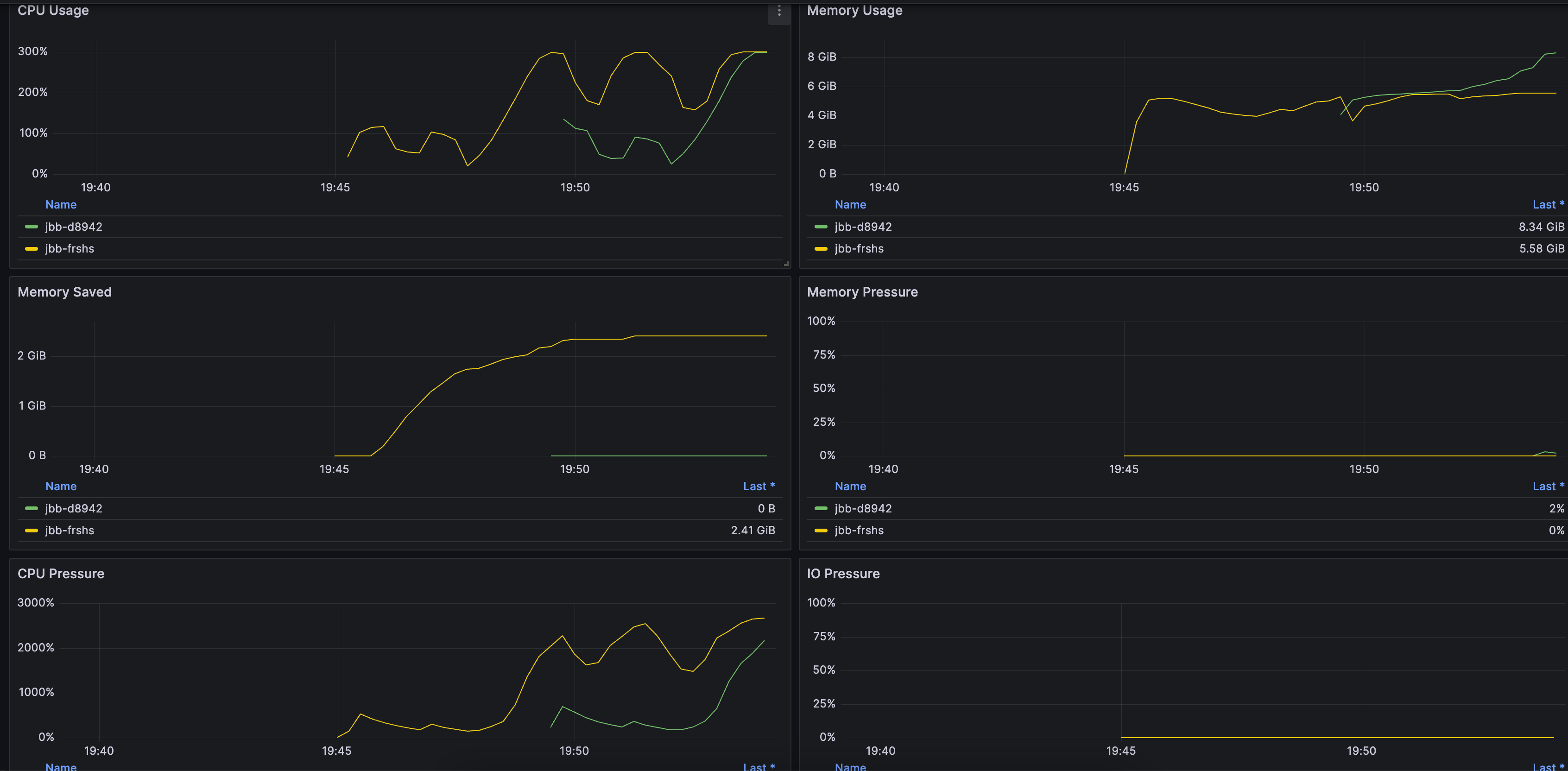

 是
是
 否
否
本页内容是否解决了您的问题?