- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 策略管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- Cluster Autoscaler 说明
- OOMGuard 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- DNSAutoscaler 说明
- COS-CSI 说明
- CFS-CSI 说明
- CFSTURBO-CSI 说明
- CBS-CSI 说明
- UserGroupAccessControl 说明
- TCR 说明
- TCR Hosts Updater
- DynamicScheduler 说明
- DeScheduler 说明
- Network Policy 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- tke-log-agent 说明
- GPU-Manager 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 远程终端
- TKE Serverless 集群指南
- TKE 注册集群指南
- TKE Insight
- TKE 调度
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- 常见问题
- 服务协议
- 联系我们
- 词汇表
HPA v2beta2 版本开始支持调节扩缩容速率
在 K8S 1.18之前,HPA 扩容是无法调整灵敏度的:
对于缩容,由
kube-controller-manager 的 --horizontal-pod-autoscaler-downscale-stabilization-window 参数控制缩容时间窗口,默认 5 分钟,即负载减小后至少需要等 5 分钟才会缩容。对于扩容,由 hpa controller 固定的算法、硬编码的常量因子来控制扩容速度,无法自定义。
这样的设计逻辑导致用户无法自定义 HPA 的扩缩容速率,而不同的业务场景对于扩容灵敏度要求可能是不一样的,如:
1. 对于有流量突发的关键业务,在需要的时候应该快速扩容(即便可能不需要,以防万一),但缩容要慢(防止另一个流量高峰)。
2. 处理关键数据的应用,数据量飙升时它们应该尽快扩容以减少数据处理时间,数据量降低时应尽快缩小规模以降低成本,数据量的短暂抖动导致不必要的频繁扩缩是可以接受的。
3. 处理常规数据/网络流量的业务,不是很重要,它们可能会以一般的方式扩大和缩小规模,以减少抖动。
HPA 在 K8S 1.18迎来了一次更新,在之前 v2beta2版本上新增了扩缩容灵敏度的控制,不过版本号依然保持 v2beta2不变。
原理与误区
HPA 在进行扩缩容时,先是由固定的算法计算出期望副本数:
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]
其中“当前指标 / 期望指标”的比例如果接近1 (在容忍度范围内,默认为0.1,即比例在0.9~1.1之间),则不进行伸缩,避免抖动导致频繁扩缩容。
说明:
容忍度是由
kube-controller-manager 参数 --horizontal-pod-autoscaler-tolerance 决定,默认是0.1,即10%。本文要介绍的扩缩容速率调节,不是指要调整期望副本数的算法,它并不会加大或缩小扩缩容比例或数量,仅是控制扩缩容的速率,实现的效果是:控制 HPA 在自定义时间内最大允许扩容/缩容自定义比例/数量的 Pod。
如何使用
使用示例
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: webspec:minReplicas: 1maxReplicas: 1000metrics:- pods:metric:name: k8s_pod_rate_cpu_core_used_limittarget:averageValue: "80"type: AverageValuetype: PodsscaleTargetRef:apiVersion: apps/v1kind: Deploymentname: webbehavior: # 这里是重点scaleDown:stabilizationWindowSeconds: 300 # 需要缩容时,先观察 5 分钟,如果一直持续需要缩容才执行缩容policies:- type: Percentvalue: 100 # 允许全部缩掉periodSeconds: 15scaleUp:stabilizationWindowSeconds: 0 # 需要扩容时,立即扩容policies:- type: Percentvalue: 100periodSeconds: 15 # 每 15s 最大允许扩容当前 1 倍数量的 Pod- type: Podsvalue: 4periodSeconds: 15 # 每 15s 最大允许扩容 4 个 PodselectPolicy: Max # 使用以上两种扩容策略中算出来扩容 Pod 数量最大的
使用说明
以上
behavior 配置是默认的,即如果不配置,会默认加上。scaleUp 和 scaleDown 都可以配置1个或多个策略,最终扩缩时用哪个策略,取决于 selectPolicy。selectPolicy 默认是 Max,即扩缩时,评估多个策略算出来的结果,最终选取扩缩 Pod 数量最多的那个策略的结果。stabilizationWindowSeconds 是稳定窗口时长,即需要指标高于或低于阈值,并持续这个窗口的时长才会真正执行扩缩,以防止抖动导致频繁扩缩容。扩容时,稳定窗口默认为0,即立即扩容;缩容时,稳定窗口默认为5分钟。policies 中定义扩容或缩容策略,type 的值可以是 Pods 或 Percent,表示每 periodSeconds 时间范围内,允许扩缩容的最大副本数或比例。场景与示例
快速扩容
当您的应用需要快速扩容时,可以使用类似如下的 HPA 配置:
behavior:scaleUp:policies:- type: Percentvalue: 900periodSeconds: 15 # 每 15s 最多允许扩容 9 倍于当前副本数
上面的配置表示扩容时立即新增当前9倍数量的副本数,当然也不能超过
maxReplicas 的限制。
假如一开始只有1个Pod,如果遭遇流量突发,且指标持续超阈值9倍以上,它将以飞快的速度进行扩容,扩容时 Pod 数量变化趋势如下:1 -> 10 -> 100 -> 1000
没有配置缩容策略,将等待全局默认的缩容时间窗口(默认5分钟)后开始缩容。
快速扩容,缓慢缩容
如果流量高峰过了,并发量骤降,如果用默认的缩容策略,等几分钟后 Pod 数量也会随之骤降,如果 Pod 缩容后突然又来一个流量高峰,虽然可以快速扩容,但扩容的过程毕竟还是需要一定时间的,如果流量高峰足够高,在这段时间内还是可能造成后端处理能力跟不上,导致部分请求失败。这时候我们可以为 HPA 加上缩容策略,HPA
behavior 配置示例如下:behavior:scaleUp:policies:- type: Percentvalue: 900periodSeconds: 15 # 每 15s 最多允许扩容 9 倍于当前副本数scaleDown:policies:- type: Podsvalue: 1periodSeconds: 600 # 每 10 分钟最多只允许缩掉 1 个 Pod
上面示例中增加了
scaleDown 的配置,指定缩容时每10分钟才缩掉1个 Pod,极大降低了缩容速度,缩容时的 Pod 数量变化趋势如下:1000 -> … (10 min later) -> 999
这个可以让关键业务在可能有流量突发的情况下保持处理能力,避免流量高峰导致部分请求失败。
缓慢扩容
如果想要您的应用不太关键,希望扩容时不要太敏感,可以让它扩容平稳缓慢一点,为 HPA 加入下面的
behavior:behavior:scaleUp:policies:- type: Podsvalue: 1periodSeconds: 300 # 每 5 分钟最多只允许扩容 1 个 Pod
假如一开始只有1个 Pod,指标一直持续超阈值,扩容时它的 Pod 数量变化趋势如下:
1 -> 2 -> 3 -> 4
禁止自动缩容
如果应用非常关键,希望扩容后不自动缩容,需要人工干预或其它自己开发的 controller 来判断缩容条件,可以使用类型如下的
behavior 配置来禁止自动缩容:behavior:scaleDown:selectPolicy: Disabled
延长缩容时间窗口
缩容默认时间窗口是5分钟,如果我们需要延长时间窗口以避免一些流量毛刺造成的异常,可以指定下缩容的时间窗口,
behavior 配置示例如下:behavior:scaleDown:stabilizationWindowSeconds: 600 # 等待 10 分钟再开始缩容policies:- type: Podsvalue: 5periodSeconds: 600 # 每 10 分钟最多只允许缩掉 5 个 Pod
上面的示例表示当负载降下来时,会等待600s (10分钟) 再缩容,每10分钟最多只允许缩掉5个 Pod。
延长扩容时间窗口
有些应用经常会有数据毛刺导致频繁扩容,而扩容出来的 Pod 可能会浪费资源。例如数据处理管道的场景,需要的副本数取决于队列中的事件数量,当队列中堆积了大量事件时,我们希望可以快速扩容,但又不希望太灵敏,因为可能只是短时间内的事件堆积,即使不扩容也可以很快处理掉。
默认的扩容算法会在较短的时间内扩容,针对这种场景我们可以给扩容增加一个时间窗口以避免毛刺导致扩容带来的资源浪费,
behavior 配置示例如下:behavior:scaleUp:stabilizationWindowSeconds: 300 # 扩容前等待 5 分钟的时间窗口policies:- type: Podsvalue: 20periodSeconds: 60 # 每分钟最多只允许扩容 20 个 Pod
上面的示例表示扩容时,需要先等待5分钟的时间窗口,如果在这段时间内指标又降下来了就不再扩容,如果一直持续超过阈值才扩容,并且每分钟最多只允许扩容20个 Pod。
常见问题
为什么用 v2beta2创建的 HPA,创建后获取到的 yaml 版本是 v1或 v2beta1?
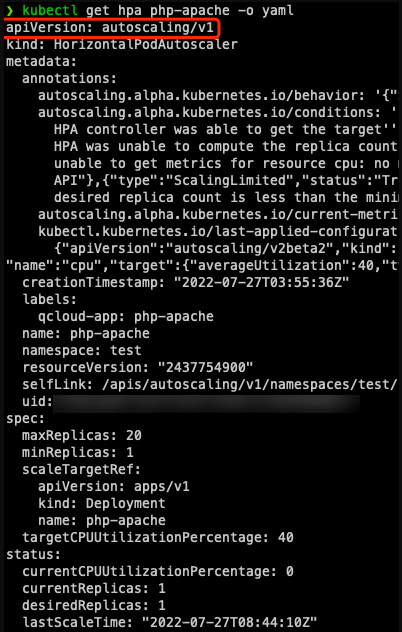
kubectl api-versions | grep autoscalingautoscaling/v1autoscaling/v2beta1autoscaling/v2beta2
以任意一种版本创建,都可以以任意版本获取(自动转换)。
如果是用 kubectl 获取,kubectl 在进行 API discovery 时,会缓存 apiserver 返回的各种资源与版本信息,有些资源存在多个版本,在 get 时如果不指定版本,会使用默认版本获取,对于 HPA,默认是 v1。如果是通过一些平台的界面获取,取决于平台的实现方式,若用腾讯云容器服务控制台,默认用 v2beta1版本展示:
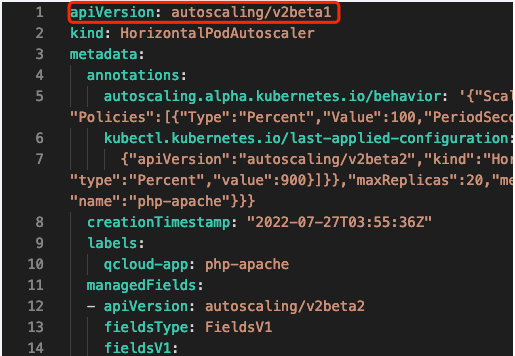
如何使用 v2beta2版本获取或编辑?
指定包含版本信息的完整资源名即可:
kubectl get horizontalpodautoscaler.v2beta2.autoscaling php-apache -o yaml# kubectl edit horizontalpodautoscaler.v2beta2.autoscaling php-apache
配置快速扩容,为什么快不起来?
如以下配置:
behavior:scaleUp:policies:- type: Percentvalue: 900periodSeconds: 10
含义是允许每10秒最大允许扩出9倍于当前数量的 Pod,实测中可能发现压力已经很大了,但扩容却并不快。
通常原因是计算周期与指标延时:
期望副本数的计算有个计算周期,默认是15秒(由
kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 参数决定)。每次计算时,都会通过相应的 metrics API 去获取当前监控指标的值,这个返回的值通常不是实时的,对于腾讯云容器服务而言,监控数据是每分钟上报一次;对于自建的 prometheus + prometheus-adapter 而言,监控数据的更新取决于监控数据抓取间隔,prometheus-adapter 的
--metrics-relist-interval 参数决定监控指标刷新周期(从 prometheus 中查询),这两部分时长之和为监控数据更新的最长时间。通常都不需要 HPA 极度的灵敏,有一定的延时一般都是可以接受的。如果实在有对灵敏度特别敏感的场景,可以考虑使用 prometheus,缩小监控指标抓取间隔和 prometheus-adapter 的
--metrics-relist-interval。小结
本文介绍了如何利用 HPA 的新特性来控制扩缩容的速率,以更好的满足各种不同场景对扩容速度的需求,也提供了常见的几种场景与配置示例,可自行根据自己需求对号入座。

 是
是
 否
否
本页内容是否解决了您的问题?