- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- Kubernetes API 操作指引
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- CBS-CSI 说明
- UserGroupAccessControl 说明
- COS-CSI 说明
- CFS-CSI 说明
- P2P 说明
- OOMGuard 说明
- TCR 说明
- TCR Hosts Updater
- DNSAutoscaler 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- Network Policy 说明
- DynamicScheduler 说明
- DeScheduler 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- GPU-Manager 说明
- Cluster Autoscaler 说明
- CFSTURBO-CSI 说明
- tke-log-agent 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 云原生监控
- 远程终端
- 策略管理
- TKE Serverless 集群指南
- TKE 边缘集群指南
- TKE 注册集群指南
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- API Category
- Node Pool APIs
- TKE Edge Cluster APIs
- CreateTKEEdgeCluster
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Introduction
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE 调度
- 常见问题
- 服务协议
- 联系我们
- 购买渠道
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- Kubernetes API 操作指引
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- 内存压缩
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- CBS-CSI 说明
- UserGroupAccessControl 说明
- COS-CSI 说明
- CFS-CSI 说明
- P2P 说明
- OOMGuard 说明
- TCR 说明
- TCR Hosts Updater
- DNSAutoscaler 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- Network Policy 说明
- DynamicScheduler 说明
- DeScheduler 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- GPU-Manager 说明
- Cluster Autoscaler 说明
- CFSTURBO-CSI 说明
- tke-log-agent 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 云原生监控
- 远程终端
- 策略管理
- TKE Serverless 集群指南
- TKE 边缘集群指南
- TKE 注册集群指南
- 云原生服务指南
- 实践教程
- 故障处理
- API 文档
- History
- API Category
- Node Pool APIs
- TKE Edge Cluster APIs
- CreateTKEEdgeCluster
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Introduction
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE 调度
- 常见问题
- 服务协议
- 联系我们
- 购买渠道
- 词汇表
温馨提示感谢您对腾讯云原生监控 TPS 的认可与信赖,为提供更优质的服务和更强大的产品能力,TPS 与原腾讯云 Prometheus 监控服务进行融合和升级,升级为 TMP。支持跨地域跨 VPC 监控,支持统一 Grafana 面板对接多监控实例实现统一查看。TMP 计费详情见 按量计费,相关云资源使用详情见 计费方式和资源使用。若您只使用基础监控的 免费指标,TMP 不会收取任何指标费用。
TPS 将于2022年5月16日下线,详情见 公告。TMP 已正式发布,欢迎 了解试用。TPS 已不支持创建新实例,我们提供一键 迁移工具,帮您一键将 TPS 实例迁移到 TMP,迁移前请 精简监控指标 或降低采集频率,否则可能产生较高费用,再次感谢您对 TPS 的支持和信任。
操作场景
本文档介绍如何精简云原生监控服务 TPS 的采集指标,避免在迁移到 TMP 后产生不必要的费用支出。
前提条件
在配置监控数据采集项前,您需要完成以下操作:
精简指标
控制台精简指标
Prometheus 监控服务 TMP 提供了一百多个免费的基础监控指标,完整的指标列表可查看 按量付费免费指标。
- 登录 容器服务控制台 ,选择左侧导航栏中的 **云原生监控**。
- 在监控实例列表页,选择需要配置数据采集规则的实例名称,进入该实例详情页。
- 在“关联集群”页面,单击集群右侧的数据采集配置,进入采集配置列表页。
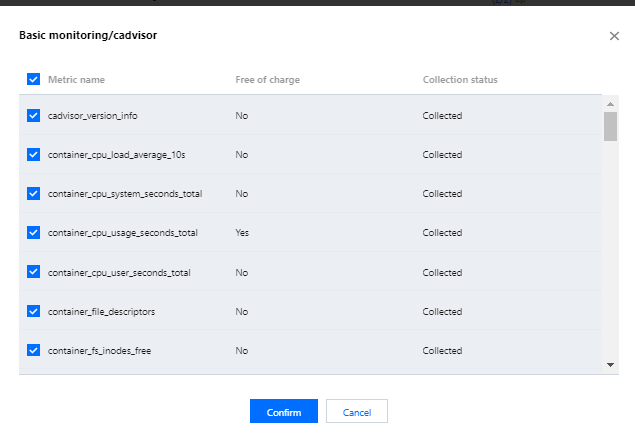
- 基础指标支持通过产品化的页面增加/减少采集对象,单击右侧的“指标详情”:

- 在以下页面您可以查看到每个指标是否免费,指标勾选表示会采集这些指标,建议您取消勾选付费指标,以免在迁移到 TMP 后造成额外的成本。仅基础监控提供免费的监控指标,完整的免费指标详情见 按量付费免费指标。付费指标计算详情见 Prometheus 监控服务按量计费。
通过 YAML 精简指标
TMP 目前收费模式为按监控数据的点数收费,为了最大程度减少不必要的浪费,建议您针对采集配置进行优化,只采集需要的指标,过滤掉非必要指标,从而减少整体上报量。详细的计费方式和相关云资源的使用请查看 文档。
以下步骤将分别介绍如何在自定义指标的 ServiceMonitor、PodMonitor,以及原生 Job 中加入过滤配置,精简自定义指标。
- 登录 容器服务控制台 ,选择左侧导航栏中的 **云原生监控**。
- 在监控实例列表页,选择需要配置数据采集规则的实例名称,进入该实例详情页。
- 在“关联集群”页面,单击集群右侧的数据采集配置,进入采集配置列表页。
- 单击编辑。如下图所示:

ServiceMonitor 和 PodMonitor
ServiceMonitor 和 PodMonitor 的过滤配置字段相同,本文以 ServiceMonitor 为例。
ServiceMonitor 示例:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 1.9.7
name: kube-state-metrics
namespace: kube-system
spec:
endpoints:
- bearerTokenSecret:
key: ""
interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量
port: http-metrics
scrapeTimeout: 15s
jobLabel: app.kubernetes.io/name
namespaceSelector: {}
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
若要采集 kube_node_info 和 kube_node_role 的指标,则需要在 ServiceMonitor 的 endpoints 列表中,加入 metricRelabelings 字段配置。注意:是 metricRelabelings 而不是 relabelings。
添加 metricRelabelings 示例:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 1.9.7
name: kube-state-metrics
namespace: kube-system
spec:
endpoints:
- bearerTokenSecret:
key: ""
interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量
port: http-metrics
scrapeTimeout: 15s # 该参数为采集超时时间,Prometheus 的配置要求采集超时时间不能超过采集间隔,即:scrapeTimeout <= interval
# 加了如下四行:
metricRelabelings: # 针对每个采集到的点都会做如下处理
- sourceLabels: ["__name__"] # 要检测的 label 名称,__name__ 表示指标名称,也可以是任意这个点所带的 label
regex: kube_node_info|kube_node_role # 上述 label 是否满足这个正则,在这里,我们希望__name__满足 kube_node_info 或 kube_node_role
action: keep # 如果点满足上述条件,则保留,否则就自动抛弃
jobLabel: app.kubernetes.io/name
namespaceSelector: {}
selector:
原生 Job
如果使用的是 Prometheus 原生的 Job,则可以参考以下方式进行指标过滤。
Job 示例:
scrape_configs:
- job_name: job1
scrape_interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量
static_configs:
- targets:
- '1.1.1.1'
若只需采集 kube_node_info 和 kube_node_role 的指标,则需要加入 metric_relabel_configs 配置。注意:是 metric_relabel_configs 而不是 relabel_configs。
添加 metric_relabel_configs 示例:
scrape_configs:
- job_name: job1
scrape_interval: 15s # 该参数为采集频率,您可以调大以降低数据存储费用,例如不重要的指标可以改为 300s,可以降低20倍的监控数据采集量
static_configs:
- targets:
- '1.1.1.1'
# 加了如下四行:
metric_relabel_configs: # 针对每个采集到的点都会做如下处理
- source_labels: ["__name__"] # 要检测的 label 名称,__name__ 表示指标名称,也可以是任意这个点所带的 label
regex: kube_node_info|kube_node_role # 上述 label 是否满足这个正则,在这里,我们希望__name__满足 kube_node_info 或 kube_node_role
action: keep # 如果点满足上述条件,则保留,否则就自动抛弃
屏蔽部分采集对象
屏蔽整个命名空间的监控
TPS 关联集群后,默认会纳管集群中所有 ServiceMonitor 和 PodMonitor,若您想屏蔽某个命名空间下的监控,可以为指定命名空间添加 label:tps-skip-monitor: "true",关于 label 的操作请 参考。
屏蔽部分采集对象
TPS 通过在用户的集群里面创建 ServiceMonitor 和 PodMonitor 类型的 CRD 资源进行监控数据的采集,若您想屏蔽指定 ServiceMonitor 和 PodMonitor 的采集,可以为这些 CRD 资源添加 labe:tps-skip-monitor: "true",关于 label 的操作请 参考。

 是
是
 否
否
本页内容是否解决了您的问题?