This document describes how to migrate unconsumed messages in a source cluster to the topics of a target cluster during the migration to the cloud.
Prerequisites
1. The source cluster has stopped message production and consumption.
2. The source cluster retains the unconsumed messages long enough to prevent them from being automatically deleted when they expire during the migration.
3. The migration script must be written in Python 2.x series on a version later than v2.7.1, preferably v2.7.5.
4. You have downloaded the migration tool migrateToCkafkaTool. Then go to the migrateToCkafkaTool directory, modify the configurations of the data-migrate.py file, and run python data-migrate.py.
How It Works
The script first scans the list of all consumer groups in the source cluster to get the list of topics (with unconsumed messages) to which the consumer has subscribed. Then the script will get the submitted offset and end offset of these topics (if a topic is subscribed to by multiple consumer groups, the script will get the smallest submitted offset). After consuming messages between the two offsets, the script will produce these messages to the corresponding topic partitions of the target cluster.
Directions
1. Create a topic in the target cluster
In the following example, the source cluster is ckafka-47bd7goz and the target cluster is ckafka-kzamzogr. We have created four topics with the same partition count as the source cluster: test1, test2, test3, and test4 in the target cluster.
In the source cluster ckafka-47bd7goz, there are two consumer groups named test123-group and test34-group. The former subscribes to topics test1, test2, and test3, and the latter, test3 and test4.
2. Download the migration toolkit
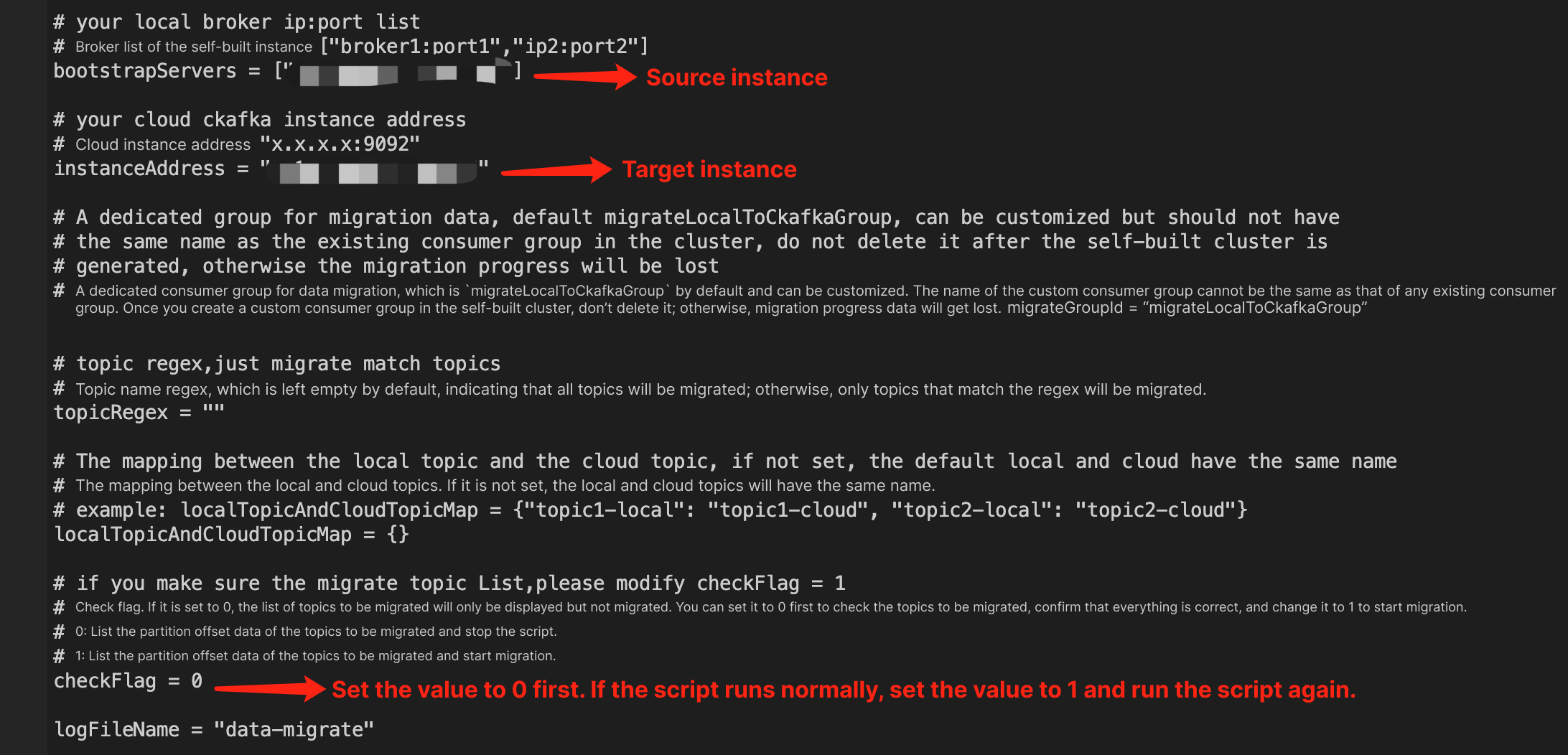
After downloading the migration tool, open the script and enter the address configurations of the source and target clusters. Set the value of checkFlag to 0 and run the script to check the topics to be migrated and their offsets.
After the script is run, some information will be output, and a text log will be written to the current directory.
3. Check the output information
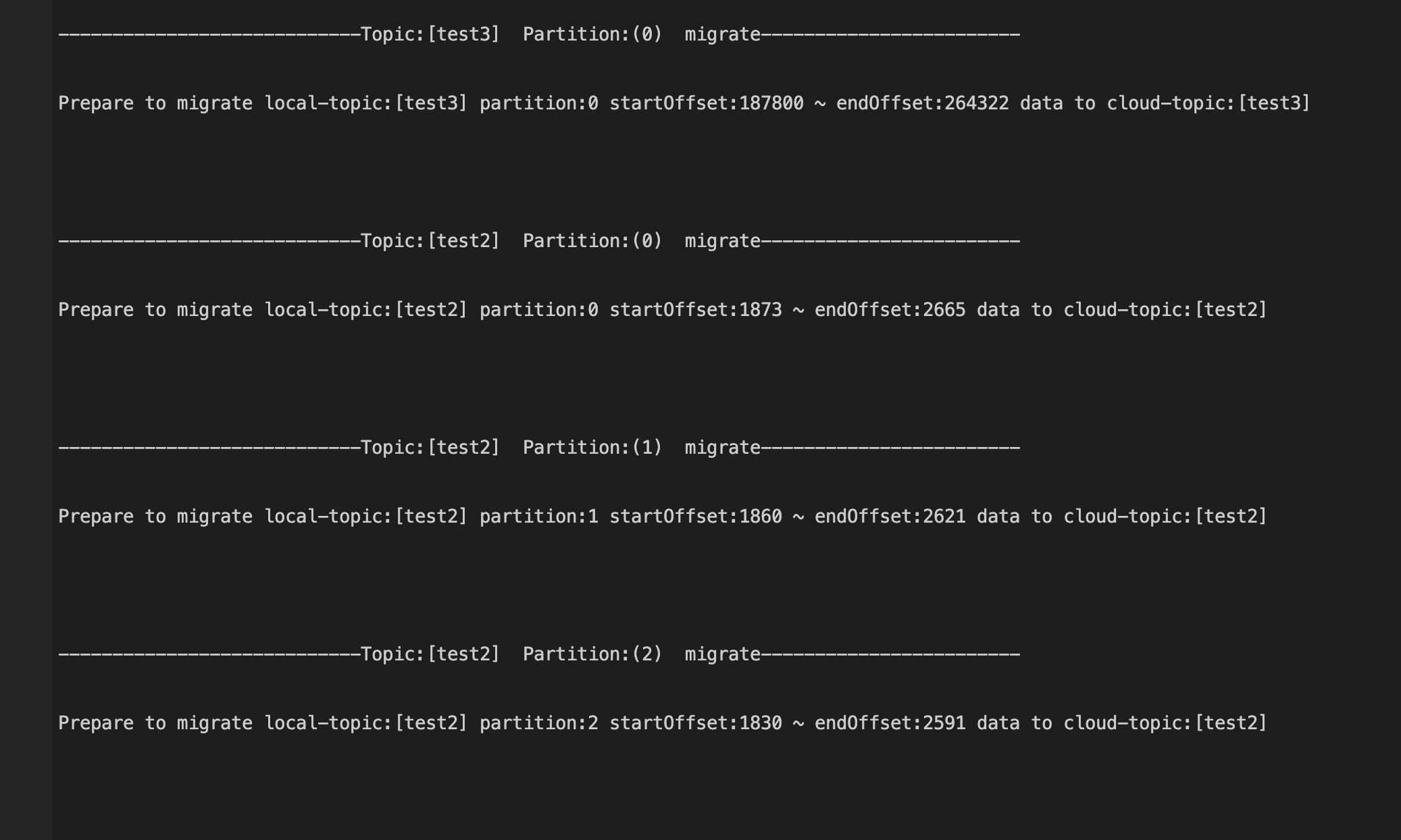
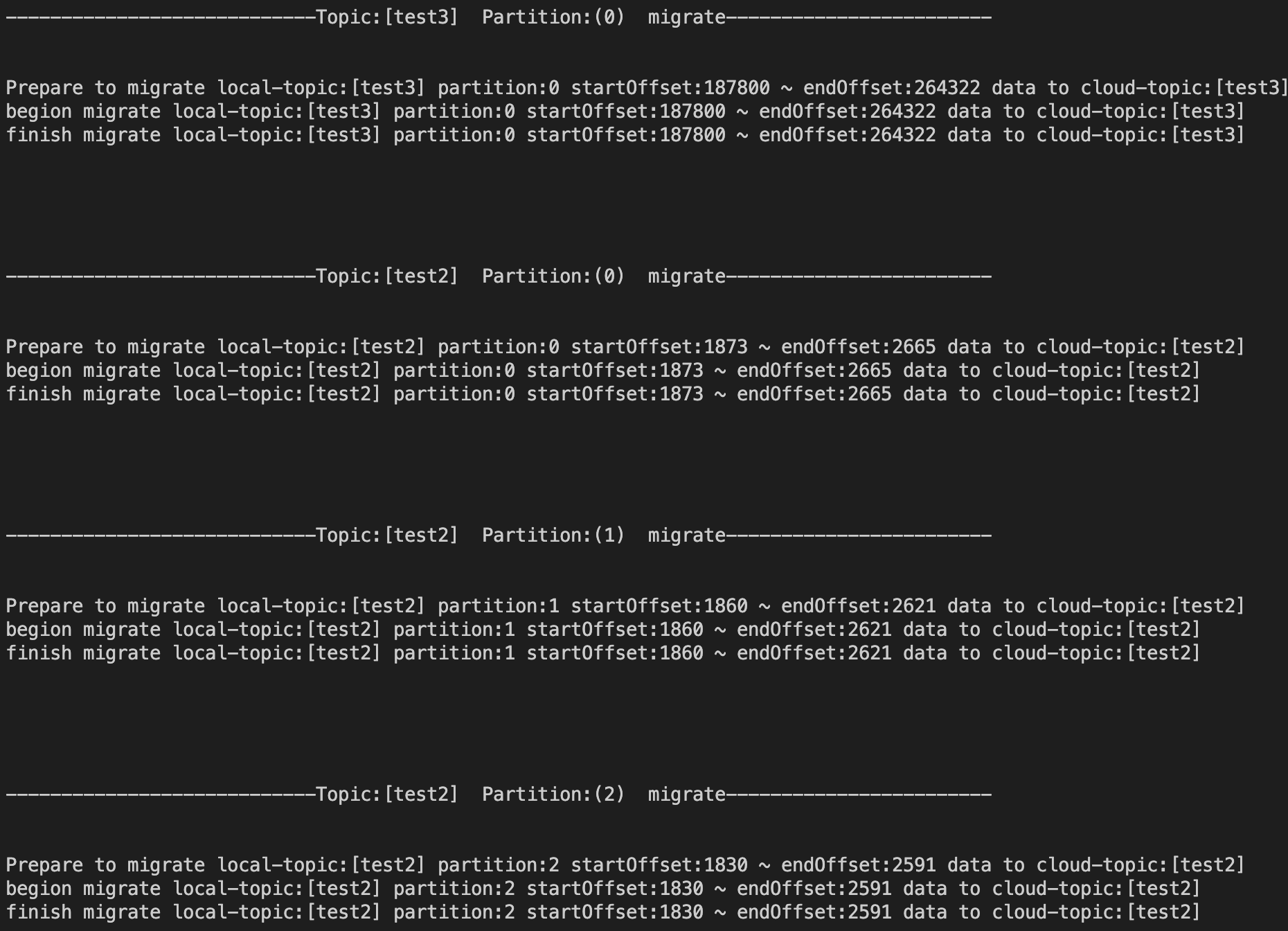
Check the Prepare to migrate information, which is the offset information of the topics to be migrated, based on the output information displayed on the screen or the text log file.
For example, you can check the subscription information of the topic test3 in the source cluster. It is subscribed to by the consumer groups test123-group and test34-group at the same time.
Theoretically, if a topic is subscribed to by multiple consumer groups, it will be synced from the smallest submitted offset, which is 187800 in this example as expected.
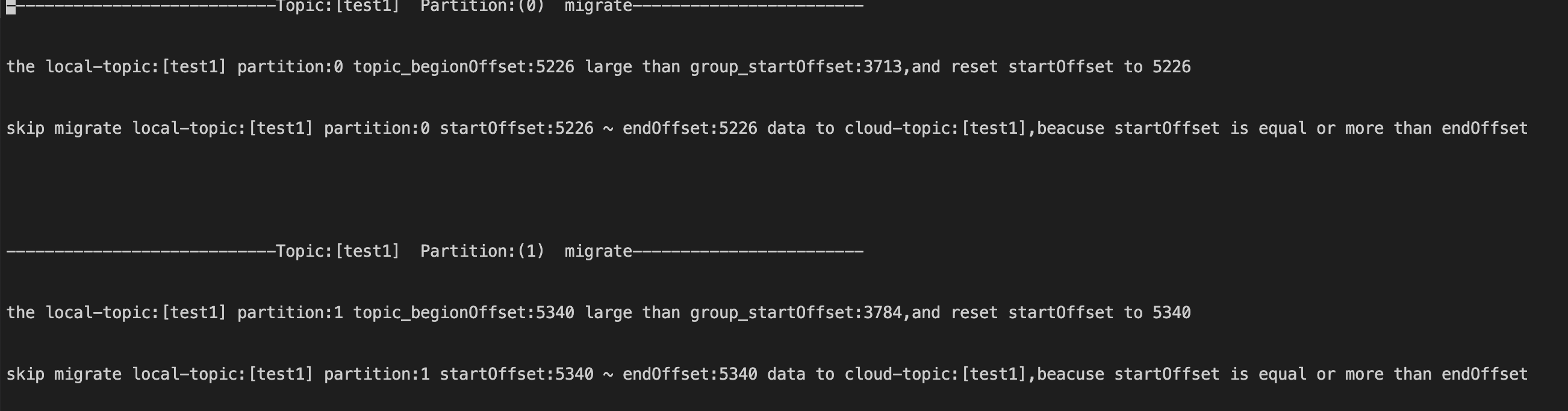
If any messages in topic test1 of the source cluster have expired and the consumer group has a submitted offset falling between expired messages, the topic test1 will be synced from the smallest offset of non-expired messages.
Let’s say you want to migrate the data from partition 0 of test1. The script will prompt you that messages have expired when the smallest offset (5226) of non-expired messages exceeds the offset (3713) submitted by the consumer group. Therefore, the offset 5226 becomes the start offset of the migration task and the largest offset of partition 0, making it impossible to migrate any messages from this partition. In this case, you will see a prompt saying skip migrate..., indicating that the migration of data in this partition will be skipped.
4. Start the migration
After checking that the output information is correct in the previous step, set the value of checkFlag to 1 and start the migration.
5. Check whether the number of messages is the same before and after the migration
Taking test3 for example, if you want to migrate 76,522 unconsumed messages from test123-group, and all these messages have actually been written to the test3 topic of the target instance, data migration is considered successful.