- 릴리스 노트 및 공지 사항
- 제품 소개
- 구매 가이드
- 시작하기
- 콘솔 가이드
- 툴 가이드
- 툴 개요
- 환경 설치 및 설정
- COSBrowser 툴
- COSCLI 툴
- COSCLI 소개
- 다운로드 및 설치 설정
- 범용 옵션
- 자주 쓰는 명령어
- 프로파일 생성 및 수정 - config
- 버킷 생성 - mb
- 버킷 삭제 - rb
- 버킷 태그 - bucket-tagging
- 버킷 또는 파일 리스트 쿼리 - ls
- 파일 유형별 통계 정보 가져오기 - du
- 파일 업/다운로드 또는 복사 - cp
- 파일 동기화 업/다운로드 또는 복사 - sync
- 파일 삭제 - rm
- 파일 해시 값 가져오기 - hash
- 멀티파트 업로드에서 생성된 조각 나열 - lsparts
- 조각 정리 - abort
- 아카이브 파일 검색 - restore
- 소프트 링크 생성/획득 - symlink
- 객체 내용 보기 - cat
- 목록하의 내용 열거 및 통계 - Isdu
- FAQ
- COSCMD 툴
- COS Migration 툴
- FTP Server 툴
- Hadoop 툴
- COSDistCp 툴
- Hadoop-cos-DistChecker 툴
- HDFS TO COS 툴
- 온라인 보조 툴
- 자가 진단 도구
- 사례 튜토리얼
- 개발자 가이드
- 데이터 레이크 스토리지
- 데이터 처리
- 장애 처리
- FAQ
- Related Agreements
- 용어집
- 릴리스 노트 및 공지 사항
- 제품 소개
- 구매 가이드
- 시작하기
- 콘솔 가이드
- 툴 가이드
- 툴 개요
- 환경 설치 및 설정
- COSBrowser 툴
- COSCLI 툴
- COSCLI 소개
- 다운로드 및 설치 설정
- 범용 옵션
- 자주 쓰는 명령어
- 프로파일 생성 및 수정 - config
- 버킷 생성 - mb
- 버킷 삭제 - rb
- 버킷 태그 - bucket-tagging
- 버킷 또는 파일 리스트 쿼리 - ls
- 파일 유형별 통계 정보 가져오기 - du
- 파일 업/다운로드 또는 복사 - cp
- 파일 동기화 업/다운로드 또는 복사 - sync
- 파일 삭제 - rm
- 파일 해시 값 가져오기 - hash
- 멀티파트 업로드에서 생성된 조각 나열 - lsparts
- 조각 정리 - abort
- 아카이브 파일 검색 - restore
- 소프트 링크 생성/획득 - symlink
- 객체 내용 보기 - cat
- 목록하의 내용 열거 및 통계 - Isdu
- FAQ
- COSCMD 툴
- COS Migration 툴
- FTP Server 툴
- Hadoop 툴
- COSDistCp 툴
- Hadoop-cos-DistChecker 툴
- HDFS TO COS 툴
- 온라인 보조 툴
- 자가 진단 도구
- 사례 튜토리얼
- 개발자 가이드
- 데이터 레이크 스토리지
- 데이터 처리
- 장애 처리
- FAQ
- Related Agreements
- 용어집
Hadoop 툴은 Hadoop-2.7.2 이상의 버전에 종속되어 있으며, Tencent Cloud COS가 기본 레이어의 파일 저장 시스템이 되어 상위 레이어의 컴퓨팅 작업을 실행하는 기능을 합니다. Hadoop 클러스터 실행에는 주요하게 단독 모드, 의사 분산 모드, 완전 분산 모드의 세 가지 모드가 있으며, 본 문서에서는 Hadoop-2.7.4 버전을 사용하여 Hadoop 완전 분산 모드 환경에서의 구축 및 간단한 wordcount 테스트에 대해 소개합니다.
환경 준비
1. 몇 대의 기기를 준비합니다.
2. 시스템 설치 및 설정: CentOS-7-x86_64-DVD-1611.iso
3. Java를 설치합니다. 자세한 작업 방법은 Java 설치 및 설정을 참조하십시오.
4. Hadoop 가용 패키지 설치: Apache Hadoop Releases Download
네트워크 설정
ifconfig -a를 사용해 각 기기의 IP를 확인하고, 상호간에 ping 명령어를 사용하여 ping 연결 가능 여부를 확인합니다. 각 기기의 IP는 모두 기록해 놓습니다.CentOS 설정
hosts 설정
vi /etc/hosts
내용 편집:
202.xxx.xxx.xxx master202.xxx.xxx.xxx slave1202.xxx.xxx.xxx slave2202.xxx.xxx.xxx slave3//IP 주소는 리얼 IP 주소로 대체
방화벽 해제
systemctl status firewalld.service //방화벽 상태 확인systemctl stop firewalld.service //방화벽 해제systemctl disable firewalld.service //시작 시 방화벽 실행 금지
시간 동기화
yum install -y ntp //ntp 서비스 설치ntpdate cn.pool.ntp.org //네트워크 시간 동기화
JDK 설치 및 설정
JDK 설치 패키지(예: jdk-8u144-linux-x64.tar.gz)를 루트(
root) 디렉터리에 업로드합니다.mkdir /usr/javatar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/java/rm -rf jdk-8u144-linux-x64.tar.gz
각 호스트 간에 JDK 복사
scp -r /usr/java slave1:/usrscp -r /usr/java slave2:/usrscp -r /usr/java slave3:/usr.......
각 호스트의 JDK 환경변수 설정
vi /etc/profile
내용 편집:
export JAVA_HOME=/usr/java/jdk1.8.0_144export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarsource/etc/profile //구성 파일 적용java -version //java 버전 확인
SSH 키 없는 액세스 설정
각 호스트에서 SSH 서비스 상태를 확인합니다.
systemctl status sshd.service //SSH 서비스 상태 확인yum install openssh-server openssh-clients //SSH 서비스 설치. 이미 설치되어 있는 경우 해당 절차 생략systemctl start sshd.service //SSH 서비스 실행. 이미 설치되어 있는 경우 해당 절차 생략
각 호스트에서 키를 생성합니다.
ssh-keygen -t rsa //키 생성
slave1:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave1.id_rsa.pubscp ~/.ssh/slave1.id_rsa.pub master:~/.ssh
slave2:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave2.id_rsa.pubscp ~/.ssh/slave2.id_rsa.pub master:~/.ssh
이상과 같이 모두 실행...
master:
cd ~/.sshcat id_rsa.pub >> authorized_keyscat slave1.id_rsa.pub >>authorized_keyscat slave2.id_rsa.pub >>authorized_keysscp authorized_keys slave1:~/.sshscp authorized_keys slave2:~/.sshscp authorized_keys slave3:~/.ssh
Hadoop 설치 및 설정
Hadoop 설치
hadoop 설치 패키지(예: hadoop-2.7.4.tar.gz)를 루트(
root) 디렉터리에 업로드합니다.tar -zxvf hadoop-2.7.4.tar.gz -C /usrrm -rf hadoop-2.7.4.tar.gzmkdir /usr/hadoop-2.7.4/tmpmkdir /usr/hadoop-2.7.4/logsmkdir /usr/hadoop-2.7.4/hdfmkdir /usr/hadoop-2.7.4/hdf/datamkdir /usr/hadoop-2.7.4/hdf/name
hadoop-2.7.4/etc/hadoop 디렉터리로 이동하여 다음 단계 작업을 진행합니다.Hadoop 설정
1. hadoop-env.sh 파일 수정 및 추가
export JAVA_HOME=/usr/java/jdk1.8.0_144
SSH 포트 기본값이 22가 아닌 경우,
hadoop-env.sh 파일에서 다음과 같이 수정할 수 있습니다.export HADOOP_SSH_OPTS="-p 1234"
2. yarn-env.sh 수정
export JAVA_HOME=/usr/java/jdk1.8.0_144
3. slaves 수정
설정 내용:
삭제:localhost추가:slave1slave2slave3
4. core-site.xml 수정
<configuration><property><name>fs.default.name</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/hadoop-2.7.4/tmp</value></property></configuration>
5. hdfs-site.xml 수정
<configuration><property><name>dfs.datanode.data.dir</name><value>/usr/hadoop-2.7.4/hdf/data</value><final>true</final></property><property><name>dfs.namenode.name.dir</name><value>/usr/hadoop-2.7.4/hdf/name</value><final>true</final></property></configuration>
6. mapred-site.xml 수정
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property></configuration>
7. yarn-site.xml 수정
<configuration><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property></configuration>
8. 각 호스트 간에 Hadoop 복사
scp -r /usr/ hadoop-2.7.4 slave1:/usrscp -r /usr/ hadoop-2.7.4 slave2:/usrscp -r /usr/ hadoop-2.7.4 slave3:/usr
9. 각 호스트에 Hadoop 환경변수 설정
구성 파일 열기:
vi /etc/profile
내용 편집:
export HADOOP_HOME=/usr/hadoop-2.7.4export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport HADOOP_LOG_DIR=/usr/hadoop-2.7.4/logsexport YARN_LOG_DIR=$HADOOP_LOG_DIR
구성 파일 적용:
source /etc/profile
Hadoop 실행
1. namenode 포맷
cd /usr/hadoop-2.7.4/sbinhdfs namenode -format
2. 실행
cd /usr/hadoop-2.7.4/sbinstart-all.sh
3. 프로세스 검사
master 호스트에 ResourceManager, SecondaryNameNode, NameNode 등이 포함되어 있으면 성공적으로 실행되었다는 의미입니다. 예시:
2212 ResourceManager2484 Jps1917 NameNode2078 SecondaryNameNode
각 slave 호스트에 DataNode, NodeManager 등이 포함되어 있으면 성공적으로 실행되었다는 의미입니다. 예시:
17153 DataNode17334 Jps17241 NodeManager
wordcount 실행
Hadoop에는 wordcount 프로세스가 포함되어 있어 직접 호출할 수 있습니다. Hadoop 실행 후, 다음의 명령어를 통해 HDFS에 있는 파일을 작업할 수 있습니다.
hadoop fs -mkdir inputhadoop fs -put input.txt /inputhadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /input /output/
6762940-439379efda5b4ad6_사본
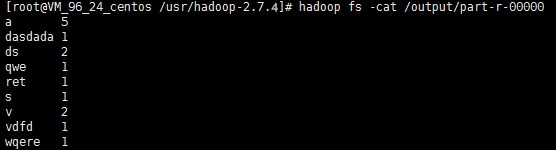
위 이미지와 같은 결과가 나타나면 Hadoop 설치가 모두 완료되었다는 의미입니다.
출력 디렉터리 조회
hadoop fs -ls /output
출력 결과 조회
hadoop fs -cat /output/part-r-00000
설명:

 예
예
 아니오
아니오
문제 해결에 도움이 되었나요?