CDH(Cloudera's Distribution, including Apache Hadoop)는 업계에서 각광받는 Hadoop의 릴리스 버전입니다. 본 문서에서는 CDH 환경에서의 COSN 스토리지 서비스 사용 방법을 안내합니다. 이를 통해 빅 데이터 연산 및 스토리지 분산을 구현함으로써 효율적인 저비용 빅 데이터 솔루션을 제공합니다.
설명:
본 문서에서 COSN은 COSN을 기반으로 구축된 파일 시스템인 Hadoop-COS를 의미합니다.
COSN 빅 데이터 모듈 지원 현황은 다음과 같습니다.
모듈 이름
COSN 빅 데이터 모듈 지원 현황
서비스 모듈 재시작 필요 여부
Yarn
지원
NodeManager 재시작
Hive
지원
HiveServer 및 HiveMetastore 재시작
Spark
지원
NodeManager 재시작
Sqoop
지원
NodeManager 재시작
Presto
지원
HiveServer, HiveMetastore, Presto 재시작
Flink
지원
필요 없음
Impala
지원
필요 없음
EMR
지원
필요 없음
자체구축 모듈
향후 지원
필요 없음
HBase
권장하지 않음
필요 없음
버전 종속
본 문서에 종속된 모듈 버전은 다음과 같습니다.
CDH 5.16.1
Hadoop 2.6.0
사용 방법
스토리지 환경 설정
1. CDH 관리 페이지에 로그인합니다.
2. 시스템 메인 페이지에서 설정>서비스 범위>고급을 선택하여 코드 스니펫 고급 설정 페이지로 이동하면 다음 그림과 같이 표시됩니다.
3. Cluster-wide Advanced Configuration Snippet(Safety Valve) for core-site.xml 코드 창에 COSN 설정을 입력합니다.
<property>
<name>fs.cosn.userinfo.secretId</name>
<value>AK***</value>
</property>
<property>
<name>fs.cosn.userinfo.secretKey</name>
<value></value>
</property>
<property>
<name>fs.cosn.impl</name>
<value>org.apache.hadoop.fs.CosFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.cosn.impl</name>
<value>org.apache.hadoop.fs.CosN</value>
</property>
<property>
<name>fs.cosn.bucket.region</name>
<value>ap-shanghai</value>
</property>
다음은 COSN 필수 설정 항목(core-site.xml에 추가 필요)입니다. COSN의 기타 설정 항목은 Hadoop 툴 문서를 참고하십시오.
COSN 매개변수
값
설명
fs.cosn.userinfo.secretId
AKxxxx
Tencent Cloud 계정의 API 키 정보
fs.cosn.userinfo.secretKey
Wpxxxx
Tencent Cloud 계정의 API 키 정보
fs.cosn.bucket.region
ap-shanghai
COS 버킷이 있는 리전
fs.cosn.impl
org.apache.hadoop.fs.CosFileSystem
FileSystem용 cosn 구현 클래스. org.apache.hadoop.fs.CosFileSystem으로 고정
fs.AbstractFileSystem.cosn.impl
org.apache.hadoop.fs.CosN
AbstractFileSystem에 대한 cosn 구현 클래스. org.apache.hadoop.fs.CosN으로 고정
4. HDFS 서비스 작업을 진행하기 위해 클라이언트 배포 설정을 클릭하면 core-site.xml 설정이 클러스터 기기에 업데이트됩니다.
5. COSN 최신 SDK 패키지를 CDH HDFS 서비스의 jar 패키지 경로에 설치합니다. 다음 예시와 같이 실제 값에 따라 변경해 주십시오.
(1) 데이터 마이그레이션 섹션에 따라 HDFS 관련 설정을 완료하고, COSN의 SDK jar 패키지를 HDFS의 해당 디렉터리에 넣습니다.
(2) CDH 시스템 메인 페이지에서 YARN을 찾아 NodeManager 서비스를 재시작합니다. TeraGen 명령어는 재시작할 필요가 없으나 TeraSort는 비즈니스 내부 로직으로 인해 NodeManger를 재시작해야 하므로, NodeManager 서비스를 일괄 재시작할 것을 권장합니다.
예시
Hadoop 표준 테스트의 TeraGen 및 TeraSort입니다.
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar teragen -Dmapred.job.maps=500 -Dfs.cosn.upload.buffer=mapped_disk -Dfs.cosn.upload.buffer.size=-1 1099 cosn://examplebucket-1250000000/terasortv1/1k-input
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar terasort -Dmapred.max.split.size=134217728 -Dmapred.min.split.size=134217728 -Dfs.cosn.read.ahead.block.size=4194304 -Dfs.cosn.read.ahead.queue.size=32 cosn://examplebucket-1250000000/terasortv1/1k-input cosn://examplebucket-1250000000/terasortv1/1k-output
설명:
cosn://schema 뒷부분을 사용자 빅 데이터 비즈니스의 버킷 경로로 변경하십시오.
2. Hive
2.1 MR 엔진
작업 단계
(1) 데이터 마이그레이션 섹션에 따라 HDFS 관련 설정을 완료하고, COSN의 SDK jar 패키지를 HDFS의 해당 디렉터리에 넣습니다.
(2) CDH 메인 페이지에서 HIVE 서비스를 찾아 Hiveserver2와 HiverMetastore 역할을 재시작합니다.
예시
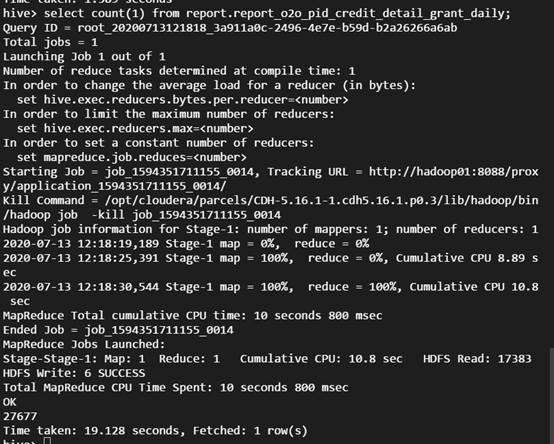
사용자의 실제 작업 쿼리입니다. Hive 명령 라인을 실행하여 Location을 생성하고, 이를 CHDFS의 파티션 테이블로 사용하는 경우입니다.
select count(1) from report.report_o2o_pid_credit_detail_grant_daily;
모니터링 결과는 다음과 같습니다.
2.2 Tez 엔진
Tez 엔진은 COSN의 jar 패키지를 Tez의 압축 패키지 내로 가져와야 합니다. 다음은 apache-tez.0.8.5를 예시로 한 설명입니다.
작업 단계
(1) CDH 클러스터에 설치한 tez 패키지를 찾은 후 압축을 해제합니다. /usr/local/service/tez/tez-0.8.5.tar.gz를 예로 들 수 있습니다.
(2) COSN의 jar 패키지를 압축 해제한 디렉터리에 넣고 다시 하나의 압축 패키지로 만듭니다.
(3) 새로 생성한 압축 패키지를 tez.lib.uris에서 지정한 경로(경로가 이미 있는 경우 변경 가능)에 업로드합니다.
(4) CDH 메인 페이지에서 HIVE를 찾아 hiveserver와 hivemetastore를 재시작합니다.
3. Spark
작업 단계
(1) 데이터 마이그레이션 섹션에 따라 HDFS 관련 설정을 완료하고, COSN의 SDK jar 패키지를 HDFS의 해당 디렉터리에 넣습니다.
(2) NodeManager 서비스를 재시작합니다.
(1) 데이터 마이그레이션 섹션에 따라 HDFS 관련 설정을 완료하고, COSN의 SDK jar 패키지를 HDFS의 해당 디렉터리에 넣습니다.
(2) COSN의 SDK jar 패키지를 presto 디렉터리에 넣어야 합니다(예시: /usr/local/services/cos_presto/plugin/hive-hadoop2).
(3) presto는 hadoop common의 gson-2...jar를 로딩할 수 없으므로 gson-2...jar 또한 presto 디렉터리에 넣어야 합니다(예시: /usr/local/services/cos_presto/plugin/hive-hadoop2, CHDFS만 gson에 종속됨).
(4) HiveServer, HiveMetaStore, Presto 서비스를 재시작합니다.
예시
HIVE에서 Location이 COSN인 테이블 쿼리를 생성합니다:
select * from cosn_test_table where bucket is not null limit 1;



 예
예
 아니오
아니오
문제 해결에 도움이 되었나요?