Hadoop-COS는 Apache Hadoop, Spark 및 Tez를 비롯한 빅 데이터 컴퓨팅 프레임워크를 통합하는 데 도움이 되는 툴입니다. HDFS와 마찬가지로 Tencent Cloud COS 데이터를 읽고 쓸 수 있습니다. Druid 및 기타 쿼리 및 분석 엔진용 Deep Storage로도 사용할 수 있습니다.
자체 구축 Hadoop에서 Hadoop-COS jar 파일을 어떻게 사용합니까?
Hadoop-COS pom 파일을 컴파일 전에 Hadoop의 버전과 동일하게 유지하도록 변경합니다. 다음으로 Hadoop-COS jar 및 COS JAVA SDK jar 파일을 hadoop/share/hadoop/common/lib 디렉터리에 넣습니다. 자세한 내용은 Hadoop-COS를 참고하십시오.
Hadoop-COS 툴에 휴지통 메커니즘이 있습니까?
HDFS의 휴지통 기능은 COS에 적용할 수 없습니다. Hadoop-COS를 사용하여 hdfs fs 명령을 실행하여 COS 데이터를 삭제하면 데이터가 cosn://user/${user.name}/.Trash 디렉터리로 이동되지만 실제 삭제는 발생하지 않으므로 데이터는 여전히 COS에 남아 있습니다. -skipTrash 매개변수를 사용하여 휴지통 기능을 건너뛰고 데이터를 직접 삭제할 수 있습니다. HDFS 휴지통과 같은 주기적인 데이터 삭제를 구현하려면 /user/${user.name}/.Trash/ 접두사가 붙은 개체에 대한 라이프사이클 규칙을 구성하십시오. 구성 가이드는 라이프사이클 설정을 참고하십시오.
CosFileSystem 클래스를 찾을 수 없는 문제
로딩 시 CosFileSystem 클래스를 찾을 수 없다는 다음 메시지가 표시되는 이유는 무엇입니까? Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.fs.CosFileSystem not found
가능한 원인1
구성이 올바르게 로딩되었지만 hadoop classpath에 Hadoop-COS jar 위치가 포함되어 있지 않습니다.
해결 방법
Hadoop-COS jar의 위치를 hadoop classpath에 로딩합니다.
가능한 원인2
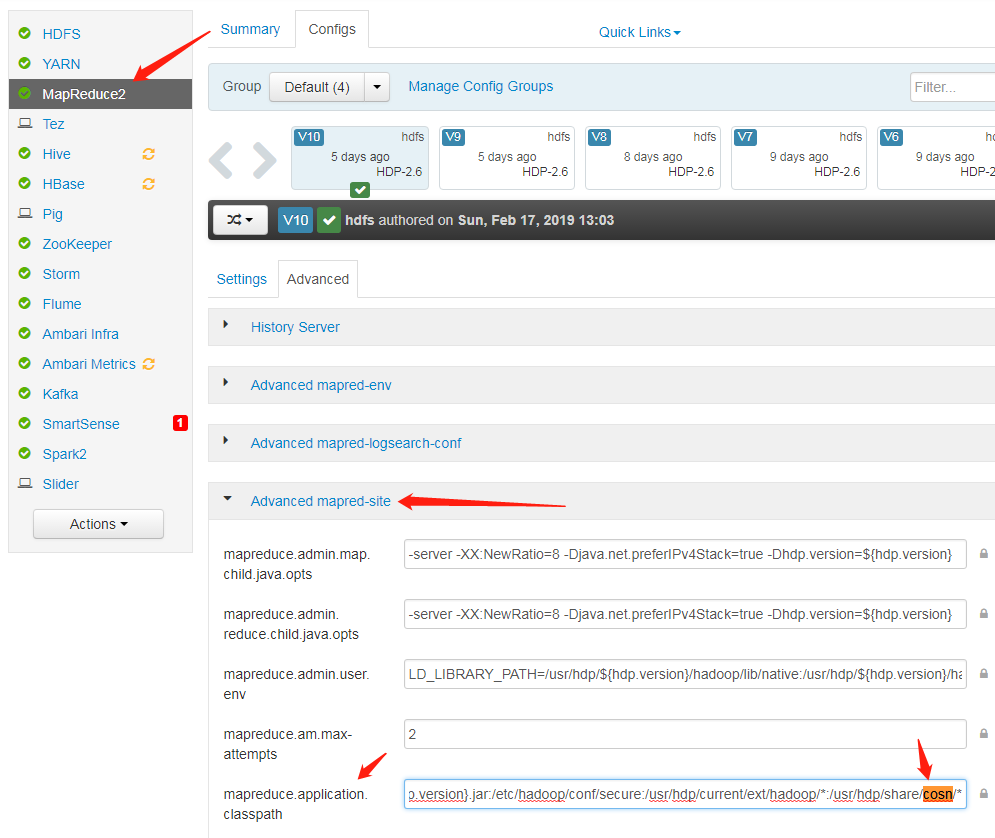
mapred-site.xml 구성 파일에 mapreduce.application.classpath는 Hadoop-COS jar의 위치가 포함되어있지 않습니다.
해결 방법
mapred-site.xml 구성 파일에 mapreduce.application.classpath에 cosn jar의 경로를 추가하고 서비스를 다시 시작합니다.
정품 Hadoop을 사용하는데 CosFileSystem 클래스를 찾을 수 없다는 오류가 표시됩니다.
Hadoop-COS는 정품 Hadoop 버전과 Hadoop-COS 버전을 유지 보호합니다. 상응하는 fs.cosn.impl과 fs.AbstractFileSystem.cosn.impl 구성이 다를 수 있습니다.
빅 데이터 시나리오에서 동시 접속률이 비교적 높은 경우 COS에서 주파수 제어가 트리거되어 503 Reduce your request rate 오류가 발생합니다. fs.cosn.maxRetries 매개변수를 설정하여 오류가 리턴된 요청을 재시도할 수 있으며, 해당 매개변수의 기본 설정은 200번입니다.
대역폭 제한을 설정했는데 적용되지 않는 이유는 무엇입니까?
신규 버전은 속도 제한 fs.cosn.traffic.limit(b/s) 구성을 지원하며, 해당 설정은 tag가 5.8.3 이상인 버전에서만 지원합니다. Github 웨어하우스에서 확인할 수 있습니다.
멀티파트 문제
Hadoop-COS에서 업로드하는 멀티파트 블록의 크기는 어떻게 합리적으로 설정합니까?
Hadoop-COS 내부에서 멀티파트 동시 업로드를 통해 대용량 파일을 처리하며, fs.cosn.upload.part.size(Byte) 구성으로 COS에 업로드하는 블록의 크기를 제어합니다.
COS의 멀티파트 업로드는 최대 10000개까지 가능합니다. 따라서 사용할 단일 파일의 최대 크기를 예측해야 합니다. 예를 들어 블록 크기가 8MB인 경우 최대 78GB의 단일 파일 업로드를 지원합니다. 블록 크기는 최대 2GB까지, 즉 단일 파일 크기는 최대 19TB까지 지원합니다. 블록 수가 10000개를 초과하면 400 오류가 발생하며 해당 설정 확인을 통해 정상 여부를 확인할 수 있습니다.
비교적 큰 파일 업로드 시 COS 상에서 파일을 표시할 때 딜레이가 발생합니다. 실시간으로 표시하지 않는 이유는 무엇입니까?
Hadoop-COS는 대용량 파일, 즉 blockSize(fs.cosn.upload.part.size)를 초과하는 파일에 대해 모두 멀티파트 업로드 방식을 사용하며, 모든 블록이 COS에 업로드된 후에야 볼 수 있습니다. Hadoop-COS는 현재 Append 작업을 지원하지 않습니다.
Buffer 문제
업로드 Buffer 유형은 어떻게 선택합니까? 유형별 차이점은 무엇입니까?
Hadoop-COS에서 업로드 시 buffer 유형을 선택할 수 있으며, fs.cosn.upload.buffer 매개변수를 사용하여 설정할 수 있고 다음 3가지 중 1가지로 설정할 수 있습니다.
mapped_disk 기본 설정. 작업 시 디스크가 부족하지 않도록 fs_cosn.tmp.dir를 공간이 충분한 디렉터리로 설정해야 합니다.
direct_memory: JVM off-heap 메모리를 사용합니다(해당 부분은 JVM의 관리 제어를 받지 않아 설정을 권장하지 않음).
non_direct_memory: JVM on-heap 메모리를 사용합니다. 권장 설정은 128M입니다.
buffer 유형이 mapped_disk일 때 buffer 생성 실패 오류인 create buffer failed. buffer type: mapped_disk, buffer factory:org.apache.hadoop.fs.buffer.CosNMappedBufferFactory 오류가 표시됩니다.
가능한 원인
현재 사용자에게 Hadoop-COS를 사용하는 임시 디렉터리에 대한 읽기/쓰기 액세스 권한이 없어서 발생할 수 있습니다. Hadoop-COS가 기본적으로 사용하는 임시 디렉터리는 /tmp/hadoop_cos로, 사용자가 fs.cosn.tmp.dir를 설정하여 지정할 수 있습니다.
해결 방법
현재 사용자에게 /tmp/hadoop_cos 권한을 부여하거나 fs.cosn.tmp.dir로 임시 파일 디렉터리를 지정하여 읽기/쓰기 권한을 부여합니다.
실행 오류 문제
연산 작업 실행 중 오류 정보인 java.net.ConnectException: Cannot assign requested address (connect failed) (state=42000,code=40000)가 표시됩니다. 어떻게 처리해야 합니까?
Cannot assign requested address 오류가 나타나는 이유는 일반적으로 사용자가 단 시간 내에 대량의 TCP 단기 연결을 생성하였기 때문에 발생합니다. 연결 완료 후 로컬 포트에서 즉시 회수되지 않으면 기본적으로 60초의 시간 초과 단계를 거치며, 이로 인해 클라이언트에 단 시간 동안 내에 Server와 Socket 연결을 구축하는 데 사용할 가용 포트가 없게 됩니다.
해결 방법
/etc/sysctl.conf 파일을 수정하여 커널 매개변수를 다음과 같이 조정해 해당 문제를 방지합니다.
net.ipv4.tcp_timestamps = 1 #TCP를 열어 타임스탬프 지원
net.ipv4.tcp_tw_reuse = 1 #TIME_WAIT 상태인 socket을 신규 TCP에 연결하는 데 사용하도록 지원
net.ipv4.tcp_tw_recycle = 1 #TIME-WAIT 상태인 socket의 빠른 회수 활성화
net.ipv4.tcp_syncookies=1 #SYN Cookies 활성화. SYN 등 대기열이 오버플로우되는 경우 cookie를 활성화하여 처리해 소량의 SYN 공격을 방지합니다. 기본값은 0입니다.
net.ipv4.ip_local_port_range = 1024 65000 #대외 연결 포트 범위. 기본값은 32768~61000이며 1024~65000으로 수정합니다.
net.ipv4.tcp_max_tw_buckets = 10240 #TIME_WAIT 상태의 Socket의 수량 제한. 해당 수량을 초과하는 경우 새로운 TIME_WAIT 소켓이 직접 릴리즈됩니다. 기본값은 180000이며, 해당 매개변수를 적합하게 낮추면 TIME_WAIT 상태의 Socket 수가 감소됩니다.
파일 업로드 시 java.lang.Thread.State: TIME_WAITING (parking) 오류가 발생합니다. 구체적으로 스택에 org.apache.hadoop.fs.BufferPoll.getBuffer 및 java.util.concurrent.locks.LinkedBlockingQueue.poll가 포함되어 잠기는 상황이 발생합니다.
가능한 원인
파일 업로드 시 여러 번 buffer를 초기화했지만 실제로 쓰기 작업이 트리거되지 않은 경우 발생할 수 있습니다.

 예
예
 아니오
아니오
문제 해결에 도움이 되었나요?