This document describes how to create a node pool in a cluster via the TKE console and describes node pool-related operations, such as viewing, managing, and deleting a node pool.
1. Log in to the TKE console and click Cluster in the left sidebar.
2. On the Cluster Management page, click the ID of the target cluster to go to the cluster details page.
3. Click Node management > Node pool in the left sidebar to go to the node pool list page.
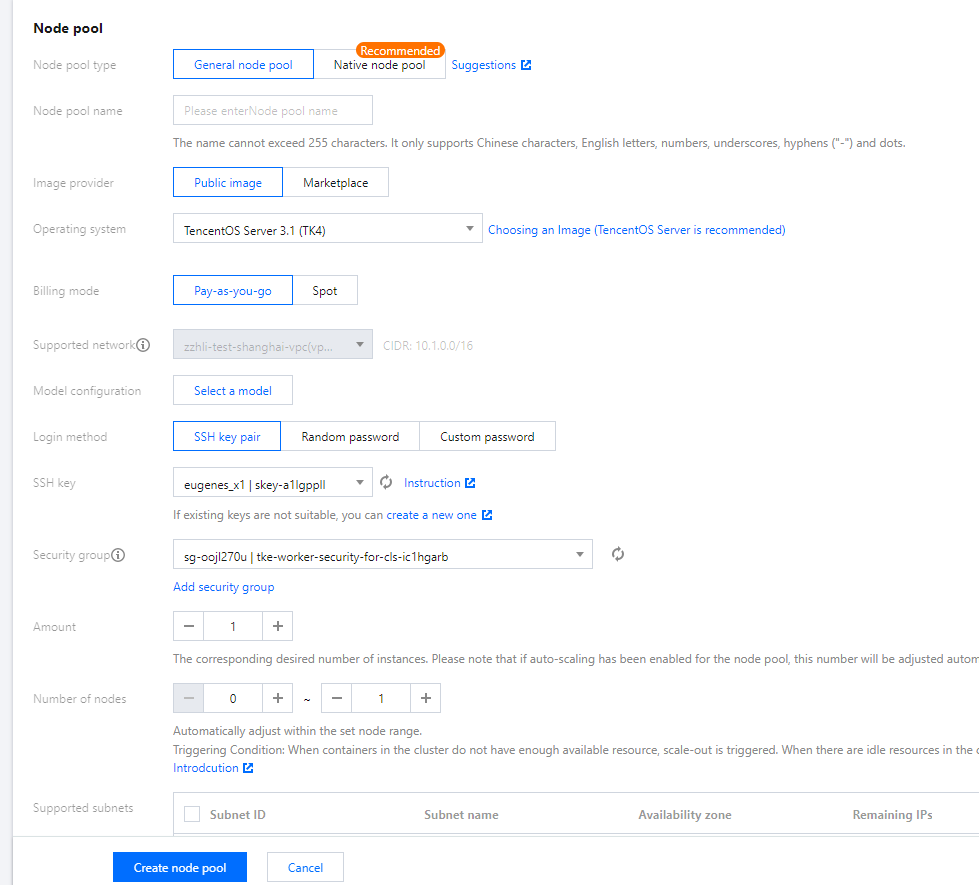
4. Click Create node pool to go to the Node pool page, and set parameters as instructed.
Node pool name: Enter a custom pool name.
Operating system: Select an OS based on actual needs. This OS takes effect on the node pool level and can be modified. After modification, the new OS only take effect for the new nodes in the node pool, rather than the existing nodes.
Billing mode: Valid values include Pay-as-you-go and Spot. You can select a value as required. For more information, see Billing Mode.
Supported network: The system will assign IP addresses within the address range of the node network for servers in the cluster.
Note
This field is specified at the cluster level, which cannot be modified after configuration.
Model configuration: Click Select a model. On the Model Configuration page, select the values as needed based on the following descriptions:
Availability zone: Launch configurations do not contain availability zone information. This option is only used to filter available instance types in the availability zone.
Model: Select the model by specifying the number of CPU cores, memory size, and instance type. For more information, see Families and Models.
System disk: Controls the storage and schedules the operating of Cloud Virtual Machines (CVMs). You can view the system disk types available for the selected model and select the system disk as required. For more information, see Cloud Disk Types.
Data disk:Stores all the user data. You can specify the values according to the following descriptions. Each model corresponds to different data disk settings. For more information, see the following table:
Model
Data Disk Settings
Standard, Memory Optimized, Computing, and GPU
No option is selected by default. If you select any of these options, you must specify the cloud disk settings and formatting settings.
High I/O and Big Data
These options are selected by default and cannot be cleared. You can customize the formatting settings for the default local disks.
Batch-based
This option is selected by default, but can be cleared. If this option is selected, you can purchase only default local disks. You can customize the formatting settings for the default local disks.
Add Data Disk (optional): click Add Data Disk and specify the settings according to the table above.
Public Bandwidth: Assign free public IP is selected by default, indicating that the system will assign a public IP for free. Billing by traffic or by bandwidth can be selected as needed. For billing details, see Public Network Billing. You can customize the network speed.
Login method: Select any one of the following login methods as required:
SSH key pair: A key pair is a pair of parameters generated by an algorithm. It is a way to log in to a CVM instance that is more secure than regular passwords. For more details, see SSH Key.
SSH key: This parameter displays only when SSH Key Pair is selected. Select an existing key in the drop-down list. For how to create a key, see Creating an SSH key.
Random password: The system sends an automatically generated password to your Message Center.
Custom password: Set a password as prompted.
Security group: The default value is the security group specified when the cluster is created. You can replace the security group or add a security group as required.
Amount: Specify the desired capacity as needed.
Note
If auto scaling has been enabled for the node pool, this quantity will be automatically adjusted based on the loads of the cluster.
Number of nodes: The number of nodes will be automatically adjusted within the specified node quantity range, which will not exceed the specified range.
Supported subnets: Select an available subnet as needed.
Note
The default multiple subnets scale-out policy of node pool is that if you have configured multiple subnets, when the node pool performs scale-out (manual scale-out and auto scaling), it creates nodes based on the priority determined by the order in the subnet list. If a node can be successfully created in the subnet of the highest priority, all nodes will be created in the subnet.
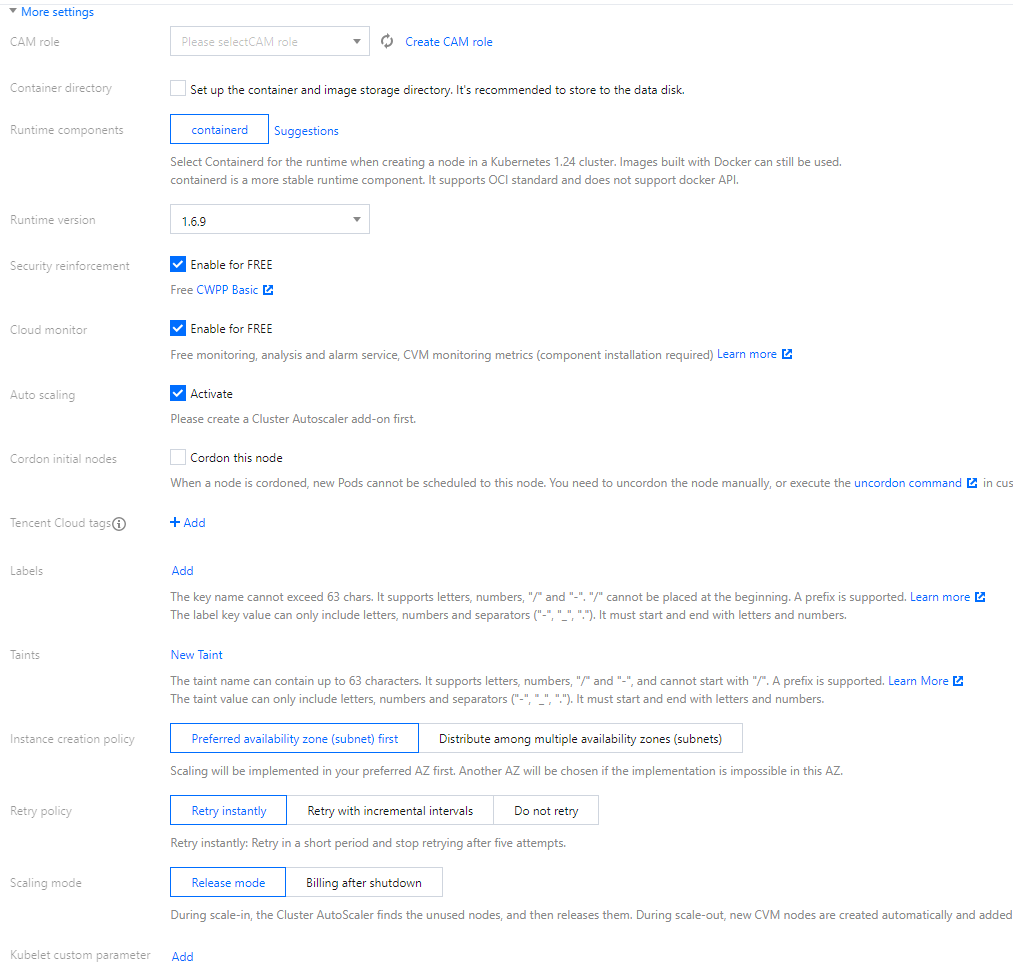
(Optional) Click More Settings to view or configure more information.
CAM role: You can bind all the nodes of the node pool to the same CAM role, and grant the authorization policy bound to the role to the nodes. For more information, see Managing Roles.
Container directory: Select this option to set up the container and image storage directory. We recommend that you store to the data disk, such as /var/lib/docker.
Security Services: Free DDoS, Web Application Firewall (WAF) and Cloud Workload Protection (CWP) are activated by default. For more information, see Cloud Workload Protection.
Cloud monitor: Free monitoring, analysis, and alarms are activated by default, and components are installed to obtain CVM monitoring metrics. For more information, see Tencent Cloud Observability Platform.
Auto scaling: Enable is selected by default.
Cordon initial nodes: After you check Cordon this node, new Pods cannot be scheduled to this node. You can uncordon the node manually, or execute the uncordon command in custom data as needed.
Labels: Click Add and customize the settings of the label. The specified label here will be automatically added to nodes created in the node pool to help filter and manage the nodes using the label.
Taints: This is a node-level attribute and is usually used with Tolerations. You can specify this parameter for all the nodes in the node pool, so as to stop scheduling Pods that do not meet the requirements to these nodes and drain such Pods from the nodes.
Note
The value of Taints usually consists of key, value, and effect. Valid values of effect are as follows:
PreferNoSchedule: Optional condition. Try not to schedule a Pod to a node with a taint that cannot be tolerated by the Pod.
NoSchedule: When a node contains a taint, a Pod without the corresponding toleration must not be scheduled.
NoExecute: When a node contains a taint, a Pod without the corresponding toleration to the taint will not be scheduled to the node and any such Pods already on the node will be drained.
Assume that Taints is set to key1=value1:PreferNoSchedule, the configuration in the TKE console is as below:
Retry policy: Select either of the following policies as needed.
Retry instantly: Retry immediately. The system stops retrying after failing five times in a row.
Retry with incremental intervals: The retry interval extends as the number of consecutive failures increases. The value ranges from seconds to one day.
Scaling mode: select either of the following two scaling modes as needed.
Release mode: If this mode is selected, the system automatically releases idle nodes as determined by Cluster AutoScaler during scale-in and automatically creates and adds a node to scaling groups during scale-out.
Billing after shutdown: If this mode is selected, during scale-out, the system preferably starts nodes that have been shut down, and if the number of nodes still fails to meet requirements, the system creates the desired number of nodes. During scale-in, the system shuts down idle nodes. If the nodes support the No Charges When Shut Down feature, the nodes that are shut down will not be billed, but remaining nodes are still billed. For more information, see No Charges When Shut down for Pay-as-You-Go Instances Details.
Custom data: Specify custom data to configure the node, that is, to run the configured script when the node is started up. You need to ensure the reentrant and retry logic of the script. The script and its log files can be viewed at the node path: /usr/local/qcloud/tke/userscript.
5. Click Create Node Pool.
Related Operations
After a node pool is created, you can manage the node pool according to the following documents:


 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?