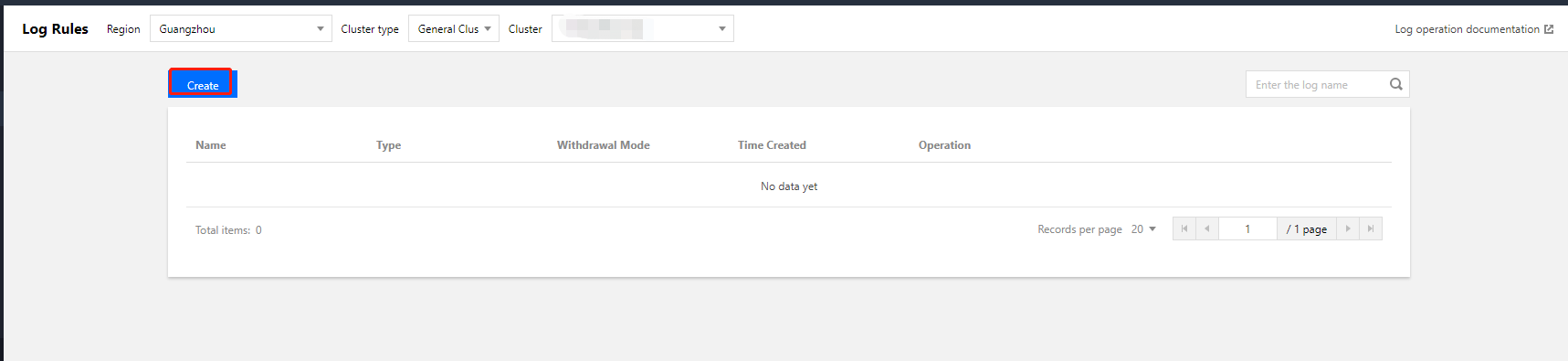
2. At the top of the Log Rules page, select the region and the TKE Serverless cluster where you want to configure the log collection rules and click Create, as shown in the figure below:
3. On the "Create Log Collecting Policy" page, select the collection type and configure the log source, consumer end, log parsing method. Currently, the following collection types are supported: container standard output and container file path.
Collecting standard output logs of a container
Collecting file logs in container
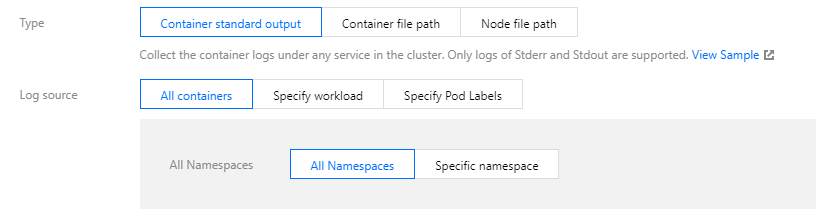
Select Container standard output as the collection type, and configure the log source as needed, as shown below:
This type of log source supports:
All containers: all namespaces or all containers under a namespace.
Specify workload: the containers of a specified workload under a namespace. You can add multiple namespaces.
Specify Pod Labels: specify multiple Pod Labels under a namespace, and collect all containers that match the Labels.
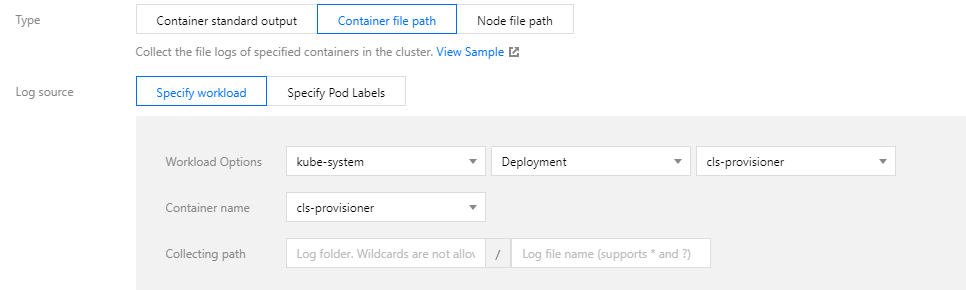
Select Container file path as the collection type, and configure the log source as needed, as shown below:
This type of log source supports:
Specify workload: the specified file path of a container of a specified workload under a namespace.
Specify Pod Labels: specify multiple Pod Labels under a namespace, and collect the specified file path of all containers that match the Labels.
You can specify a file path or use wildcards for the collection path. For example, when the container file path is /opt/logs/*.log, you can specify the collection path as /opt/logs and the file name as *.log.
Note:
If the collection type is selected as "Container File Path", the corresponding path cannot be a soft link. Otherwise, the actual path of the soft link will not exist in the collector's container, resulting in log collection failure.
Note:
For container standard output and container files, besides the original log content, the metadata related to the container or Kubernetes (such as the name of the Pod that generated the logs) will also be reported to the CLS. Therefore, when viewing logs, users can trace the log source or search based on the container identifier or characteristics (such as container name and labels).
The metadata related to the container or Kubernetes is shown in the table below:
Field Name
Description
cluster_id
The ID of the cluster to which logs belong
container_name
The name of the container to which logs belong
image_name
The image name IP of the container to which logs belong
namespace
The namespace of the Pod to which logs belong
pod_uid
The UID of the Pod to which logs belong
pod_name
The name of the Pod to which logs belong
pod_ip
The IP of the Pod to which logs belong
pod_lable_{label name}
The labels of the Pod to which logs belong (for example, if a Pod has two labels: app=nginx and env=prod, the reported log will have two metadata entries attached: pod_label_app:nginx and pod_label_env:prod).
4. Configure the CLS as the consumer end. Select the desired logset and log topic. It is recommended to select Auto-create Log Topic, as shown in the figure below:
Note:
CLS currently only supports log collection and reporting for intra-region container clusters.
The log set and log topic cannot be updated after the log rule is configured.
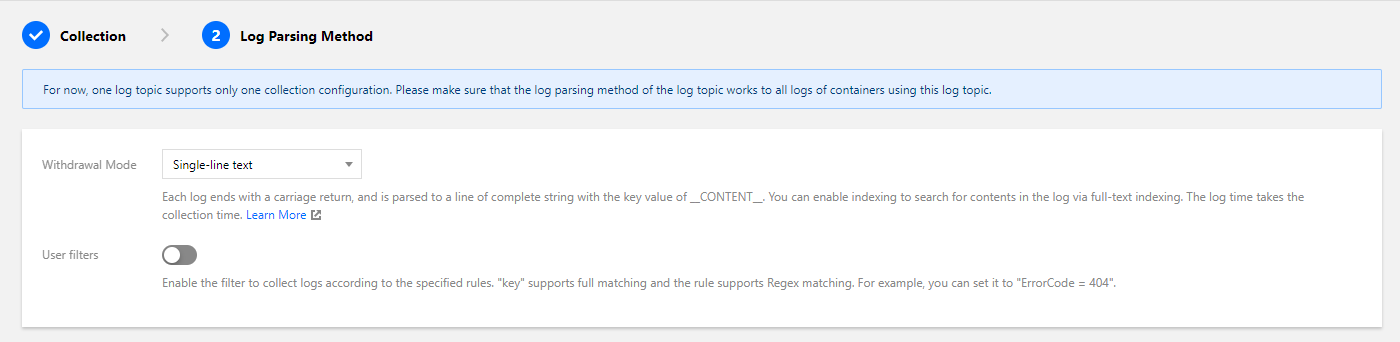
5. Click Next and choose a log extraction mode, as shown below:
Extraction modes
Parsing Mode
Description
Related Document
Full text in a single line
A log contains only one line of content, and the line break `\\n` to mark the end of a log. Each log will be parsed into a complete string with CONTENT as the key value. When log Index is enabled, you can search for log content via full-text search. The time attribute of a log is determined by the collection time.
A log with full text in multi lines spans multiple lines and a first-line regular expression is used for match. When a log in a line matches the preset regular expression, it is considered as the beginning of a log, and the next matching line will be the end mark of the log. A default key value, CONTENT, will be set as well. The time attribute of a log is determined by the collection time. The regular expression can be generated automatically.
The single-line - full regular expression mode is a log parsing mode where multiple key-value pairs can be extracted from a complete log. When configuring the single-line - full regular expression mode, you need to enter a sample log first and then customize your regular expression. After the configuration is completed, the system will extract the corresponding key-value pairs according to the capture group in the regular expression. The regular expression can be generated automatically.
The multi-line - full regular expression mode is a log parsing mode where multiple key-value pairs can be extracted from a complete piece of log data that spans multiple lines in a log text file (such as Java program logs) based on a regular expression. When configuring the multi-line - full regular expression mode, you need to enter a sample log first and then customize your regular expression. After the configuration is completed, the system will extract the corresponding key-value pairs according to the capture group in the regular expression. The regular expression can be generated automatically.
A JSON log automatically extracts the key at the first layer as the field name and the value at the first layer as the field value to implement structured processing of the entire log. Each complete log ends with a line break `\\n`.
In a separator log, the entire log data can be structured according to the specified separator, and each complete log ends with a line break `\\n`. When CLS processes separator logs, you need to define a unique key for each separate field. Invalid fields, which are fields that need not be collected, can be left blank. However, you cannot leave all fields blank.
Instructions for automatic regular expression generation
When you select Multiple lines - full regex, Single line - full regex, or Multi-line texts, the regular expression can automatically generated based on the log sample.
Here takes the Single line - full regex as an example:
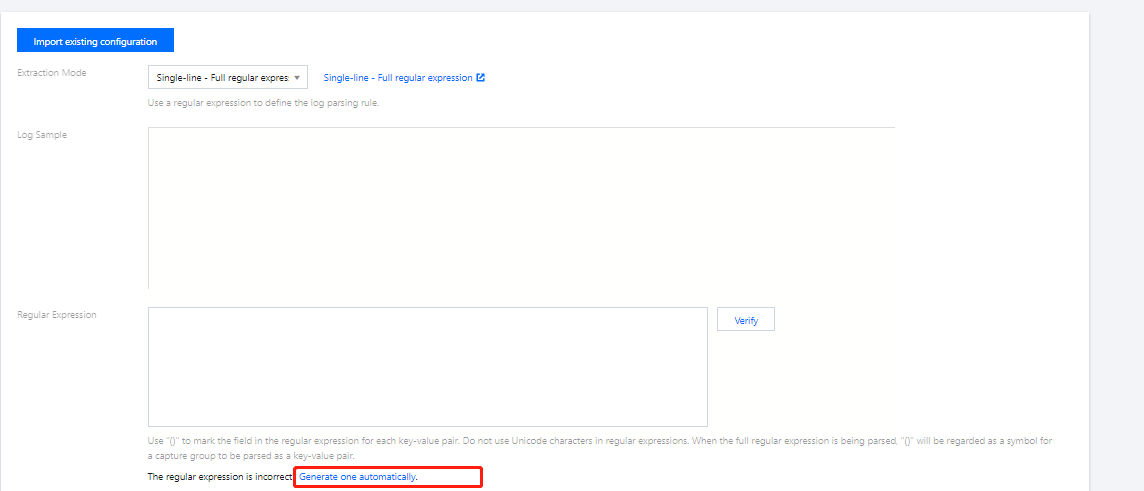
1. Click Auto-Generate Regular Expression, as shown below:
2. In the pop-up window, select the field to be extracted in the log sample, and fill in the key.
3. Click Confirm to generate the corresponding regular expression of the field, and automatically fill in the extraction result. Repeat this operation until the log is completely extracted.
Note:
Currently, one log topic supports only one collection configuration. Ensure that all container logs that adopt the log topic can accept the log parsing method that you choose. If you create different collection configurations under the same log topic, the earlier collection configurations will be overwritten.
6. Enable other features as needed.
Enable the filter and configure the rules.
After the filter is enabled, only the logs that meet the filter rules will be collected. Key supports full matching and the rule supports regex matching. For example, you can set to collect logs containing "ErrorCode = 404".
Enable the upload of the log that failed to parse.
After this feature is enabled, all logs that failed to parse (as the “Key”), and the original log content (as the “Value”) are uploaded. When this feature is disabled, the logs that failed to parse will be discarded.



 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?