This document introduces the log-related features of TKE, including log collection, storage, and query, and provides suggestions based on actual application scenarios.
Note:
This document is only applicable to TKE clusters.
For more information on how to enable log collection for a TKE cluster and its basic usage, see Log Collection.
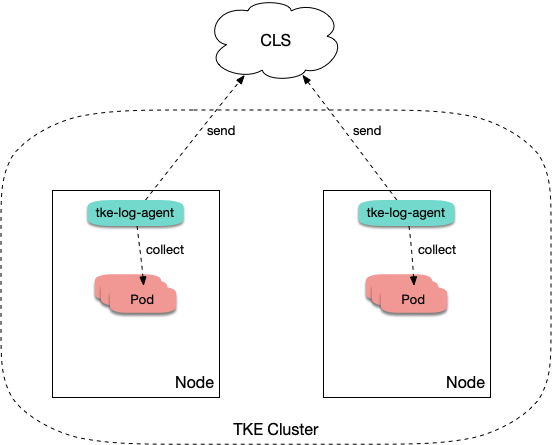
Architecture
After log collection is enabled for a TKE cluster, tke-log-agent is deployed on each node as a DaemonSet. According to the collection rules, tke-log-agent collects container logs from each node and reports them to CLS for storage, indexing and analysis. See the figure below:
Use Cases of Collection Types
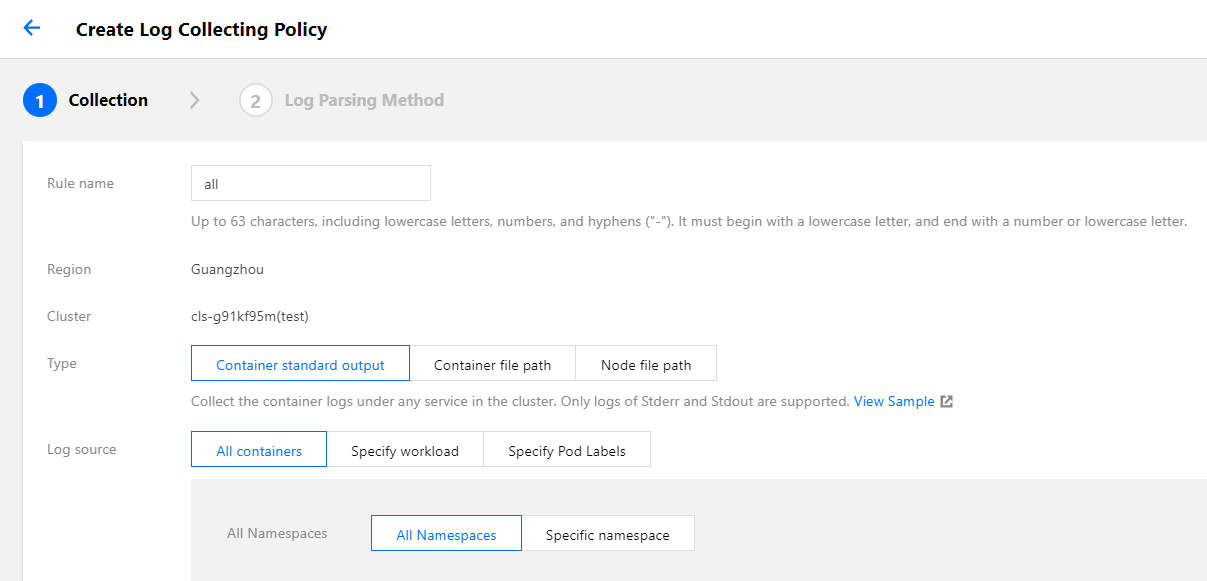
To use the TKE log collection feature, you need to determine the target data source for collection when creating log collection rules. TKE supports collection of standard output, files in a container and files on a host. See below for more details.
Collecting standard output
If you choose to collect from standard output, logs of containers in a pod are written to the standard output, and the log content will be managed by the container runtime (Docker or Containerd). We recommend using standard out as it is the simplest collection mode. Its advantages are as follows:
1. No extra volume mounting is needed.
2. You can view the log content by simply running kubectl logs.
3. No worries about log rotation. The container runtime will perform storage and automatic rotation of logs to prevent situations where the disk capacity is exhausted because some pods write excessive logs.
4. You don’t need to worry about the log file path. You can use unified collection rules to cover a wide range of workloads and reduce operation complexity.
Usually logs are written into log files. When containers are used, log files are written in containers. Please note:
If no volume is mounted in the log file path:
Log files will be written to the container writable layer and stored in the container data disk. Usually, the path is /var/lib/docker. We recommend that you mount a volume to this path, and the volume should not be used for the system disk. After the container stops, the logs will be cleared.
If a volume is mounted in the log file path:
Log files will be stored in the backend storage of the corresponding volume type. Usually, emptydir is used. After the container stops, the logs will be cleared. During runtime, log files will be stored in /var/lib/kubelet of the host. This path usually does not have a mounted disk, so it will use the system disk. As unified storage is available when using the log collection feature, you are not advised to mount other persistent storage to store log files (such as CBS, COS, or CFS).
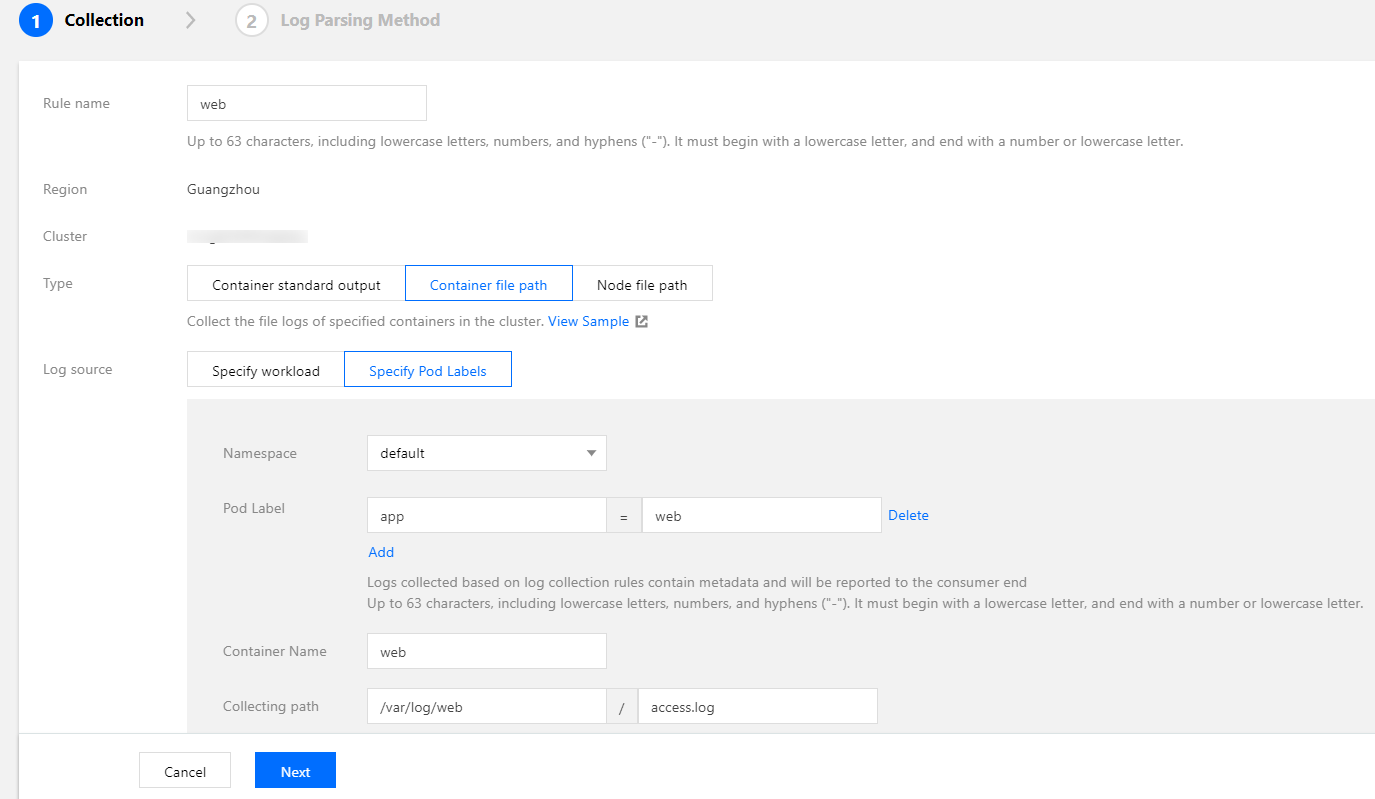
Most open-source log collectors require you to mount a volume to the pod log file path before collection, but TKE log collection does not require mounting. To output logs to files in containers, you do not need to consider whether to mount a volume. The following figure shows a sample collection configuration. For more information on configuration, see Collecting File Logs in a Container.
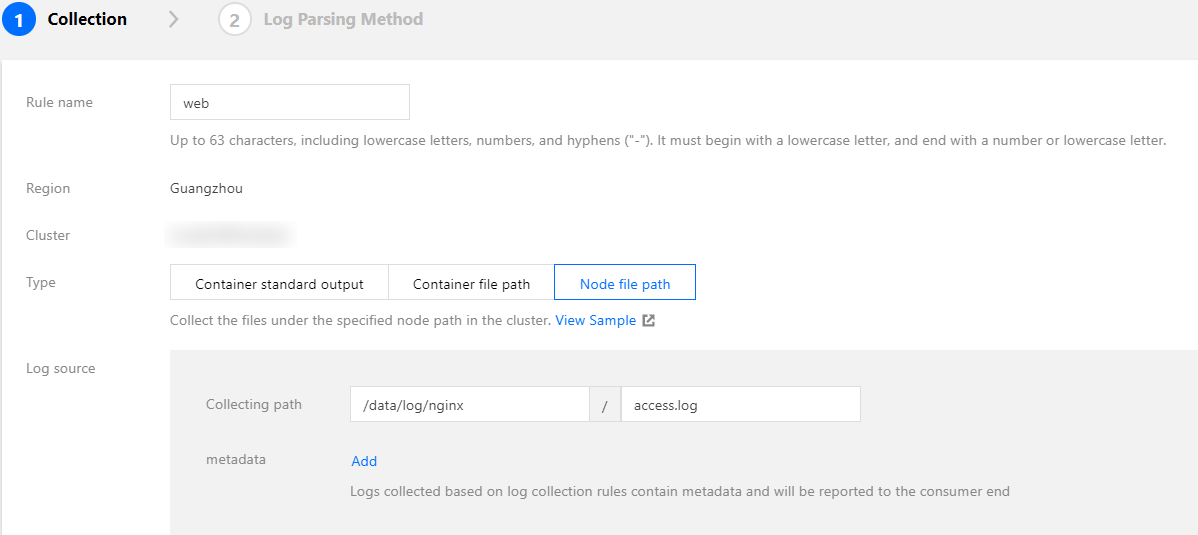
Collecting files on the host
If businesses need to write logs into log files and you hope to retain the original log files as a backup after the container stops to avoid complete log loss in the event of collection exceptions, you can mount a hostPath to the log file path. This way, log files will be stored in the specified directory on the host and these log files will not be cleared after the container stops.
As log files are not automatically cleared, the issue of repeated collection may occur if a pod is scheduled to another container and then scheduled back to the original container causing log files to be written into the same path. In that case, there are two collection scenarios:
Same file name:
For example, assume the fixed file path is /data/log/nginx/access.log. In this case, repeated collection will not occur, because the collector will remember the time point of previously collected log files and collect only increments.
Different file names:
Usually, the log frameworks used by businesses automatically perform log rotation periodically, generally on a daily basis, and automatically rename old log files and add the timestamp suffix. If the collection rules use*as the wildcard character to match log file names, repeated collection may occur. After the log framework renames log files, the collector will mistakenly think it has found new log files, so it will collect the files again.
Note:
Usually, repeated collection will not occur. If the log framework automatically performs rotation, we recommend that the wildcard character *not be used to match log files.
TKE log collection is integrated with CLS on the cloud, and log data is reported to CLS. CLS manages logs based on logsets and log topics. A logset is a project management unit of CLS and can include multiple log topics. Usually, the logs of the same business are put in the same logset, and applications or services of the same type in the same business use the same log topic.
In TKE, log collection rules have a one-to-one correspondence with log topics. When selecting the consumer during the creation of TKE log collection rules, you need to specify the logset and log topic. Logsets are usually created in advance, and you can choose to automatically create log topics. See the figure below:
After a log topic is automatically created, you can go to Logset Management, open the details page of the corresponding logset, and rename the log topic to make it easier to find in future searches.
Configuring Log Format Parsing
When creating a log collection rule, you need to configure the log parsing format to facilitate future searches. Please refer to the following sections to complete configuration based on the actual situation.
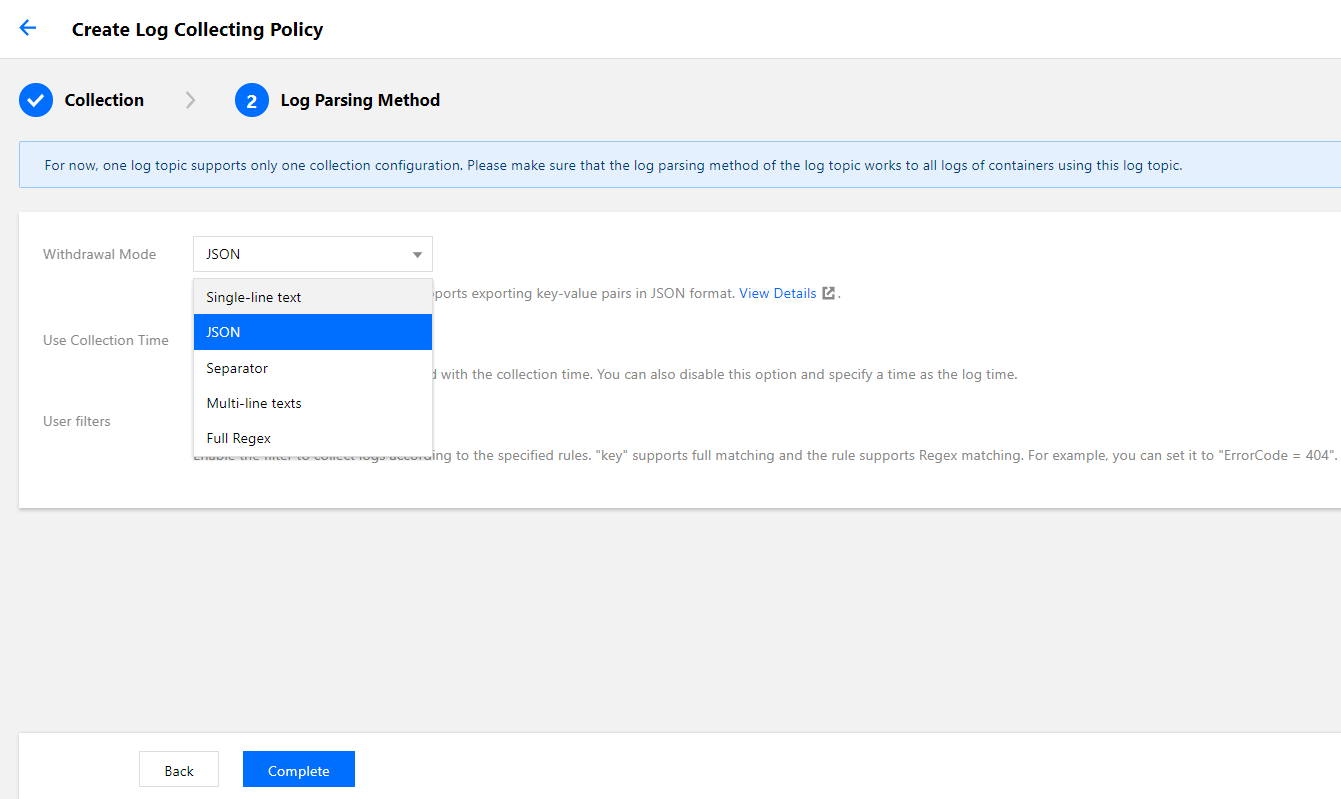
Selecting an extraction mode
TKE supports five extraction modes: single-line text, JSON, separator, multi-line text, and full RegEx, as shown in the figure below:
JSON mode
Single-line text and multi-line text modes
Separator and full RegEx modes
You can only select JSON mode when logs are output in JSON format, in which case this mode is recommended. In JSON format, the logs are already structured, allowing CLS to extract the JSON key as the field name and value as the corresponding key value. This means you do not have to configure complex matching rules based on the business log output format. A sample of such logs is as follows:
If the log does not have a fixed output format, you can consider using the single-line text or multi-line text extraction mode. In these two modes, the log content is not structured and log fields are not extracted. The timestamp of each log is determined by the log collection time, so only simple fuzzy searches are supported. The difference between these two modes is whether the log content is in a single line or multiple lines:
Single-line: each single line is an independent log, and no matching conditions need to be set.
Multi-line: you need to set the first-line regular expression, that is, the regular expression for matching the first line of each log. When a line of log content matches the preset regular expression, it is considered as the beginning of a log, and the next matching line will be the end mark of the log. Assume that the multi-line log content is as follows:
10.20.20.10 - - [Tue Jan 2214:24:03 CST 2019 +0800] GET /online/sample HTTP/1.1 127.0.0.1 20062835 http://127.0.0.1/group/1
Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0 0.3100.310
In this case, you can set the first-line regular expression as: \\d+\\.\\d+\\.\\d+\\.\\d+\\s-\\s.*, as shown in the figure below:
If the log content is a single-line text output in a fixed format, you can consider using the separator or full RegEx extraction mode:
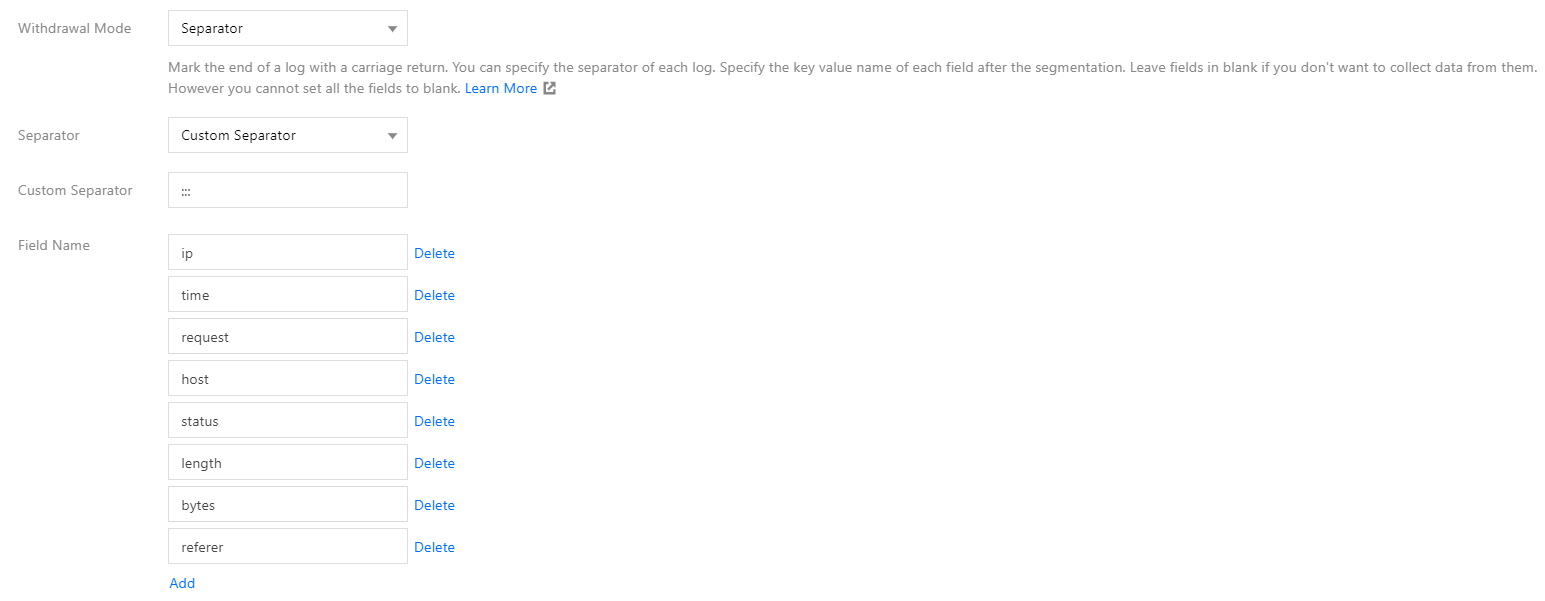
The separator mode is applicable to simple formats. In this mode, field values in the log are separated by a fixed string. For example, a log with ::: as the separator is as follows:
You can configure ::: as a custom separator and configure the field name for each field in sequence, as shown in the figure below:
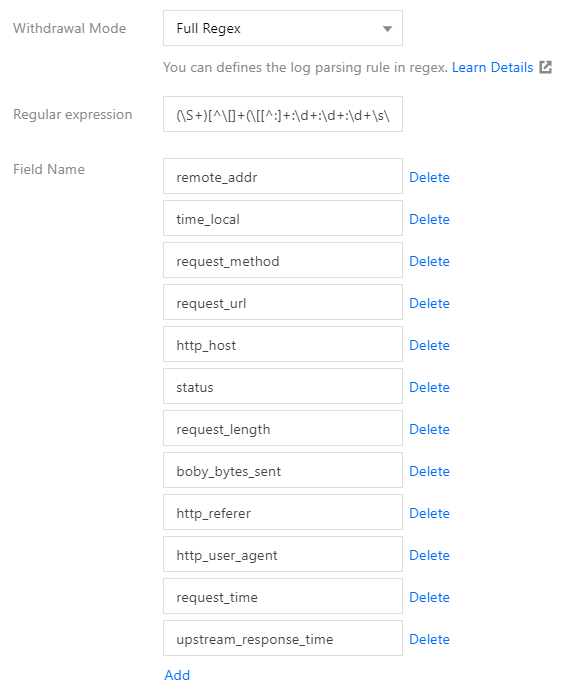
The full RegEx mode is applicable to complex formats. In this mode, a regular expression is used to match the log format. For example, assume a log is as follows:
CLS will use () as the capture group to distinguish each field from others. You need to set the field name for each field, as shown in the figure below:
Configuring the content to be filtered out
You can choose to filter out useless log information to lower costs.
If you use the JSON, separator, or full RegEx extraction mode, the log content is structured, and you can specify fields to perform regular expression matching for the log content to be retained, as shown in the figure below:
If you use the single-line text or multi-line text extraction mode, the log content is not structured, so you cannot specify fields for filtering. Usually, you can use regular expressions to perform fuzzy matching on the full log content to be retained, as shown in the figure below:
Note:
The content should be matched using a regular expression, instead of perfect match. For example, to retain only the domain name a.test.com in a log, the expression for matching should be a\\.test\\.com, instead of a.test.com.
Customizing log timestamps
Each log should contain a timestamp used mainly for searching. This allows users to select a time period during searches. By default, the log timestamp is determined by the collection time, but you can customize it by selecting a certain field as the timestamp. This can allow for more precise searches. For example, assume that a service has been running for some time before you create a collection rule. If you do not set a custom time format, the timestamps of old logs will be set to the current time during collection, resulting in inaccurate timestamps.
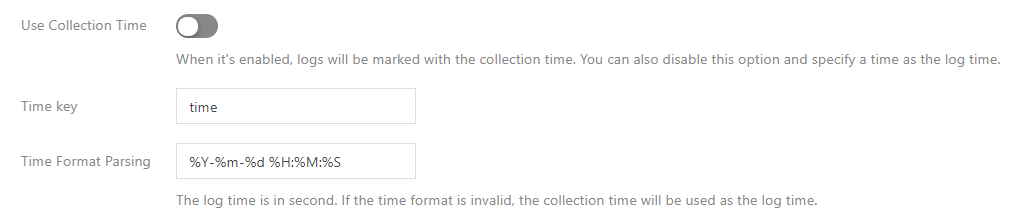
As the single-line text and multi-line text extraction modes do not structure log content, no field can be specified as the timestamp, which means these two modes do not support this feature. Other extraction modes support this feature. You need to disable "Use collection time", select a field name as the timestamp, and configure the time format. For example, assuming that the time field is used as the timestamp and the time value of a log is 2020-09-22 18:18:18, you can set the time format as: %Y-%m-%d %H:%M:%S, as shown in the figure below:
Note:
The CLS timestamps currently support precision to the second. If the timestamp field of a business log is precise to the millisecond, you cannot use custom timestamps and can only use the default timestamp determined by the collection time.
After log collection rules are configured, the collector will automatically start collecting logs and report them to CLS. You can query logs in Search Analysis on the CLS console. After an index is enabled, the Lucene syntax is supported. There are three types of indexes, as follows:
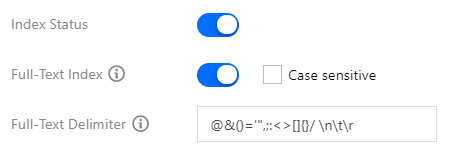
Full-text index: used for fuzzy search. You do not need to specify a field. See the figure below:
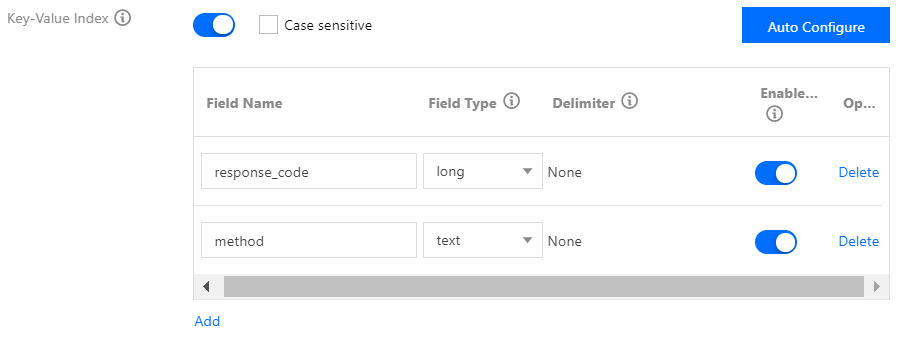
Key value index: index for structured log content. You can specify log fields to search. See the figure below:
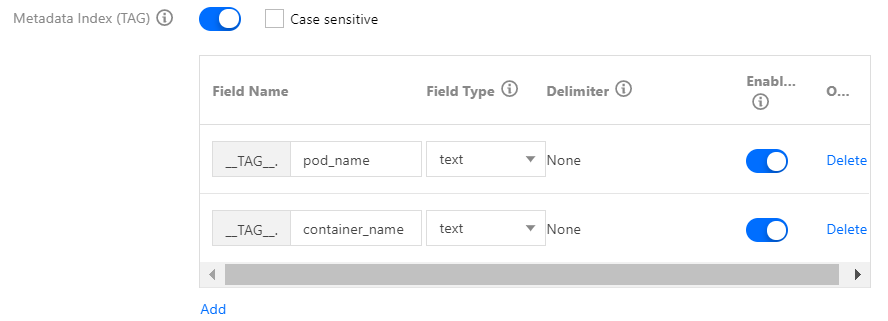
Metadata field index: when some extra fields, such as pod name and namespace, are automatically attached during log reporting, this index allows you to specify these fields during search. See the figure below:
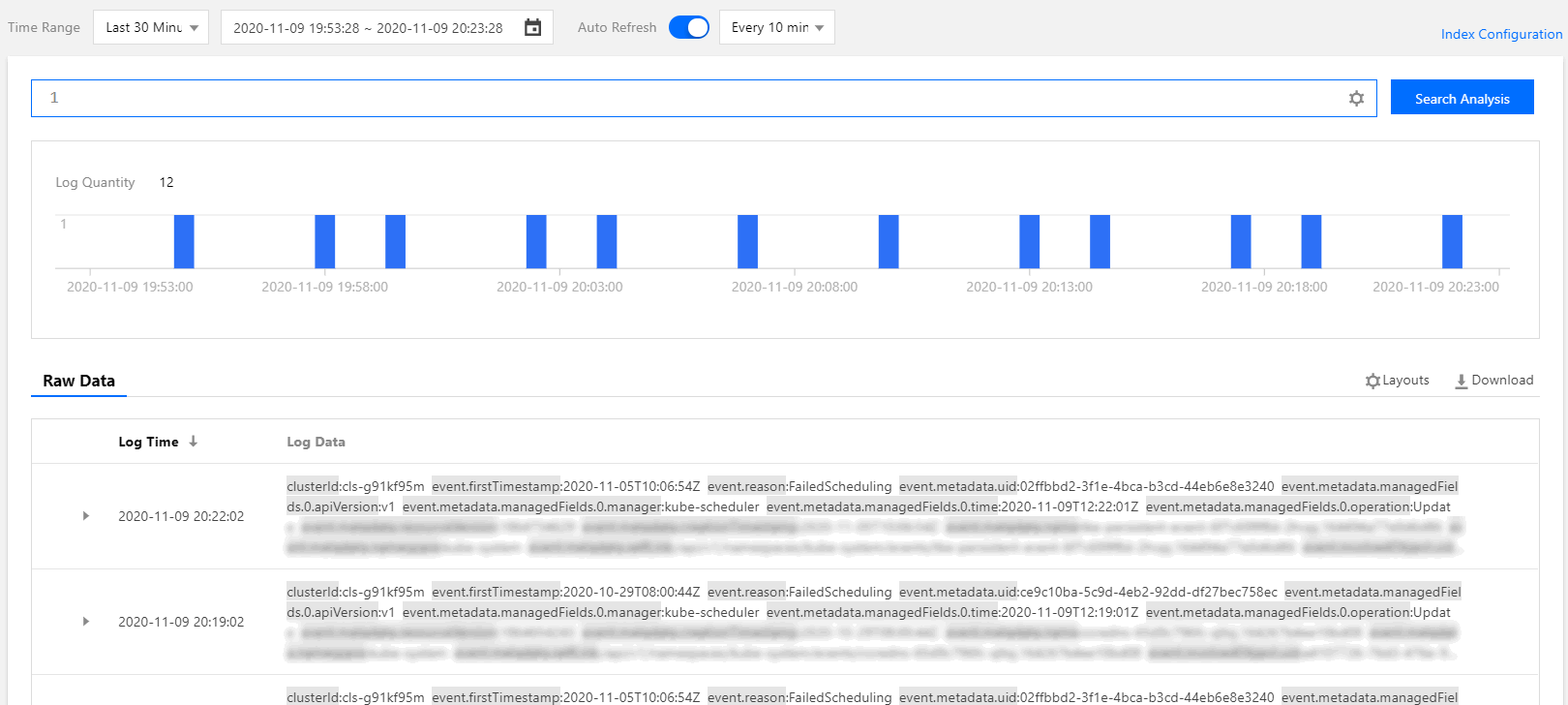
The following figure shows a query sample:
Publishing Logs to COS and Ckafka
CLS allows logs to be published to COS and the message queue CKafka. You can set it in the log topic, as shown in the figure below:
This is applicable to the following scenarios:
Scenarios where long-term archiving and storage of log data are required. The logset stores log data for seven days by default. You can adjust the duration. The larger the data volume, the higher the cost. Usually, data is stored for a few days. If you need to store logs for a longer period, you can publish log data to COS for low-cost storage.
Scenarios where further processing (such as offline calculation) of logs is required. You can publish log data to COS or Ckafka to be consumed and processed by other programs.





 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?