In order to shorten the linkage and improve the performance when the business in a cluster accesses a Service of the LoadBalancer type through Tencent Cloud CLB, the community edition of Kube-Proxy binds the CLB IP to the local dummy ENI in IPVS mode, so that the traffic short-circuits on the node instead of going through CLB and thus is directly forwarded to the endpoint locally. However, this optimization conflicts with the health check mechanism of CLB. The following makes a detailed analysis and describes corresponding solutions.
Similarly, when you use TKE, CLB loopback may occur, causing service inaccessibility or several seconds of latency during access to an Ingress. This document describes the symptoms, causes, and solutions of this problem.
Issue Description
CLB loopback may cause the following symptoms:
No matter whether you are in iptables or IPVS mode, when you access an Ingress on the cluster private network, a 4-second latency or inaccessibility occurs.
In IPVS mode, when you access a LoadBalancer service on the cluster private network within your cluster, it is completely inaccessible, or the connection is unstable.
Workaround
Avoiding layer-4 loopback
Note:
Avoiding the layer-4 loopback problem requires CLB to support non-VIP health check source IP. This feature is currently in beta test. To try it our, submit a ticket for assistance.
To solve the loopback problem that may be encountered when using the Service, follow the steps below:
1. Check whether kube-proxy is on the latest version, and if not, upgrade it as follows:
1.1 To solve this problem, kube-proxy needs to support binding the LB address to the IPVS ENI. You can find version numbers that support this capability in TKE Kubernetes Revision Version History, such as v1.20.6-tke.12, v1.18.4-tke.20, v1.16.3-tke.25, v1.14.3-tke.24, and v1.12.4-tke.30.
1.2 Determine the version of the cluster: you can view the version number of the current cluster on the Basic Information page in the cluster as shown below:
1.3 Find the DaemonSet named kube-proxy under the kube-system namespace, update the version number of its image, and select a version that supports this capability or a later version. For example, for a cluster on v1.18, you need to select an image version later than v1.18.4-tke.20.
2. Annotate all Services:
service.cloud.tencent.com/prevent-loopback: "true"
Effect:
kube-proxy will bind the CLB VIP to the local system based on this information to solve the loopback problem.
service-controller will call the CLB API and change its health detection IP to an IP in the 100.64 IP range to solve the health check problem.
Avoiding layer-7 loopback
To solve the loopback problem that may be encountered when using Ingress, follow the steps below:
1. Submit a ticket to apply for the CLB layer-7 SNAT and keepalive capabilities.
Note:
These capabilities will enable persistent connection. Then, persistent connections will be used between CLB and real server, and CLB will no longer pass through the source IP, which can be obtained from XFF. To ensure normal forwarding, enable the "Allow by default" feature in the CLB security group or allow 100.127.0.0/16 in the CVM security group. For more information, see Configuring HTTP Listener.
2. Use the capabilities of TkeServiceConfig to enhance the configuration capabilities of the Ingress. For existing Ingresses, you need to add an annotation: ingress.cloud.tencent.com/tke-service-config-auto: "true". For more information, see Ingress Annotation.
Purpose: this automatically generates the corresponding TkeServiceConfig for the Ingress and provides additional configuration for the Ingress.
Effect: the Ingress will generate a resource named <IngressName>-auto-ingress-config of the TkeServiceConfig type.
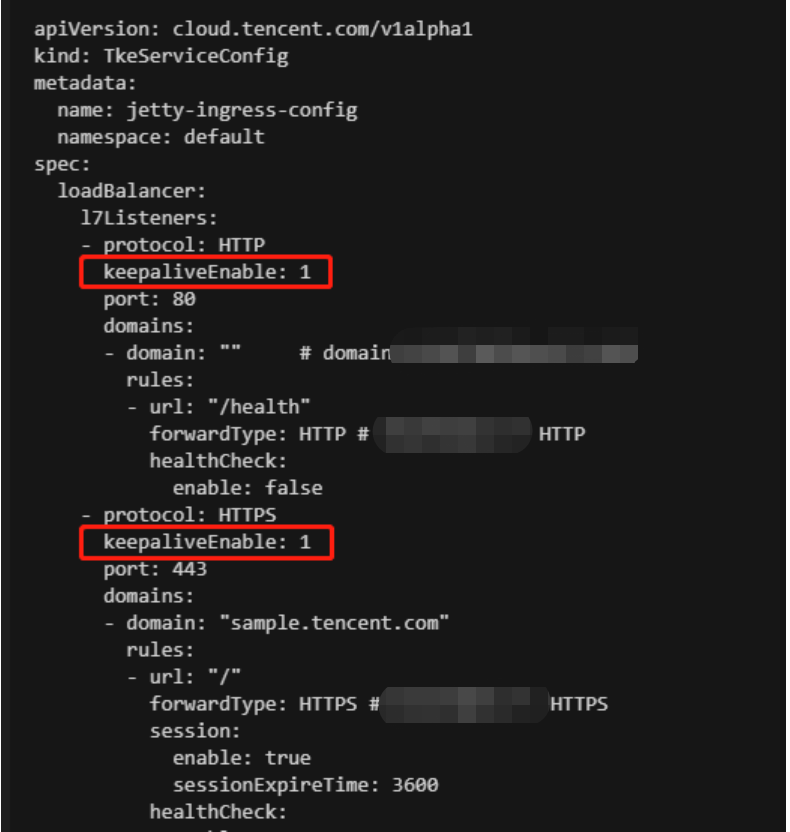
3. Add a field in the generated TkeServiceConfig named <IngressName>-auto-ingress-config. The field name is spec.loadBalancer.l7Listeners[].keepaliveEnable, and the field value is 1. Note that this field needs to be added for each port as shown below:
The root cause is that when CLB forwards a request to the real server, the packet source and target IPs are both on the same node, but Linux will ignore the received packets whose source IP is the local IP by default, causing the data packet to be looped within the CVM instance as shown below:
Analysis of layer-7 loopback problem
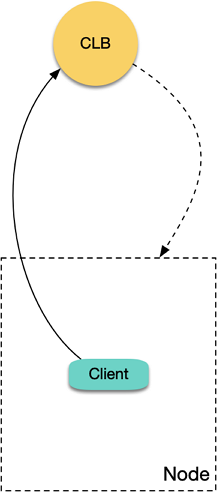
If you use a TKE CLB Ingress, a CLB instance and layer-7 listener rules (HTTP/HTTPS) for ports 80 and 443 will be created for each Ingress resource, and the same NodePort of each corresponding TKE node will be bound to each Ingress location as the real server (a location corresponds to a Service, and each Service uses the same NodePort of each node to expose the traffic). CLB forwards the request to the corresponding real server (i.e., NodePort) according to the location matched by the request, and the traffic will be forwarded to the corresponding backend Pod after passing the NodePort and the Kubernetes iptables or IPVS. When a Pod in the cluster accesses the private network Ingress in the cluster, CLB will forward the request to the corresponding NodePort of a node in the cluster.
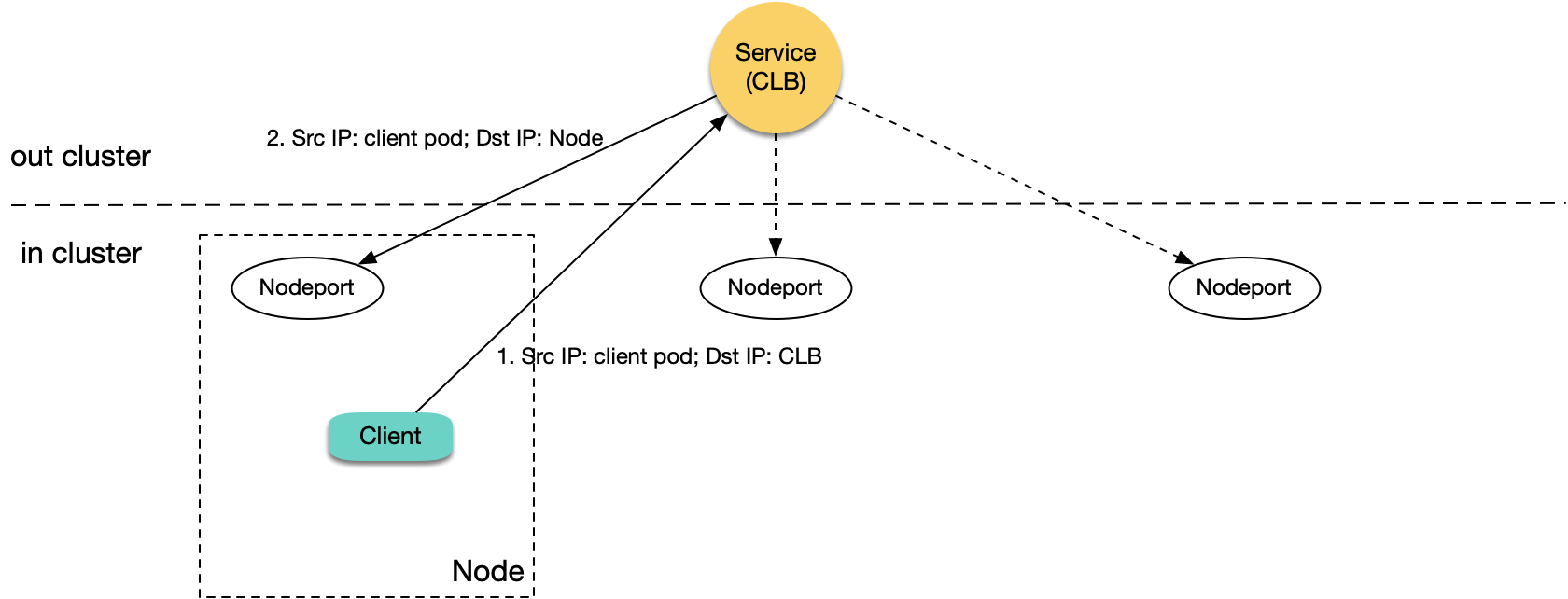
As shown above, when the node whose traffic is forwarded is the node of the client that sends the request:
1. A Pod in the cluster accesses CLB, and CLB forwards the request to the corresponding NodePort of any node.
2. When the packet reaches the NodePort, the target IP is the node IP, and the source IP is the actual IP of the client Pod. As CLB does not perform SNAT, it will pass through the actual source IP.
3. As the source and target IPs are both on the same server, loopback will occur, and CLB cannot receive response from the real server.
The most frequent fault of access to an Ingress in the cluster is a latency of several seconds. It is because if a layer-7 CLB instance's request to a real server times out (in about 4 seconds), the instance will try the next real server. Therefore, if you set a long timeout period on the client, loopback may occur with a symptom of slow request response with a several-second latency. If your cluster has only one node, CLB has no real server for retry, and the symptom will be inaccessibility.
Analysis of layer-4 loopback problem
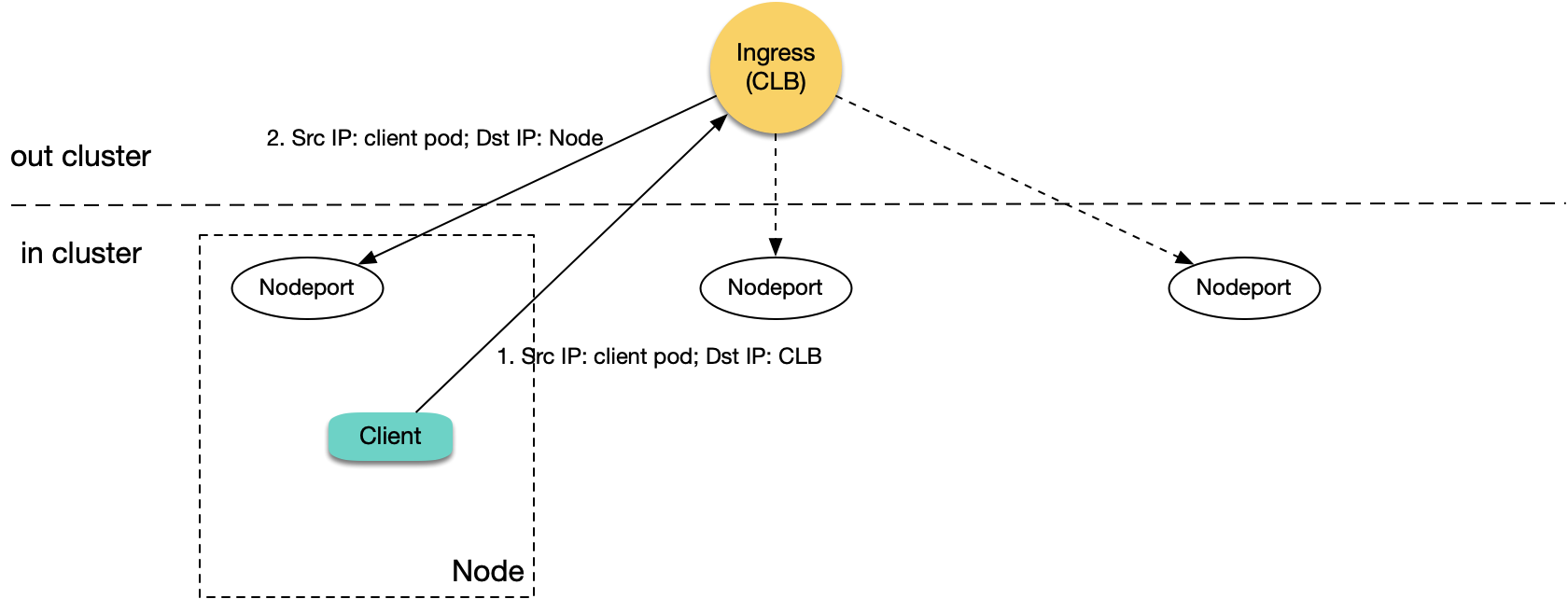
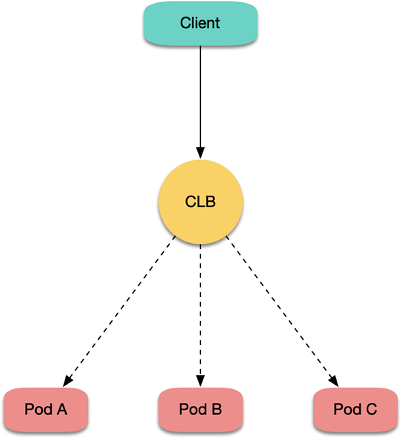
If you use a LoadBalancer-type private network Service to expose your service, a private network CLB instance and the corresponding layer-4 listener (TCP/UDP) will be created. If a Pod in your cluster accesses the EXTERNAL-IP (i.e., CLB IP) of the LoadBalancer-type Service, the native Kubernetes will not actually access the LB but will directly forward the traffic to the backend Pod through iptables or IPVS without passing CLB as shown below:
Therefore, the native Kubernetes logic has no loopback errors. However, in IPVS mode of TKE, the access request packet of a client to a CLB IP will be actually sent to CLB. Loopback will occur when a Pod accesses the CLB IP of a LoadBalancer-type Service in the same cluster in IPVS mode, which is similar to the aforementioned private network Ingress loopback error as shown below:
The differences lie in that when loopback occurs, the layer-4 CLB instance will not try the next real server, and the symptom is usually unstable connection. If the cluster has only one node, complete inaccessibility will be caused.
Why doesn't the IPVS mode of TKE use the similar forwarding logic of the native Kubernetes (i.e., the traffic is directly forwarded to the backend Pod without passing the LB)?
In the legacy TKE IPVS mode, the cluster uses a private network LoadBalancer Service to expose your service, and the health checks performed by the private network CLB on the backend NodePort will all fail. Below are the causes:
IPVS mainly runs on the INPUT chain, so the forwarded VIPs (Service cluster IP and EXTERNAL-IP) need to be used as the local server IP to make the packet enter the INPUT chain and get processed by IPVS.
kube-proxy binds both the cluster IP and EXTERNAL-IP to a dummy ENI named kube-ipvs0, which is only used to bind the VIPs (the kernel automatically generates the local route for it) instead of receiving traffic.
The source IP of the health check packets in private network CLB sent to the NodePort is the CLB VIP, and the target IP is the node IP. When a health check packet arrives at the node, the node will discover that the source IP is the local server IP (as it is bound to kube-ipvs0) and discard it. Therefore, CLB health check packets can never get the response, that is, all checks will fail. Although CLB has the all-dead-all-alive logic (failure of all checks are deemed as that all requests can be forwarded), this problem still equals that the check is of no use and will cause some exceptions in certain cases.
To solve the aforementioned problems, the solution of TKE is not to bind EXTERNAL-IP to kube-ipvs0 in IPVS mode; that is, packets of a cluster Pod's access requests to the CLB IP will not enter the INPUT chain; instead, they will be directly sent by the node ENI to CLB actually. In this way, the health check packets will not be discarded as packets with the local server IP when entering the node, and the health check response packets will not enter in the INPUT chain and then get looped within it.
Although this method fixes the problem of CLB health check failure, it also makes cluster Pods' access request packets to CLB actually arrive at CLB. As the service in the cluster is accessed, the packets will be forwarded back to a cluster node, which also may cause loopback.
Note:
The problem has been submitted to the community, but there is still no solution.
FAQs
Why public network CLB does not have loopback?
There is no loopback issue if you use a public network Ingress or public network LoadBalancer Service. This is because the source IP of the packets received by public network CLB is the public network egress IP of a CVM instance, but the CVM instance cannot sense its own public network IP internally. When a packet is forwarded to the CVM instance, the public network source IP will not be considered as the local server IP, so there will not be loopback.
Does CLB have any mechanism to avoid loopback?
Yes. CLB will determine the source IP and will not consider forwarding the request to the real server with the same IP; instead, it will forward the request to another real server. However, the source Pod IP is different from the real server IP, and CLB does not know whether the two IPs are on the same node, so the request may still be forwarded and cause loopback.
Can anti-affinity deployment of the client and server avoid loopback?
If you deploy a client and a server through anti-affinity so that they are not on the same node, can CLB loopback be avoided?
By default, LB is bound to a real server through a node NodePort, and a request may be forwarded to NodePort of any node. In this case, no matter whether the client and server are on the same node, loopback may occur. However, if externalTrafficPolicy: Local is set for the Service, LB will forward them to only the node with a Server Pod. If the client and server are scheduled to different nodes through anti-affinity, no loopback will occur. Therefore, anti-affinity and externalTrafficPolicy: Local can avoid the loopback issue (including private network Ingress and private network LoadBalancer Service).
Does the direct LB-Pod connection of VPC-CNI have the CLB loopback issue?
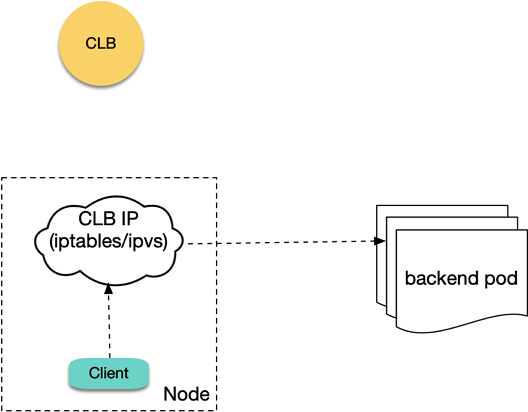
TKE generally uses the Global Router network mode, and another mode is VPC-CNI (elastic network interface). Currently, direct LB-Pod connection supports only the Pods of VPC-CNI; that is, LB is directly bound to the backend Pod rather than NodePort as the real server as shown below:
In this case, requests can bypass the NodePort instead of possibly being forwarded to any node like before. However, if the client and server are on the same node, loopback may still occur, which can be avoided through anti-affinity.
Are there any suggestions?
The anti-affinity and externalTrafficPolicy: Local methods are not very graceful. Generally, you should avoid accessing the CLB instance in the cluster for a service in the cluster, as the service is already in the cluster, and forwarding through CLB not only lengthens the network linkage but also may cause loopback.
When you access a service in the cluster, use the service name such as server.prod.svc.cluster.local as much as possible. In this way, requests will not pass CLB, and loopback will not be caused.
If your business has a coupled domain name and cannot use a Service name, you can use the rewrite plugin of coreDNS to point the domain name to a Service in the cluster. Below is the sample coreDNS configuration:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile:|2-
.:53 {
rewrite name roc.oa.com server.prod.svc.cluster.local
...
If multiple Services share the same domain name, you can deploy an Ingress Controller (such as nginx-ingress) by yourself:
1. Use the aforementioned rewrite method to point the domain name to the self-built Ingress Controller.
2. Match the self-built Ingress with a Service according to the request location (domain name + path) and forward the request to the backend Pod. The entire linkage will not pass CLB, so loopback can be avoided.


 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?