If your DeScheduler uses TPS as the data source and you don't change it, the DeScheduler will become invalid. To use TMP as the data source, you need to upgrade the DeScheduler before associating it with a TMP instance, as TMP adds API authentication capabilities.
If your DeScheduler uses the self-built Prometheus service, it will not be affected by the TPS deactivation, but you need to guarantee the stability and reliability of the self-built Prometheus service.
Overview
Add-on Description
DeScheduler is a plug-in provided by TKE based on the Kubernetes native community of DeScheduler to implement rescheduling based on actual node loads. After being installed in a TKE cluster, this plug-in will take effect in synergy with Kube-scheduler to monitor in real time high-load nodes in the cluster and drain low-priority pods. We recommend that you use it together with the TKE DynamicScheduler add-on to ensure cluster load balancing in multiple dimensions. This add-on relies on the Prometheus add-on and rule configuration. We recommend you read Deploying dependencies carefully before installing it; otherwise, it may not work properly.
Kubernetes objects deployed in a cluster
Kubernetes Object Name
Type
Requested Resource
Namespace
descheduler
Deployment
200 MB CPU and 200 MiB MEM for each instance; one instance in total
kube-system
descheduler
ClusterRole
-
kube-system
descheduler
ClusterRoleBinding
-
kube-system
descheduler
ServiceAccount
-
kube-system
descheduler-policy
ConfigMap
-
kube-system
probe-prometheus
ConfigMap
-
kube-system
Use Cases
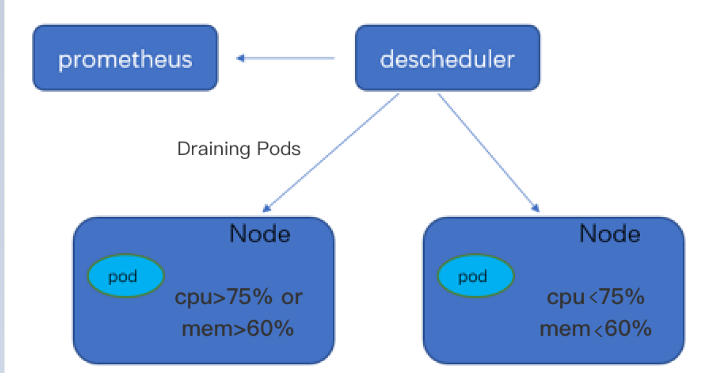
The DeScheduler addresses the unreasonable running of existing nodes in the cluster through rescheduling. The policy of the community Descheduler is implemented based on the data on the API server, but not actual node loads. Therefore, the policy can be adjusted to rescheduling based on actual loads by monitoring nodes.
TKE's ReduceHighLoadNode policy relies on Prometheus and Node Exporter monitoring data. Pods are drained and rescheduled based on node metrics such as CPU utilization, memory utilization, network I/O, and system loadavg, thereby avoiding extreme node loads. The ReduceHighLoadNode of the DeScheduler needs to be used together with the Dynamic Scheduler's policy based on actual node loads.
Notes
The Kubernetes is on v1.10.x or later.
In certain cases, some Pods will be scheduled repeatedly to nodes that require rescheduling, which causes Pods to be drained repeatedly. In this case, you can change the nodes to which Pods can be scheduled as needed, or mark the Pods as undrainable.
This add-on has been interconnected to TKE's monitoring and alarming system.
We recommend you enable event persistence for the cluster to better monitor the add-on for exceptions and locate the problems. When the Descheduler drains a Pod, an event will be generated. You can determine whether a Pod is drained repeatedly through the event with the reason of "Descheduled".
To prevent the DeScheduler from draining critical Pods, the algorithm is designed not to drain Pods by default. For a Pod that can be drained, its workload needs to be displayed and determined. For StatefulSet and Deployment objects, you can set annotations indicating that Pods can be drained.
Preconditions for Pod draining: To prevent drained Pods from running out of resources, the cluster should contain at least five nodes, and at least four of them should have a load below the target utilization.
Pod draining is a high-risk operation. Please perform Pod draining according to node affinity, taint-related configuration, and Pods' requirements for nodes to prevent situations where no node can be scheduled after Pod draining.
If a large number of Pods are drained, the service may become unavailable. Kubernetes provides native PDB objects to prevent a large number of Pods in a workload from becoming unavailable after the draining API is called, but the PDB configuration needs to be created. TKE's DeScheduler includes a guarantee measure to check whether the number of Pods prepared by a workload is greater than half of the number of the replicas; if not, the draining API will not be called.
How It Works
The DeScheduler is based on the rescheduling concept of the community Descheduler to scan for running Pods on each node that are not in line with the policy and drain them for rescheduling. The community Descheduler provides some of the policies based on the data on the API server, for example, the LowNodeUtilization policy that relies on the request and limit values of the Pod. The data can effectively balance the cluster resource allocation and avoid resource fragmentation. However, the community policy lacks the support for the occupation of actual node resources. Specifically, if the same number of resources are allocated from node A and node B, their peak loads will differ significantly due to differences in CPU and memory usage during actual Pod running.
Therefore, TKE has released the DeScheduler, which monitors the actual node loads at the underlying layer for rescheduling. With node load statistics of the cluster from Prometheus and the configured load threshold, it regularly executes the check rules in the policy and drains Pods from high-load nodes.
Add-on Parameter Description
Prometheus data query address
Notes
To ensure that the required monitoring data can be pulled by the add-on and the scheduling policy can take effect, follow the "Configuring the Prometheus file" step in Deploying dependencies to configure the monitoring data collection rules.
If you use the self-built Prometheus service, just enter the data query URL (HTTP/HTTPS).
If you use the managed Prometheus service, just select the managed instance ID, and the system will automatically parse the data query URL of the instance.
Utilization threshold and target utilization
Notes
A default value has been set for the load threshold parameter. If you have no special requirements, you can directly use it.
If the average CPU or memory utilization of the node in the past five minutes exceeds the configured threshold, the Descheduler will identify the node as a high-load node, execute the logic to drain and reschedule Pods to reduce the load below the target utilization.
Directions
Dependency deployment
The DeScheduler add-on relies on the actual node loads in the current and past periods of time to make scheduling decisions. It needs to get the information of the actual node loads of the system through the Prometheus add-on. Before using the DeScheduler add-on, you can use the self-built Prometheus monitoring service or the TKE cloud native monitoring service.
Self-built Prometheus
TMP
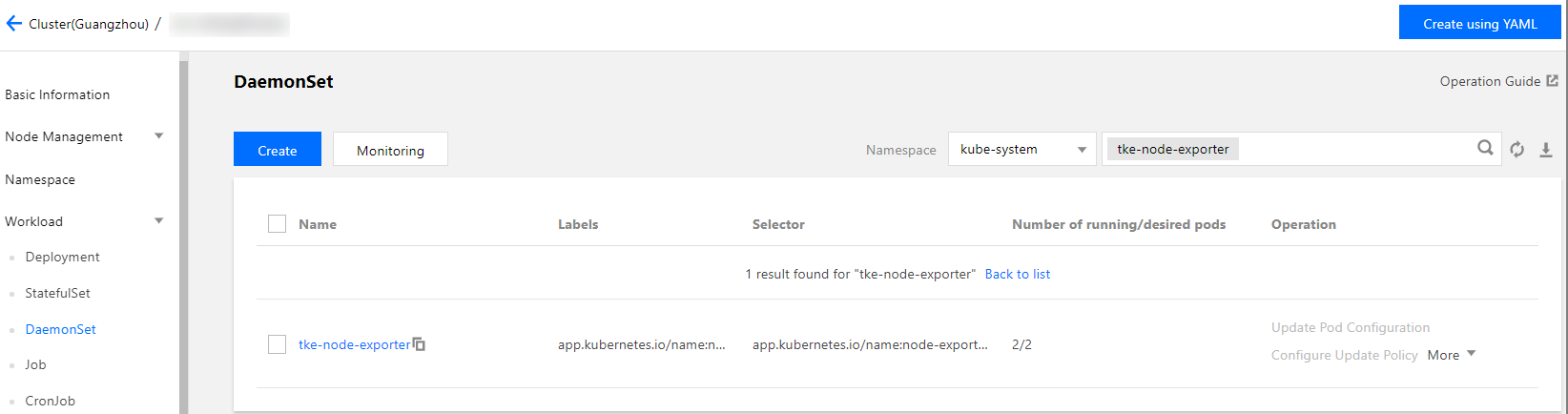
Deploying the Node Exporter and Prometheus
You can deploy the Node Exporter and Prometheus as needed to monitor node metrics through the Node Exporter.
Aggregation rule configuration
After getting the node monitoring data from the Node Exporter, you need to aggregate and calculate the data collected in the native Node Exporter through Prometheus. To get metrics such as cpu_usage_avg_5m and mem_usage_avg_5m required by the DeScheduler, you need to configure rules in Prometheus. Below is a sample:
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
- name: mem-usage-1m
interval: 1m
rules:
- record: mem_usage_avg_5m
expr: avg_over_time(mem_usage_active[5m])
Notes
When using TKE's DynamicScheduler, you need to configure the aggregation rules in Prometheus to get node monitoring data. As some of the DynamicScheduler's aggregation rules are identical to those of the DeScheduler, do not overlap rules during configuration. In addition, you should configure the following rules to use the Dynamic Scheduler together with the DeScheduler:
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
-name: cpu-usage-5m
interval: 5m
rules:
-record: cpu_usage_max_avg_1h
expr: max_over_time(cpu_usage_avg_5m[1h])
-record: cpu_usage_max_avg_1d
expr: max_over_time(cpu_usage_avg_5m[1d])
Configuring the Prometheus file
1. The above section defines the rules to calculate the metrics required by the DeScheduler. You need to configure the rules to Prometheus as a general Prometheus configuration file. Below is a sample:
global:
evaluation_interval: 30s
scrape_interval: 30s
external_labels:
rule_files:
- /etc/prometheus/rules/*.yml# `/etc/prometheus/rules/*.yml` is the defined `rules` file.
2. Copy the rules configurations to a file (such as de-scheduler.yaml) and put the file under /etc/prometheus/rules/ of the above Prometheus container.
3. Reload the Prometheus server to get the metrics required by the Dynamic Scheduler from Prometheus.
Note
In general, the above Prometheus configuration file and rules configuration file are stored via a ConfigMap before being mounted to a Prometheus server's container. Therefore, you only need to modify the ConfigMap.
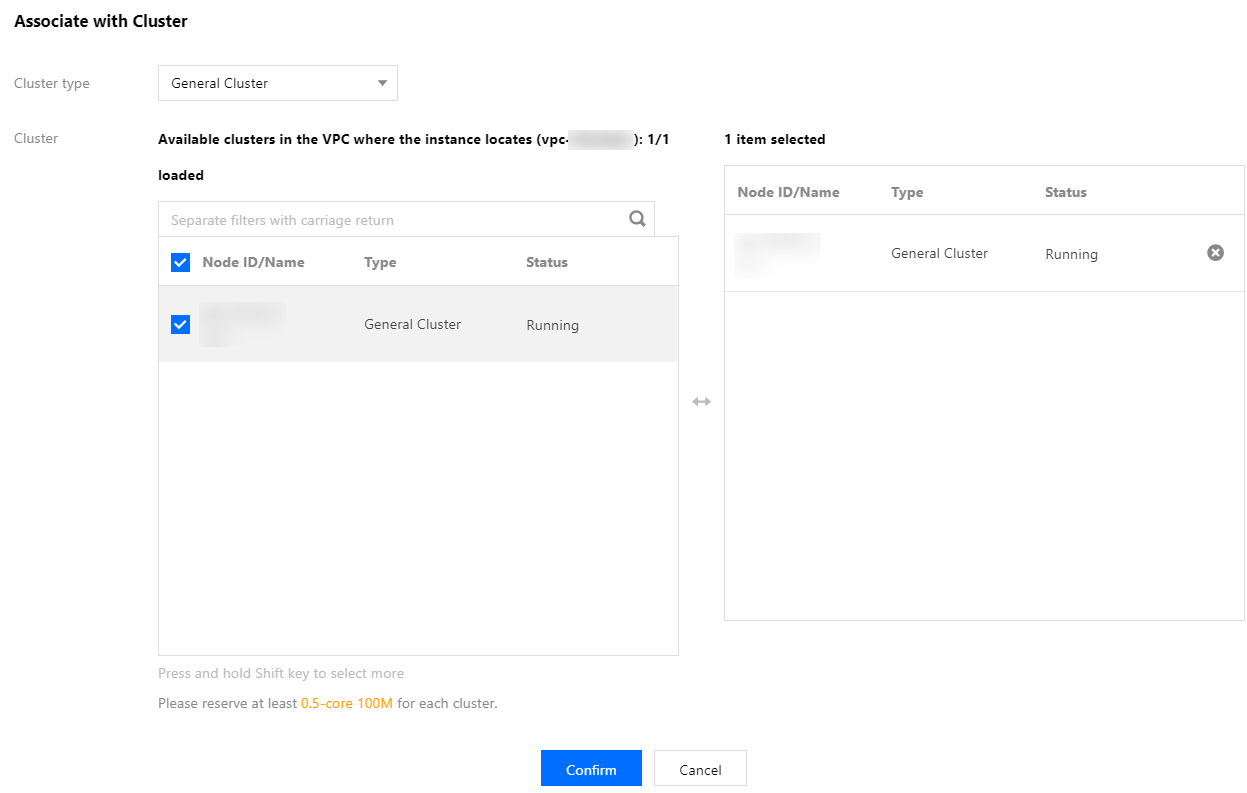
3. After associating with the native managed cluster, you can see that the Node Exporter has been installed on each node of the cluster.
4. Set the Prometheus aggregation rules. The content is the same as that configured in Self-built Prometheus monitoring service. The rules take effect immediately after being saved without server reloading.
Installing the add-on
1. Log in to the TKE console and select Cluster in the left sidebar.
2. On the Cluster management page, click the ID of the target cluster to go to the cluster details page.
3. In the left sidebar, click Add-On Management. On the Add-On List page, click Create.
4. On the Create Add-on page, select DynamicScheduler (dynamic scheduler). Click Parameter Configurations and enter the parameters required by the add-on as instructed in Add-On Parameter Description.
5. Click Done. After the add-on is installed successfully, the DeScheduler can run normally without extra configurations.
6. To drain a workload (such as StatefulSet and Deployment objects), set the following annotation:

 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?