- Release Notes and Announcements
- Release Notes
- Announcements
- Security Vulnerability Fix Description
- TKE Native Node Sub-product Name Change Notice
- Announcement on Authentication Upgrade of Some TKE APIs
- Discontinuing Update of NginxIngress Addon
- qGPU Service Adjustment
- Version Upgrade of Master Add-On of TKE Managed Cluster
- Upgrading tke-monitor-agent
- Instructions on Cluster Resource Quota Adjustment
- Decommissioning Kubernetes Version
- Deactivation of Scaling Group Feature
- Notice on TPS Discontinuation on May 16, 2022 at 10:00 (UTC +8)
- Basic Monitoring Architecture Upgrade
- Starting Charging on Managed Clusters
- Instructions on Stopping Delivering the Kubeconfig File to Nodes
- Release Notes
- Product Introduction
- Purchase Guide
- Quick Start
- TKE General Cluster Guide
- TKE General Cluster Overview
- Purchase a TKE General Cluster
- High-risk Operations of Container Service
- Deploying Containerized Applications in the Cloud
- Open Source Components
- Permission Management
- Cluster Management
- Cluster Overview
- Cluster Hosting Modes Introduction
- Cluster Lifecycle
- Creating a Cluster
- Changing the Cluster Operating System
- Deleting a Cluster
- Cluster Scaling
- Connecting to a Cluster
- Upgrading a Cluster
- Enabling IPVS for a Cluster
- Custom Kubernetes Component Launch Parameters
- Using KMS for Kubernetes Data Source Encryption
- Images
- Worker node introduction
- Normal Node Management
- Native Node Management
- Overview
- Native Node Parameters
- Purchasing Native Nodes
- Lifecycle of a Native Node
- Creating Native Nodes
- Modifying Native Nodes
- Deleting Native Nodes
- Self-Heal Rules
- Declarative Operation Practice
- Native Node Scaling
- In-place Pod Configuration Adjustment
- Enabling Public Network Access for a Native Node
- Management Parameters
- Enabling SSH Key Login for a Native Node
- FAQs for Native Nodes
- Supernode management
- Registered Node Management
- Memory Compression Instructions
- GPU Share
- Kubernetes Object Management
- Overview
- Namespace
- Workload
- Deployment Management
- StatefulSet Management
- DaemonSet Management
- CronJob Management
- Job Management
- Setting the Resource Limit of Workload
- Setting the Scheduling Rule for a Workload
- Setting the Health Check for a Workload
- Setting the Run Command and Parameter for a Workload
- Using a Container Image in a TCR Enterprise Instance to Create a Workload
- Auto Scaling
- Configuration
- Service Management
- Ingress Management
- Storage Management
- Policy Management
- Application and Add-On Feature Management Description
- Add-On Management
- Add-on Overview
- Add-On Lifecycle Management
- Cluster Autoscaler
- OOMGuard
- NodeProblemDetectorPlus Add-on
- NodeLocalDNSCache
- DNSAutoscaler
- COS-CSI
- CFS-CSI
- CFSTURBO-CSI
- CBS-CSI Description
- UserGroupAccessControl
- TCR Introduction
- TCR Hosts Updater
- DynamicScheduler
- DeScheduler
- Network Policy
- Nginx-ingress
- HPC
- Description of tke-monitor-agent
- tke-log-agent
- GPU-Manager Add-on
- Helm Application
- Application Market
- Network Management
- Container Network Overview
- GlobalRouter Mode
- VPC-CNI Mode
- VPC-CNI Mode
- Multiple Pods with Shared ENI Mode
- Pods with Exclusive ENI Mode
- Static IP Address Mode Instructions
- Non-static IP Address Mode Instructions
- Interconnection Between VPC-CNI and Other Cloud Resources/IDC Resources
- Security Group of VPC-CNI Mode
- Instructions on Binding an EIP to a Pod
- VPC-CNI Component Description
- Limits on the Number of Pods in VPC-CNI Mode
- Cilium-Overlay Mode
- OPS Center
- Log Management
- Backup Center
- Remote Terminals
- TKE Serverless Cluster Guide
- TKE Registered Cluster Guide
- TKE Insight
- TKE Scheduling
- Cloud Native Service Guide
- Practical Tutorial
- Cluster
- Cluster Migration
- Serverless Cluster
- Security
- Service Deployment
- Network
- DNS
- Self-Built Nginx Ingress Practice Tutorial
- Quick Start
- Custom Load Balancer
- Enabling CLB Direct Connection
- Optimization for High Concurrency Scenarios
- High Availability Configuration Optimization
- Observability Integration
- Access to Tencent Cloud WAF
- Installing Multiple Nginx Ingress Controllers
- Migrating from TKE Nginx Ingress Plugin to Self-Built Nginx Ingress
- Complete Example of values.yaml Configuration
- Using Network Policy for Network Access Control
- Deploying NGINX Ingress on TKE
- Nginx Ingress High-Concurrency Practices
- Nginx Ingress Best Practices
- Limiting the bandwidth on pods in TKE
- Directly connecting TKE to the CLB of pods based on the ENI
- Use CLB-Pod Direct Connection on TKE
- Obtaining the Real Client Source IP in TKE
- Using Traefik Ingress in TKE
- Release
- Logs
- Monitoring
- OPS
- Removing and Re-adding Nodes from and to Cluster
- Using Ansible to Batch Operate TKE Nodes
- Using Cluster Audit for Troubleshooting
- Renewing a TKE Ingress Certificate
- Using cert-manager to Issue Free Certificates
- Using cert-manager to Issue Free Certificate for DNSPod Domain Name
- Using the TKE NPDPlus Plug-In to Enhance the Self-Healing Capability of Nodes
- Using kubecm to Manage Multiple Clusters kubeconfig
- Quick Troubleshooting Using TKE Audit and Event Services
- Customizing RBAC Authorization in TKE
- Clearing De-registered Tencent Cloud Account Resources
- Terraform
- DevOps
- Auto Scaling
- Cluster Auto Scaling Practices
- Using tke-autoscaling-placeholder to Implement Auto Scaling in Seconds
- Installing metrics-server on TKE
- Using Custom Metrics for Auto Scaling in TKE
- Utilizing HPA to Auto Scale Businesses on TKE
- Using VPA to Realize Pod Scaling up and Scaling down in TKE
- Adjusting HPA Scaling Sensitivity Based on Different Business Scenarios
- Implementing elasticity based on traffic prediction with EHPA
- Implementing Horizontal Scaling based on CLB monitoring metrics using KEDA in TKE
- Containerization
- Microservice
- Cost Management
- Hybrid Cloud
- Fault Handling
- Disk Full
- High Workload
- Memory Fragmentation
- Cluster DNS Troubleshooting
- Cluster kube-proxy Troubleshooting
- Cluster API Server Inaccessibility Troubleshooting
- Service and Ingress Inaccessibility Troubleshooting
- Common Service & Ingress Errors and Solutions
- Engel Ingres appears in Connechtin Reverside
- CLB Ingress Creation Error
- Troubleshooting for Pod Network Inaccessibility
- Pod Status Exception and Handling
- Authorizing Tencent Cloud OPS Team for Troubleshooting
- CLB Loopback
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- FAQs
- Service Agreement
- Contact Us
- Glossary
- User Guide(Old)
- Release Notes and Announcements
- Release Notes
- Announcements
- Security Vulnerability Fix Description
- TKE Native Node Sub-product Name Change Notice
- Announcement on Authentication Upgrade of Some TKE APIs
- Discontinuing Update of NginxIngress Addon
- qGPU Service Adjustment
- Version Upgrade of Master Add-On of TKE Managed Cluster
- Upgrading tke-monitor-agent
- Instructions on Cluster Resource Quota Adjustment
- Decommissioning Kubernetes Version
- Deactivation of Scaling Group Feature
- Notice on TPS Discontinuation on May 16, 2022 at 10:00 (UTC +8)
- Basic Monitoring Architecture Upgrade
- Starting Charging on Managed Clusters
- Instructions on Stopping Delivering the Kubeconfig File to Nodes
- Release Notes
- Product Introduction
- Purchase Guide
- Quick Start
- TKE General Cluster Guide
- TKE General Cluster Overview
- Purchase a TKE General Cluster
- High-risk Operations of Container Service
- Deploying Containerized Applications in the Cloud
- Open Source Components
- Permission Management
- Cluster Management
- Cluster Overview
- Cluster Hosting Modes Introduction
- Cluster Lifecycle
- Creating a Cluster
- Changing the Cluster Operating System
- Deleting a Cluster
- Cluster Scaling
- Connecting to a Cluster
- Upgrading a Cluster
- Enabling IPVS for a Cluster
- Custom Kubernetes Component Launch Parameters
- Using KMS for Kubernetes Data Source Encryption
- Images
- Worker node introduction
- Normal Node Management
- Native Node Management
- Overview
- Native Node Parameters
- Purchasing Native Nodes
- Lifecycle of a Native Node
- Creating Native Nodes
- Modifying Native Nodes
- Deleting Native Nodes
- Self-Heal Rules
- Declarative Operation Practice
- Native Node Scaling
- In-place Pod Configuration Adjustment
- Enabling Public Network Access for a Native Node
- Management Parameters
- Enabling SSH Key Login for a Native Node
- FAQs for Native Nodes
- Supernode management
- Registered Node Management
- Memory Compression Instructions
- GPU Share
- Kubernetes Object Management
- Overview
- Namespace
- Workload
- Deployment Management
- StatefulSet Management
- DaemonSet Management
- CronJob Management
- Job Management
- Setting the Resource Limit of Workload
- Setting the Scheduling Rule for a Workload
- Setting the Health Check for a Workload
- Setting the Run Command and Parameter for a Workload
- Using a Container Image in a TCR Enterprise Instance to Create a Workload
- Auto Scaling
- Configuration
- Service Management
- Ingress Management
- Storage Management
- Policy Management
- Application and Add-On Feature Management Description
- Add-On Management
- Add-on Overview
- Add-On Lifecycle Management
- Cluster Autoscaler
- OOMGuard
- NodeProblemDetectorPlus Add-on
- NodeLocalDNSCache
- DNSAutoscaler
- COS-CSI
- CFS-CSI
- CFSTURBO-CSI
- CBS-CSI Description
- UserGroupAccessControl
- TCR Introduction
- TCR Hosts Updater
- DynamicScheduler
- DeScheduler
- Network Policy
- Nginx-ingress
- HPC
- Description of tke-monitor-agent
- tke-log-agent
- GPU-Manager Add-on
- Helm Application
- Application Market
- Network Management
- Container Network Overview
- GlobalRouter Mode
- VPC-CNI Mode
- VPC-CNI Mode
- Multiple Pods with Shared ENI Mode
- Pods with Exclusive ENI Mode
- Static IP Address Mode Instructions
- Non-static IP Address Mode Instructions
- Interconnection Between VPC-CNI and Other Cloud Resources/IDC Resources
- Security Group of VPC-CNI Mode
- Instructions on Binding an EIP to a Pod
- VPC-CNI Component Description
- Limits on the Number of Pods in VPC-CNI Mode
- Cilium-Overlay Mode
- OPS Center
- Log Management
- Backup Center
- Remote Terminals
- TKE Serverless Cluster Guide
- TKE Registered Cluster Guide
- TKE Insight
- TKE Scheduling
- Cloud Native Service Guide
- Practical Tutorial
- Cluster
- Cluster Migration
- Serverless Cluster
- Security
- Service Deployment
- Network
- DNS
- Self-Built Nginx Ingress Practice Tutorial
- Quick Start
- Custom Load Balancer
- Enabling CLB Direct Connection
- Optimization for High Concurrency Scenarios
- High Availability Configuration Optimization
- Observability Integration
- Access to Tencent Cloud WAF
- Installing Multiple Nginx Ingress Controllers
- Migrating from TKE Nginx Ingress Plugin to Self-Built Nginx Ingress
- Complete Example of values.yaml Configuration
- Using Network Policy for Network Access Control
- Deploying NGINX Ingress on TKE
- Nginx Ingress High-Concurrency Practices
- Nginx Ingress Best Practices
- Limiting the bandwidth on pods in TKE
- Directly connecting TKE to the CLB of pods based on the ENI
- Use CLB-Pod Direct Connection on TKE
- Obtaining the Real Client Source IP in TKE
- Using Traefik Ingress in TKE
- Release
- Logs
- Monitoring
- OPS
- Removing and Re-adding Nodes from and to Cluster
- Using Ansible to Batch Operate TKE Nodes
- Using Cluster Audit for Troubleshooting
- Renewing a TKE Ingress Certificate
- Using cert-manager to Issue Free Certificates
- Using cert-manager to Issue Free Certificate for DNSPod Domain Name
- Using the TKE NPDPlus Plug-In to Enhance the Self-Healing Capability of Nodes
- Using kubecm to Manage Multiple Clusters kubeconfig
- Quick Troubleshooting Using TKE Audit and Event Services
- Customizing RBAC Authorization in TKE
- Clearing De-registered Tencent Cloud Account Resources
- Terraform
- DevOps
- Auto Scaling
- Cluster Auto Scaling Practices
- Using tke-autoscaling-placeholder to Implement Auto Scaling in Seconds
- Installing metrics-server on TKE
- Using Custom Metrics for Auto Scaling in TKE
- Utilizing HPA to Auto Scale Businesses on TKE
- Using VPA to Realize Pod Scaling up and Scaling down in TKE
- Adjusting HPA Scaling Sensitivity Based on Different Business Scenarios
- Implementing elasticity based on traffic prediction with EHPA
- Implementing Horizontal Scaling based on CLB monitoring metrics using KEDA in TKE
- Containerization
- Microservice
- Cost Management
- Hybrid Cloud
- Fault Handling
- Disk Full
- High Workload
- Memory Fragmentation
- Cluster DNS Troubleshooting
- Cluster kube-proxy Troubleshooting
- Cluster API Server Inaccessibility Troubleshooting
- Service and Ingress Inaccessibility Troubleshooting
- Common Service & Ingress Errors and Solutions
- Engel Ingres appears in Connechtin Reverside
- CLB Ingress Creation Error
- Troubleshooting for Pod Network Inaccessibility
- Pod Status Exception and Handling
- Authorizing Tencent Cloud OPS Team for Troubleshooting
- CLB Loopback
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateBackupStorageLocation
- CreateCluster
- DeleteBackupStorageLocation
- DescribeBackupStorageLocations
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- UpdateClusterKubeconfig
- UpdateClusterVersion
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- CheckEdgeClusterCIDR
- DescribeAvailableTKEEdgeVersion
- DescribeECMInstances
- DescribeEdgeCVMInstances
- DescribeEdgeClusterInstances
- DescribeEdgeClusterUpgradeInfo
- DescribeTKEEdgeClusterStatus
- ForwardTKEEdgeApplicationRequestV3
- DescribeEdgeLogSwitches
- CreateECMInstances
- CreateEdgeCVMInstances
- CreateEdgeLogConfig
- DeleteECMInstances
- DeleteEdgeCVMInstances
- DeleteEdgeClusterInstances
- DeleteTKEEdgeCluster
- DescribeTKEEdgeClusterCredential
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeScript
- InstallEdgeLogAgent
- UninstallEdgeLogAgent
- UpdateEdgeClusterVersion
- DescribeTKEEdgeClusters
- CreateTKEEdgeCluster
- Cloud Native Monitoring APIs
- Scaling group APIs
- Super Node APIs
- Add-on APIs
- Other APIs
- Data Types
- Error Codes
- TKE API 2022-05-01
- FAQs
- Service Agreement
- Contact Us
- Glossary
- User Guide(Old)
Feature Overview
Generally, qGPU Pods fairly use physical GPU resources, and a qGPU kernel driver allocates equivalent GPU time slices to each task. As different GPU computing tasks have different running characteristics and importance levels, they have different requirements for GPU resources and use the resources differently. For example, real-time inference is sensitive to GPU resources and latency. It needs to get GPU resources as quickly as possible for computing, but the utilization is usually low. Model training requires a large amount of GPU resources but is insensitive to latency, which means it can endure a certain period of suppression.
Again this backdrop, Tencent Cloud has launched qGPU online/offline hybrid deployment, an innovative technology for deploying and scheduling online and offline GPU resources. Specifically, both online (high-priority) and offline (low-priority) tasks are deployed on the same GPU card, guaranteeing 100% utilization of the idle computing power by low-priority tasks and absolute preemption by high-priority tasks at the kernel and driver levels. This technology achieves 100% GPU utilization and minimizes costs.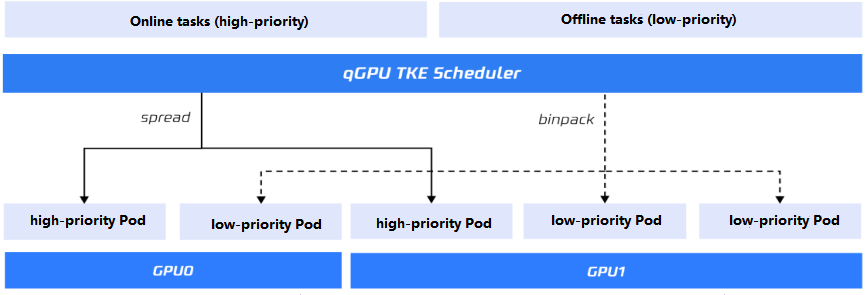
Strengths
qGPU online/offline hybrid deployment keeps GPU computing power under absolute control and pushes the utilization to the limit:
- 100% utilization of the idle computing power of high-priority tasks: All GPU computing power can be used by low-priority tasks when it is not occupied by high-priority tasks.
- 100% preemption of the computing power of low-priority tasks: Busy high-priority tasks can preempt GPU computing power from low-priority tasks.
Typical Use Cases
Hybrid deployment of online and offline inference
Search and recommendation support online services and are sensitive to the real-timeness of GPU computing power, while data preprocessing supports offline data cleansing and processing and is insensitive to the real-timeness of GPU computing power. The former can be set as a high-priority task and the latter as a low-priority one for deployment on the same GPU card.
Hybrid deployment of online inference and offline training
Real-time reference is sensitive to the availability of GPU computing power and uses a relatively small amount of resources, while model training consumes a large amount of resources and is insensitive to the availability of GPU computing power. Therefore, the former can be set as a high-priority task and the latter as a low-priority one for deployment on the same GPU card.
How It Works
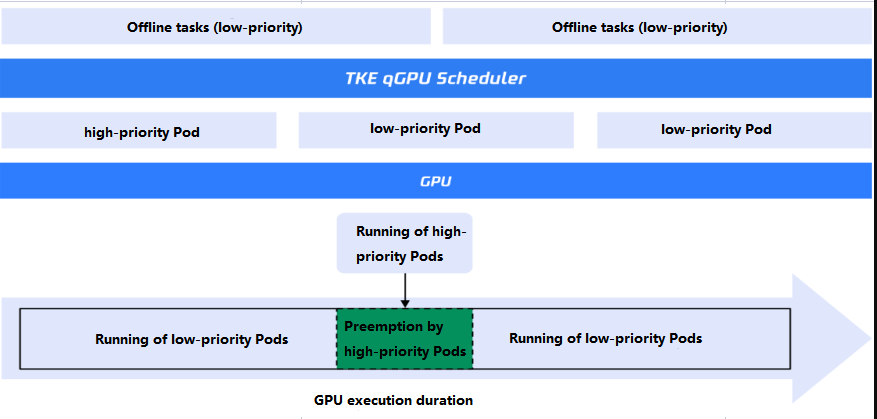
qGPU online/offline hybrid deployment can be enabled through the online/offline scheduling policy of the TKE cluster to allow online (high-priority) and offline (low-priority) tasks to share physical GPU resources more efficiently. qGPU online/offline hybrid deployment technology has two features:
Feature 1: 100% utilization of the idle computing power by low-priority Pods
After low-priority Pods are scheduled to the node GPU, if the GPU computing power is not occupied by high-priority Pods, low-priority Pods can use all the computing power. When multiple low-priority Pods share the GPU computing power, the qGPU policy applies. When there are multiple high-priority Pods, resource competition applies instead of a specific policy.
Feature 2: 100% preemption of the computing power of low-priority Pods
qGPU online/offline hybrid deployment provides a priority-based preemption capability, which ensures that high-priority Pods can immediately and completely use the GPU computing power when they are busy. This is implemented through a priority-based preemption and scheduling policy at the qGPU driver layer:
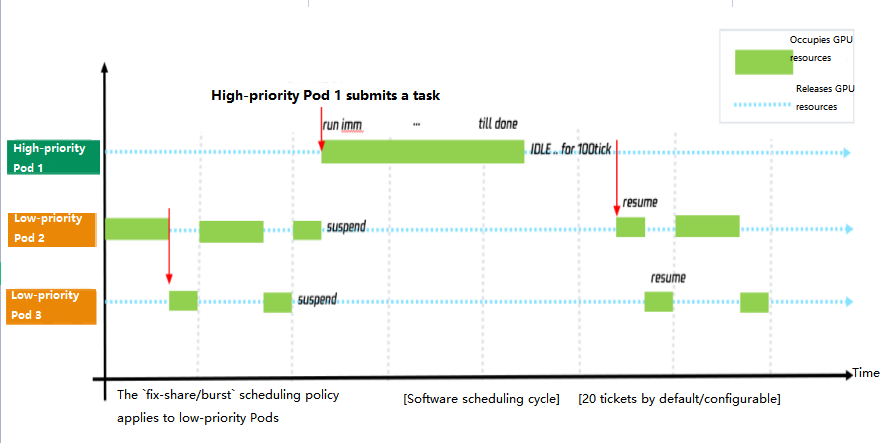
First, the qGPU driver perceives the requirements of high-priority Pods for GPU computing power and provides all computing power to them within one millisecond after they submit computing tasks. When high-priority Pods have no running tasks, the driver will release the occupied computing power after 100 milliseconds and allocate it to offline Pods.
Second, the qGPU driver supports suspending and resuming computing tasks. When a high-priority Pod has a running computing task, the low-priority Pod that occupies GPU computing power will be suspended immediately to release the computing power. When the task of the high-priority Pod ends, the low-priority Pod will be woken up to resume the computing task from where it ends. The sequence diagram of computing tasks at different priorities is as shown below:
Scheduling policy
On a general qGPU node, you can set the policy for scheduling Pods on the same card. In the online/offline hybrid deployment feature, the policy affects only the scheduling of low-priority Pods.
- Low-priority Pods
When high-priority Pods are sleeping and low-priority Pods are running, low-priority Pods are scheduled based on the policy. When high-priority Pods use GPU computing power, all low-priority ones will be suspended immediately until the high-priority task ends, after which low-priority tasks resume based on the policy. - High-priority Pods
When high-priority Pods have computing tasks, they preempt the GPU computing power immediately. High-priority Pods always preempt resources from low-priority Pods, and high-priority Pods compete for GPU computing power with each other, both of which are not subject to a specific policy.

 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?