This document describes the causes and solutions of various FAQs of TKE Serverless clusters.
Why is the Pod specification inconsistent with the set Request/Limit?
When allocating resources for Pods, TKE Serverless will calculate the Request and Limit values set by the workload, and automatically determine the amount of resources required for running the Pods, instead of allocating resources according to the set Request and Limit values. For more information, see CPU specifications calculation methods for pods and GPU specification calculation methods for pods.
How do I create or modify the container network of a TKE Serverless cluster?
When creating a cluster, you need to select a VPC as the cluster network and specify a subnet as the container network. For more information, see Notes on the Container Network. The Pod of the TKE Serverless cluster directly occupies an IP address of the container network subnet. When using the cluster, you can create or modify the container network through creating or removing the super node. The detailed instructions are shown below.
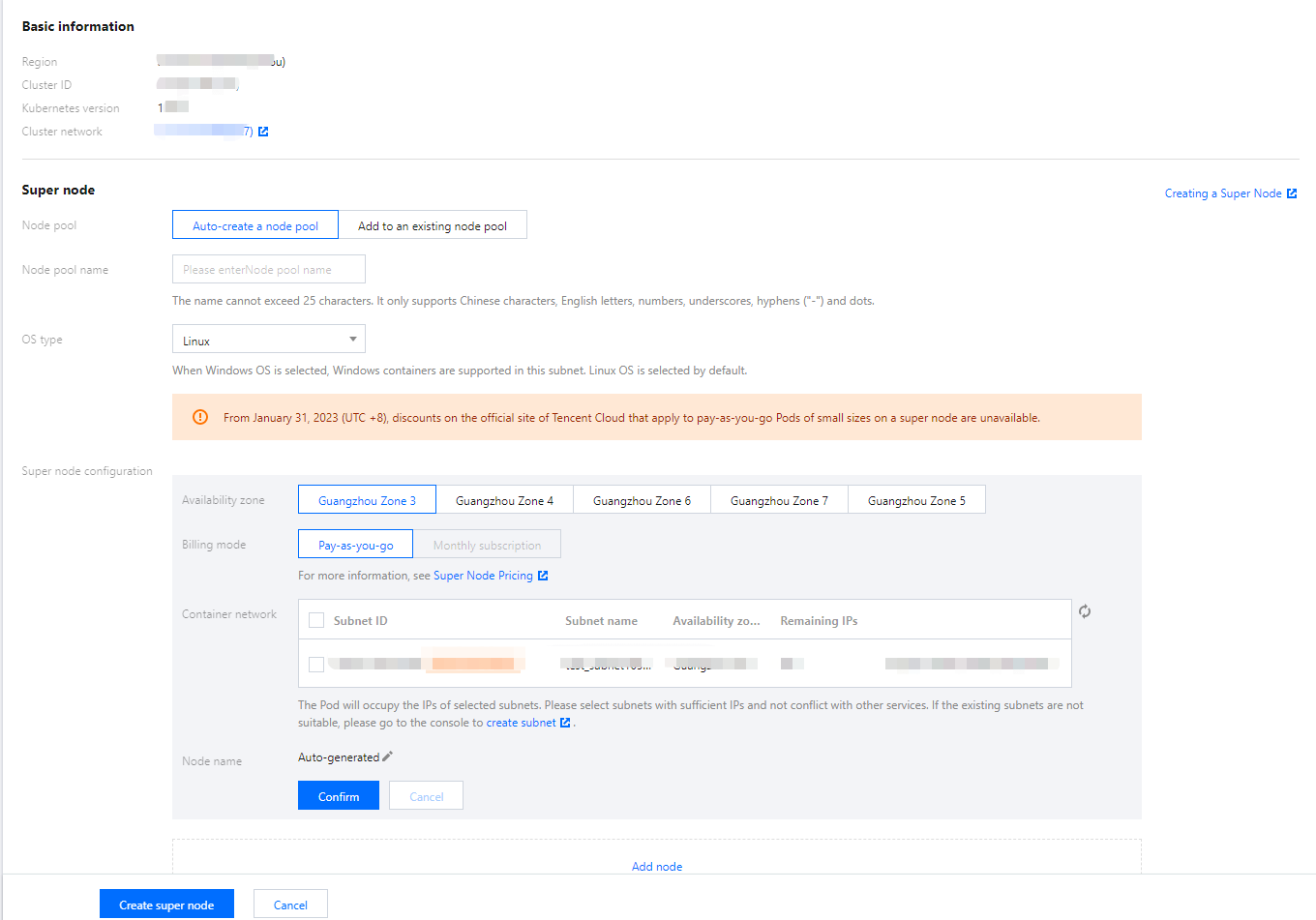
Step 1. Create a super node to add a container network
1. Log in to the TKE console and click Cluster in the left sidebar.
2. Click the ID of the cluster for which you need to modify the container network to go to the cluster details page.
3. Click Super node in the left sidebar. On the Super node page, click Create.
4. On the Create super node page, select the container network with sufficient IP addresses and click OK.
Step 2. Remove the super node to delete the container network
Note
Make sure that at least one super node remains in the TKE Serverless cluster after the removal. If there is only one super node, you cannot remove it.
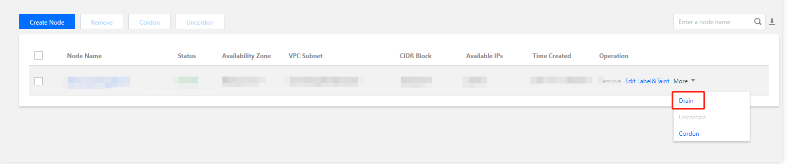
Before removing a super node, you need to drain all Pods on it (excluding those managed by DaemonSet) to other super nodes. After the draining is completed, you can remove the super node; otherwise, the removal will fail. The detailed directions are as shown below.
1. Log in to the TKE console and click Cluster in the left sidebar.
2. Click the ID of the cluster for which you need to modify the container network to go to the cluster details page.
3. Click Super node in the left sidebar. On the Super node page, choose More > Drain on the right of the node name.
4. On the Drain node page, check the node information and click OK. After the node is drained, it will enter the "Blocked" status, and no more Pods can be scheduled to it.
Note
Note that Pods will be rebuilt once the node is drained.
5. On the Super node page, click Remove on the right of the node name.
6. On the Delete node page, click OK.
What should I do if the Pod fails to schedule because of insufficient subnet IPs?
When a Pod fails to be scheduled due to insufficient subnet IP addresses, you can find two events in the node logs.
Event 1:
Event 2:
You can query the YAML of the super node in the [TKE console]](https://console.tencentcloud.com/tke2/ecluster?rid=1!991ea712f9f39b63beaafb2cdb56ba5f) or by running the following command in the command line tool:
kubectl get nodes -oyaml
The following information will appear:
spec:
taints:
-effect: NoSchedule
key: node.kubernetes.io/network-unavailable
timeAdded:"2021-04-20T07:00:16Z"
-lastHeartbeatTime:"2021-04-20T07:55:28Z"
lastTransitionTime:"2021-04-20T07:00:16Z"
message: eklet node has insufficient IP available of subnet subnet-bok73g4c
reason: EKLetHasInsufficientSubnetIP
status:"True"
type: NetworkUnavailable
It shows that the Pod fails to be scheduled due to insufficient subnet IP addresses of the container network. In this case, you need to create super nodes to add subnets and available IP ranges. For how to create a super node, see Creating Super Node.
What are the instructions for using the TKE Serverless cluster security group?
When creating the TKE Serverless cluster Pod, if you do not specify a security group, the default security group will be used. You can also specify a security group for the Pod through Annotation eks.tke.cloud.tencent.com/security-group-id: security group ID. Make sure that the security group ID already exists in the region where the workload resides. For more information about this annotation, see Annotation.
How do I set a container termination message?
Kubernetes can set the message source of the container exit through terminationMessagePath, that is, when the container exits, Kubernetes will retrieve termination messages from the termination message file specified in the terminationMessagePath field of a container, and use this contents from the specified file to populate the container's termination message. The default value of the message is /dev/termination-log.
Moreover, you can set the terminationMessagePolicy field of a container for further termination message customization. This field defaults to “File”, which means the termination messages are retrieved only from the termination message file. You can set the terminationMessagePolicy to FallbackToLogsOnError as needed, and Kubernetes will use the last chunk of container log output if the termination message file is empty and the container exited with an error.
Sample code:
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: nginx
spec:
containers:
-image: nginx
imagePullPolicy: Always
name: nginx
resources:
limits:
cpu: 500m
memory: 1Gi
requests:
cpu: 250m
memory: 256Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: FallbackToLogsOnError
With the above configuration, when the container exits with an error and the termination message file is empty, Get Pod will find that the output of stderr is displayed in containerStatuses.
How do I use Host parameters?
Note the following when using TKE Serverless clusters:
TKE Serverless clusters do not have nodes but are compatible with Host parameters, such as Hostpath, Hostnetwork: true, and DnsPolicy: ClusterFirstWithHostNet. Note that these parameters cannot deliver the full capabilities of K8s, as there is no node.
For example, you may want to use Hostpath to share data, but the two Pods scheduled to the same super node will see the Hostpath of different hosts. In addition, if the Pod is rebuilt, Hostpath files will be deleted at the same time.
How do I mount CFS/NFS?
In TKE Serverless clusters, you can use Tencent Cloud's Cloud File Storage (CFS) or mount an external NFS as a volume to a Pod for persistent data storage. A sample YAML to mount CFS/NFS to a Pod is as shown below:
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
-image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
-mountPath: /cache
name: cache-volume
volumes:
-name: nfs
nfs:
path: /dir
server: 127.0.0.1
---
spec.volumes: Set the name, type, and parameters of the volume.
spec.volumes.nfs: Set the NFS/CFS disk.
spec.containers.volumeMounts: Set the mount point of the volume in the Pod.
How do I speed up container startup by image reuse?
TKE Serverless supports caching container images to speed up the next startup of the container with the same images.
Conditions for Reuse:
1. For Pods with the same Workload, if a Pod is created and terminated at the same AZ within the cache time, the new Pod will not pull the same image by default.
2. If you want to reuse images for Pods with different workloads (including Deployment, Statefulset, and Job), use the following annotation:
eks.tke.cloud.tencent.com/cbs-reuse-key
For Pods with the same annotation value under the same user account, the start-up image will be reused within the cache time as much as possible. We recommend you enter the image name of the annotation value: eks.tke.cloud.tencent.com/cbs-reuse-key: "image-name".
Cache time: 2 hours.
How do I solve image reuse exceptions?
When image reuse function is enabled, if a Pod is created, $kubectl describe pod may see the following errors:
no space left on device: unknown
Warning FreeDiskSpaceFailed 26m eklet, eklet-subnet-xxx failed to garbage collect required amount of images. Wanted to free 4220828057 bytes, but freed 3889267064 bytes
Methods for Resume:
No action is required. Wait for a few minutes and the Pod will run automatically.
Cause:
no space left on device: unknown
When the Pod reuses the system disk by default, the original image in the system disk occupies all of the space, and the disk does not have enough space to download the new image, so the error "no space left on device: unknown" is reported. TKE Serverless supports the regular image repossession mechanism. When the whole space is occupied, the mechanism will automatically delete the existing redundant images in the system disk to free up the current disk. The process takes several minutes).
Warning FreeDiskSpaceFailed 26m eklet, eklet-subnet-xxx failed to garbage collect required amount of images. Wanted to free 4220828057 bytes, but freed 3889267064 bytes
This log shows that the current Pod needs 4220828057 bytes to download the image, but currently only 3889267064 bytes are available. The cause is that there are multiple images on the disk and only some images have been freed up. The regular image repossession mechanism of TKE Serverless will continue to free up the disk until a new image can be successfully pulled.
What should I do if Operation not permitted is reported when I mount an external NFS?
If you use an external NFS for persistent storage, the event Operation not permitted will be reported when a connection is made. You need to modify the /etc/exports file of your NFS and add the /<path><ip-range>(rw,insecure) parameter. See the example below:
/data/ 10.0.0.0/16(rw,insecure)
How do I free up a full Pod disk (ImageGCFailed)?
TKE Serverless Pods provide 20 GB of free system disk space by default. If the disk is full, you can free it up in the following ways.
1. Free up unused container images
If 80% of the space is used, the TKE Serverless backend will trigger the container image repossession process to recover the unused images and free up the space. If this process fails, the ImageGCFailed: failed to garbage collect required amount of images message will be reported to remind you of the insufficient disk space.
Common causes of insufficient disk space include:
The business has a lot of temporary outputs. You can confirm this with the du command.
The business holds deleted file descriptors, so disk space is not freed up. You can confirm this with the lsof command.
If you want to adjust the threshold for the container image repossession, set the following annotation:
If your business has been upgraded in-place or a container has abnormally exited, the exited container will be retained until the disk utilization reaches 85%. The cleanup threshold can be adjusted with the following annotation:
If you do not want to have the exited container automatically cleaned up (for example, you need the exit information for further troubleshooting), you can disable the automatic cleanup with the following annotation; however, the disk space cannot be automatically freed up in this case.
Only the Pod is restarted, but the host will not be rebuilt. Normal gracestop, prestop, and health checks are performed for the exit and startup.
Description
This feature was launched on April 27, 2022 (UTC +8) and can be enabled on Pods created earlier only after they are rebuilt.
9100 port issue
TKE Serverless Pods expose monitoring data via port 9100 by default, and you can access 9100/metrics to get the data by running the following commands:
Get all metrics:
curl -g "http://<pod-ip>:9100/metrics"
We recommend that you remove the ipvs metric for large clusters:
If your business requires listening on port 9100, you can avoid conflicts by using other ports to collect monitoring data when creating a Pod. The configuration is as shown below:
eks.tke.cloud.tencent.com/metrics-port: "9110"
If the port for monitoring data exposure is not changed and the business listens on port 9100 directly, an error will be reported in the new TKE Serverless network scheme, indicating that port 9100 is already in use:
listen() to 0.0.0.0:9100, backlog 511 failed (1: Operation not permitted)
When this error is reported, you need to add the annotation metrics-port to the Pod to change the monitoring port and then rebuild the Pod.
Note
If the Pod has a public EIP, you need to set up a security group. Pay attention to port 9100 and allow traffic over required ports.



 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?