- Release Notes and Announcements
- Release Notes
- Announcements
- Notification on Service Suspension Policy Change in Case of Overdue Payment for COS Pay-As-You-Go (Postpaid)
- Implementation Notice for Security Management of COS Bucket Domain (Effective January 2024)
- Notification of Price Reduction for COS Retrieval and Storage Capacity Charges
- Daily Billing for COS Storage Usage, Request, and Data Retrieval
- COS Will Stop Supporting New Default CDN Acceleration Domains
- Product Introduction
- Purchase Guide
- Getting Started
- Console Guide
- Console Overview
- Bucket Management
- Bucket Overview
- Creating Bucket
- Deleting Buckets
- Querying Bucket
- Clearing Bucket
- Setting Access Permission
- Setting Bucket Encryption
- Setting Hotlink Protection
- Setting Origin-Pull
- Setting Cross-Origin Resource Sharing (CORS)
- Setting Versioning
- Setting Static Website
- Setting Lifecycle
- Setting Logging
- Accessing Bucket List Using Sub-Account
- Adding Bucket Policies
- Setting Log Analysis
- Setting INTELLIGENT TIERING
- Setting Inventory
- Domain Name Management
- Setting Bucket Tags
- Setting Log Retrieval
- Setting Cross-Bucket Replication
- Enabling Global Acceleration
- Setting Object Lock
- Object Management
- Uploading an Object
- Downloading Objects
- Copying Object
- Previewing or Editing Object
- Viewing Object Information
- Searching for Objects
- Sorting and Filtering Objects
- Direct Upload to ARCHIVE
- Modifying Storage Class
- Deleting Incomplete Multipart Uploads
- Setting Object Access Permission
- Setting Object Encryption
- Custom Headers
- Deleting Objects
- Restoring Archived Objects
- Folder Management
- Data Extraction
- Setting Object Tag
- Exporting Object URLs
- Restoring Historical Object Version
- Batch Operation
- Monitoring Reports
- Data Processing
- Content Moderation
- Smart Toolbox User Guide
- Data Processing Workflow
- Application Integration
- User Tools
- Tool Overview
- Installation and Configuration of Environment
- COSBrowser
- COSCLI (Beta)
- COSCLI Overview
- Download and Installation Configuration
- Common Options
- Common Commands
- Generating and Modifying Configuration Files - config
- Creating Buckets - mb
- Deleting Buckets - rb
- Tagging Bucket - bucket-tagging
- Querying Bucket/Object List - ls
- Obtaining Statistics on Different Types of Objects - du
- Uploading/Downloading/Copying Objects - cp
- Syncing Upload/Download/Copy - sync
- Deleting Objects - rm
- Getting File Hash Value - hash
- Listing Incomplete Multipart Uploads - lsparts
- Clearing Incomplete Multipart Uploads - abort
- Retrieving Archived Files - restore
- Creating/Obtaining a Symbolic Link - symlink
- Viewing Contents of an Object - cat
- Getting Pre-signed URL - signurl
- Listing Contents and Statistics Under a Directory - lsdu
- FAQs
- COSCMD
- COS Migration
- FTP Server
- Hadoop
- COSDistCp
- HDFS TO COS
- GooseFS-Lite
- Online Auxiliary Tools
- Diagnostic Tool
- Practical Tutorial
- Overview
- Access Control and Permission Management
- ACL Practices
- CAM Practices
- Granting Sub-Accounts Access to COS
- Authorization Cases
- Working with COS API Authorization Policies
- Security Guidelines for Using Temporary Credentials for Direct Upload from Frontend to COS
- Generating and Using Temporary Keys
- Authorizing Sub-Account to Get Buckets by Tag
- Descriptions and Use Cases of Condition Keys
- Granting Bucket Permissions to a Sub-Account that is Under Another Root Account
- Performance Optimization
- Data Migration
- Accessing COS with AWS S3 SDK
- Data Disaster Recovery and Backup
- Domain Name Management Practice
- Image Processing
- Audio/Video Practices
- Workflow
- Direct Data Upload
- Content Moderation
- Data Security
- Data Verification
- Big Data Practice
- Using COS in the Third-party Applications
- Use the general configuration of COS in third-party applications compatible with S3
- Storing Remote WordPress Attachments to COS
- Storing Ghost Attachment to COS
- Backing up Files from PC to COS
- Using Nextcloud and COS to Build Personal Online File Storage Service
- Mounting COS to Windows Server as Local Drive
- Setting up Image Hosting Service with PicGo, Typora, and COS
- Managing COS Resource with CloudBerry Explorer
- Developer Guide
- Creating Request
- Bucket
- Object
- Data Management
- Data Disaster Recovery
- Data Security
- Cloud Access Management
- Batch Operation
- Global Acceleration
- Data Workflow
- Monitoring and Alarms
- Data Lake Storage
- Cloud Native Datalake Storage
- Metadata Accelerator
- Metadata Acceleration Overview
- Migrating HDFS Data to Metadata Acceleration-Enabled Bucket
- Using HDFS to Access Metadata Acceleration-Enabled Bucket
- Mounting a COS Bucket in a Computing Cluster
- Accessing COS over HDFS in CDH Cluster
- Using Hadoop FileSystem API Code to Access COS Metadata Acceleration Bucket
- Using DataX to Sync Data Between Buckets with Metadata Acceleration Enabled
- Big Data Security
- GooseFS
- Data Processing
- Troubleshooting
- API Documentation
- Introduction
- Common Request Headers
- Common Response Headers
- Error Codes
- Request Signature
- Action List
- Service APIs
- Bucket APIs
- Basic Operations
- Access Control List (acl)
- Cross-Origin Resource Sharing (cors)
- Lifecycle
- Bucket Policy (policy)
- Hotlink Protection (referer)
- Tag (tagging)
- Static Website (website)
- Intelligent Tiering
- Bucket inventory(inventory)
- Versioning
- Cross-Bucket Replication(replication)
- Log Management(logging)
- Global Acceleration (Accelerate)
- Bucket Encryption (encryption)
- Custom Domain Name (Domain)
- Origin-Pull (Origin)
- Object APIs
- Batch Operation APIs
- Data Processing APIs
- Image Processing
- Basic Image Processing
- Scaling
- Cropping
- Rotation
- Converting Format
- Quality Change
- Gaussian Blurring
- Adjusting Brightness
- Adjusting Contrast
- Sharpening
- Grayscale Image
- Image Watermark
- Text Watermark
- Obtaining Basic Image Information
- Getting Image EXIF
- Obtaining Image’s Average Hue
- Metadata Removal
- Quick Thumbnail Template
- Limiting Output Image Size
- Pipeline Operators
- Image Advanced Compression
- Persistent Image Processing
- Image Compression
- Blind Watermark
- Basic Image Processing
- AI-Based Content Recognition
- Media Processing
- File Processing
- File Processing
- Image Processing
- Job and Workflow
- Common Request Headers
- Common Response Headers
- Error Codes
- Workflow APIs
- Workflow Instance
- Job APIs
- Media Processing
- Canceling Media Processing Job
- Querying Media Processing Job
- Media Processing Job Callback
- Video-to-Animated Image Conversion
- Audio/Video Splicing
- Adding Digital Watermark
- Extracting Digital Watermark
- Getting Media Information
- Noise Cancellation
- Video Quality Scoring
- SDRtoHDR
- Remuxing (Audio/Video Segmentation)
- Intelligent Thumbnail
- Frame Capturing
- Stream Separation
- Super Resolution
- Audio/Video Transcoding
- Text to Speech
- Video Montage
- Video Enhancement
- Video Tagging
- Voice/Sound Separation
- Image Processing
- Multi-Job Processing
- AI-Based Content Recognition
- Sync Media Processing
- Media Processing
- Template APIs
- Media Processing
- Creating Media Processing Template
- Creating Animated Image Template
- Creating Splicing Template
- Creating Top Speed Codec Transcoding Template
- Creating Screenshot Template
- Creating Super Resolution Template
- Creating Audio/Video Transcoding Template
- Creating Professional Transcoding Template
- Creating Text-to-Speech Template
- Creating Video Montage Template
- Creating Video Enhancement Template
- Creating Voice/Sound Separation Template
- Creating Watermark Template
- Creating Intelligent Thumbnail Template
- Deleting Media Processing Template
- Querying Media Processing Template
- Updating Media Processing Template
- Updating Animated Image Template
- Updating Splicing Template
- Updating Top Speed Codec Transcoding Template
- Updating Screenshot Template
- Updating Super Resolution Template
- Updating Audio/Video Transcoding Template
- Updating Professional Transcoding Template
- Updating Text-to-Speech Template
- Updating Video Montage Template
- Updating Video Enhancement Template
- Updating Voice/Sound Separation Template
- Updating Watermark Template
- Updating Intelligent Thumbnail Template
- Creating Media Processing Template
- AI-Based Content Recognition
- Media Processing
- Batch Job APIs
- Callback Content
- Appendix
- Content Moderation APIs
- Submitting Virus Detection Job
- SDK Documentation
- SDK Overview
- Preparations
- Android SDK
- Getting Started
- Android SDK FAQs
- Quick Experience
- Bucket Operations
- Object Operations
- Uploading an Object
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Restoring Archived Objects
- Querying Object Metadata
- Generating Pre-Signed URLs
- Configuring Preflight Requests for Cross-origin Access
- Server-Side Encryption
- Single-Connection Bandwidth Limit
- Extracting Object Content
- Remote Disaster Recovery
- Data Management
- Cloud Access Management
- Data Verification
- Image Processing
- Setting Custom Headers
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- C SDK
- C++ SDK
- .NET(C#) SDK
- Getting Started
- .NET (C#) SDK
- Bucket Operations
- Object Operations
- Uploading Objects
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Checking Whether Objects Exist
- Restoring Archived Objects
- Querying Object Metadata
- Object Access URL
- Getting Pre-Signed URLs
- Configuring Preflight Requests for Cross-Origin Access
- Server-Side Encryption
- Single-URL Speed Limits
- Extracting Object Content
- Cross-Region Disaster Recovery
- Data Management
- Cloud Access Management
- Image Processing
- Content Moderation
- Setting Custom Headers
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- Backward Compatibility
- SDK for Flutter
- Go SDK
- iOS SDK
- Getting Started
- iOS SDK
- Quick Experience
- Bucket Operations
- Object Operations
- Uploading Objects
- Downloading Objects
- Listing Objects
- Copying and Moving Objects
- Extracting Object Content
- Checking Whether an Object Exists
- Deleting Objects
- Restoring Archived Objects
- Querying Object Metadata
- Server-Side Encryption
- Object Access URL
- Generating Pre-Signed URL
- Configuring CORS Preflight Requests
- Cross-region Disaster Recovery
- Data Management
- Cloud Access Management
- Image Processing
- Content Recognition
- Setting Custom Headers
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- Java SDK
- Getting Started
- FAQs
- Bucket Operations
- Object Operations
- Uploading Object
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Checking Whether Objects Exist
- Querying Object Metadata
- Modifying Object Metadata
- Object Access URL
- Generating Pre-Signed URLs
- Restoring Archived Objects
- Server-Side Encryption
- Client-Side Encryption
- Single-URL Speed Limits
- Extracting Object Content
- Uploading/Downloading Object at Custom Domain Name
- Data Management
- Cross-Region Disaster Recovery
- Cloud Access Management
- Image Processing
- Content Moderation
- File Processing
- Media Processing
- AI-Based Content Recognition
- Troubleshooting
- Setting Access Domain Names (CDN/Global Acceleration)
- JavaScript SDK
- Node.js SDK
- PHP SDK
- Python SDK
- Getting Started
- Python SDK FAQs
- Bucket Operations
- Object Operations
- Uploading Objects
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Checking Whether Objects Exist
- Querying Object Metadata
- Modifying Object Metadata
- Object Access URL
- Getting Pre-Signed URLs
- Restoring Archived Objects
- Extracting Object Content
- Server-Side Encryption
- Client-Side Encryption
- Single-URL Speed Limits
- Cross-Region Disaster Recovery
- Data Management
- Cloud Access Management
- Content Recognition
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- Image Processing
- React Native SDK
- Mini Program SDK
- Getting Started
- FAQs
- Bucket Operations
- Object Operations
- Uploading an Object
- Downloading Objects
- Listing Objects
- Deleting Objects
- Copying and Moving Objects
- Restoring Archived Objects
- Querying Object Metadata
- Checking Whether an Object Exists
- Object Access URL
- Generating Pre-Signed URL
- Configuring CORS Preflight Requests
- Single-URL Speed Limits
- Server-Side Encryption
- Remote disaster-tolerant
- Data Management
- Cloud Access Management
- Data Verification
- Content Moderation
- Setting Access Domain Names (CDN/Global Acceleration)
- Image Processing
- Troubleshooting
- Error Codes
- FAQs
- Related Agreements
- Appendices
- Glossary
- Release Notes and Announcements
- Release Notes
- Announcements
- Notification on Service Suspension Policy Change in Case of Overdue Payment for COS Pay-As-You-Go (Postpaid)
- Implementation Notice for Security Management of COS Bucket Domain (Effective January 2024)
- Notification of Price Reduction for COS Retrieval and Storage Capacity Charges
- Daily Billing for COS Storage Usage, Request, and Data Retrieval
- COS Will Stop Supporting New Default CDN Acceleration Domains
- Product Introduction
- Purchase Guide
- Getting Started
- Console Guide
- Console Overview
- Bucket Management
- Bucket Overview
- Creating Bucket
- Deleting Buckets
- Querying Bucket
- Clearing Bucket
- Setting Access Permission
- Setting Bucket Encryption
- Setting Hotlink Protection
- Setting Origin-Pull
- Setting Cross-Origin Resource Sharing (CORS)
- Setting Versioning
- Setting Static Website
- Setting Lifecycle
- Setting Logging
- Accessing Bucket List Using Sub-Account
- Adding Bucket Policies
- Setting Log Analysis
- Setting INTELLIGENT TIERING
- Setting Inventory
- Domain Name Management
- Setting Bucket Tags
- Setting Log Retrieval
- Setting Cross-Bucket Replication
- Enabling Global Acceleration
- Setting Object Lock
- Object Management
- Uploading an Object
- Downloading Objects
- Copying Object
- Previewing or Editing Object
- Viewing Object Information
- Searching for Objects
- Sorting and Filtering Objects
- Direct Upload to ARCHIVE
- Modifying Storage Class
- Deleting Incomplete Multipart Uploads
- Setting Object Access Permission
- Setting Object Encryption
- Custom Headers
- Deleting Objects
- Restoring Archived Objects
- Folder Management
- Data Extraction
- Setting Object Tag
- Exporting Object URLs
- Restoring Historical Object Version
- Batch Operation
- Monitoring Reports
- Data Processing
- Content Moderation
- Smart Toolbox User Guide
- Data Processing Workflow
- Application Integration
- User Tools
- Tool Overview
- Installation and Configuration of Environment
- COSBrowser
- COSCLI (Beta)
- COSCLI Overview
- Download and Installation Configuration
- Common Options
- Common Commands
- Generating and Modifying Configuration Files - config
- Creating Buckets - mb
- Deleting Buckets - rb
- Tagging Bucket - bucket-tagging
- Querying Bucket/Object List - ls
- Obtaining Statistics on Different Types of Objects - du
- Uploading/Downloading/Copying Objects - cp
- Syncing Upload/Download/Copy - sync
- Deleting Objects - rm
- Getting File Hash Value - hash
- Listing Incomplete Multipart Uploads - lsparts
- Clearing Incomplete Multipart Uploads - abort
- Retrieving Archived Files - restore
- Creating/Obtaining a Symbolic Link - symlink
- Viewing Contents of an Object - cat
- Getting Pre-signed URL - signurl
- Listing Contents and Statistics Under a Directory - lsdu
- FAQs
- COSCMD
- COS Migration
- FTP Server
- Hadoop
- COSDistCp
- HDFS TO COS
- GooseFS-Lite
- Online Auxiliary Tools
- Diagnostic Tool
- Practical Tutorial
- Overview
- Access Control and Permission Management
- ACL Practices
- CAM Practices
- Granting Sub-Accounts Access to COS
- Authorization Cases
- Working with COS API Authorization Policies
- Security Guidelines for Using Temporary Credentials for Direct Upload from Frontend to COS
- Generating and Using Temporary Keys
- Authorizing Sub-Account to Get Buckets by Tag
- Descriptions and Use Cases of Condition Keys
- Granting Bucket Permissions to a Sub-Account that is Under Another Root Account
- Performance Optimization
- Data Migration
- Accessing COS with AWS S3 SDK
- Data Disaster Recovery and Backup
- Domain Name Management Practice
- Image Processing
- Audio/Video Practices
- Workflow
- Direct Data Upload
- Content Moderation
- Data Security
- Data Verification
- Big Data Practice
- Using COS in the Third-party Applications
- Use the general configuration of COS in third-party applications compatible with S3
- Storing Remote WordPress Attachments to COS
- Storing Ghost Attachment to COS
- Backing up Files from PC to COS
- Using Nextcloud and COS to Build Personal Online File Storage Service
- Mounting COS to Windows Server as Local Drive
- Setting up Image Hosting Service with PicGo, Typora, and COS
- Managing COS Resource with CloudBerry Explorer
- Developer Guide
- Creating Request
- Bucket
- Object
- Data Management
- Data Disaster Recovery
- Data Security
- Cloud Access Management
- Batch Operation
- Global Acceleration
- Data Workflow
- Monitoring and Alarms
- Data Lake Storage
- Cloud Native Datalake Storage
- Metadata Accelerator
- Metadata Acceleration Overview
- Migrating HDFS Data to Metadata Acceleration-Enabled Bucket
- Using HDFS to Access Metadata Acceleration-Enabled Bucket
- Mounting a COS Bucket in a Computing Cluster
- Accessing COS over HDFS in CDH Cluster
- Using Hadoop FileSystem API Code to Access COS Metadata Acceleration Bucket
- Using DataX to Sync Data Between Buckets with Metadata Acceleration Enabled
- Big Data Security
- GooseFS
- Data Processing
- Troubleshooting
- API Documentation
- Introduction
- Common Request Headers
- Common Response Headers
- Error Codes
- Request Signature
- Action List
- Service APIs
- Bucket APIs
- Basic Operations
- Access Control List (acl)
- Cross-Origin Resource Sharing (cors)
- Lifecycle
- Bucket Policy (policy)
- Hotlink Protection (referer)
- Tag (tagging)
- Static Website (website)
- Intelligent Tiering
- Bucket inventory(inventory)
- Versioning
- Cross-Bucket Replication(replication)
- Log Management(logging)
- Global Acceleration (Accelerate)
- Bucket Encryption (encryption)
- Custom Domain Name (Domain)
- Origin-Pull (Origin)
- Object APIs
- Batch Operation APIs
- Data Processing APIs
- Image Processing
- Basic Image Processing
- Scaling
- Cropping
- Rotation
- Converting Format
- Quality Change
- Gaussian Blurring
- Adjusting Brightness
- Adjusting Contrast
- Sharpening
- Grayscale Image
- Image Watermark
- Text Watermark
- Obtaining Basic Image Information
- Getting Image EXIF
- Obtaining Image’s Average Hue
- Metadata Removal
- Quick Thumbnail Template
- Limiting Output Image Size
- Pipeline Operators
- Image Advanced Compression
- Persistent Image Processing
- Image Compression
- Blind Watermark
- Basic Image Processing
- AI-Based Content Recognition
- Media Processing
- File Processing
- File Processing
- Image Processing
- Job and Workflow
- Common Request Headers
- Common Response Headers
- Error Codes
- Workflow APIs
- Workflow Instance
- Job APIs
- Media Processing
- Canceling Media Processing Job
- Querying Media Processing Job
- Media Processing Job Callback
- Video-to-Animated Image Conversion
- Audio/Video Splicing
- Adding Digital Watermark
- Extracting Digital Watermark
- Getting Media Information
- Noise Cancellation
- Video Quality Scoring
- SDRtoHDR
- Remuxing (Audio/Video Segmentation)
- Intelligent Thumbnail
- Frame Capturing
- Stream Separation
- Super Resolution
- Audio/Video Transcoding
- Text to Speech
- Video Montage
- Video Enhancement
- Video Tagging
- Voice/Sound Separation
- Image Processing
- Multi-Job Processing
- AI-Based Content Recognition
- Sync Media Processing
- Media Processing
- Template APIs
- Media Processing
- Creating Media Processing Template
- Creating Animated Image Template
- Creating Splicing Template
- Creating Top Speed Codec Transcoding Template
- Creating Screenshot Template
- Creating Super Resolution Template
- Creating Audio/Video Transcoding Template
- Creating Professional Transcoding Template
- Creating Text-to-Speech Template
- Creating Video Montage Template
- Creating Video Enhancement Template
- Creating Voice/Sound Separation Template
- Creating Watermark Template
- Creating Intelligent Thumbnail Template
- Deleting Media Processing Template
- Querying Media Processing Template
- Updating Media Processing Template
- Updating Animated Image Template
- Updating Splicing Template
- Updating Top Speed Codec Transcoding Template
- Updating Screenshot Template
- Updating Super Resolution Template
- Updating Audio/Video Transcoding Template
- Updating Professional Transcoding Template
- Updating Text-to-Speech Template
- Updating Video Montage Template
- Updating Video Enhancement Template
- Updating Voice/Sound Separation Template
- Updating Watermark Template
- Updating Intelligent Thumbnail Template
- Creating Media Processing Template
- AI-Based Content Recognition
- Media Processing
- Batch Job APIs
- Callback Content
- Appendix
- Content Moderation APIs
- Submitting Virus Detection Job
- SDK Documentation
- SDK Overview
- Preparations
- Android SDK
- Getting Started
- Android SDK FAQs
- Quick Experience
- Bucket Operations
- Object Operations
- Uploading an Object
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Restoring Archived Objects
- Querying Object Metadata
- Generating Pre-Signed URLs
- Configuring Preflight Requests for Cross-origin Access
- Server-Side Encryption
- Single-Connection Bandwidth Limit
- Extracting Object Content
- Remote Disaster Recovery
- Data Management
- Cloud Access Management
- Data Verification
- Image Processing
- Setting Custom Headers
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- C SDK
- C++ SDK
- .NET(C#) SDK
- Getting Started
- .NET (C#) SDK
- Bucket Operations
- Object Operations
- Uploading Objects
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Checking Whether Objects Exist
- Restoring Archived Objects
- Querying Object Metadata
- Object Access URL
- Getting Pre-Signed URLs
- Configuring Preflight Requests for Cross-Origin Access
- Server-Side Encryption
- Single-URL Speed Limits
- Extracting Object Content
- Cross-Region Disaster Recovery
- Data Management
- Cloud Access Management
- Image Processing
- Content Moderation
- Setting Custom Headers
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- Backward Compatibility
- SDK for Flutter
- Go SDK
- iOS SDK
- Getting Started
- iOS SDK
- Quick Experience
- Bucket Operations
- Object Operations
- Uploading Objects
- Downloading Objects
- Listing Objects
- Copying and Moving Objects
- Extracting Object Content
- Checking Whether an Object Exists
- Deleting Objects
- Restoring Archived Objects
- Querying Object Metadata
- Server-Side Encryption
- Object Access URL
- Generating Pre-Signed URL
- Configuring CORS Preflight Requests
- Cross-region Disaster Recovery
- Data Management
- Cloud Access Management
- Image Processing
- Content Recognition
- Setting Custom Headers
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- Java SDK
- Getting Started
- FAQs
- Bucket Operations
- Object Operations
- Uploading Object
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Checking Whether Objects Exist
- Querying Object Metadata
- Modifying Object Metadata
- Object Access URL
- Generating Pre-Signed URLs
- Restoring Archived Objects
- Server-Side Encryption
- Client-Side Encryption
- Single-URL Speed Limits
- Extracting Object Content
- Uploading/Downloading Object at Custom Domain Name
- Data Management
- Cross-Region Disaster Recovery
- Cloud Access Management
- Image Processing
- Content Moderation
- File Processing
- Media Processing
- AI-Based Content Recognition
- Troubleshooting
- Setting Access Domain Names (CDN/Global Acceleration)
- JavaScript SDK
- Node.js SDK
- PHP SDK
- Python SDK
- Getting Started
- Python SDK FAQs
- Bucket Operations
- Object Operations
- Uploading Objects
- Downloading Objects
- Copying and Moving Objects
- Listing Objects
- Deleting Objects
- Checking Whether Objects Exist
- Querying Object Metadata
- Modifying Object Metadata
- Object Access URL
- Getting Pre-Signed URLs
- Restoring Archived Objects
- Extracting Object Content
- Server-Side Encryption
- Client-Side Encryption
- Single-URL Speed Limits
- Cross-Region Disaster Recovery
- Data Management
- Cloud Access Management
- Content Recognition
- Setting Access Domain Names (CDN/Global Acceleration)
- Troubleshooting
- Image Processing
- React Native SDK
- Mini Program SDK
- Getting Started
- FAQs
- Bucket Operations
- Object Operations
- Uploading an Object
- Downloading Objects
- Listing Objects
- Deleting Objects
- Copying and Moving Objects
- Restoring Archived Objects
- Querying Object Metadata
- Checking Whether an Object Exists
- Object Access URL
- Generating Pre-Signed URL
- Configuring CORS Preflight Requests
- Single-URL Speed Limits
- Server-Side Encryption
- Remote disaster-tolerant
- Data Management
- Cloud Access Management
- Data Verification
- Content Moderation
- Setting Access Domain Names (CDN/Global Acceleration)
- Image Processing
- Troubleshooting
- Error Codes
- FAQs
- Related Agreements
- Appendices
- Glossary
Overview
CDH (Cloudera's distribution, including Apache Hadoop) is one of the most popular Hadoop distributions in the industry. This document describes how to access a COS bucket over the HDFS protocol, a flexible, cost-effective big-data solution, in a CDH environment to separate big data computing from storage.
Note:
To access a COS bucket over the HDFS protocol, you need to enable metadata acceleration first.
Currently, the support for big data modules by COS is as follows:
Module Name | Supported | Service Module to Restart |
YARN | Yes | NodeManager |
YARN | Yes | NodeManager |
Hive | Yes | HiveServer and HiveMetastore |
Spark | Yes | NodeManager |
Sqoop | Yes | NodeManager |
Presto | Yes | HiveServer, HiveMetastore, and Presto |
Flink | Yes | None |
Impala | Yes | None |
EMR | Yes | None |
Self-built component | To be supported in the future | No |
HBase | Not recommended | None |
Versions
This example uses software versions as follows:
CDH 5.16.1
Hadoop 2.6.0
How to Use
Configuring the storage environment
1. Log in to Cloudera Manager (CDH management page).
2. On the homepage, select Configuration > Service-Wide > Advanced as shown below:

3. Specify your COS settings in the configuration snippet
Cluster-wide Advanced Configuration Snippet(Safety Valve) for core-site.xml.<property><name>fs.AbstractFileSystem.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter</value></property><property><name>fs.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter</value></property><!--Temporary directory of the local cache. For data read/write, data will be written to the local disk when the memory cache is insufficient. This path will be created automatically if it does not exist--><property><name>fs.ofs.tmp.cache.dir</name><value>/data/emr/hdfs/tmp/chdfs/</value></property><!--appId--><property><name>fs.ofs.user.appid</name><value>1250000000</value></property>
The following lists the required settings (to be added to
core-site.xml). For other settings, see Mounting COS Bucket to Compute Cluster.Configuration Item | Value | Description |
fs.ofs.user.appid | 1250000000 | User `appid` |
fs.ofs.tmp.cache.dir | /data/emr/hdfs/tmp/chdfs/ | Temporary directory of the local cache |
fs.ofs.impl | com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter | The implementation class of CHDFS for `FileSystem` is fixed at `com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter`. |
fs.AbstractFileSystem.ofs.impl | com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter | The implementation class of CHDFS for `AbstractFileSystem` is fixed at `com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter`. |
4. Take action on your HDFS service by clicking. Now, the core-site.xml settings above will apply to servers in the cluster.
5. Place the latest client installation package in the path of the JAR package of the CDH HDFS service and replace the relevant information with the actual value as shown below:
cp chdfs_hadoop_plugin_network-2.0.jar /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hadoop-hdfs/
Note:
The SDK JAR file needs to be put in the same location on each server in the cluster.
Data migration
Use Hadoop Distcp to migrate your data from CDH HDFS to a COS bucket. For details, see Migrating Data Between HDFS and COS.
Using CHDFS for big data suites
MapReduce
Directions
1. Configure HDFS as instructed in Data migration and put the client installation package of COS in the correct HDFS directory.
2. On the Cloudera Manager homepage, find YARN and restart the NodeManager service (recommended). You can choose not to restart it for the TeraGen command, but must restart it for the TeraSort command because of the internal business logic.
Sample
The example below shows TeraGen and TeraSort in Hadoop standard test:
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar teragen -Dmapred.map.tasks=4 1099 ofs://examplebucket-1250000000/teragen_5/hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar terasort -Dmapred.map.tasks=4 ofs://examplebucket-1250000000/teragen_5/ ofs://examplebucket-1250000000/result14
Note:
Replace the part after
ofs:// schema with the mount point path of your CHDFS instance.Hive
MR engine
Directions
1. Configure HDFS as instructed in Data migration and put the client installation package of COS in the correct HDFS directory.
2. On the Cloudera Manager homepage, find HIVE and restart the Hiveserver2 and HiverMetastore roles.
Sample
To query your actual business data, use the Hive command line to create a location as a partitioned table on CHDFS:
CREATE TABLE `report.report_o2o_pid_credit_detail_grant_daily`(`cal_dt` string,`change_time` string,`merchant_id` bigint,`store_id` bigint,`store_name` string,`wid` string,`member_id` bigint,`meber_card` string,`nickname` string,`name` string,`gender` string,`birthday` string,`city` string,`mobile` string,`credit_grant` bigint,`change_reason` string,`available_point` bigint,`date_time` string,`channel_type` bigint,`point_flow_id` bigint)PARTITIONED BY (`topicdate` string)ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION'ofs://examplebucket-1250000000/user/hive/warehouse/report.db/report_o2o_pid_credit_detail_grant_daily'TBLPROPERTIES ('last_modified_by'='work','last_modified_time'='1589310646','transient_lastDdlTime'='1589310646')
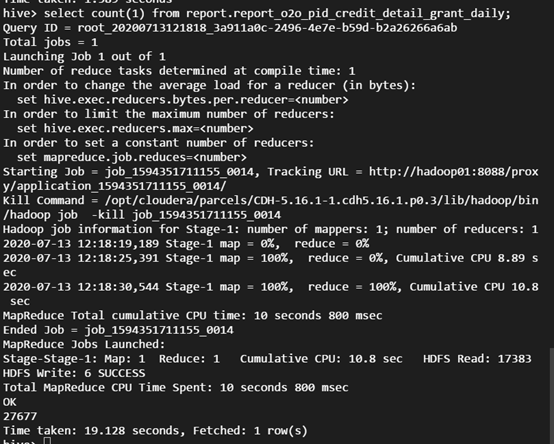
Perform a SQL query:
select count(1) from report.report_o2o_pid_credit_detail_grant_daily;
The output is as shown below:
Tez engine
You need to import the client installation package of COS as part of a Tez tar.gz file. The following example uses apache-tez.0.8.5:
Directions
1. Locate and decompress the Tez tar.gz file installed in the CDH cluster, e.g., /usr/local/service/tez/tez-0.8.5.tar.gz.
2. Put the client installation package of COS in the directory generated after decompression and recompress it to output a compressed package.
3. Upload this new file to the path as specified by tez.lib.uris, or simply replace the existing file with the same name.
4. On the Cloudera Manager homepage, find HIVE and restart hiveserver and hivemetastore.
Spark
Directions
1. Configure HDFS as instructed in Data migration and put the client installation package of COS in the correct HDFS directory.
2. Restart NodeManager.
Sample
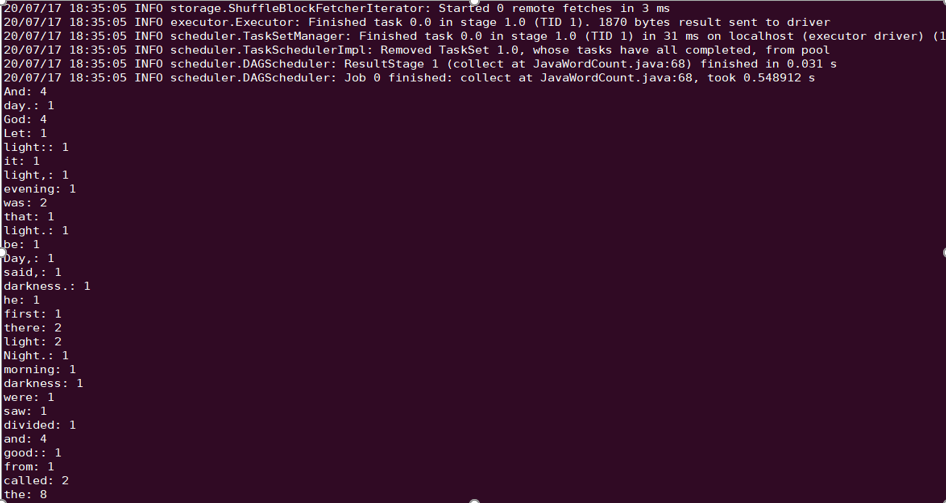
The following uses the conducted
Spark example word count test as an example.spark-submit --class org.apache.spark.examples.JavaWordCount --executor-memory 4g --executor-cores 4 ./spark-examples-1.6.0-cdh5.16.1-hadoop2.6.0-cdh5.16.1.jar ofs://examplebucket-1250000000/wordcount
The output is as shown below:
Sqoop
Directions
1. Configure HDFS as instructed in Data migration and put the client installation package of COS in the correct HDFS directory.
2. Put the client installation package of COS in the
sqoop directory, for example, /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/sqoop/.3. Restart NodeManager.
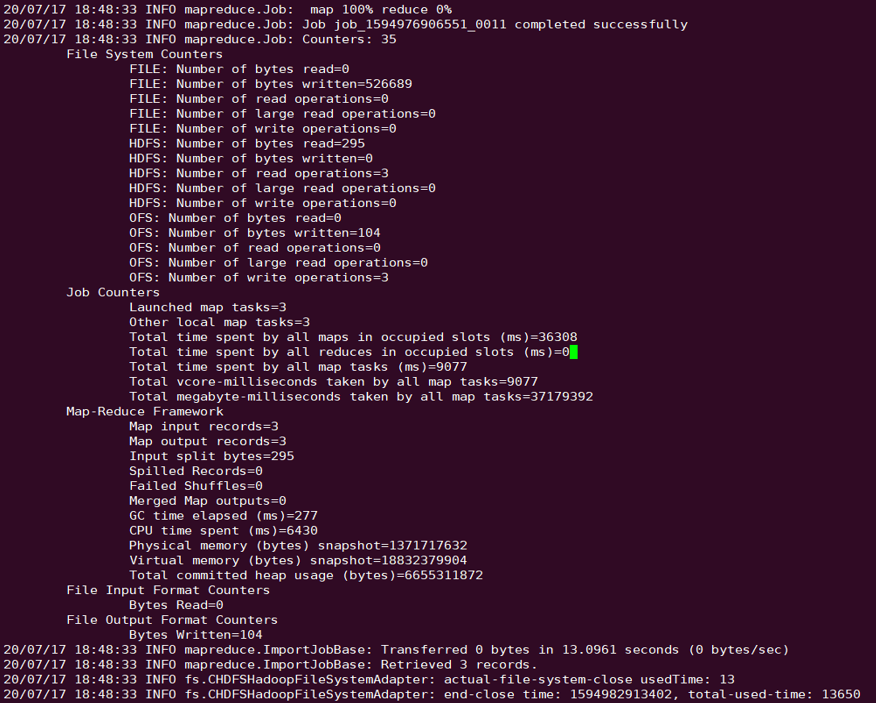
Sample
sqoop import --connect "jdbc:mysql://IP:PORT/mysql" --table sqoop_test --username root --password 123 --target-dir ofs://examplebucket-1250000000/sqoop_test
The output is as shown below:
Presto
Directions
1. Configure HDFS as instructed in Data migration and put the client installation package of COS in the correct HDFS directory.
2. Put the client installation package of COS in the
presto directory, for example, /usr/local/services/cos_presto/plugin/hive-hadoop2.3. Presto does not load the gson-2...jar JAR file (only used for COS), from Hadoop Common, so you need to manually put it into the presto directory, for example,
/usr/local/services/cos_presto/ plugin/hive-hadoop2.4. Restart HiveServer, HiveMetaStore, and Presto.
Sample
The example below queries the COS scheme table as a HIVE-created Location:
select * from chdfs_test_table where bucket is not null limit 1;
Note:
chdfs_test_table is a table with location as "ofs scheme".The output is as shown below:


 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?