- 動向とお知らせ
- 製品の説明
- 購入ガイド
- クイックスタート
- コンソールガイド
- コンソール概要
- バケットの管理
- オブジェクトの管理
- バッチ処理
- データ監視
- データ処理
- インテリジェントツールボックス使用ガイド
- データワークフロー
- アプリ統合
- ツールガイド
- プラクティスチュートリアル
- 開発者ガイド
- データレークストレージ
- データ処理
- トラブルシューティング
- よくある質問
- 用語集
- 動向とお知らせ
- 製品の説明
- 購入ガイド
- クイックスタート
- コンソールガイド
- コンソール概要
- バケットの管理
- オブジェクトの管理
- バッチ処理
- データ監視
- データ処理
- インテリジェントツールボックス使用ガイド
- データワークフロー
- アプリ統合
- ツールガイド
- プラクティスチュートリアル
- 開発者ガイド
- データレークストレージ
- データ処理
- トラブルシューティング
- よくある質問
- 用語集
概要
CDH(Cloudera's Distribution, including Apache Hadoop)は、業界で流行りのHadoopディストリビューションです。ここでは、CDH環境において、HDFSプロトコルを使用してCOS(Cloud Object Storage)バケットへアクセスし、ビッグデータの計算とストレージの分離を実現し、フレキシブルかつ低コストのビッグデータソリューションを提供する方法についてご説明します。
注意:
HDFSプロトコルを使用してCOSバケットへアクセスし、最初にメタデータアクセラレーション機能をオンにする必要があります。
現在ビッグデータコンポーネントに対するCOSのサポート状況は次のとおりです。
コンポーネント名 | CHDFSビッグデータコンポーネントのサポート状況 | サービスコンポーネントの再起動の要否 |
Yarn | サポート | NodeManagerの再起動 |
Yarn | サポート | NodeManagerの再起動 |
Hive | サポート | HiveServerおよびHiveMetastoreの再起動 |
Spark | サポート | NodeManagerの再起動 |
Sqoop | サポート | NodeManagerの再起動 |
Presto | サポート | HiveServerおよびHiveMetastoreとPrestoの再起動 |
Flink | サポート | いいえ |
Impala | サポート | いいえ |
EMR | サポート | いいえ |
セルフビルドコンポーネント | フォローアップサポート | なし |
HBase | 推奨しない | なし |
バージョンの依存関係
依存するコンポーネントのバージョンは次のとおりです。
CDH 5.16.1
Hadoop 2.6.0
利用方法
ストレージ環境の設定
1. CDH管理ページにログインします。
2. 下図に示すとおり、設定 > サービス範囲* > 高度を選択して、コードセグメントの高度な設定ページに進みます。

3. Cluster-wide Advanced Configuration Snippet(Safety Valve) for core-site.xmlのコードボックスに、COSビッグデータサービス設定を入力します。
<property><name>fs.AbstractFileSystem.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter</value></property><property><name>fs.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter</value></property><!--ローカルcacheの一時ディレクトリ。データの読み取りと書き込みの場合、メモリcacheが不足すると、ローカルディスクに書き込まれます。このパスが存在しない場合は、自動的に作成されます--><property><name>fs.ofs.tmp.cache.dir</name><value>/data/emr/hdfs/tmp/chdfs/</value></property><!--appId--><property><name>fs.ofs.user.appid</name><value>1250000000</value></property>
構成アイテム | 値 | 意味 |
fs.ofs.user.appid | 1250000000 | ユーザーappid |
fs.ofs.tmp.cache.dir | /data/emr/hdfs/tmp/chdfs/ | ローカルcacheの一時ディレクトリ |
fs.ofs.impl | com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter | chdfsのFileSystemに対する実装クラスは、com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapterに固定されます |
fs.AbstractFileSystem.ofs.impl | com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter | chdfsのAbstractFileSystemに対する実装クラスは、com.qcloud.chdfs.fs.CHDFSDelegateFSAdapterに固定されます |
4. HDFSサービスを操作し、「クライアント設定のデプロイ」をクリックします。この時点で、上記のcore-site.xmlの設定がクラスター内のマシンに更新されます。
5.最新のクライアントインストールパッケージを、CDH HDFSサービスのjarパッケージパスに配置します。実際の値に従って置き換えてください。次に例を示します。
cp chdfs_hadoop_plugin_network-2.0.jar /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hadoop-hdfs/
注意:
クラスター内の各マシンは、SDKパッケージを同じ場所に配置する必要があります。
データマイグレーション
ビッグデータスイートによるCHDFSの使用
MapReduce
操作手順
1. [データマイグレーション]#1の章に従って、HDFSの関連設定を行い、COSのクライアントインストールパッケージをHDFSの対応するディレクトリに配置します。
2. CDHシステムのホームページでYARNを見つけてNodeManagerサービスを再起動します(TeraGen コマンドを再起動する必要はありませんが、TeraSortは内部ビジネスロジックのためにNodeMangerを再起動する必要があります。NodeManagerサービスを一律に再起動することをお勧めします)。
事例
以下に、Hadoop標準テストでのTeraGenとTeraSortの例を示します。
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar teragen -Dmapred.map.tasks=4 1099 ofs://examplebucket-1250000000/teragen_5/hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar terasort -Dmapred.map.tasks=4 ofs://examplebucket-1250000000/teragen_5/ ofs://examplebucket-1250000000/result14
説明:
ofs://schemaの後ろを、ユーザーCHDFSのマウントポイントパスに置き換えてください。Hive
MRエンジン
操作手順
1. データマイグレーションの章に従って、HDFSの関連設定の配置を行い、COSのクライアントインストールパッケージをHDFSの対応するディレクトリに配置します。
2. CDHメインページでHIVEサービスを見つけ、Hiveserver2およびHiverMetastoreのロールを再起動します。
事例
例えば、あるユーザーの実際の業務の照会では、Hiveコマンドラインを実行してLocationを1つ作成し、CHDFSのパーティションテーブルとします。
CREATE TABLE `report.report_o2o_pid_credit_detail_grant_daily`(`cal_dt` string,`change_time` string,`merchant_id` bigint,`store_id` bigint,`store_name` string,`wid` string,`member_id` bigint,`meber_card` string,`nickname` string,`name` string,`gender` string,`birthday` string,`city` string,`mobile` string,`credit_grant` bigint,`change_reason` string,`available_point` bigint,`date_time` string,`channel_type` bigint,`point_flow_id` bigint)PARTITIONED BY (`topicdate` string)ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION'ofs://examplebucket-1250000000/user/hive/warehouse/report.db/report_o2o_pid_credit_detail_grant_daily'TBLPROPERTIES ('last_modified_by'='work','last_modified_time'='1589310646','transient_lastDdlTime'='1589310646')
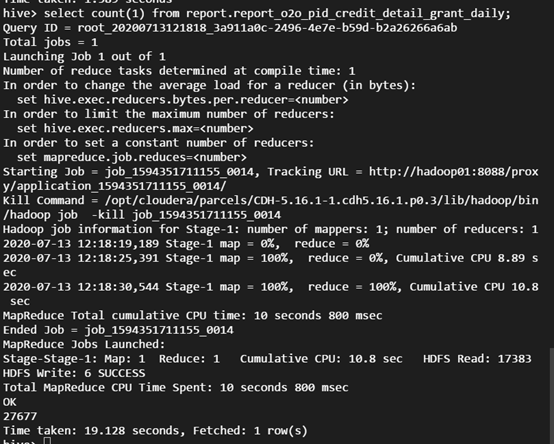
SQL照会を実行します。
select count(1) from report.report_o2o_pid_credit_detail_grant_daily;
観察の結果は次のとおりです。
Tezエンジン
Tezエンジンは、COSのクライアントインストールパッケージをTezの圧縮パッケージにインポートする必要があります。以下は、apache-tez.0.8.5を例として説明しています。
操作手順
1. CDHクラスターによってインストールされたtezパッケージを見つけて、解凍します。例:/usr/local/service/tez/tez-0.8.5.tar.gz。
2. COSのクライアントインストールパッケージを、解凍したディレクトリ下に置き、圧縮パッケージを再圧縮して出力します。
3. tez.lib.urisで指定されたパス下に、新しい圧縮パッケージをアップロードします(以前にパスがある場合は、直接置き換えてください)。
4. CDHメインページでHIVEを見つけて、hiveserverおよびhivemetastoreを再起動します。
Spark
操作手順
1. データマイグレーションの章に従って、HDFSの関連設定の配置を行い、COSのクライアントインストールパッケージをHDFSの対応するディレクトリに配置します。
2. NodeManagerサービスを再起動します。
事例
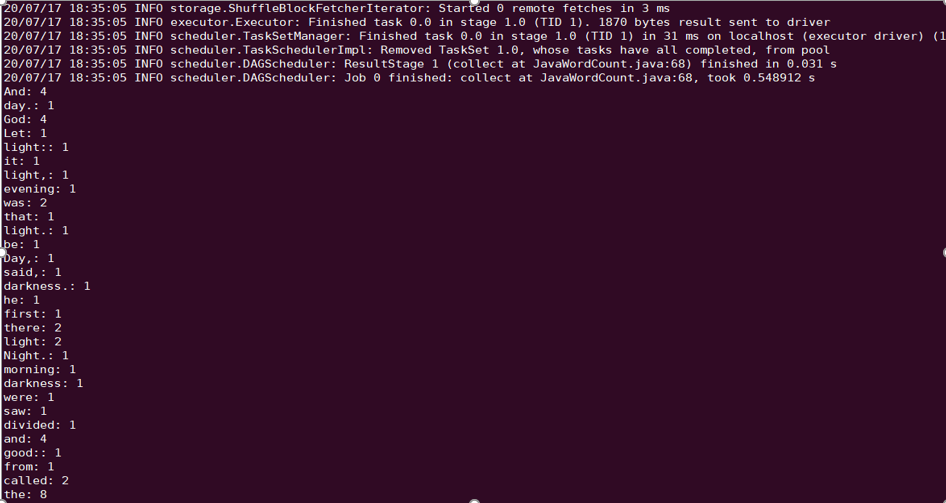
例として、Spark example word countテストの実施を取り上げます。
spark-submit --class org.apache.spark.examples.JavaWordCount --executor-memory 4g --executor-cores 4 ./spark-examples-1.6.0-cdh5.16.1-hadoop2.6.0-cdh5.16.1.jar ofs://examplebucket-1250000000/wordcount
実行結果は次のとおりです。
Sqoop
操作手順
1. データマイグレーションの章に従って、HDFSの関連設定の配置を行い、COSのクライアントインストールパッケージをHDFSの対応するディレクトリに配置します。
2. COSのクライアントインストールパッケージもsqoopディレクトリに配置する必要があります(例:/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/sqoop/)。
3. NodeManagerサービスを再起動します。
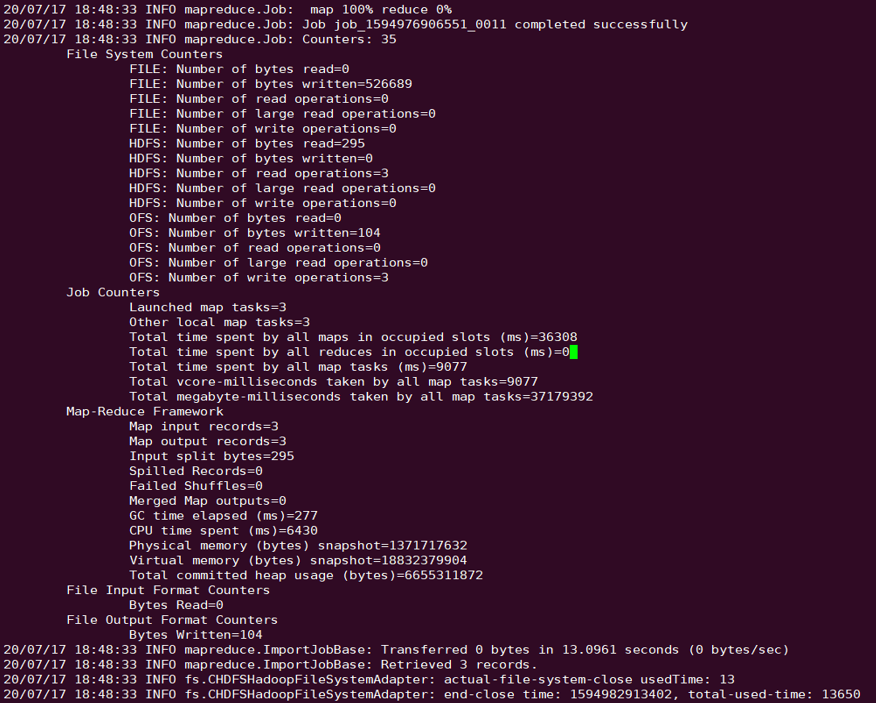
事例
sqoop import --connect "jdbc:mysql://IP:PORT/mysql" --table sqoop_test --username root --password 123 --target-dir ofs://examplebucket-1250000000/sqoop_test
実行結果は次のとおりです。
Presto
操作手順
1. データマイグレーションの章に従って、HDFSの関連設定の配置を行い、COSのクライアントインストールパッケージをHDFSの対応するディレクトリに配置します。
2. COSのクライアントインストールパッケージもprestoディレクトリ下に配置する必要があります(例:/usr/local/services/cos_presto/plugin/hive-hadoop2)。
3. prestoはhadoop commonのgson-2...jarをロードしないため、gson-2...jarもprestoディレクトリ下に配置する必要があります(例: /usr/local/services/cos_presto/plugin/hive-hadoop2、COSのみがgsonに依存します)。
4. HiveServer、HiveMetaStoreおよびPrestoサービスを再起動します。
事例
例として、HIVEによってLocationをCOSとして作成したテーブルの照会を取り上げます。
select * from chdfs_test_table where bucket is not null limit 1;
説明:
chdfs_test_tableはlocationがofs schemeのテーブルです。
確認の結果は次のとおりです。


 はい
はい
 いいえ
いいえ
この記事はお役に立ちましたか?