COS offers the metadata acceleration feature to provide high-performance file system capabilities. Metadata acceleration leverages the powerful metadata management feature of Cloud HDFS (CHDFS) at the underlying layer to allow using file system semantics for COS access. The designed system metrics can reach a bandwidth of up to 100 GB/s, over 100,000 queries per second (QPS), and a latency of milliseconds. Buckets with metadata acceleration enabled can be widely used in scenarios such as big data, high-performance computing, machine learning, and AI. For more information on metadata acceleration, see Metadata Acceleration Overview.
Benefits of HDFS Access
In the past, big data access based on COS was mainly implemented through the Hadoop-COS tool. The tool internally adapts Hadoop Compatible File System (HCFS) APIs to COS RESTful APIs to access data in COS. The difference in metadata organization between COS and file systems leads to varying metadata operation performance, which affects the big data analysis performance. Buckets with metadata acceleration enabled are fully compatible with the HCFS protocol and can be accessed directly by using native HDFS APIs. This saves the overheads of converting the HDFS protocol to COS protocol and provides native HDFS features such as efficient directory rename (as an atomic operation), file atime, and mtime update, efficient directory DU statistics, and POSIX ACL permission support.
Creating Bucket and Configuring the HDFS Protocol
1. Create a COS bucket and enable metadata acceleration for it.
After the bucket is created, go to the File List page of the bucket, where you can upload and download files.
2. On the left sidebar, click Performance Configuration > Metadata Acceleration, and you can see that metadata acceleration is enabled.
When you create a bucket that requires metadata acceleration to be enabled, you need to perform the corresponding authorization operation as prompted. After you click Authorize, the HDFS protocol will be automatically enabled, and you can see the default bucket mount target information.
Note:
If the system indicates that the corresponding HDFS file system is not found, submit a ticket.
3. In the HDFS Permission Configuration column, click Add Permission Configuration.
4. Select the VPC where the computing cluster resides in the VPC Name column, enter the IP address or range that needs to be opened in the Node IP column, select Can edit or Can view as the access type, and click Save.
Note:
The HDFS permission configuration is different from the native COS permission system. If you use HDFS to access a COS bucket, we recommend you configure HDFS permission to authorize servers in a specified VPC to access the COS bucket and enjoy the same permission experience as that of native HDFS.
Configuring Computing Cluster to Access COS
Environmental dependency
Dependency
chdfs-hadoop-plugin
COSN (hadoop-cos)
cos_api-bundle
Version
≥ v2.7
≥ v8.1.5
Make sure that the version matches the COSN version as listed in tencentyun/hadoop-cos.
The EMR environment has already been seamlessly integrated with COS, and you only need to complete the following steps:
1. Find an EMR server and run the following command on it to check whether the package versions in the folders of the services required by the EMR environment meet the requirements for environment dependencies.
find / -name "chdfs*"
find / -name "temrfs_hadoop*"
Make sure that the versions of two JAR packages in the search results meet the above requirements for environment dependencies.
2. If the chdfs-hadoop-plugin needs to be updated, perform the following steps:
Download the script files of the updated JAR package at:
Run the following command to put the two scripts in the /root directory of the server to add the execution permission to update_cos_jar.sh:
sh update_cos_jar.sh https://hadoop-jar-beijing-1259378398.cos.ap-beijing.myqcloud.com/hadoop_plugin_network/2.7
Replace the parameter with the bucket in the corresponding region, such as https://hadoop-jar-guangzhou-1259378398.cos.ap-guangzhou.myqcloud.com/hadoop_plugin_network/2.7 in Guangzhou region.
Perform the above steps on each EMR node until all JAR packages are replaced.
3. If the hadoop-cos package or cos_api-bundle package needs to be updated, perform the following steps:
Replace /usr/local/service/hadoop/share/hadoop/common/lib/hadoop-temrfs-1.0.5.jar with temrfs_hadoop_plugin_network-1.1.jar.
Add the following configuration items to core-site.xml:
emr.temrfs.download.version=2.7.5-8.1.5-1.0.6 (Replace 2.7.5 with your Hadoop version and replace 8.1.5 with the version of the required hadoop-cos package (which must be 8.1.5 or later). The cos_api-bundle version will be automatically adapted.)
Modify the configuration item fs.cosn.impl=com.qcloud.emr.fs.TemrfsHadoopFileSystemAdapter in core-site.xml.
4. Configure core-site.xml in the EMR console by adding new configuration items fs.cosn.bucket.region and fs.cosn.trsf.fs.ofs.bucket.region to specify the COS region where the bucket resides, such as ap-shanghai.
Note:
fs.cosn.bucket.region and fs.cosn.trsf.fs.ofs.bucket.region are required to specify the COS region where the bucket resides, such as ap-shanghai.
5. Restart resident services such as YARN, Hive, Presto, and Impala.
Self-built Hadoop/CDH environments
1. In a self-built environment as described in Install CDH, you need to download three JAR packages meeting the version requirements in the environment dependencies.
2. Place the installation packages in the classpath path of each server in the Hadoop cluster, such as /usr/local/service/hadoop/share/hadoop/common/lib/ (which may vary by component).
3. Modify the hadoop-env.sh file under the $HADOOP_HOME/etc/hadoop directory by adding the COSN JAR package to your Hadoop environment variables as follows:
<!-- API key information of the account, which can be viewed in the [CAM console](https://console.tencentcloud.com/capi). -->
<property>
<name>fs.cosn.userinfo.secretId</name>
<value>XXXXXXXXXXXXXXXXXXXXXXXX</value>
</property>
<!-- API key information of the account, which can be viewed in the [CAM console](https://console.tencentcloud.com/capi). -->
<property>
<name>fs.cosn.userinfo.secretKey</name>
<value>XXXXXXXXXXXXXXXXXXXXXXXX</value>
</property>
<!-- Configure the account's `appid` -->
<property>
<name>fs.cosn.trsf.fs.ofs.user.appid</name>
<value>125XXXXXX</value>
</property>
<!-- Local temporary directory, which is used to store temporary files generated during execution. -->
<property>
<name>fs.cosn.trsf.fs.ofs.tmp.cache.dir</name>
<value>/tmp</value>
</property>
5. Restart resident services such as YARN, Hive, Presto, and Impala.
Verifying environment
After all environment configuration steps are completed, you can verify the environment in the following ways:
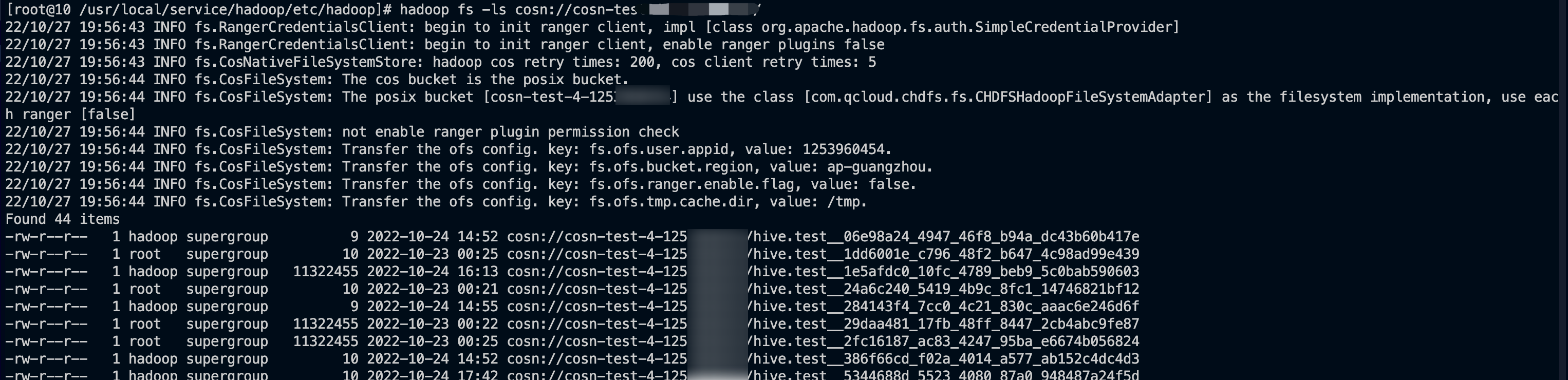
Use the Hadoop command line on the client to check whether mounting is successful.
Log in to the COS console to check whether the files and directories in the bucket file list are consistent.
Ranger Permission Configuration
By default, the native POSIX ACL mode is adopted for authentication for the HDFS protocol. If you need to use Ranger authentication, configure as follows:
EMR environment
1. The EMR environment has integrated the COS Ranger Service, so you can select it when purchasing an EMR cluster.
2. In the HDFS authentication mode of the HDFS protocol, select the Ranger authentication mode and configure the corresponding address information of Ranger.
Add the new configuration item fs.cosn.credentials.provider and set it to org.apache.hadoop.fs.auth.RangerCredentialsProvider.
2. In the HDFS authentication mode of the HDFS protocol, select the Ranger authentication mode and configure the corresponding address information of Ranger.
Add the new configuration item fs.cosn.credentials.provider and set it to org.apache.hadoop.fs.auth.RangerCredentialsProvider.
Others
In a big data scenario, you can access a bucket with metadata acceleration enabled over the HDFS protocol in the following steps:
3. By default, the native POSIX ACL mode is adopted for authentication. If you need to use Ranger authentication, see COS Ranger Permission System Solution.