Tencent Kubernetes Engine
- Release Notes and Announcements
- Release Notes
- Announcements
- Security Vulnerability Fix Description
- Release Notes
- Kubernetes Version Maintenance
- Runtime Version Maintenance Description
- Product Introduction
- Quick Start
- TKE General Cluster Guide
- Purchase a TKE General Cluster
- Permission Management
- Controlling TKE cluster-level permissions
- TKE Kubernetes Object-level Permission Control
- Cluster Management
- Images
- Worker node introduction
- Normal Node Management
- Native Node Management
- Purchasing Native Nodes
- Supernode management
- Purchasing a Super Node
- Registered Node Management
- Memory Compression Instructions
- GPU Share
- qGPU Online/Offline Hybrid Deployment
- Kubernetes Object Management
- Workload
- Configuration
- Auto Scaling
- Service Management
- Ingress Management
- CLB Type Ingress
- API Gateway Type Ingress
- Storage Management
- Use File to Store CFS
- Use Cloud Disk CBS
- Add-On Management
- CBS-CSI Description
- Network Management
- GlobalRouter Mode
- VPC-CNI Mode
- Static IP Address Mode Instructions
- Cilium-Overlay Mode
- OPS Center
- Audit Management
- Event Management
- Monitoring Management
- Log Management
- Using CRD to Configure Log Collection
- Backup Center
- TKE Serverless Cluster Guide
- Purchasing a TKE Serverless Cluster
- TKE Serverless Cluster Management
- Super Node Management
- Kubernetes Object Management
- OPS Center
- Log Collection
- Using a CRD to Configure Log Collection
- Audit Management
- Event Management
- TKE Registered Cluster Guide
- Registered Cluster Management
- Ops Guide
- TKE Insight
- TKE Scheduling
- Job Scheduling
- Native Node Dedicated Scheduler
- Cloud Native Service Guide
- Cloud Service for etcd
- Version Maintenance
- Cluster Troubleshooting
- Practical Tutorial
- Cluster
- Serverless Cluster
- Mastering Deep Learning in Serverless Cluster
- Scheduling
- Security
- Service Deployment
- Proper Use of Node Resources
- Network
- DNS
- Self-Built Nginx Ingress Practice Tutorial
- Logs
- Monitoring
- OPS
- DevOps
- Construction and Deployment of Jenkins Public Network Framework Appications based on TKE
- Auto Scaling
- KEDA
- Containerization
- Microservice
- Cost Management
- Hybrid Cloud
- Fault Handling
- Pod Status Exception and Handling
- Pod exception troubleshooter
- API Documentation
- Making API Requests
- Elastic Cluster APIs
- Resource Reserved Coupon APIs
- Cluster APIs
- Third-party Node APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- Cloud Native Monitoring APIs
- Super Node APIs
- TKE API 2022-05-01
- Making API Requests
- Node Pool APIs
- FAQs
- TKE General Cluster
- TKE Serverless Cluster
- About OPS
- Service Agreement
- User Guide(Old)

DocumentationTencent Kubernetes EnginePractical TutorialSchedulingIncreasing Cluster Packing Rate via Native Nodes
Increasing Cluster Packing Rate via Native Nodes

Last updated: 2024-12-24 15:50:21
Overview
Native Node-specific schedulers can effectively solve the problem of high packing rate but low utilization rate in the cluster. By using the node amplification capability of the native node-specific scheduler, the packing rate of nodes can be improved, thereby increasing the overall resource utilization rate without any modification or restart for the business.
However, how to determine the configuration of the amplification factor? How to use the corresponding thresholds in a conjunction manner to ensure the stability of the amplified nodes? These issues directly affect the stability and effectiveness of a feature. Additionally, what are the specific benefits and risks brought by the amplification capability?
Pros and Cons of Native Node Amplification
Benefits | Risks |
1. Improvement of resource utilization rate: By virtual amplification, the computational and storage capacity of the nodes can be utilized more effectively, preventing idle resources after being occupied. This helps in cost reduction, thus improving the overall running efficiency. 2. Zero-cost usage of business: With the native node amplification capability, the schedulable capacity of the nodes is adjusted with zero invasion, zero modification, and zero migration to the business. This helps rapid testing of new features and their application in the actual production environment. | 1. Resource competition: If all the containers running on the nodes attempt to use the over-allocated resources, it may lead to resource competition, thus decreasing system performance and stability. 2. Beware of over-amplification: If the actual demands of the workloads on the nodes exceed the available resources, it may lead to business impact or even cause a system crash and downtime. |
This document provides the best practices for utilizing the amplification capability of native nodes from a first-person perspective, helping you give the amplification capability into full play while reducing feature risks. The best practices mainly include the following five steps:
Step 1: Locate the typical nodes that need amplification, i.e., nodes with a high packing rate but a low utilization rate.
Step 2: Determine the target utilization rate of the nodes. Only by clarifying the target can the configuration value with a reasonable amplification factor be determined.
Step 3: Determine the amplification factor and threshold based on the node target utilization rate and current status.
Step 4: Select the target nodes, and schedule the Pods on these nodes to the amplified nodes.
Step 5: After the rescheduled Pods in Step 4 run, you can deactivate the target nodes.
Operation Steps
Step 1: Observing the Current Packing Rate and Utilization Rate of Nodes
Note:
The Packing Rate and the Utilization Rate are defined as follows:
Packing Rate: The sum of the Requests for all Pods on a node divided by the actual capacity of the node.
Utilization Rate: The sum of the actual usage for all Pods on a node divided by the actual capacity of the node.
Tencent Kubernetes Engine (TKE) provides TKE Insight, making it easy for you to directly view the packing rate and utilization rate trend charts. For more details, refer to Node Map.
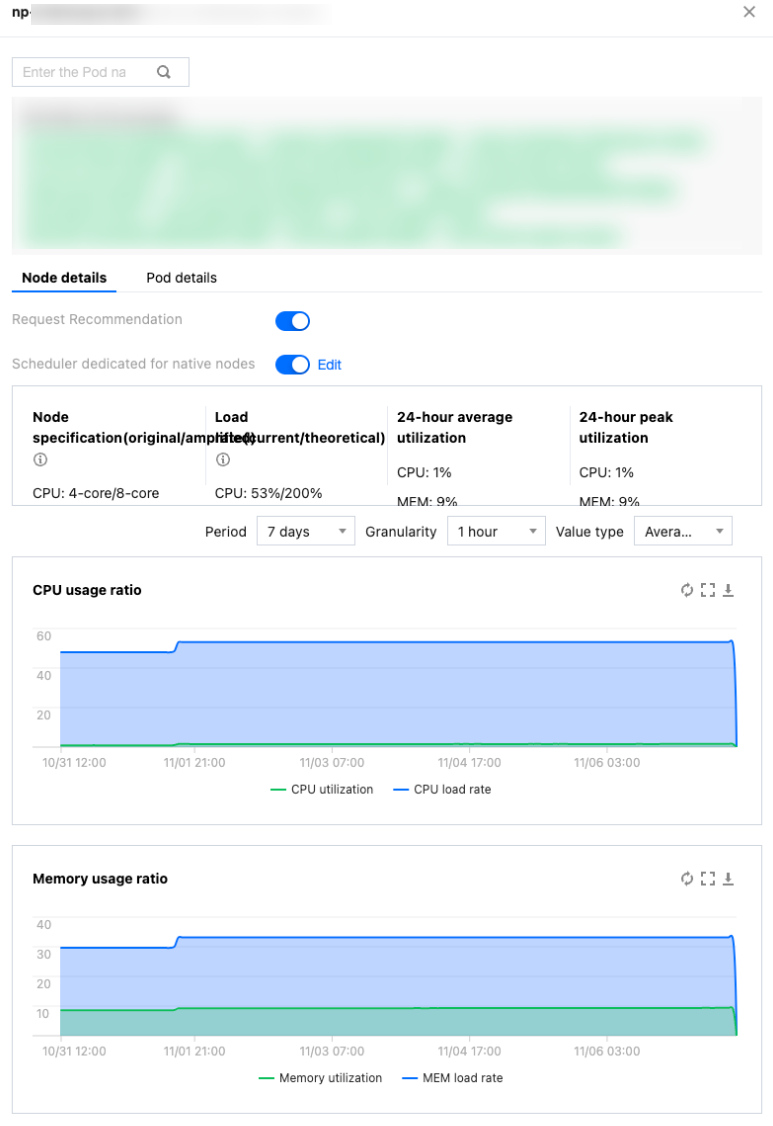
The relationship of the packing rate and the utilization rate is analyzed as follows:
1. High Packing Rate and High Utilization Rate
For example:The packing rate is over 90%, the CPU utilization rate is over 50%, or the memory utilization rate is over 90%.
Description: The node resources are reasonably used, and it is safe and stable integrally. However, be aware that the node memory may encounter OOM (Out of Memory) situations.
Suggestion: It is best to configure the runtime threshold of 90% to prevent the node stability risk.
2. High Packing Rate and Low Utilization Rate
For example: The packing rate is over 90%, the CPU utilization rate is below 50% (such as 10%), or the memory utilization rate is below 90% (such as 30%).
Description: There is an over-configuration for the Pod on the node, that is, the resource application amount far exceeds the actual usage. Since the packing rate is already high, it is impossible to schedule more Pods, resulting in the inability to improve the node utilization rate.
Suggestion: Through virtual amplification of native node specifications, allow the packing rate of the node to exceed the cap of 100%, thereby scheduling more Pods and improving the node utilization rate.
3. Low Packing Rate and High Utilization Rate
For example: The packing rate is below 90% (such as 50%), the CPU utilization rate is over 50%, or the memory utilization rate is over 90%.
Description: There is a prevalent overselling scenario among the Pods on the node, that is, the Limit (resource cap) exceeds the Request (resource demand), or the Pod is not configured with Request.
Suggestion: Pods configured in this way have lower QoS (Quality of Service) levels and may restart or even be rescheduled at a high load of the node. It is necessary to check whether the Pods so configured are low-priority Pods. Additionally, it is recommended to configure the runtime threshold of 90% to prevent the node stability risk.
4. Low Packing Rate and Low Utilization Rate
For example: The packing rate is below 90% (such as 50%), the CPU utilization rate is below 50% (such as 10%), or the memory utilization rate is below 90% (such as 30%).
Description: The node is not fully utilized.
Suggestion: More Pods can be scheduled onto this node, or the Pods on this node can be evicted to other nodes before deactivating this node. Additionally, you can consider replacing it with a smaller node.
Step 2: Determining the Target Utilization Rate of the Nodes
During the setting of a reasonable node amplification factor and threshold, it is necessary to determine the target utilization rate of the node to ensure a high utilization rate while preventing node anomalies. The examples involving multiple utilization rate indicators are shown as below:
CPU utilization rate of the node: Based on Tencent's internal experience with large-scale on-cloud business implementation, it is an ideal target to set the peak CPU utilization rate of the node as 50%.
Memory utilization rate of the node: By analyzing the scale of millions of businesses, it is found that the memory utilization rate of the node is generally high and fluctuates less than CPU. Therefore, it is an ideal target to set the peak memory utilization rate of the node as 90%.
Based on actual conditions and business needs, you can set the target utilization rate of the node based on these indicators to maintain stability and efficient utilization of the node during amplification.
Step 3: Determining the Amplification Factor and Threshold
After understanding the current utilization status and target of the node, the amplification factor and threshold can be determined to achieve the target utilization rate. The amplification factor indicates how many times the node capacity can be amplified. The examples are shown as below:
Assume that the current utilization rate is 20% and the target utilization is 40%. This means that one more times of businesses can be added to the node, therefore, the node amplification factor needs to be configured as 2.
Assume that the current utilization rate is 15% and the target utilization is 45%. This means that three more times of businesses can be added to the node, therefore, the node amplification factor needs to be configured as 3.
Note:
The peak value is generally used to view the current utilization rate, ensuring that enough resources are available during business peaks.
The calculation formula for the amplification factor is as follows:
CPU Amplification Factor = Target Utilization Rate of CPU/Current Utilization Rate of CPU
Memory Amplification Factor = Target Utilization Rate of Memory/Current Utilization Rate of Memory
The current peak utilization rate of the CPU is 10%, the peak utilization rate of the memory is 47%. Assume that the target utilization rate of the CPU is 50% and the target utilization rate of the memory is 90%.
Then the CPU amplification factor is 5 (please note not to set it too high to avoid a situation where the CPU is sufficient but the node memory has a bottleneck), and the amplification factor of the memory is 2.
After determining the target utilization rate, you can set the threshold based on the target. For example:
Scheduling threshold: It is recommended to set it less than or equal to the target utilization rate to allow nodes that haven't reached the target utilization rate to continuously scheduling Pods. Setting it too high may cause node overload. For example, if the target utilization rate of the CPU is 50%, you can set the scheduling threshold of the CPU as 40%.
Runtime threshold: It is recommended to set it greater than or equal to the target utilization rate to prevent a high utilization rate from causing node overload. For example, if the target utilization rate of the CPU is 50%, you can set the runtime threshold of the CPU as 60%.
Step 4: Scheduling Pods to the Amplified Nodes
Only by scheduling Pods to the amplified nodes can you improve the resource utilization rate of the node. There are two ways to achieve this:
1. Cordon other nodes: Schedule new Pods only to the amplified nodes to prevent other nodes from receiving new Pod scheduling requests.
2. Use the tag selector capability of the Workload: Use the tag selector to schedule the Pods specifically to the amplified nodes.
Suggestion:
During the node amplification, it is best to choose those nodes that are easy to deactivate, and reschedule the Pods on these nodes to the amplified nodes. These nodes may include:
Nodes with a small number of Pods.
Pay-as-you-go nodes.
About-to-expire nodes with monthly subscriptions.
If you specify the CPU and memory amplification factor for the node, you can confirm it by checking the annotations of:
expansion.scheduling.crane.io/cpu and expansion.scheduling.crane.io/memory related to the amplification factor. The examples are shown as below:kubectl describe node 10.8.22.108...Annotations: expansion.scheduling.crane.io/cpu: 1.5 # CPU amplification factorexpansion.scheduling.crane.io/memory: 1.2 # Memory amplification factor...Allocatable:cpu: 1930m # Original schedulable resource amount of the nodeephemeral-storage: 47498714648hugepages-1Gi: 0hugepages-2Mi: 0memory: 1333120Kipods: 253...Allocated resources:(Total limits may be over 100 percent, i.e., overcommitted.)Resource Requests Limits-------- -------- ------cpu 960m (49%) 8100m (419%) # Occupancy of Request and Limit for this nodememory 644465536 (47%) 7791050368 (570%)ephemeral-storage 0 (0%) 0 (0%)hugepages-1Gi 0 (0%) 0 (0%)hugepages-2Mi 0 (0%) 0 (0%)...
Notes:
The original schedulable amount of the CPU for the current node is 1930m, and the total CPU request for all Pods on the node is 960m. Under normal circumstances, the maximum schedulable CPU resource for this node is 970m (1930m - 960m). However, through virtual amplification, the schedulable amount of the CPU for this node is increased to 2895m (1930m * 1.5), leaving an actual schedulable CPU resource of 1935m (2895m - 960m).
At this time, if you create a workload with only one Pod requesting 1500m of CPU, this Pod cannot be scheduled onto this node without the node amplification capability.
apiVersion: apps/v1kind: Deploymentmetadata:namespace: defaultname: test-schedulerlabels:app: nginxspec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:nodeSelector: # Specify node schedulingkubernetes.io/hostname: 10.8.20.108 # Specify the use of the native nodes in the example.containers:- name: nginximage: nginx:1.14.2resources:requests:cpu: 1500m # The application amount is greater than the schedulable amount before amplification but less than the schedulable amount after amplification.ports:- containerPort: 80
The workload is successfully created:
% kubectl get deploymentNAME READY UP-TO-DATE AVAILABLE AGEtest-scheduler 1/1 1 1 2m32s
Check the resource occupancy of the node again:
kubectl describe node 10.8.22.108...Allocated resources:(Total limits may be over 100 percent, i.e., overcommitted.)Resource Requests Limits-------- -------- ------cpu 2460m (127%) 8100m (419%) # Occupancy of Request and Limit for this node. It can be seen that, the total Request exceeds the original schedulable amount. The node specification amplification is successful.memory 644465536 (47%) 7791050368 (570%)ephemeral-storage 0 (0%) 0 (0%)hugepages-1Gi 0 (0%) 0 (0%)hugepages-2Mi 0 (0%) 0 (0%)
Step 5: Removing Redundant Nodes
On the node selected in Step 4, after all non-DaemonSet Pods on the node are removed, this node can be removed and deleted, thus carrying the same business volume with fewer nodes.
In this way, you can organize Pods in the cluster. For example, suppose the cluster has 20 native nodes and 20 ordinary nodes, all with the same specifications, and the overall resource utilization rate is 10% for the CPU and 40% for the memory. By double the CPU and memory of the 20 native nodes, you can migrate the Pods on the 20 ordinary nodes onto the native nodes. This will increase the resource utilization rate of the native nodes to 20% for the CPU and 80% for the memory. At the same time, there will be no Pods on the ordinary nodes, so these ordinary nodes can be removed from the cluster, reducing the node scale by half.
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No