This document describes how the parallel query feature works.
How parallelism works
TDSQL-C for MySQL offers the parallel query feature to push complete data partitions down to different threads for parallel computing, aggregate the result in the user thread, and return it to you. This greatly improves the query efficiency.
Below is an example of how parallel query works.
Note:
MySQL/InnoDB uses segmentation and paging physical storage, with a page being a partition. Here, a row is used to represent a partition.
Specify the t table for grouped and aggregated query as follows.
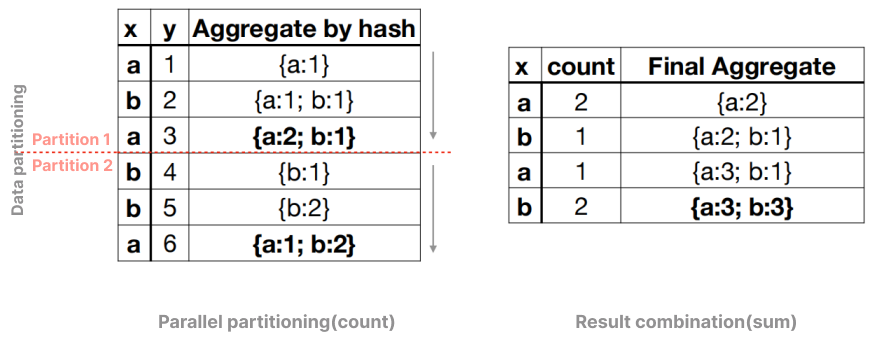
select x, count(*) from t group by x;
The hash aggregate algorithm (iterative evaluation) is performed as follows. When each row is iterated, the group aggregate status is updated. After all data rows are iterated, the group aggregate result is obtained. If the aggregate status update is fixed, then the time complexity of the algorithm is O(n).
If k threads are used to accelerate the query (here, k is 2), it is better to first divide the data table into k * p partitions (here, p is 1). In this way, each thread can process p partitions to generate an tentative local result. Then, local results are combined in the same user thread to get the final result.
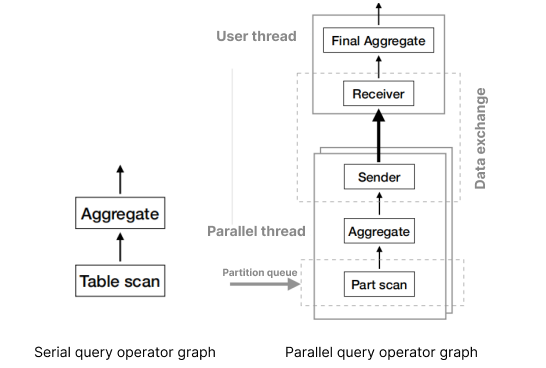
Based on the above example, we can get the following operator graphs of serial and parallel queries.
As can be seen, in parallel query, data falls into different partitions that do not overlap based on parallelism. This process is called data partitioning.
After data is partitioned, special operations in the original plan are split, which is called task splitting. Then, data is scanned and executed in multiple worker threads (parallel threads), which aggregate the results to the user thread through the exchange operator. This process depends on data exchange.
After data exchange, the user thread completes the aggregation and outputs the complete result. Here, the user thread is responsible for data partitioning and task splitting and also works as the coordinator (also known as the coordinator thread) for the parallel execution of subtasks by worker threads. In addition, it combines the results and sends the final result to you. Worker threads execute parallel subtasks and exchange intermediate results through the data channel.
The core elements of parallel query can be concluded as follows:
Data partitioning: Data in the original table is partitioned and read by partition.
Task splitting: Special operations in the original plan are split into "local-global" segments. In addition, the data exchange operator is inserted to support cross-thread data transfer.
Data exchange: Data is transferred among different threads.
Parallel query process
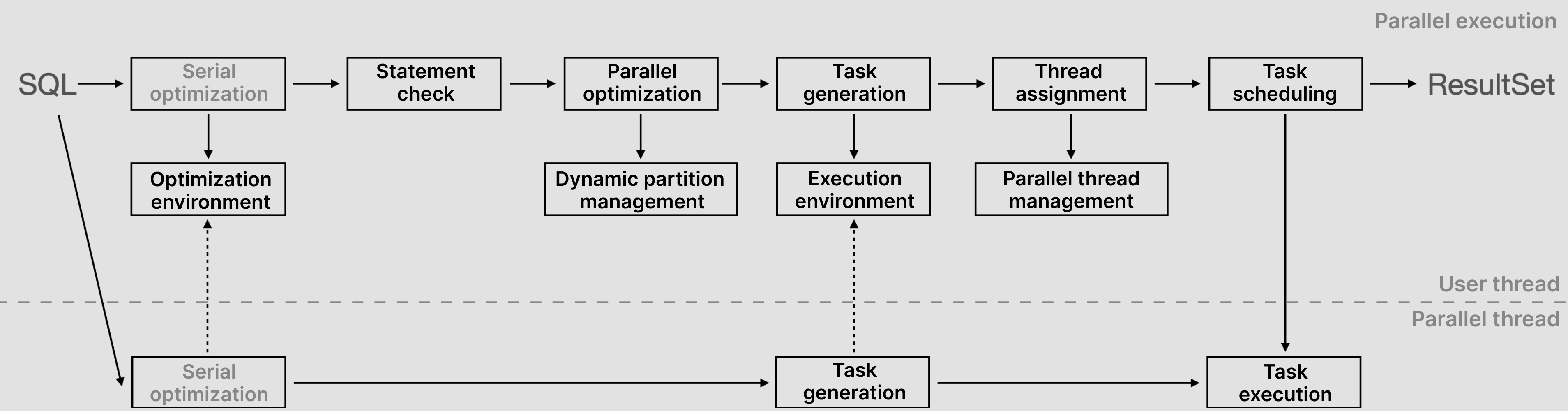
Based on the above principle, TDSQL-C for MySQL implements a complete parallel query plan to expand serial processing as shown below.
In a traditional MySQL serial process, serial optimization is first performed on a SQL statement to output a serial execution plan. Then, the iterative model is executed to output the result. The efficiency is low throughout the process. To implement parallel query, TDSQL-C for MySQL has redesigned SQL statement processing:
1. In parallel query, all processes are performed by the user thread and worker threads (parallel threads). After a SQL statement starts, the user thread analyzes it against the parameters in the optimizer and generate an execution plan. You can simply consider the SQL optimization environment as a highly abstract deterministic compute module, with the SQL and optimization environment as the input and the execution plan as the output. For the same input, the optimization path and output are the same, ensuring the accuracy of the result.
2. After the execution plan is generated, the statement check starts. At this point, the computing layer checks whether the statement meets the criteria for parallel query. The statement-level check includes dynamic query, data isolation level check (RC or RR), and execution cost check. At the execution plan level, the iteration operator and function are checked for parallel support. If the criteria are not met, the statement goes back to serial execution; otherwise, it proceeds to parallel query and optimization. For more information, see Supported Statement Scenarios and Restricted Scenarios.
3. During parallel optimization, the computing layer partitions the data in the target table as needed and splits the tasks of aggregation or sorting to be executed by worker threads. As optimization involves data partitioning, TDSQL-C for MySQL leverages the dynamic partition management capability to balance data in each thread, so as to execute multiple tasks in each thread and minimize data skew.
4. Then, the computing layer generates parallel query tasks, pushes them down to worker threads as task replicas, and configures the number of tasks on worker threads based on the configured parameters. Then, worker threads start working in parallel and push their results up to the user thread, which eventually returns the aggregated result to you. At this point, the parallel query of a statement ends.
In summary, after receiving the SQL statement, the user thread performs common operations such as parsing, verification, and optimization and generates a serial execution plan. In addition, it searches for the information (optimization environment) necessary for optimization. Then, it analyzes the serial execution plan (statement check, i.e., check of the operator tree, execution environment, and optimization cost) and decides whether to start parallel optimization. During parallel optimization, the serial operator tree is divided into several coarse-grained tasks, the algorithm is determined for data exchange between parallel tables (dynamic partitions) and tasks, and a task dependency graph is drawn. At this point, the user thread is ready, which means execution can start after enough worker threads are obtained from the available thread manager. After worker threads complete their work, data is exchanged to the user thread for aggregation. Then, the final result is returned to you.
In the above process, TDSQL-C for MySQL provides various parameters to adjust parallel query capabilities and control the resource load caused by the statement execution cost and parallel query. It also offers many metrics for you to monitor parallel query information in real time. For more information, see Enabling/Disabling Parallel Query.