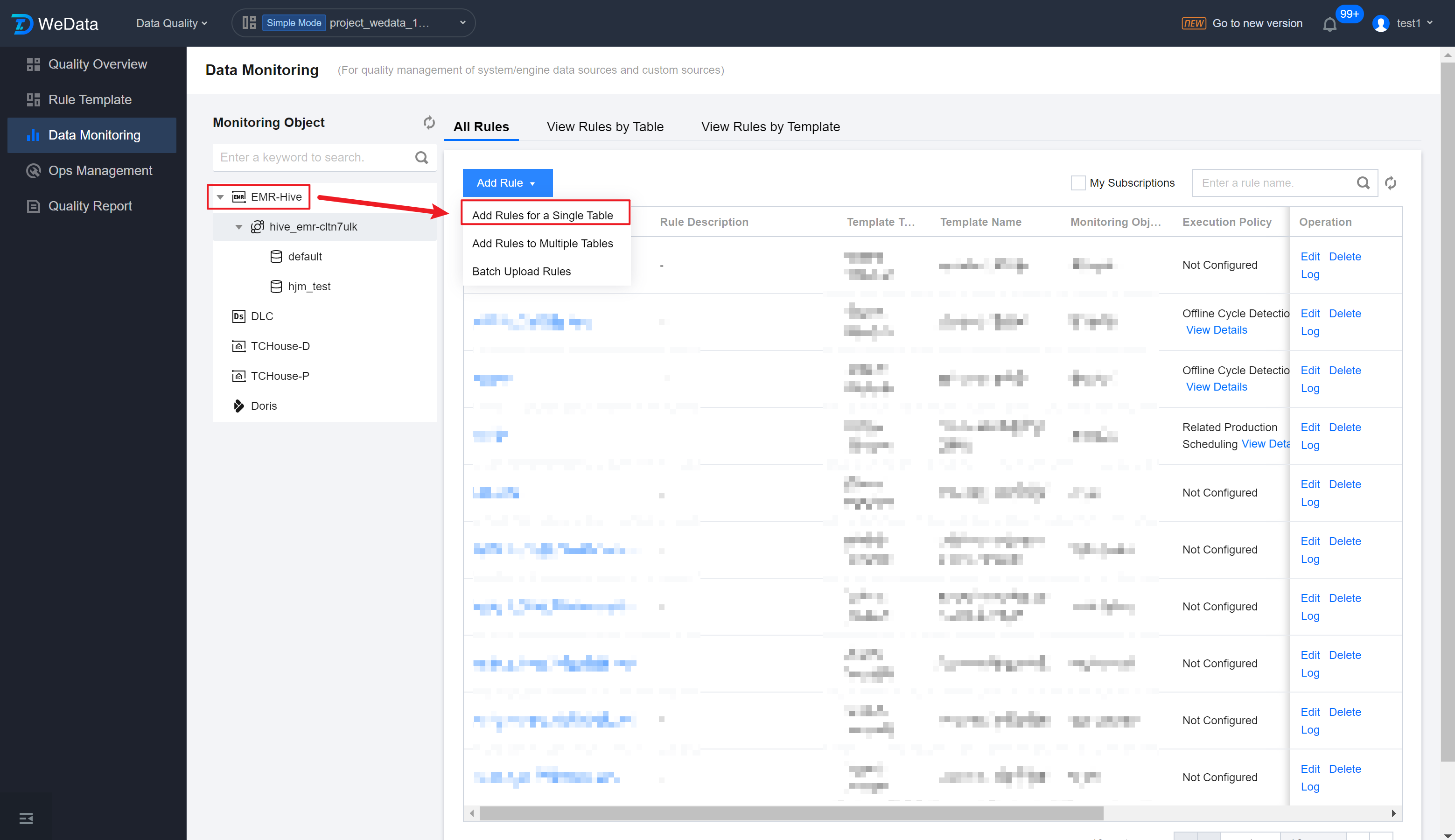
Enter the Data Quality > Data Monitoring > EMR interface, click Add Rules for a Single Table, to start adding a new quality rule.
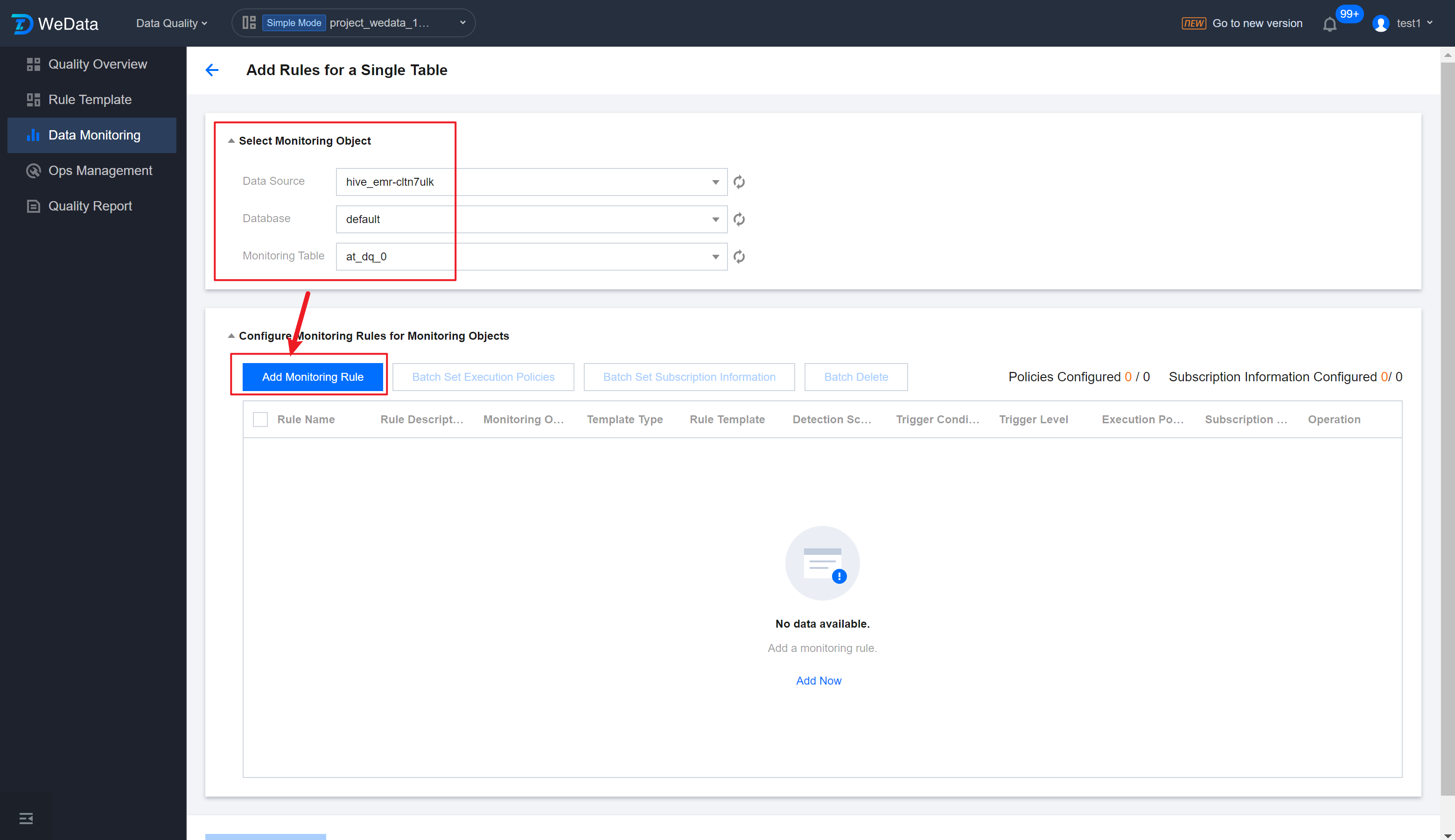
Step 2: Select Monitoring Object
Enter the Add Rules for a Single Table interface, select the data source, database, and monitoring table in sequence, click Add Monitoring Rule.
Step 3: Add Monitoring Rule
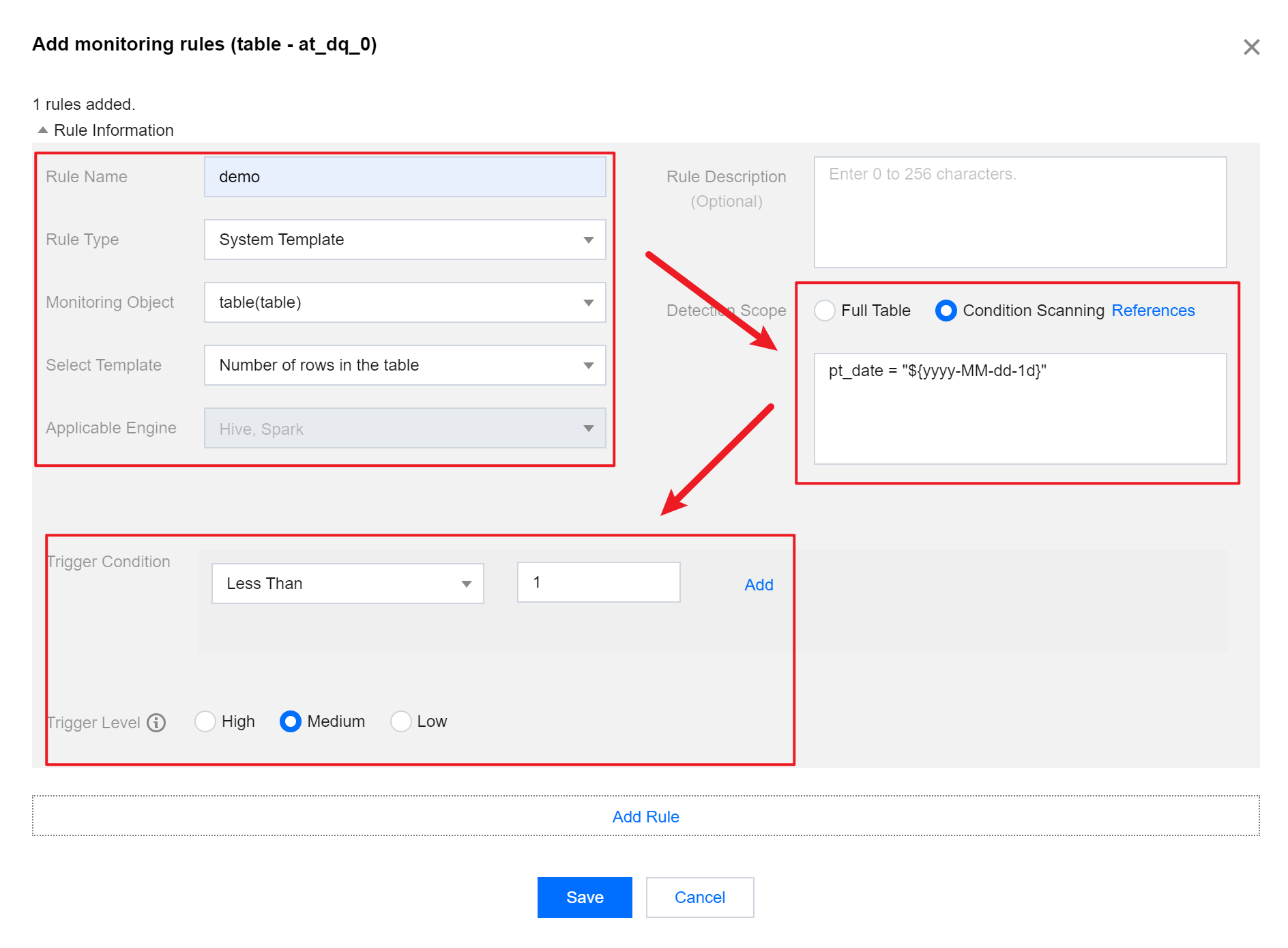
In the pop-up to add a new Monitoring Rule, fill in the following information, click Save.
Explanation:
Element
Note
Rule Type
Select System Template.
Here, you can choose a System Template, a Custom Template, or Custom SQL:
System Template: WeData has built-in 56 rule templates that you can try for free. Detailed descriptions of each template can be found in the System Template Description.
Custom Template: You can add rules that are applicable to your own business in the rule template menu for easy reuse. Detailed operation instructions can be found in the Custom Template Description.
Custom SQL: You can directly write SQL statements as detection rules. Detailed operation instructions can be found in Adding Quality Rules.
Monitoring Object
Select Table(table).
Monitored objects can be divided into: Table-level and Field-Level:
Table-level, can monitor the number of table rows, table size (only supports Hive tables).
Field-Level, can monitor whether a field is empty, duplicated, its average value, maximum value, minimum value, etc.
Select Template
Select Number of table rows.
WeData has built-in 56 rule templates that you can try for free. Detailed descriptions of each template can be found in the System Template Description.
Detection Range
Select Conditional Scan.
Enter the following WHERE Condition:
pt_date='${yyyy-MM-dd-1d}'
Note:
Typically, partition fields are specified here to avoid full table scans for every quality task, thus preventing a waste of computing resources.
In SQL, ${yyyy-MM-dd-1d} is a date variable representing the day before the execution date. It will be replaced with the specific date when the quality task is executed.
For example: When the quality task executes on 2024-05-02 00:00:00, ${yyyy-MM-dd-1d} will be replaced with 2024-05-01.
The specific replacement logic of time variables can be found in the Time Parameter Description.
Trigger Condition
Comparator: select Less than.
Comparison Value: enter 1.
Number of table rows less than 1, combined with the time variable entered for the detection range, indicates: trigger an alert when there is no new data added yesterday.
Note:
The trigger condition entered here is Abnormal Value, meaning: the condition that triggers the alert.
Trigger Level
Select Medium.
Trigger levels can be categorized into: High, Medium, Low.
High: When an alert is triggered, immediately block downstream task execution (only effective when linked with a production task).
Medium: Only trigger an alert.
Low: Does not trigger an alarm, only displays the result as abnormal.
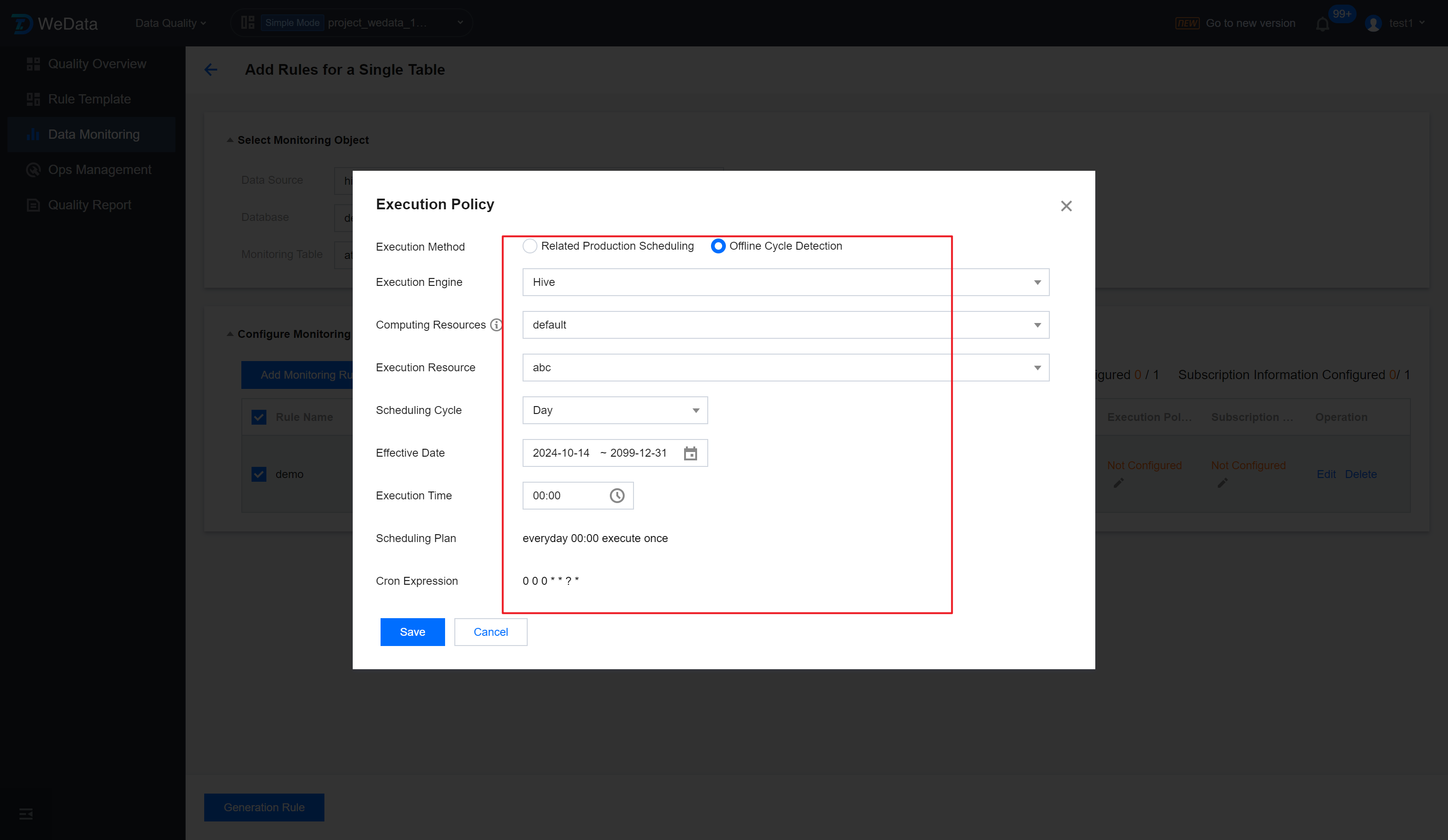
Step 4: Set Execution Strategy
After clicking Batch Set Execution Policies , enter the Execution Policies setting page. After setting up the batch execution policies, click Save.
Explanation:
Element
Note
Execution Method
Select Associate Production Scheduling.
You can choose to associate production scheduling and offline periodic detection here:
Associate Production Scheduling: That is, associated scheduling. Quality tasks are linked with production tasks (data synchronization tasks or data development tasks), and running quality rule tasks are inserted after the completion of production tasks. If an anomaly is found, the handler will be notified immediately to address the issue, and depending on the task level, downstream tasks may be blocked to prevent the problem data from expanding.
Note:
The same quality inspection task can be associated with multiple production tasks; likewise, the same production task can be associated with multiple quality inspection tasks.
Offline Periodic Detection: That is, independent scheduling. For selected database tables, the core business fields are set for periodic quality inspections at a self-defined frequency such as daily, hourly, or by minute. Quality tasks will be executed at the set period, and if anomalies are detected, subscribers will be notified immediately.
Execution Engine
Select Hive.
Here you can choose between Hive and Spark, depending on the EMR resources purchased. Generally, Hive tables can directly select the Hive engine.
Computing Resources
Select default
Here you can select a resource group within the EMR cluster. Generally, you can directly select default.
Execute Resources
The execute resources here refer to the schedule resource group that the project has already bound.
Select task
Select the Hive SQL task created in the preparation work.
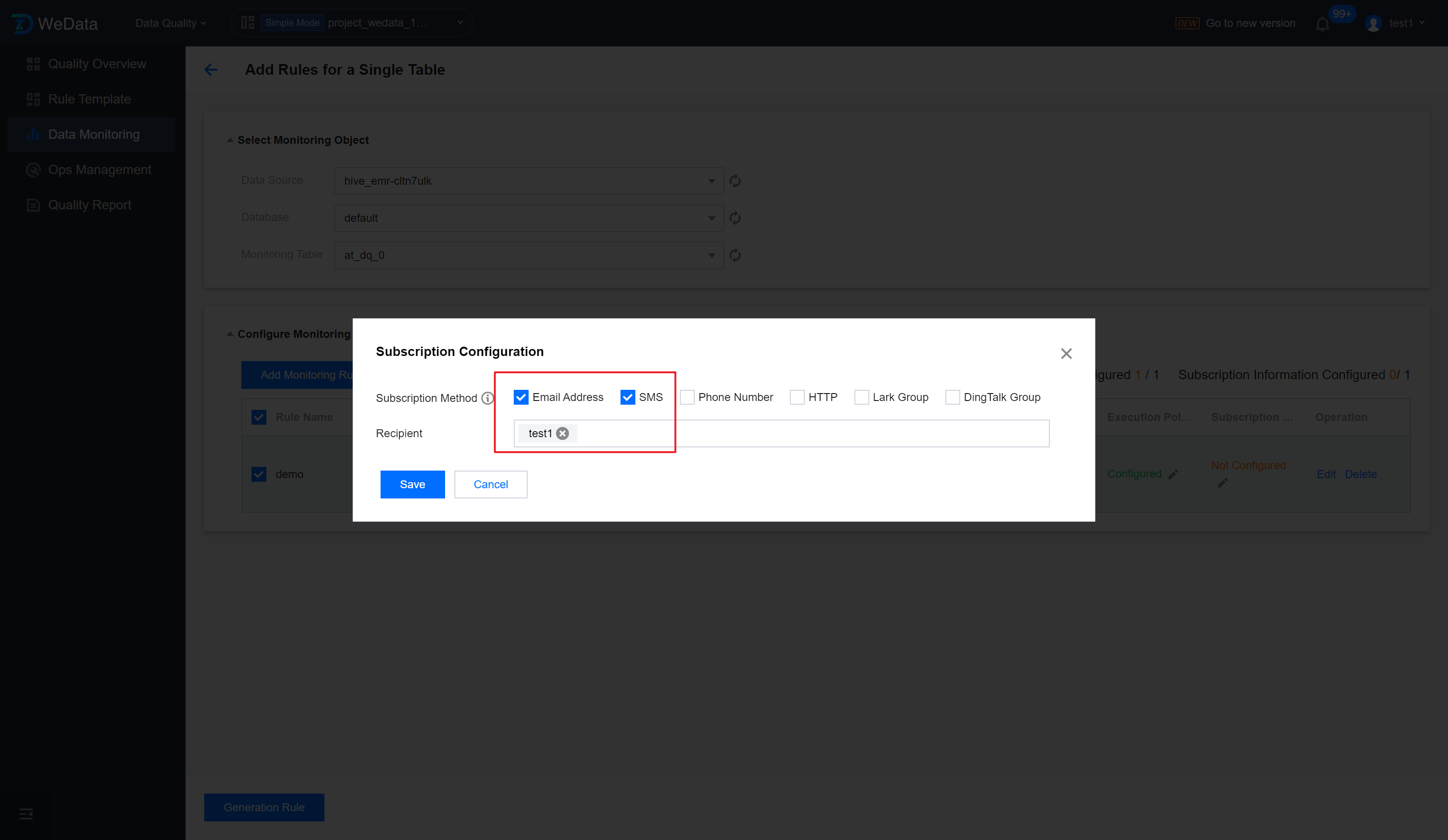
Step 5: Set up subscription
When the running result of the quality inspection task meets the trigger condition (i.e., the result is unexpected, the detection result fails), how and to whom a notification should be sent.
Enter the Subscription Configuration interface, check the Subscription Method, set up the Recipient, and click Save.
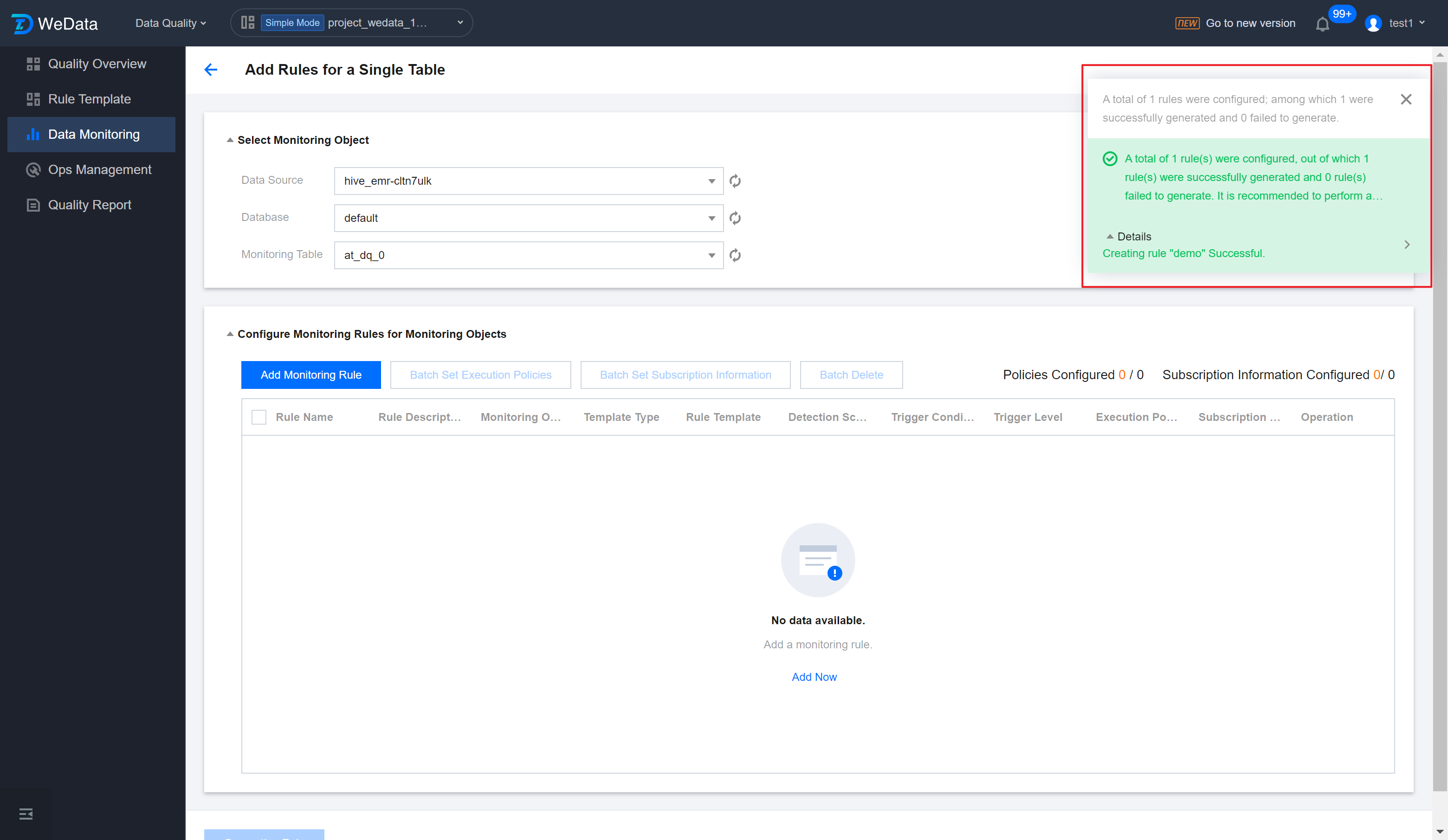
Step 6: Generate rules and view details
1. Enter the Single Table New Rule interface, click Generate Rules. You must click Generate Rules to produce quality inspection rules.
2. You can click Details in the upper right corner of the interface to enter the Rule List.
Step 7: Trial run
1. Go to the table dimension's rule list, click Trial run;
2. Modify the scheduling time, and click Start trial run; after the trial run ends, you can click Click to view running results.
Note:
Since the data partition entered during data insertion is 2024-05-01, you can enter 2024-05-02 here.
Step 8: View trial run results
1. After entering the Execution instance and result page, you can click the left Dropdown triangle to expand the Rule details.
2. Click the Execution history of a rule to view the Historical running results.
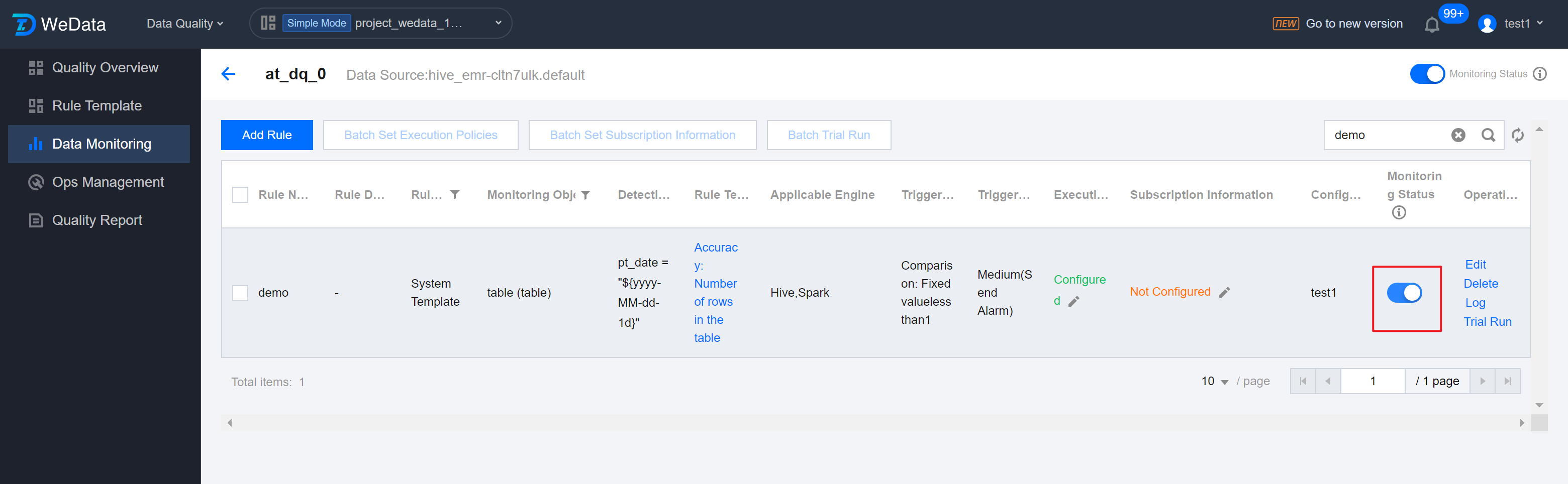
Step 9: Enable Monitoring
If the trial run results are satisfactory, you can return to the Quality Rule List at the table dimension and enable monitoring in the Monitoring Status Column
Note:
Only monitoring rules in the Enabled state will run automatically.
View Job Execution Results
When a quality task completes, if the detection result is abnormal, the system automatically sends an alarm and blocks downstream tasks for those with a high trigger level.
Database Table Responsible Persons and Data Development Engineers need to promptly troubleshoot anomalies and resolve issues.
1. On the Data Quality > Operations Management > Execute Instances and Results page, select the data source and database in turn to view the task's execution results.
2. On this page, you can view the task's detection status and expand to see the results and logs of each rule using the Left Dropdown Triangle.
Note:
Detection status is categorized into two main types:
Task Process Status:
Issuing: The detection task has been generated but is queued for deployment, which might be delayed due to Compute Resource Tension.
Link Failure: The task could not be deployed to the computing resource (e.g., EMR), possibly due to a network disconnection between the Schedule Resource Group and the computing resource.
SQL Detection Status:
Under detection: The SQL is running on the computing resource (e.g., EMR), and detection may take longer due to Compute Resource Tension.
Normal: The SQL has been executed, and the results meet expectations (not reaching the Detection Rules trigger conditions).
Abnormal: The SQL has been executed, and the results do not meet expectations (having reached the Trigger Conditions of the Detection Rules, at which point Task Alert Information will be sent).

 Yes
Yes
 No
No
Was this page helpful?