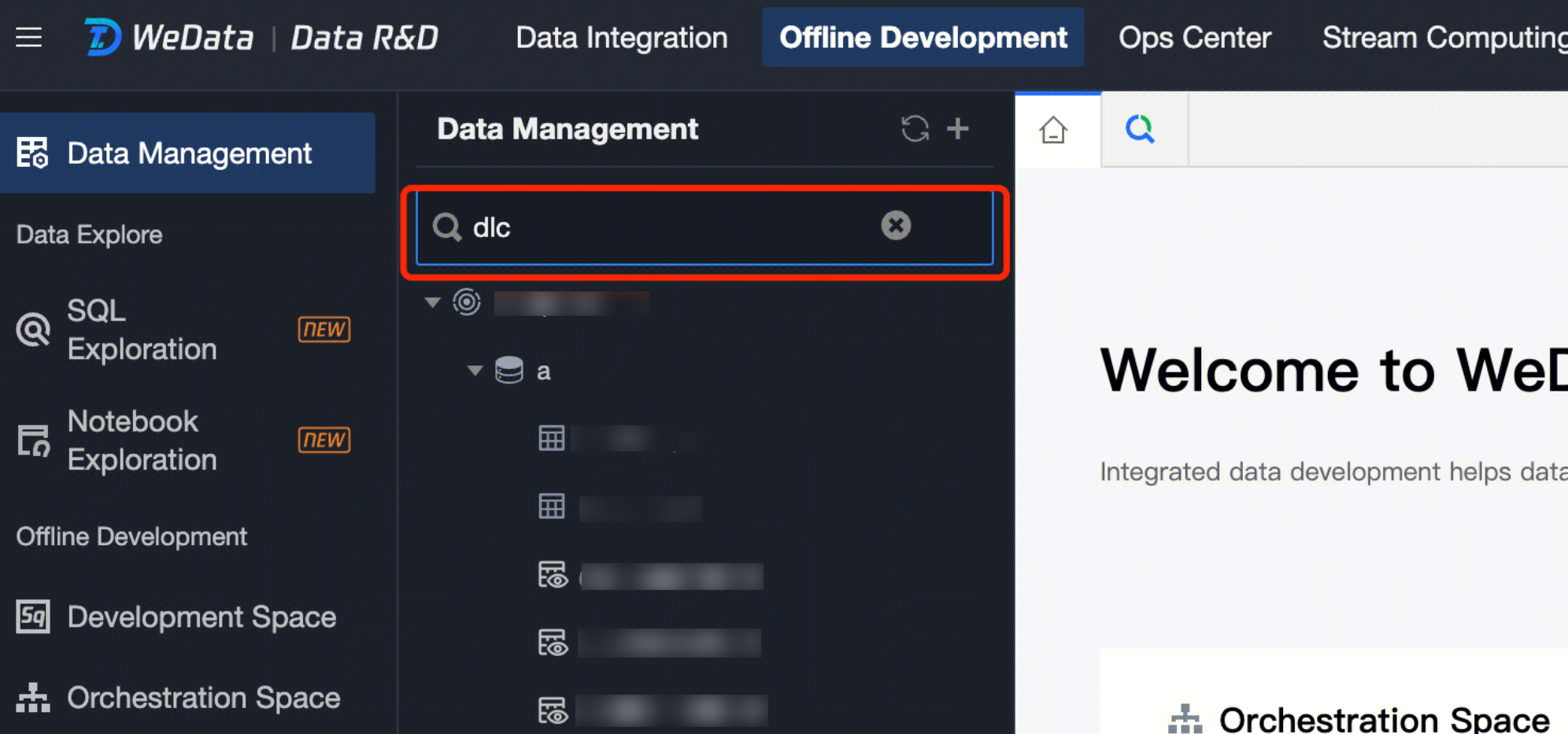
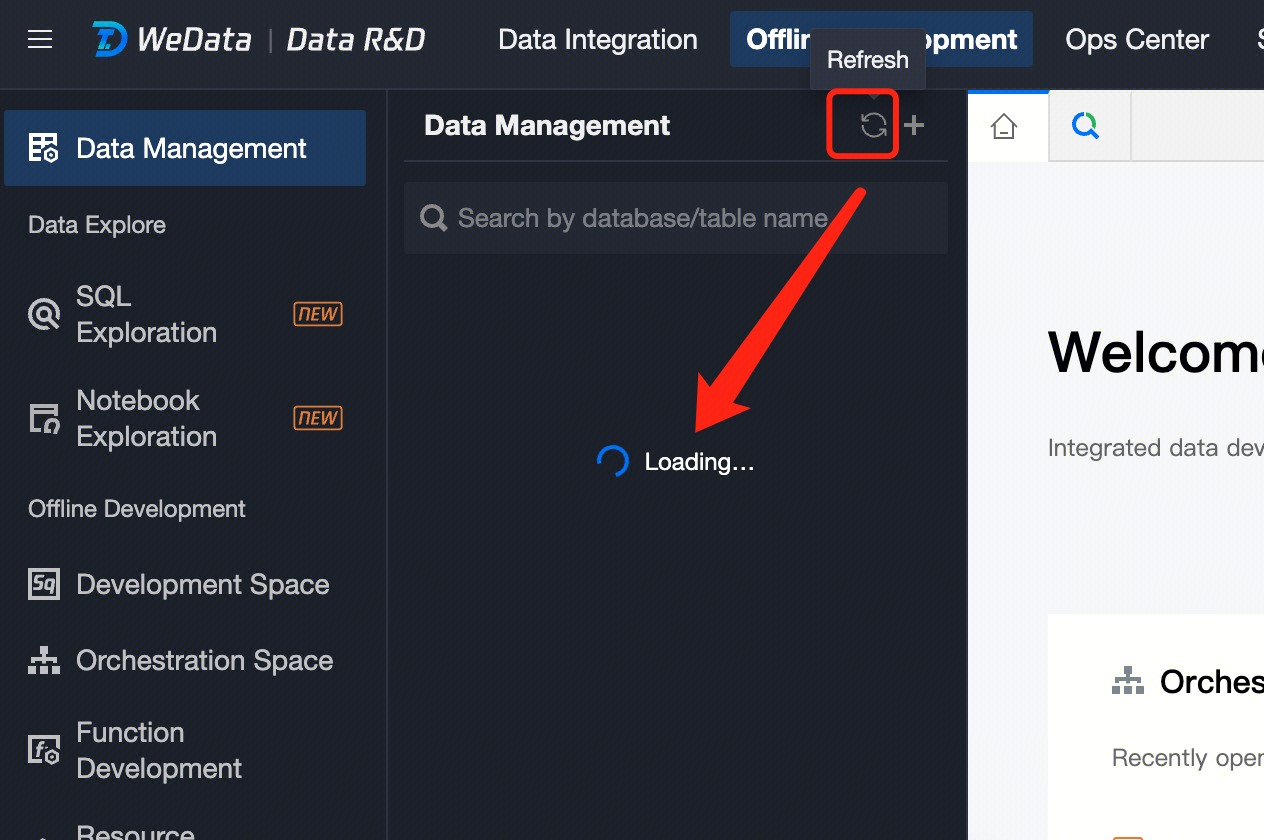
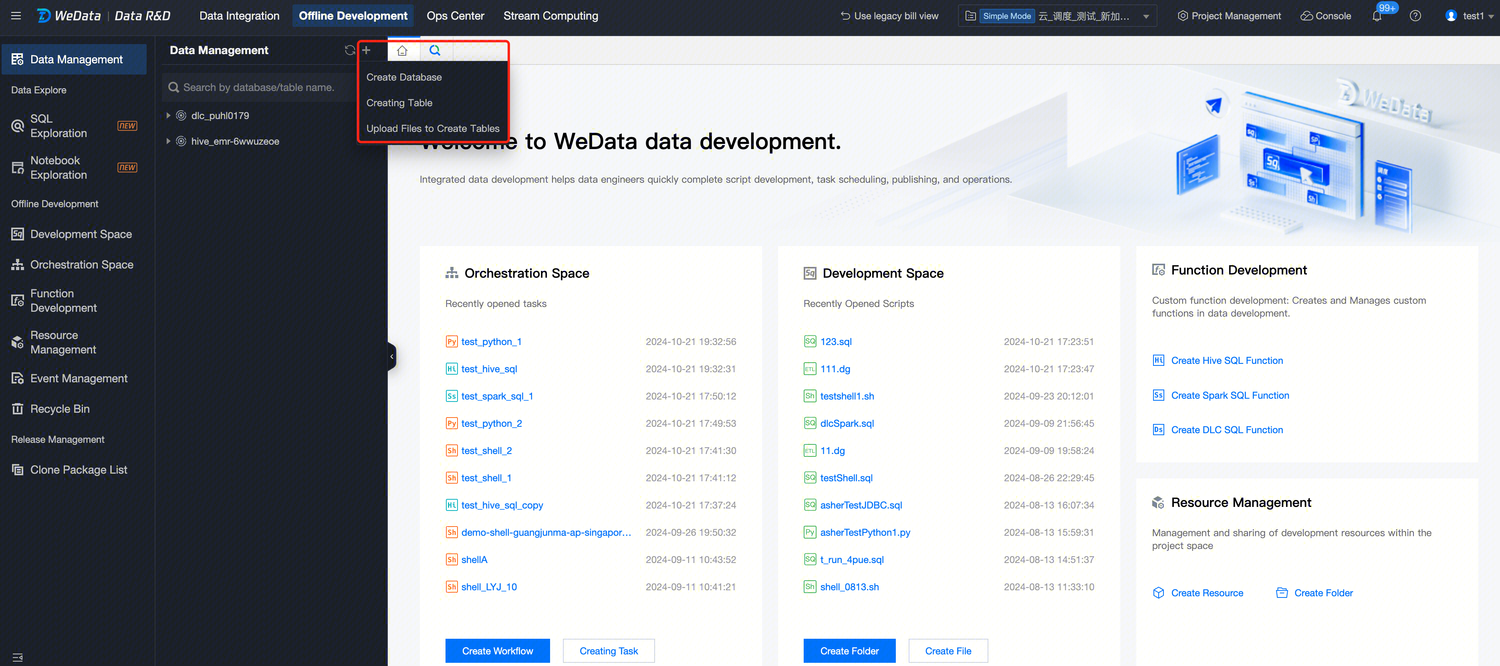
Enter the Data Management page
2. click Project List in the left menu to find the target project for the data management feature.
3. After selecting a project, click to enter the Data Development module.
4. click Data Management in the left menu.
Data Management Overview
Currently, WeData supports the creation of Hive and DLC database tables within the EMR and DLC engines of the system source.
Note:
Data sources can only be displayed in the Data Management directory after binding the computational storage engine in the project management page.
Data Management Directory
The directory tree is used to display the hierarchy and relationships of all database tables in the data source. This feature allows you to:
Quickly locate target tables. The directory tree feature allows users to quickly locate the position of target tables, improving operational efficiency and reducing operation time and the possibility of errors.
Display relationships between database tables. Through the directory tree feature, users can clearly see the hierarchy and relationships between database tables, making it easier to analyze and understand the associations and dependencies between them.
Manage and maintain the data warehouse. Through the directory tree feature, users can classify and manage databases by data warehouse layers, facilitating maintenance and adjustment of databases, such as deleting or renaming tables, fields, etc.
Convenient search feature. Through the search box feature of the directory tree, users can easily browse and search database tables and jump to the target table for operations.
Database Table Search
The search feature helps users quickly locate and browse target database tables or datasets. It provides users with a clear hierarchy view and quick search functionality, allowing users to easily find the required data, thereby improving data management and query efficiency.
Enter the name of the database or data table in the search window. The database catalog will search for the corresponding database structure. The search feature supports fuzzy search.
Refresh Directory
The directory tree refresh feature is used to reload the data source, database, and data table to update the contents displayed in the directory tree. This helps users update and sync the latest data from the data source to ensure that users get the latest data table information.
Database management
New database
Depending on the bound data source, you can create a database under Hive or DLC data source.
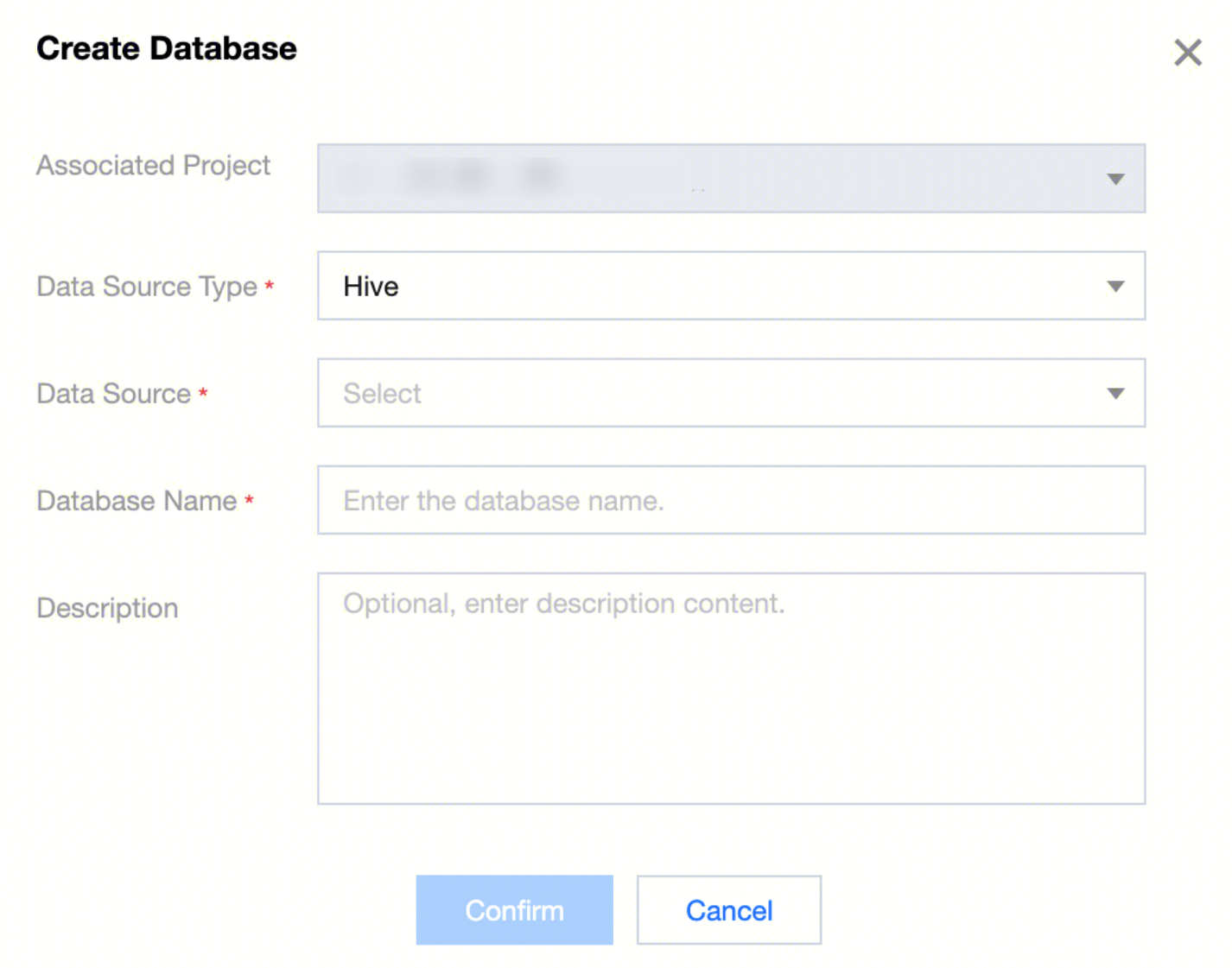
In the data management directory, click Create New Database. Follow the prompts to select the data source type, data source, customize the database name, and description information (optional). Once configured, the database can be created in the corresponding data source.
Hive database
Hive database information:
|
Data source type | Select Hive type. |
Data Source | Select Hive type data source. |
Database name | Customize Hive database name. |
Description | Optional: Customize description content. |
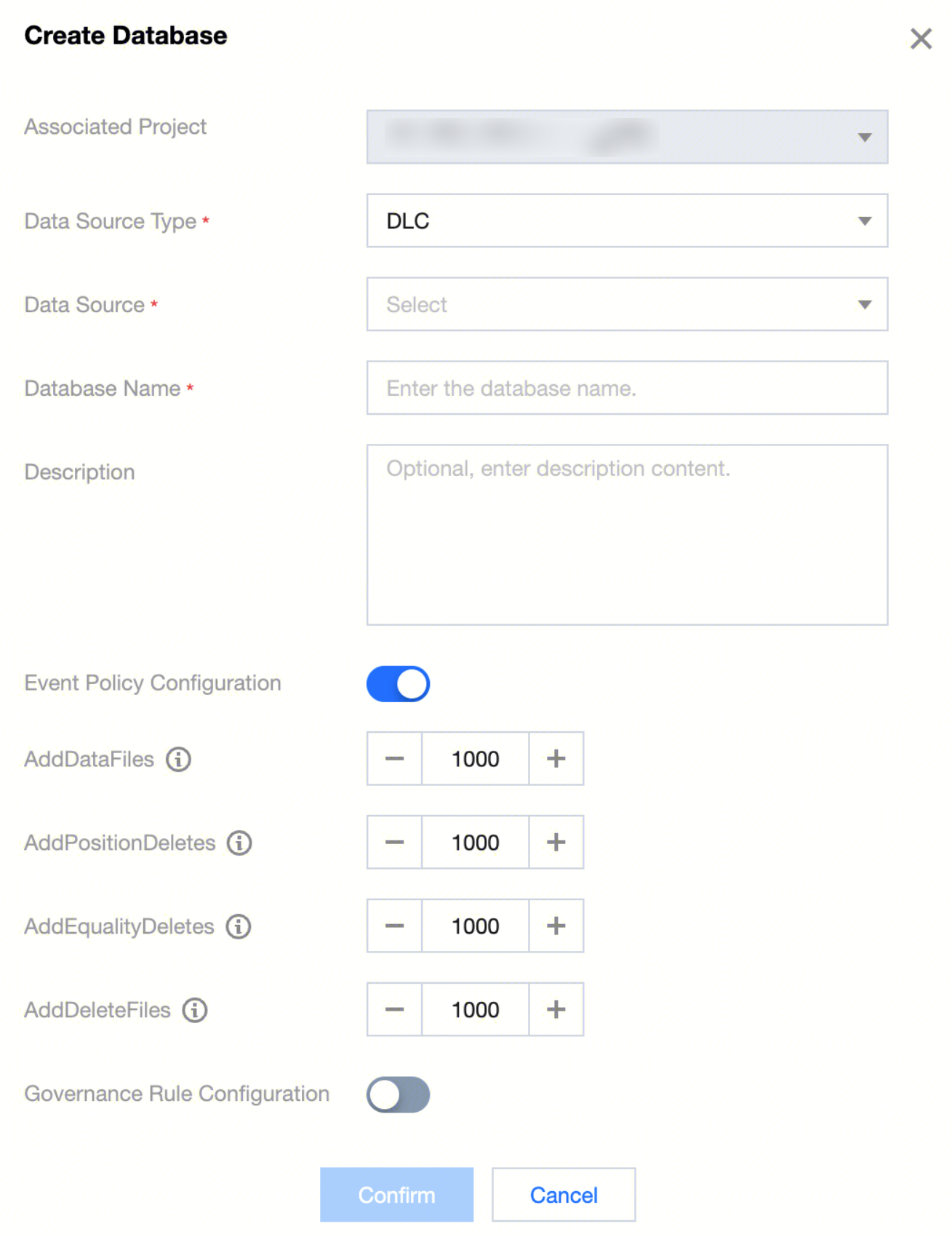
DLC database
If creating a database under DLC data source, you can configure event strategies and governance rules for the database.
DLC database information:
|
Basic Information Configuration | Data source type | Select DLC type. |
| Data Source | Select DLC type data source. |
| Database name | Custom Definition DLC database name. |
| Description | Optional: Customize description content. |
Event Policy Configuration | AddDataFiles | Set the maximum number of files to be added. Exceeding this value will trigger small file merging. |
| AddPositionDeletes | Set the maximum number of Position deletes. Exceeding this value will trigger small file merging. |
| AddEqualityDeletes | Set the maximum number of Equality deletes. Exceeding this value will trigger small file merging. |
| AddDeleteFiles | Set the number of delete files. When the total of expired snapshot's AddDataFiles + AddDeleteFiles exceeds the threshold AddDataFiles + AddDeleteFiles, the snapshot will be deleted from that point. |
Governance Rule Configuration | Small File Combination | Once enabled, a large number of data files smaller than the threshold will be combined into larger files, reducing the number of files and improving query performance. |
| Delete Expired Snapshot | Once enabled, expired historical snapshot information will be automatically cleaned up, reducing the number of metadata/data files, saving storage space, and improving query speed. |
| Delete Orphan Files | Once enabled, invalid data files will be automatically cleaned up periodically, saving storage space. |
| Metadata Merge | Once enabled, metadata manifests files will be automatically merged, reducing the number of manifests files and improving data query efficiency. |
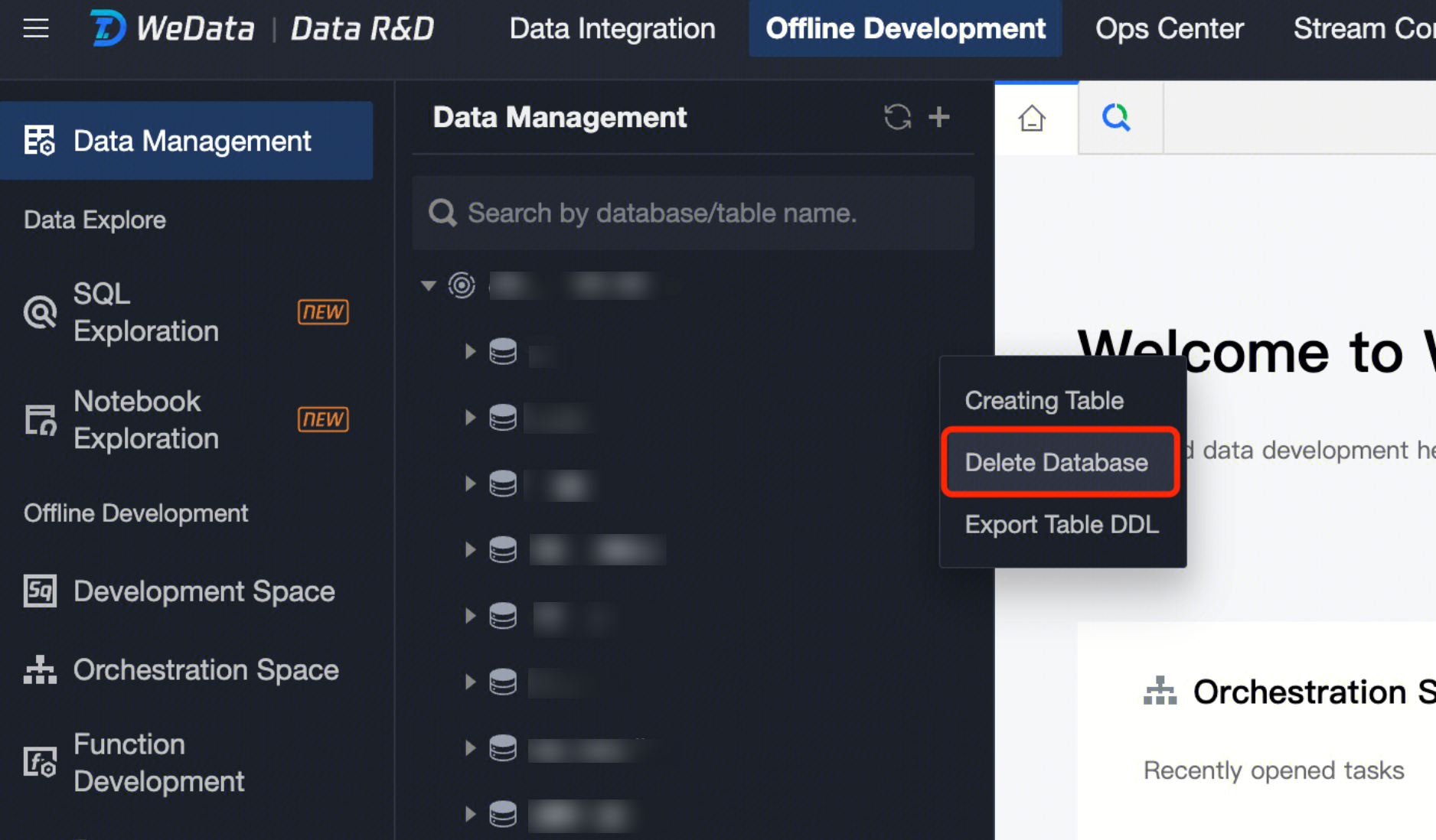
Dropping a Database
In the data management directory tree, move the cursor over the database you want to delete, click to expand the database operation menu, then click Delete Database. Confirm in the popup to delete the corresponding database. Note:
A library cannot be recovered once deleted, so please delete it carefully.
Managing a data table
Note:
The database must be created before creating a data table.
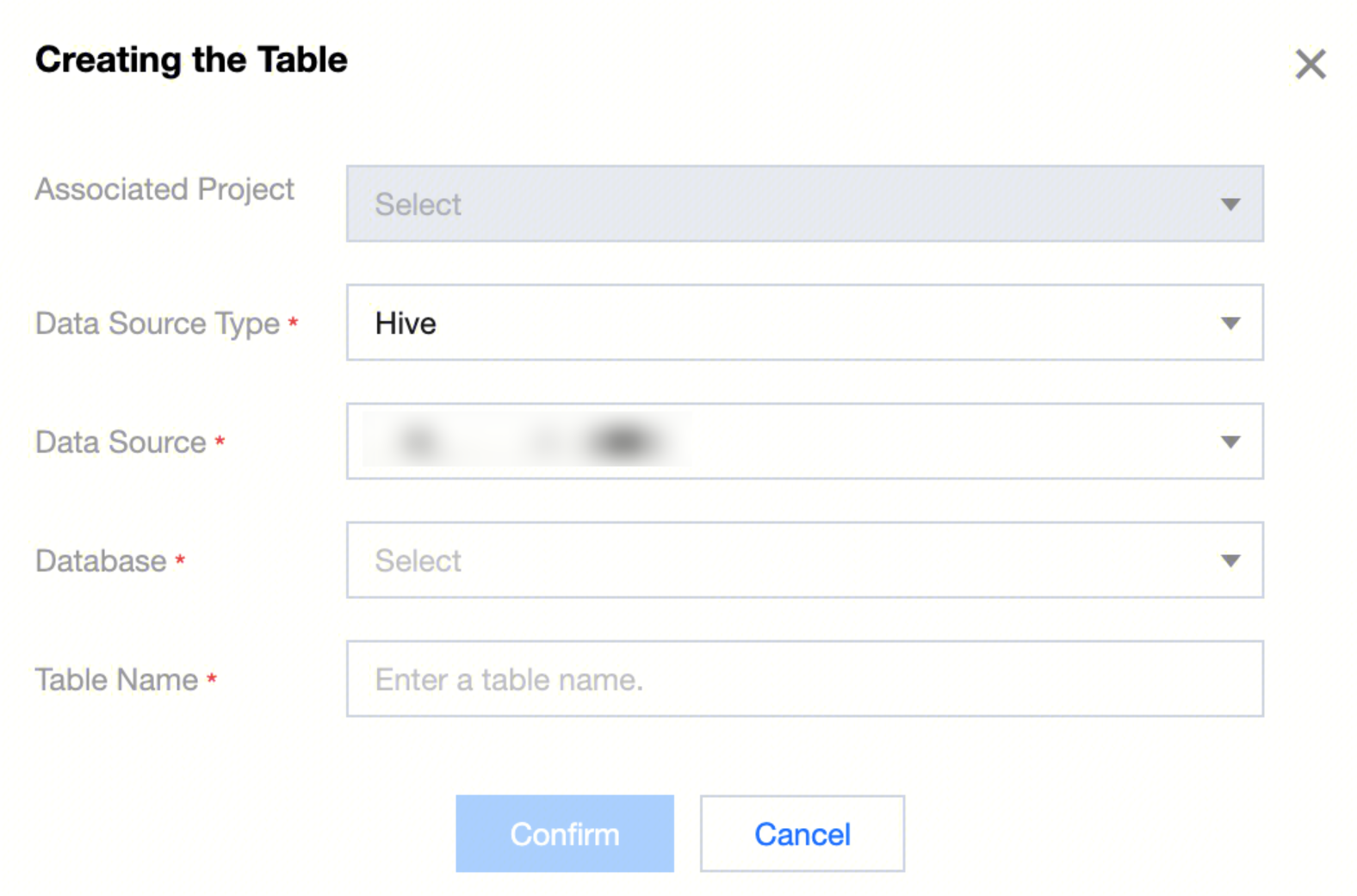
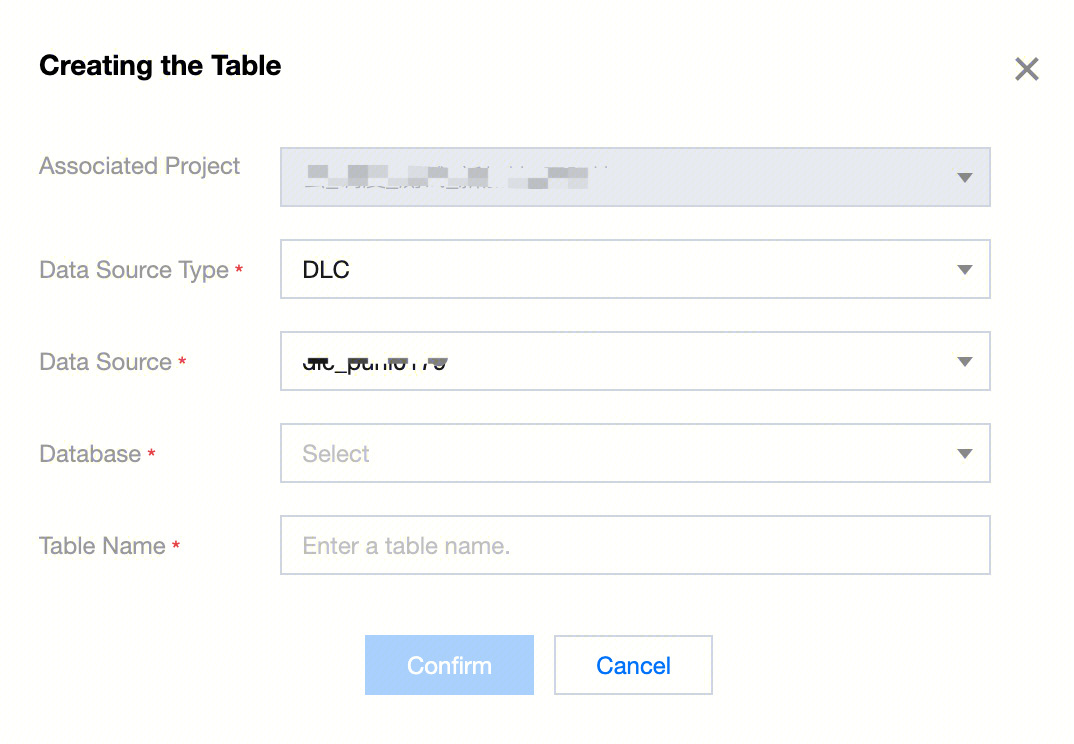
In the data management directory, click Create New Data Table. In the popup, follow the prompts to select the data source type, data source, and database. Define the data table name and complete the configuration, then click OK to enter the data table's Basic Attributes and Field design page.
Hive Data Table
1. When using EMR as the computational storage engine, you can create Hive data tables under the Hive data source in data management.
Note:
The Hive service must be started in the EMR cluster. If Ranger is enabled in Hive, make sure the Ranger's username and password are correct. Currently, the feature for modifying and adding fields is not provided.
2. After completing the basic information in the popup for creating a new table, you can enter the data table design page to configure the table's basic attributes and field information.
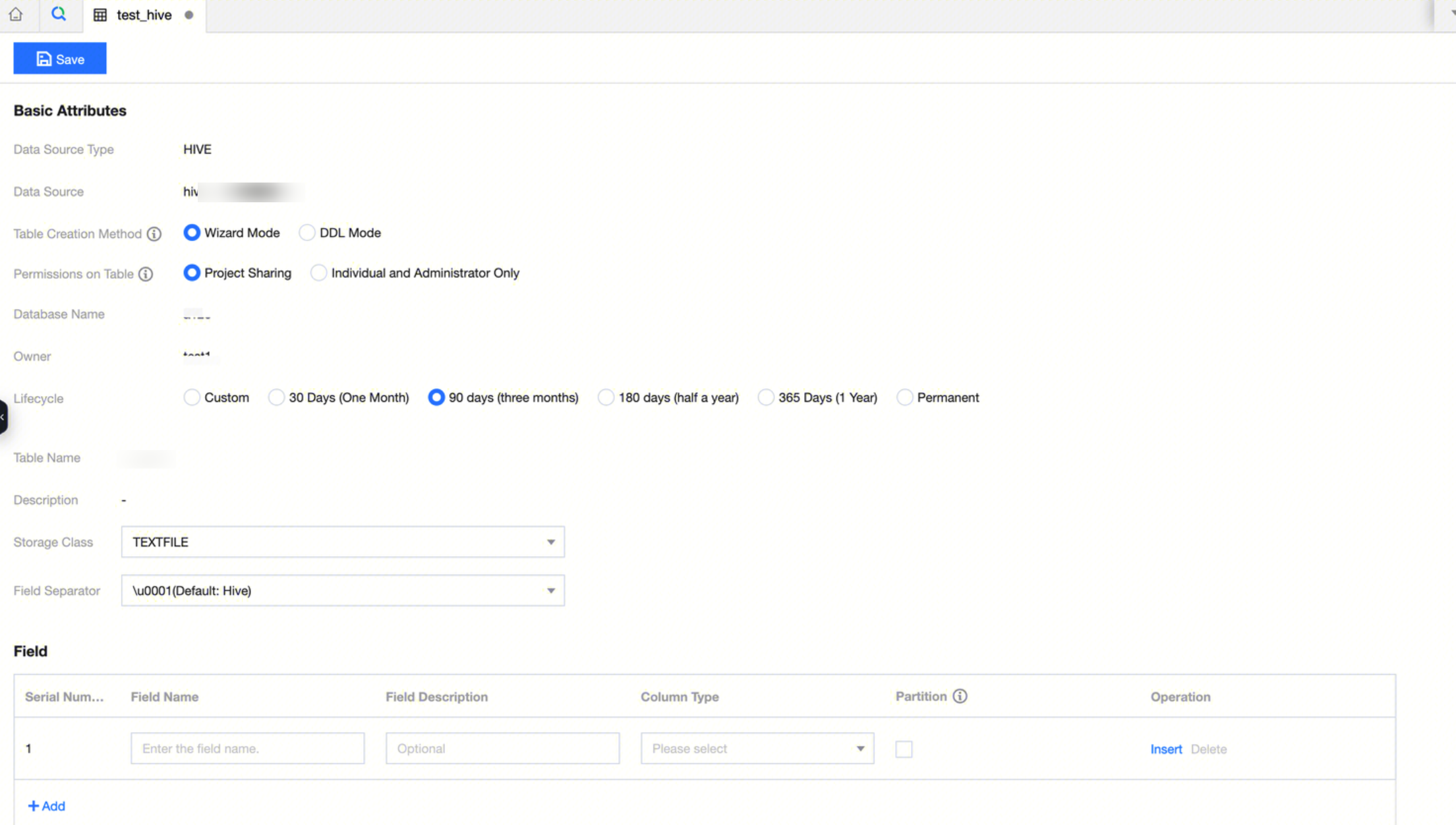
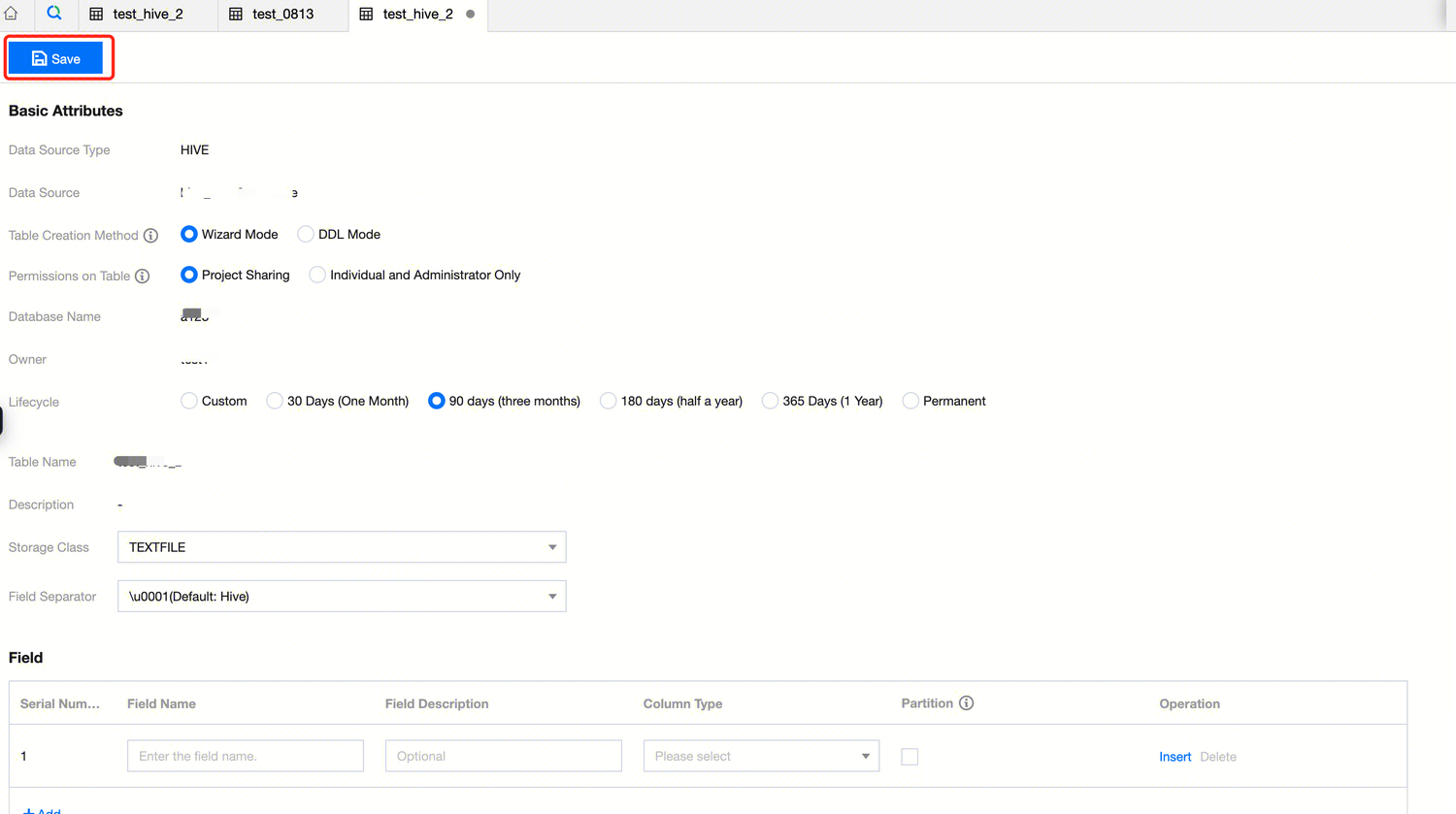
3. Hive Table Configuration:
|
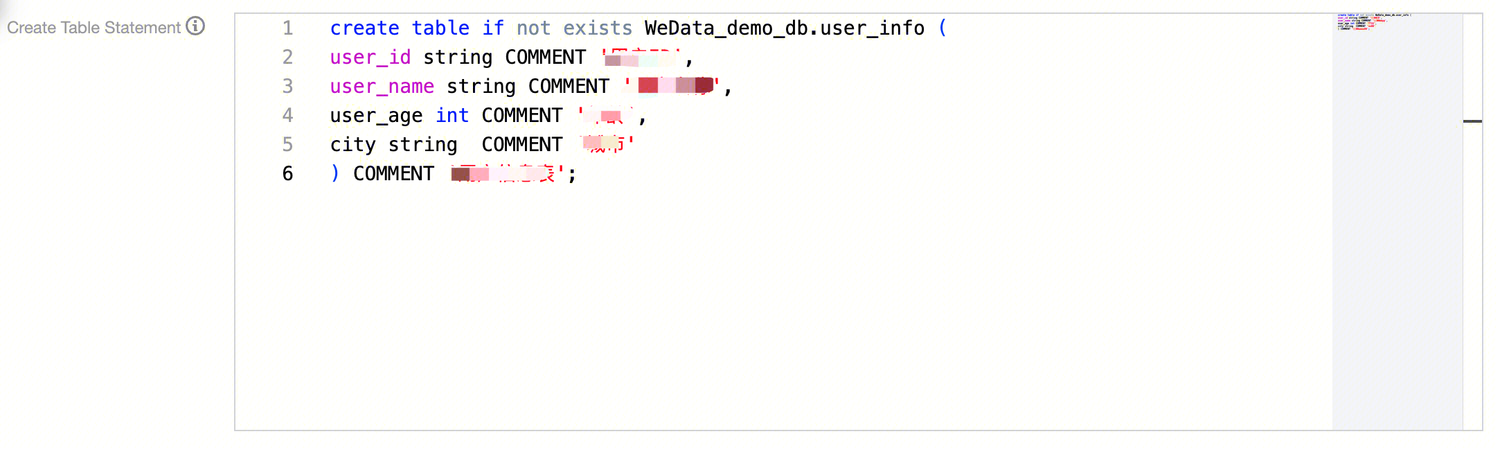
Table Creation Method | Wizard Mode Using the traditional method to manually add fields, define the field name, field Chinese name, field English name, column type, whether it is partitioned, and description after inserting the field. DDL Mode Use SQL Create Table statements to create data tables. Only the CREATE TABLE statement is supported for new tables, and only the ALTER TABLE ADD / REPLACE COLUMNS statement is supported for editing tables. For example: create table if not exists WeData_demo_db.user_info (
user_id string COMMENT 'User ID',
user_name string COMMENT 'Username',
user_age int COMMENT 'Age',
city string COMMENT 'City',
) COMMENT 'User Information Table';
Note: During the table creation process, ensure the table name in the DDL statement matches the name entered when creating the new data table. |
Permissions on Table | Project sharing Assign data table permissions to the current project. All members within the project will have data table permissions, including editing, inquiring, and deleting. Individuals and administrators only Assign data table permissions to the creator individual and the current project's administrator. (Note: Data permissions take effect in approximately 30 seconds) |
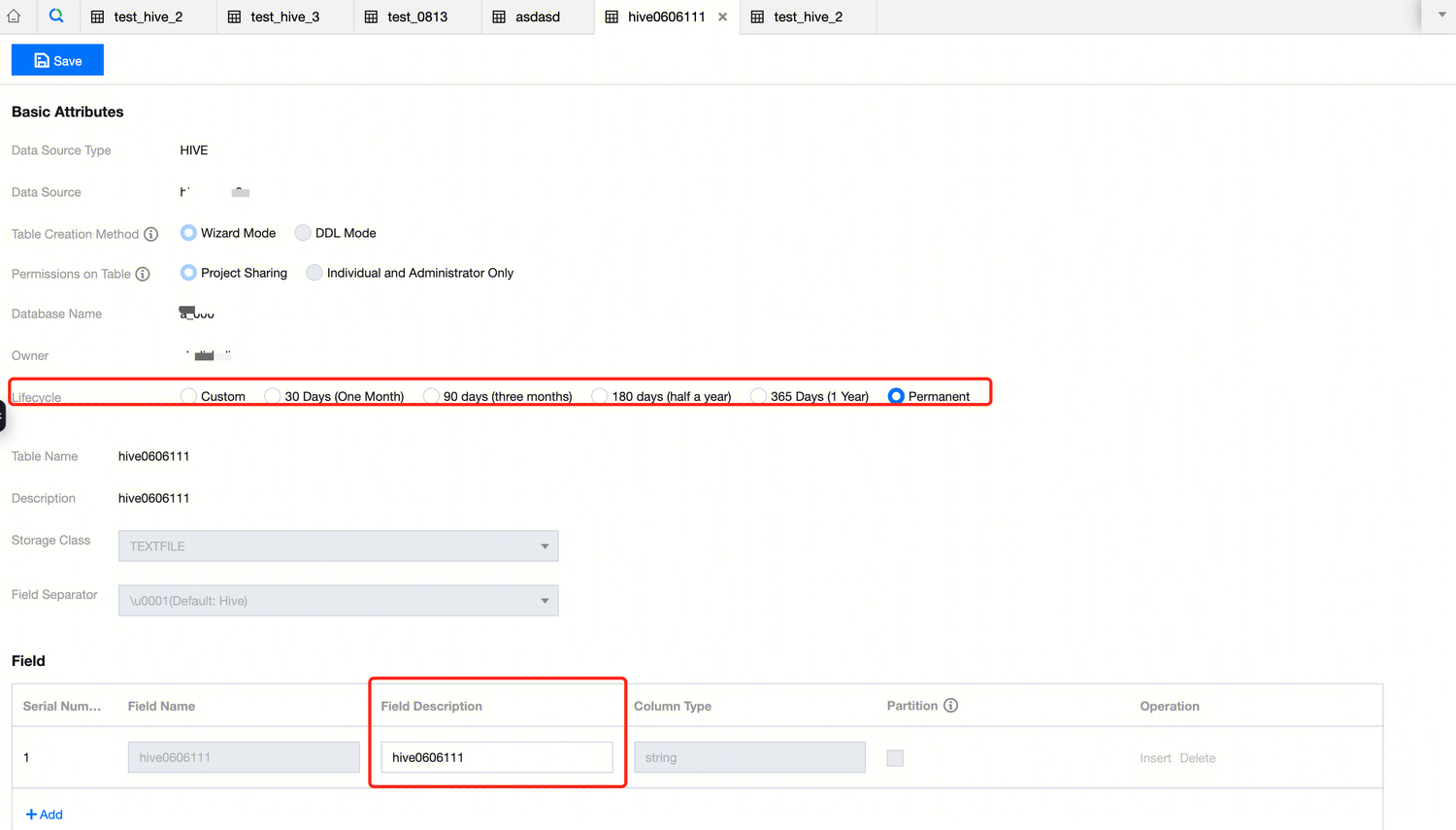
Lifecycle | EMR-Hive tables do not support lifecycle configuration. The current configuration is ineffective. Please be aware that this configuration item will be removed in future iterations. |
Storage Class | Support choosing four types of storage methods: TEXTFILE: A type of text format storage where plain text files are stored, with each line representing a record. PARQUET: A columnar storage format that divides data into rows and columns and stores them by column on the disk. It can be faster than row-based storage in certain scenarios and supports column compression. ORC: An optimized column storage format for storing and processing large-scale data. It uses advanced compression algorithms and indexing technology to improve processing speed and query efficiency. CSV: A common text format that uses commas as field delimiters and encloses each field value in quotation marks. |
Field Separator | Separate each field in the data table for reading and processing in a program or system. Five types of field delimiters are supported: \u0001 (Hive default), | (vertical bar), (space), ; (semicolon), , (comma), \t (tab) |
Field configuration | A field contains configuration information such as field name, field description, column type, and partition status. Partition Field Description: All fields cannot be selected as partition fields; at least one field must be a non-partition field. Partition fields do not support array, map, decimal types. |
4. After completing the configuration of the data table's Basic Attributes and Fields, click Save in the upper left corner to finish creating the data table. You can see the created data table in the data management directory on the left.
DLC Data Table
1. When using DLC as the computational storage engine, you can create DLC data tables under the DLC data source in data management.
Note:
Currently, DLC table creation only supports visual table creation; DDL table creation is not yet supported. Please create tables directly in the SQL statements in data development.
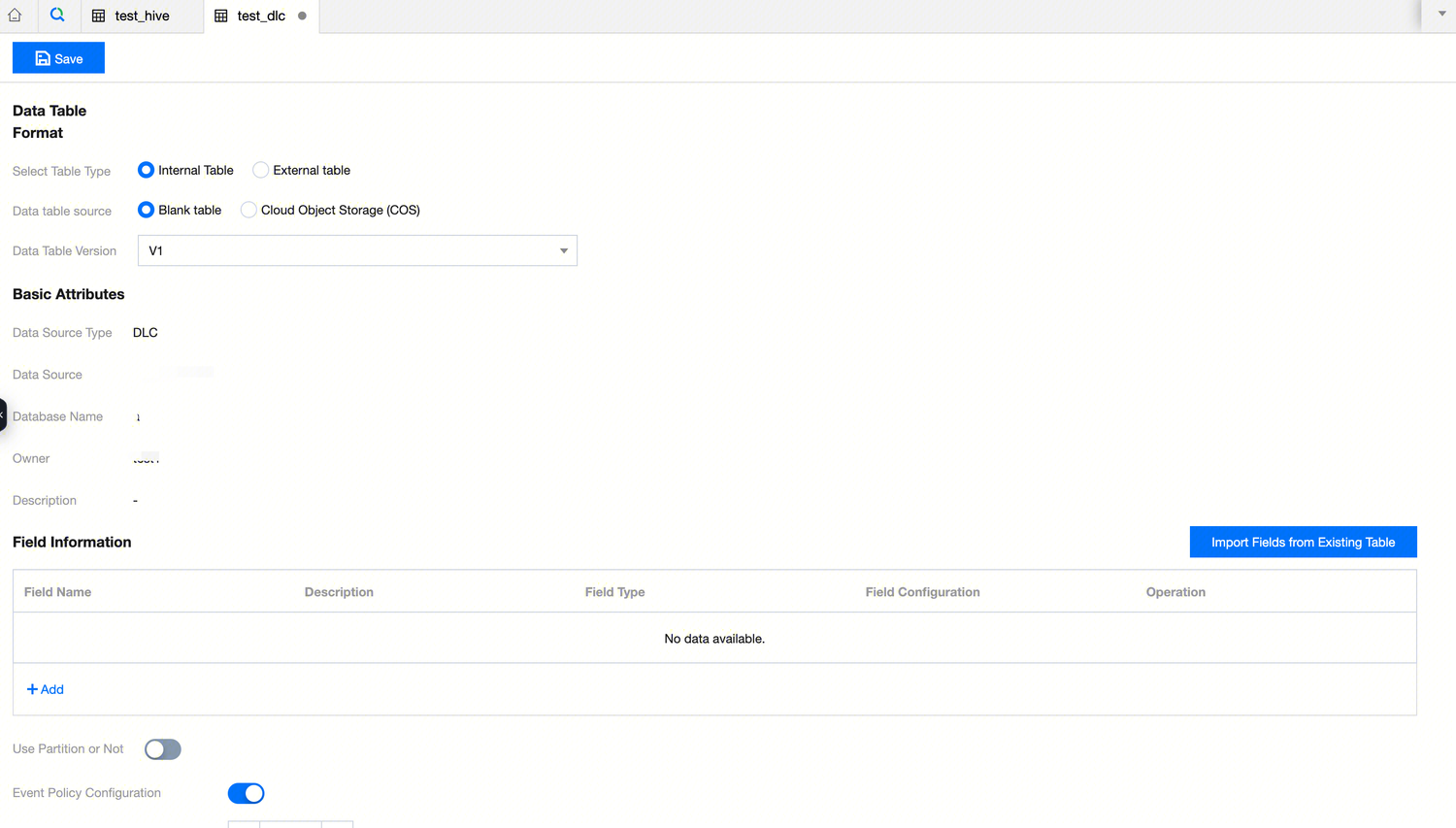
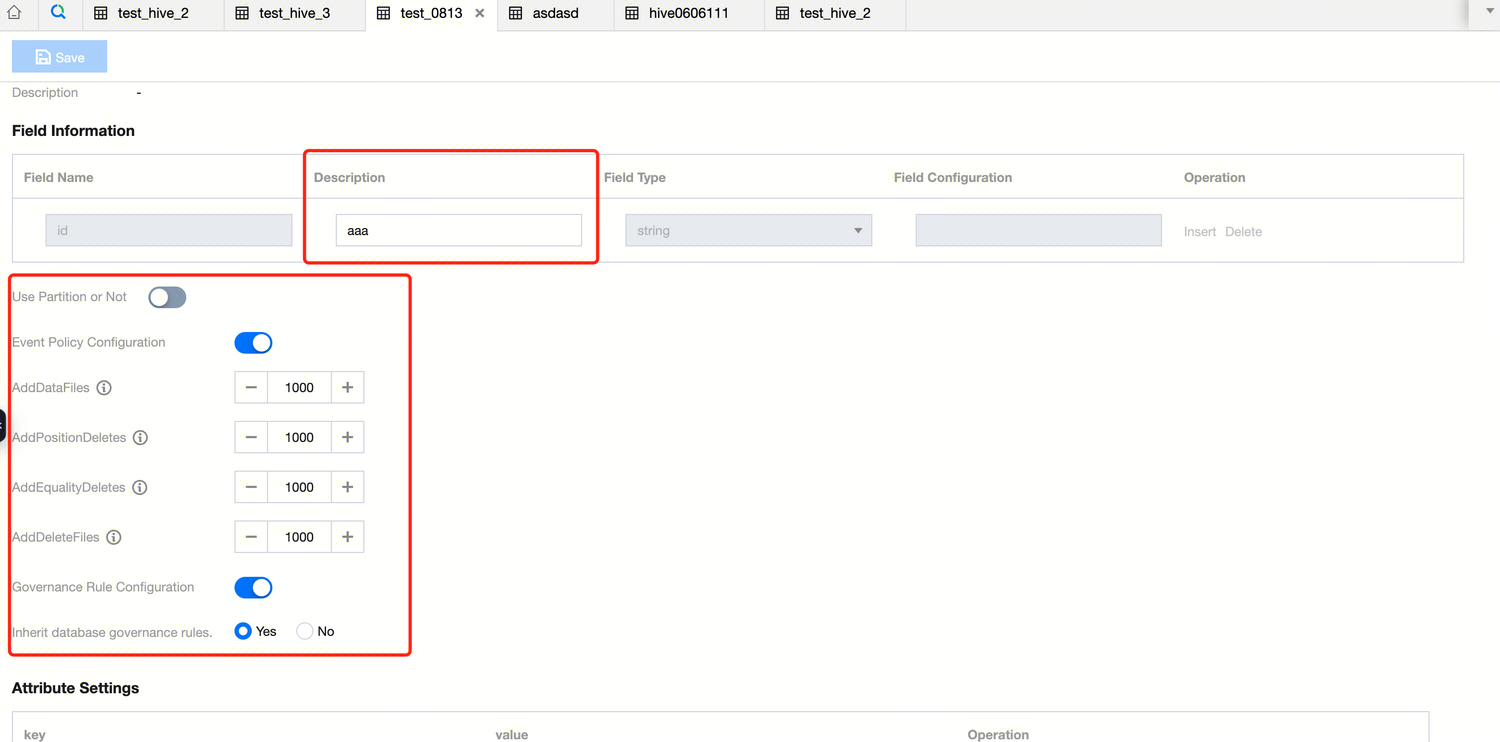
2. After completing the basic information in the new table popup, you can enter the data table design page. You need to configure the data table format, field information, and parameter attributes.
3. DLC Table Creation Configuration:
|
Data Table Format | Select Table Creation Type | You can choose to create an internal table or an external table. |
| Data Table Source | Specify whether to create an empty table or COS COS when creating an internal table. |
| Storage Path | COS COS and external tables require the location full path. |
| Data Format | Data formats include: CSV, JSON, PARQUET, ORC, AVRO. |
| Data Table Version | Select the data table version, V1 or V2. |
| upsert | When selecting the data table version V2, you can choose whether to use upsert for writing. |
Basic Attributes | Chinese name | Custom Definition of table Chinese name. |
| Description | Custom Description Information. |
Field Information | Field name | Design table field names. |
| Field Type | Supports DLC data table field types. |
| Description | Custom Definition of field description information. |
| Whether to use partitioning | Design partitioning, including partition field, conversion strategy, and policy parameters. |
| Event Policy Configuration | AddDataFiles: Set the maximum number of files to be added. Exceeding this value will trigger small file merging. |
|
| AddPositionDeletes: Set the maximum number of Position deletes. Exceeding this value will trigger small file merging. |
|
| AddEqualityDeletes: Set the maximum number of Equality deletes. Exceeding this value will trigger small file merging. |
|
| AddDeleteFiles: Set the number of delete files. When the total of expired snapshot's AddDataFiles + AddDeleteFiles exceeds the threshold AddDataFiles + AddDeleteFiles, the snapshot will be deleted from that point. |
| Governance Rule Configuration | Support enabling data table governance rules. Governance rule configuration items can choose to inherit the governance rules of the database selected when the current data table was created, or the data table can have its own Definition governance rules. The following governance rules are included: Small File Merge: Once enabled, a large number of data files smaller than the threshold will be combined into larger files, reducing the number of files and improving query performance. Delete Expired Snapshots: Once enabled, expired historical snapshot information will be automatically cleaned up, reducing the number of metadata/data files, saving storage space, and improving query speed. Delete Orphaned Files: Once enabled, invalid data files will be automatically cleaned up periodically, saving storage space. Metadata Merge: Once enabled, metadata manifests files will be automatically merged, reducing the number of manifests files, and improving data query efficiency. |
Attribute settings | Parameter configuration | Support self Definition data table parameter configuration, such as format-version, write.upsert.enabled. |
Upload Data Table
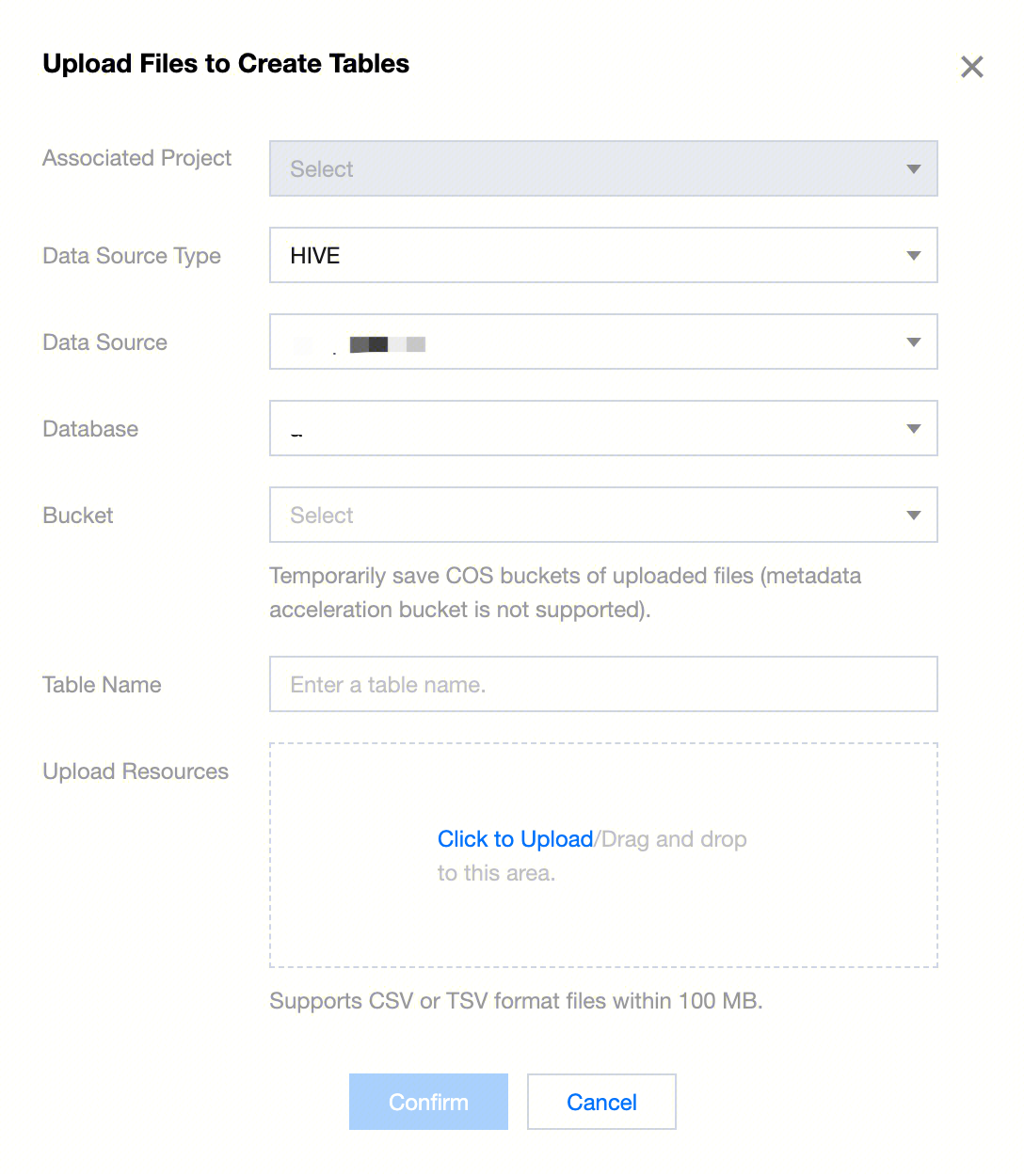
1. In the data management directory or main data management interface, click Create Table by Uploading File. Currently, only Hive Type Data Table uploads are supported.
Upload Example:
Note:
1. Currently support uploading CSV and TSV files, with a maximum file size of 100 MB.
2. You need to bind the EMR cluster with the WeData project, which includes the corresponding Hive service.
3. If Ranger is configured in project management, the Ranger username and password must be correct.
4. The EMR_QCSRole role set for the COS bucket must have access permissions to COS, otherwise, there will be an error indicating a problem with the COS path when importing data.
2. In the pop-up window, follow the prompts to select the data source type, data source, database, bucket, custom table name, and the uploaded table creation resources.
3. File upload configuration:
|
Data source type | Hive type data sources are supported. |
Data Source | Select the WeData data source under the corresponding data source type. |
Database | Displays the Hive databases bound to the current project and links by data source type. Searching by library name is supported. |
Bucket | COS bucket for temporarily storing uploaded files. |
Table name | The default is to automatically enter the uploaded file name without the suffix, but you can customize the name. |
Upload resources | Click to upload or drag and drop to upload, a progress bar is provided. The upload format is: CSV or TSV format. |
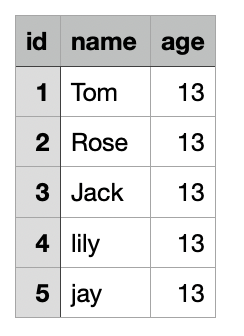
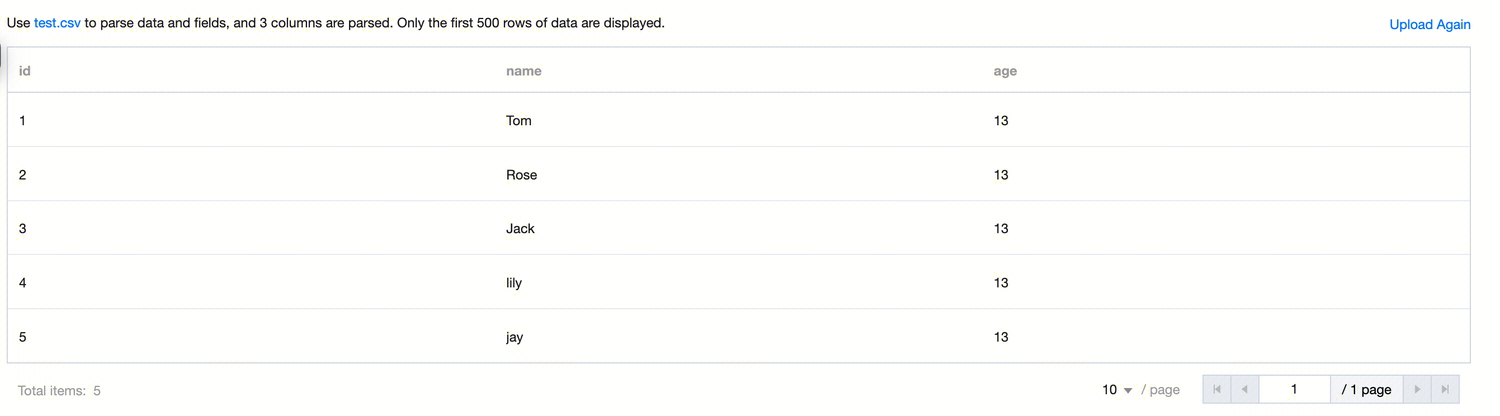
4. Here, as an example, the data format for a CSV file is as follows:
5. After completing the popup message configuration, click OK to enter the table creation page.
6. On the table creation page, you can set table permissions, the Chinese name for the table, and the table description information. The parsed uploaded file will provide fields, data preview, and support configuration for file format, column separator, column quotation marks, first row field confirmation, file encoding method, and field attributes.
|
Basic Attributes | Permissions on Table | Select the permission ownership after creating the current data table, either for in-project sharing or for use by the individual and administrator only. |
| Chinese name | The default automatically incorporates the file name without the suffix, can be customized. |
| Description | Custom Data Table Description Information. |
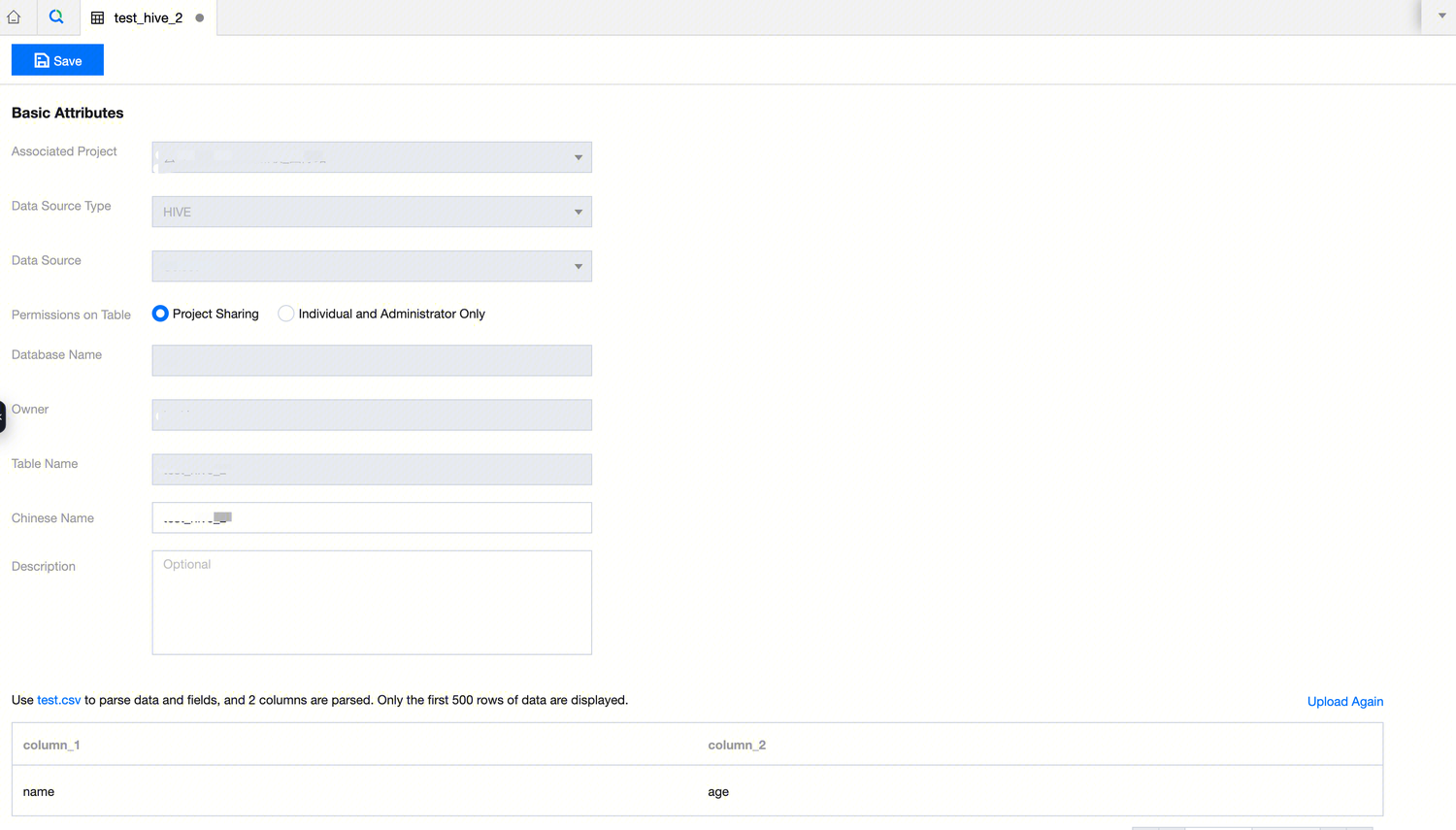
File Attributes | Data preview | After file parsing, only the first 500 rows of data are displayed. Click Re-upload to open the file upload dialog for re-uploading the table file. |
| File Format | Drop-down selection supports CSV,TSV. |
| Column delimiter | Users can enter custom input, a single character or a Unicode escape sequence like \u0001. CSV default: , (comma) TSV default: \t (tab character) |
| Column Quotes | The default is double quotes. Users can switch to single quotes. |
| First line is column name | The default is no. It can be switched to yes. |
| File encoding method | Default is UTF-8. Users can choose UTF-8, GBK, ISO-8859-1. |
Field attributes | Field name | Field names are parsed according to the first line of the file being the column names attribute. If the first line of data in the file is not the column name, use column_1, column_2, column_3, ... column_x to sequentially fill in the field names. Users can also custom define and modify the field names. |
| Field Chinese Name | Custom Definition Field Chinese Name. |
| Field English Name | Custom Definition Field English Name. |
| Column type | Choose the corresponding data type supported by the data source based on the data source type. |
| Description | Custom Definition of field description information. |
7. After configuring the table creation information on the page, click Save at the top left corner of the page to generate the data table.
8. The progress of the corresponding data table generation can be viewed in the progress pop-up after saving. Once the creation steps are successfully executed, the data table will be successfully generated.
Edit Data Table
1. Move the cursor to the data table that needs to be edited in the data management directory tree, double-click the left mouse button to open the corresponding data table's edit page. Some parameters of the data table can be edited on the page.
Editable content in Hive includes lifecycle and field description.
2. Editable content in DLC includes table field description, event policy configuration, and governance rule configuration.
3. After editing the data table, click Save to complete the data table editing operation.
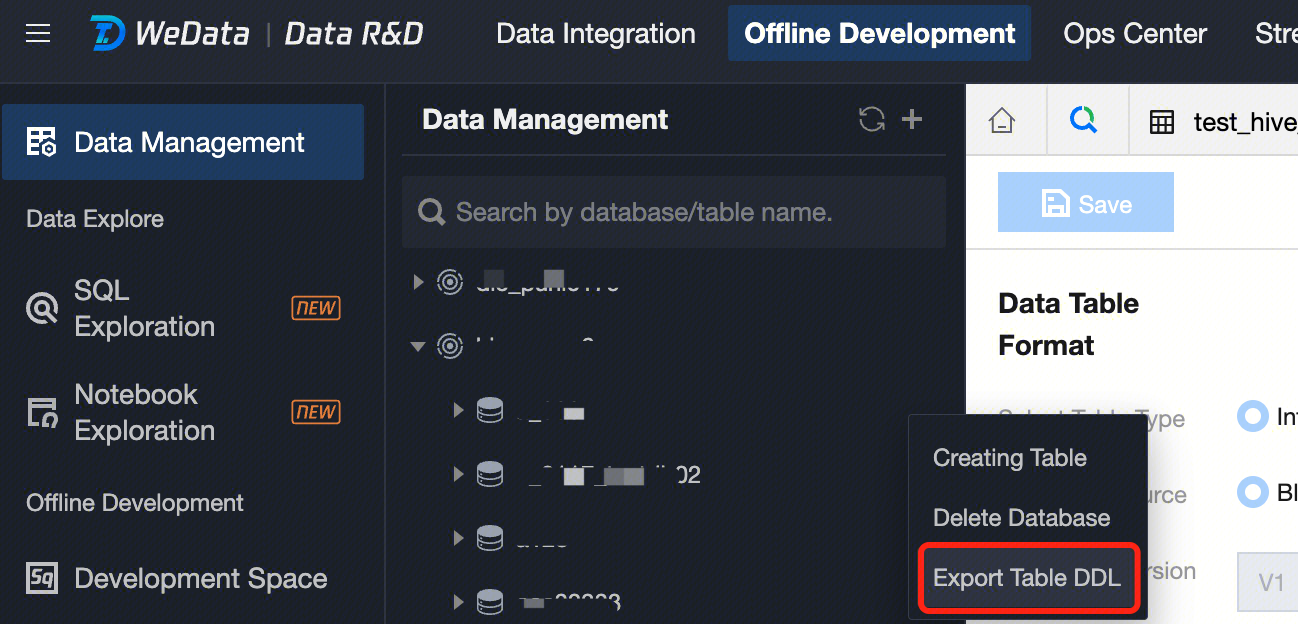
Export Table DDL
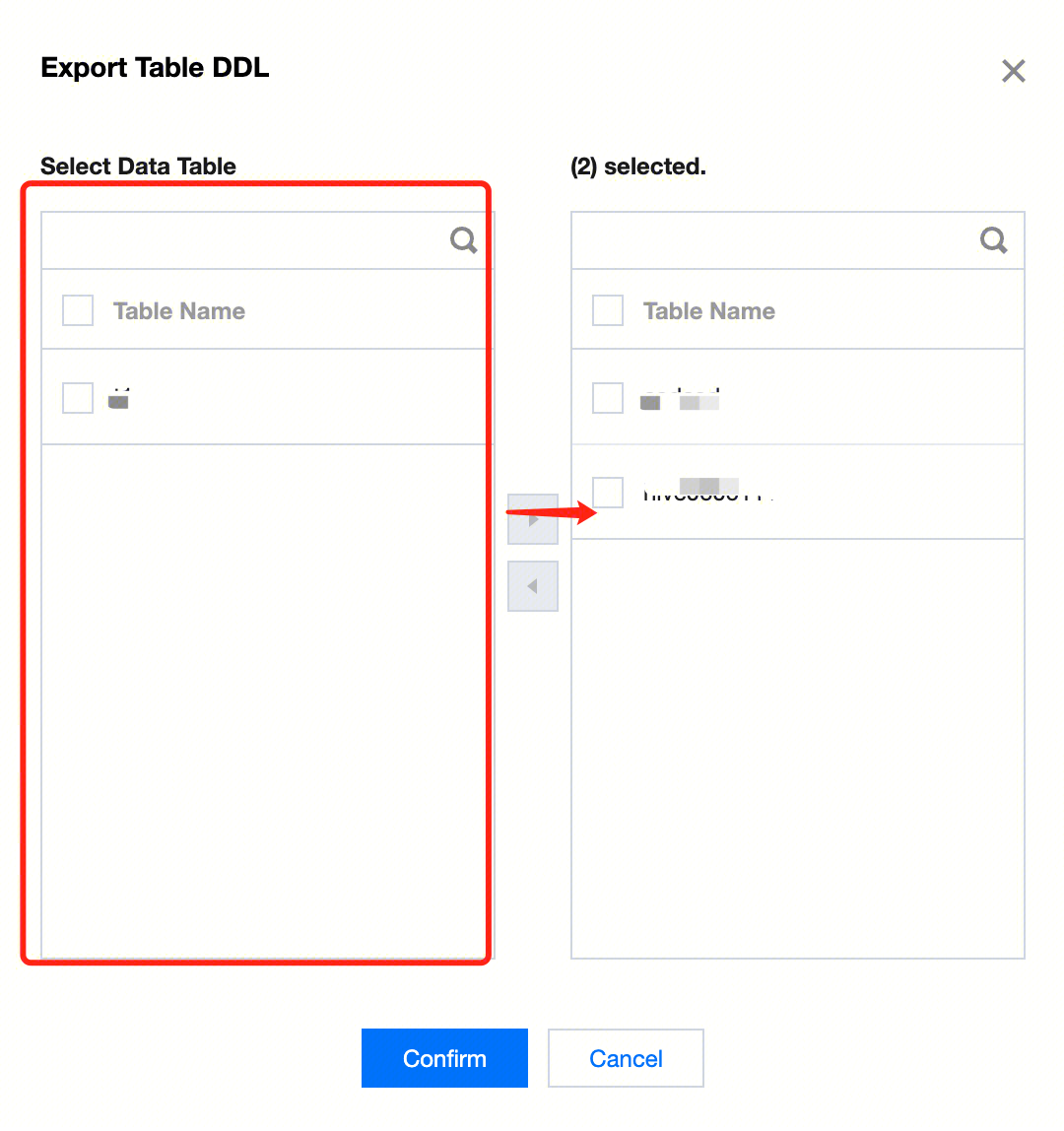
1. In the data management directory tree, move the cursor to the database where the data table for which you want to export the DDL is located, click to expand the database operation menu, then click Export Table DDL. In the left panel of the popup, select the data table whose DDL you want to export under the current database, add it to the right panel, and confirm to export the corresponding data table's DDL file. 2. Select the data table whose DDL you want to export.
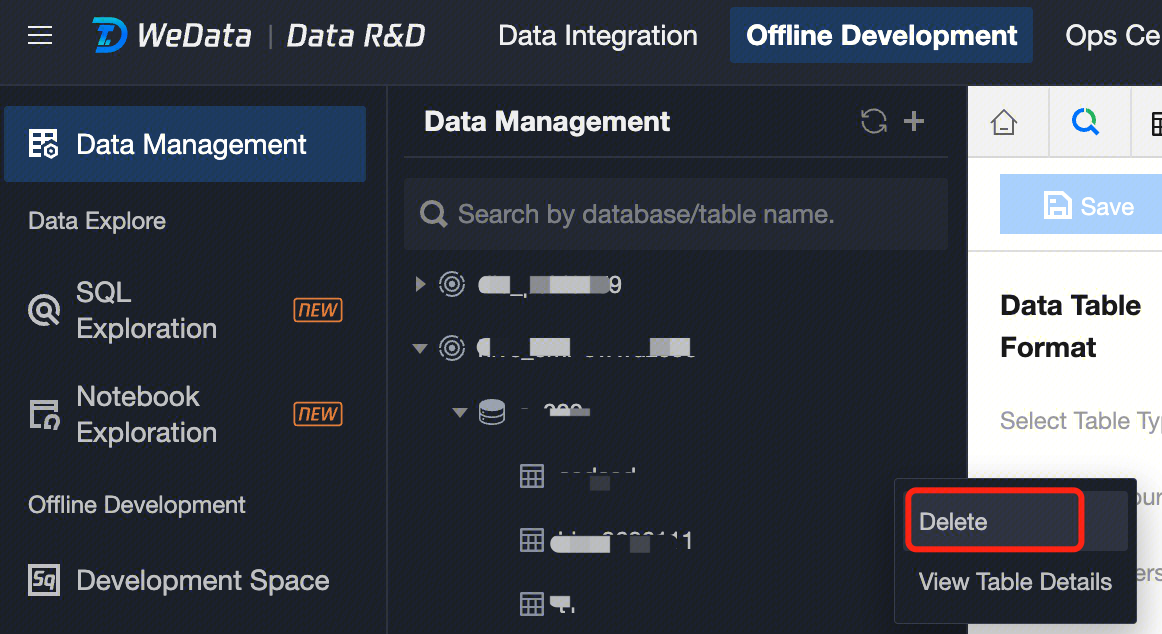
Dropping a Table
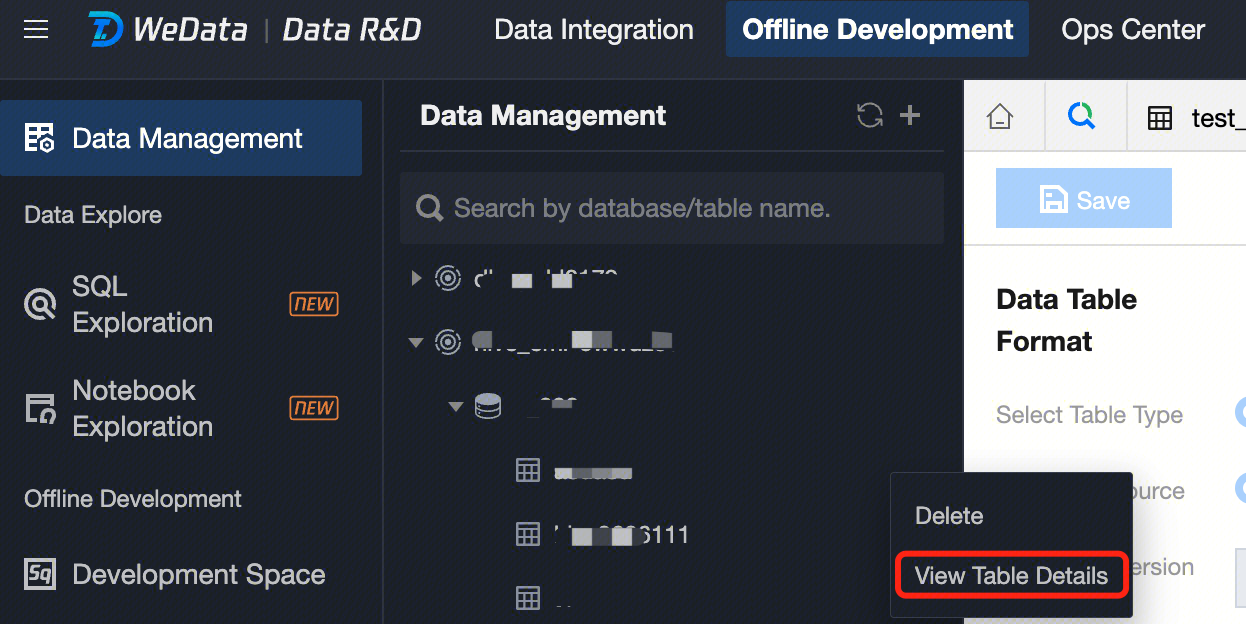
1. In the data management directory tree, move the cursor to the data table you want to delete, click to expand the data table operation menu, then click Delete, and confirm in the popup to delete the corresponding data table. Viewing table details
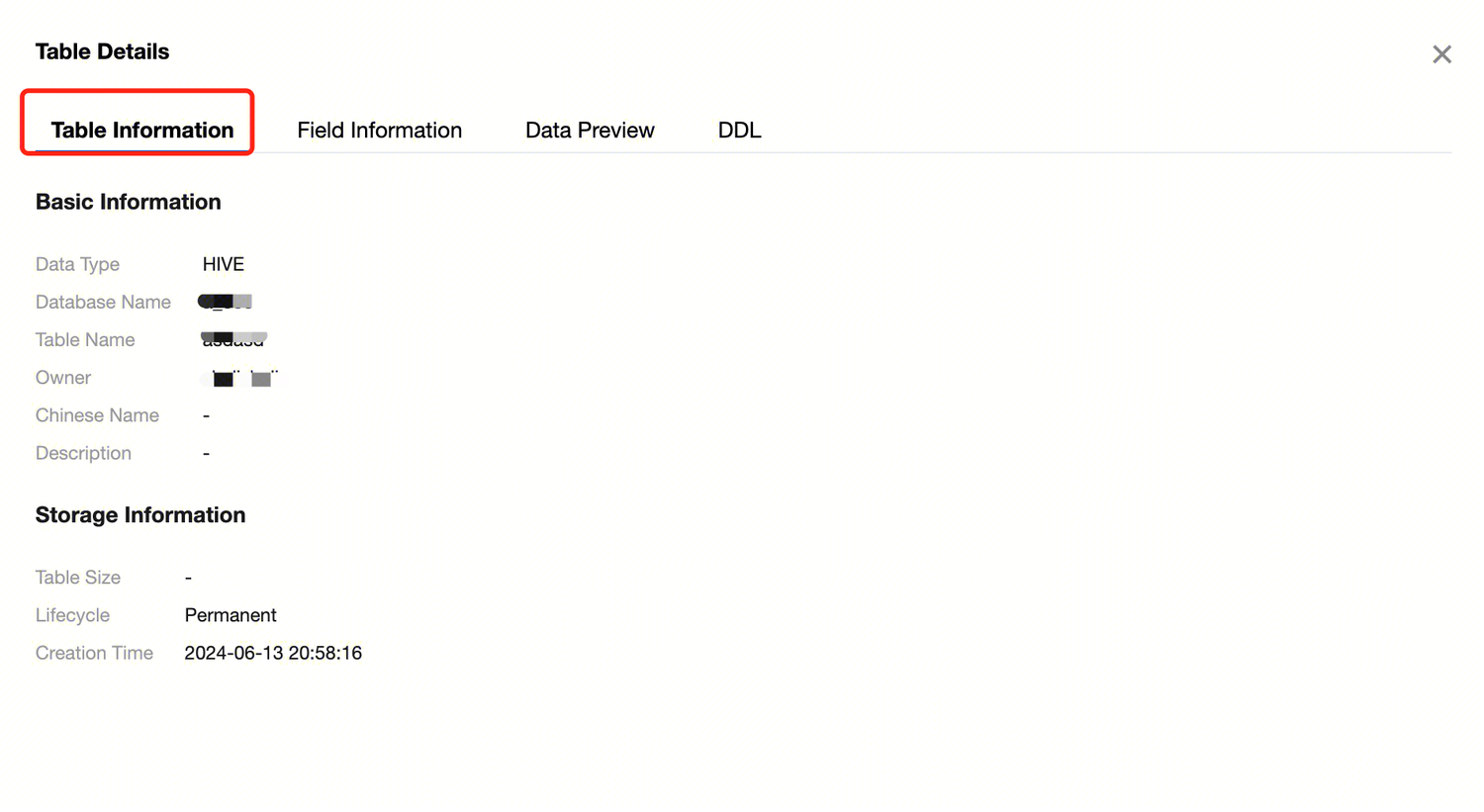
In the data management directory tree, move the cursor to the data table whose details you want to view, click to expand the data table operation menu, then click View Table Details to see basic information, storage information, field information, data preview, and table DDL. Table Information
Table detail information:
|
Basic information | Data Type | The storage and computing engine type to which the data table belongs. |
| Database name | The name of the database to which the data table belongs. |
| Table name | The identifier name of the data table. |
| Owner | The person in charge of the data table. |
| Chinese name | The Chinese name of the data table. |
| Description | User-defined description information. |
Storage Information | Table Size | The data in the current table has occupied physical storage space. |
| Lifecycle | The lifecycle of the current table is used to control its effective usage time, enhancing overall security and saving storage and computing resources during data governance. |
| Creation Time | Creation date and time of the current table. |
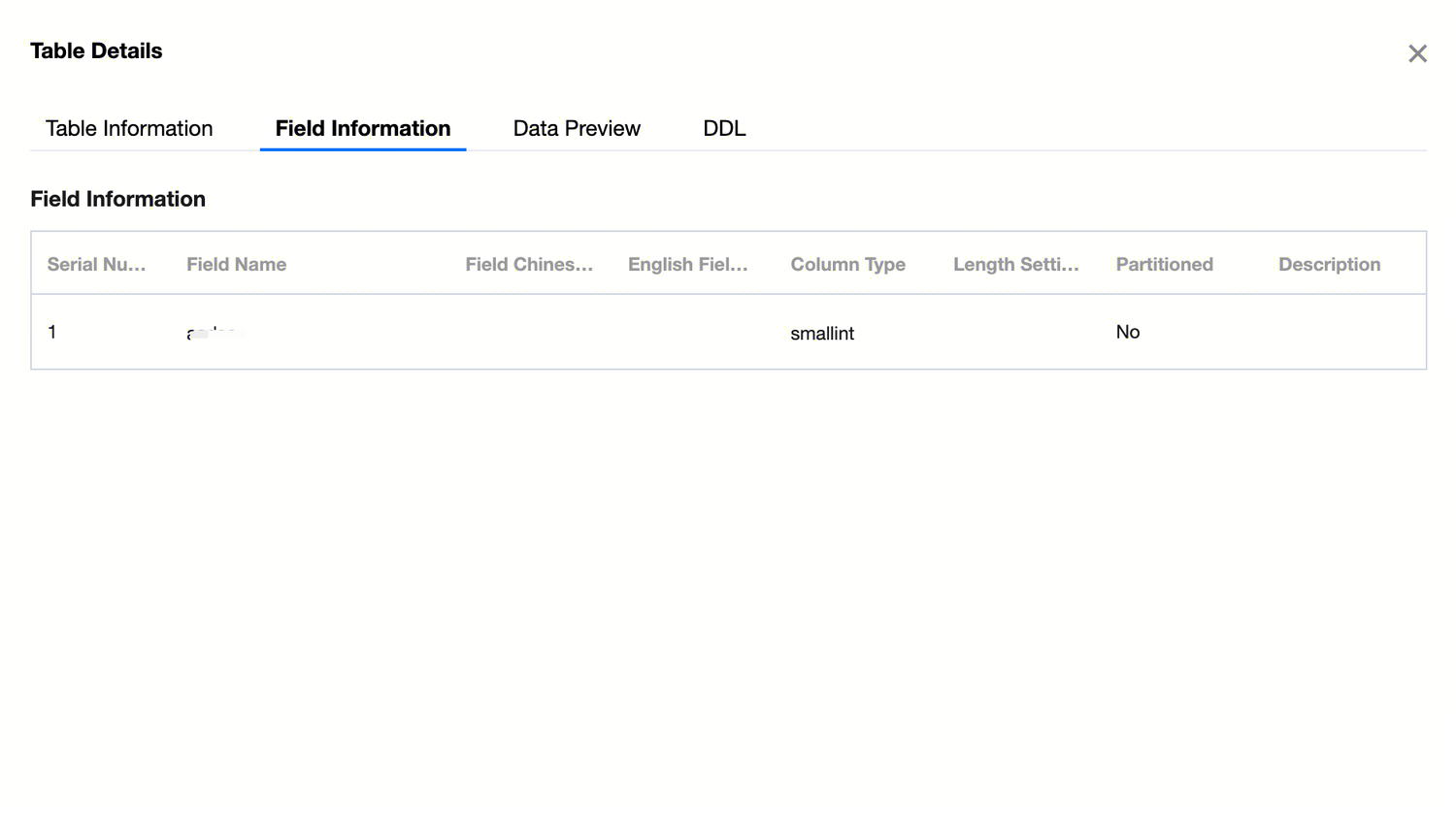
Field Information
Displays the field metadata of the current table, including field sequence number, field name, field Chinese name, field English name, column type, partition status, and description information.
Data preview
Capture a portion of the actual data in the current table as preview data to help users quickly understand the data in the table and provide references needed for data cleaning and data analysis.
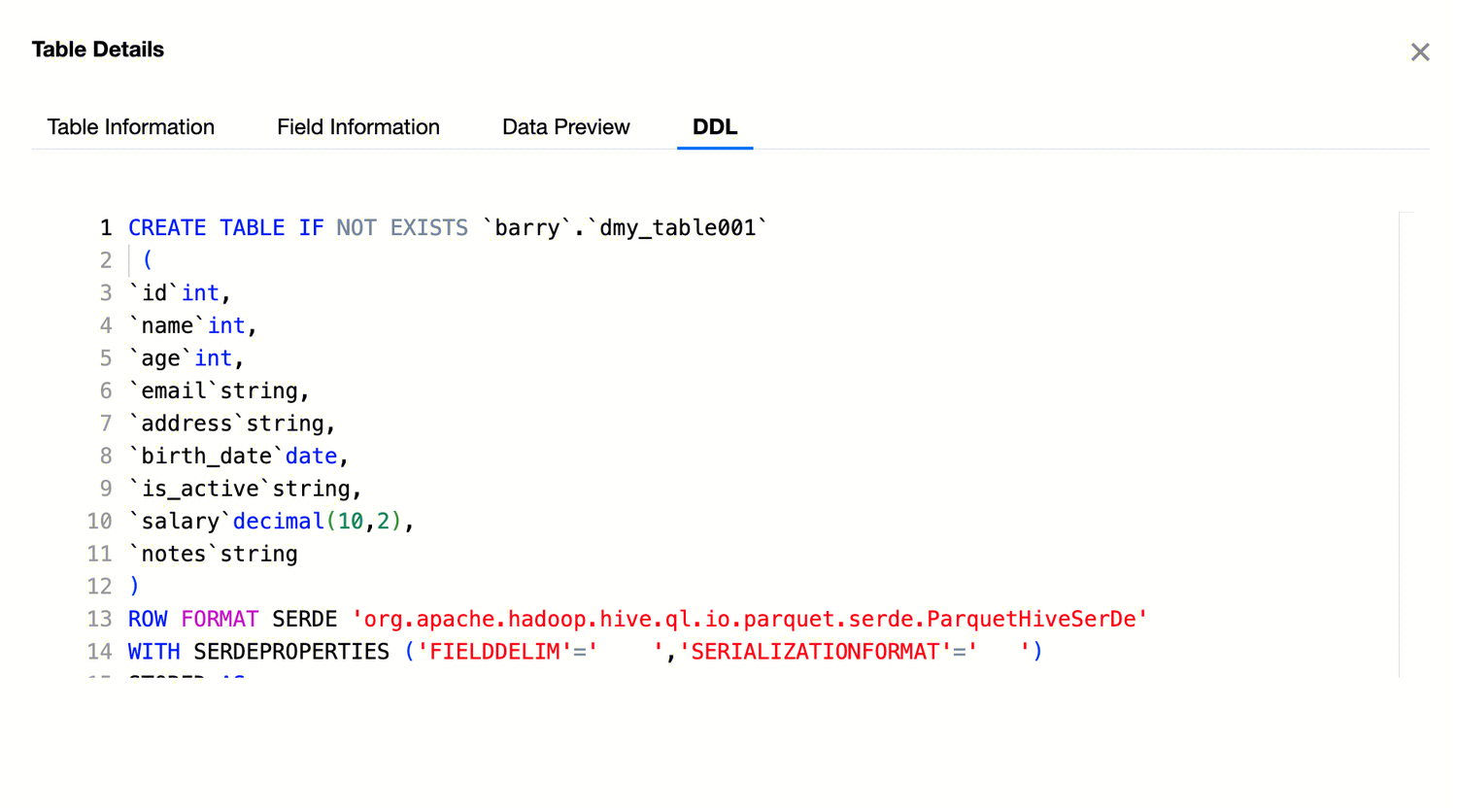
DDL
By viewing the table's DDL, you can understand important information such as table name, column names, data types, and constraints, thereby better understanding the structure and characteristics of the table.