2. Both Kafka and CKafka can select the Kafka data source and configure read and write settings according to Kafka steps.
Use Limits
When parameter.groupId and parameter.kafkaConfig.group.id are configured simultaneously, parameter.groupId has higher priority than the group.id in kafkaConfig settings.
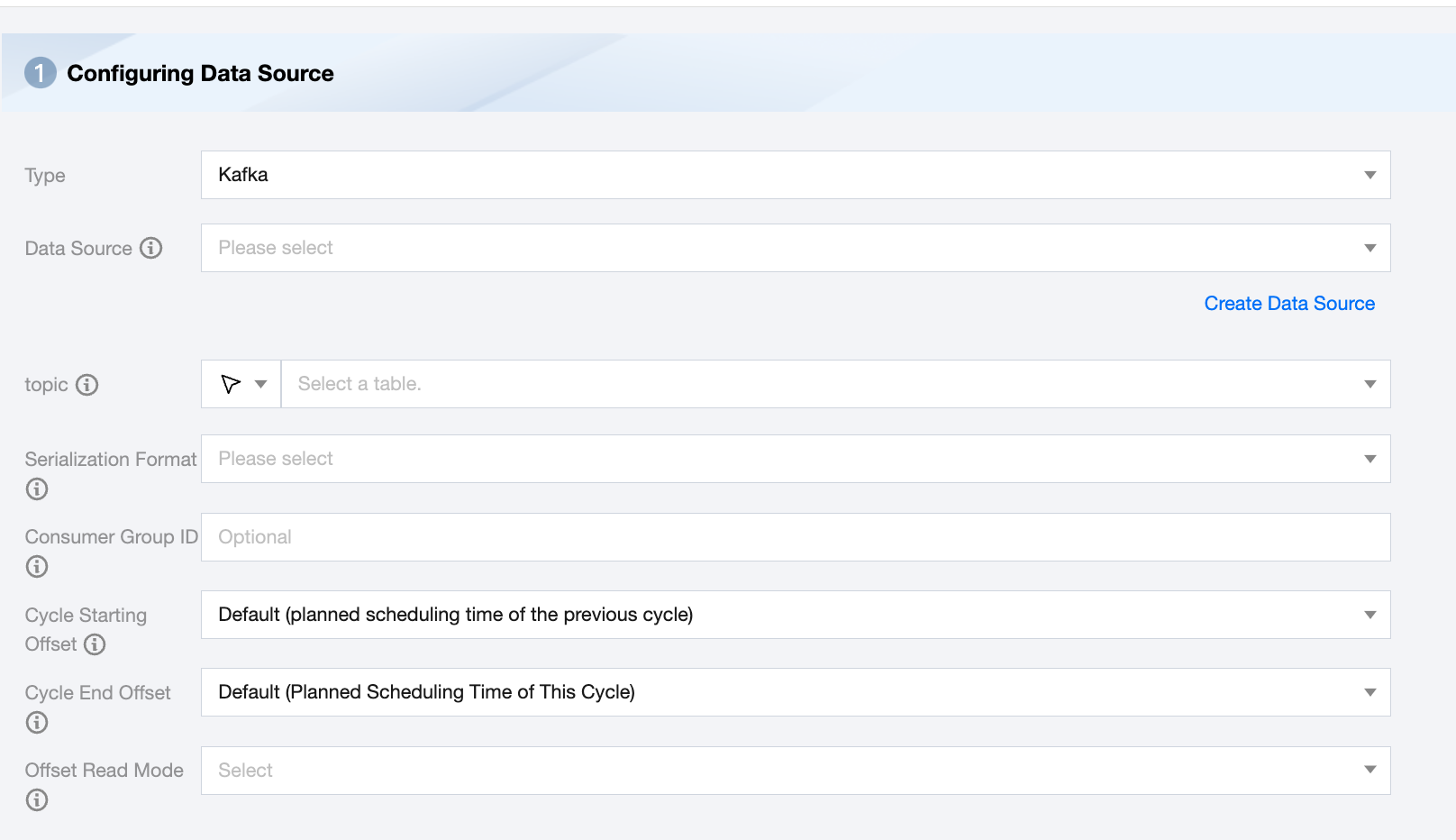
Kafka Offline Single Table Read Node Configuration
Parameters
Description
Data Source
The Kafka data source type supports Kafka and Ckafka.
topic
Kafka's Topic is an aggregation of messages sources that Kafka processes.
Serialization Format
Kafka data to be read supports constant columns, data columns, and attribute columns:
Constant Column: Columns wrapped in single quotes are constant columns, e.g., ["'abc'", "'123'"]
Data Column
If your data is in JSON format, it supports retrieving JSON attributes, e.g., ["event_id"]
If your data is in JSON format, it supports retrieving nested JSON attributes, e.g., ["tag.desc"]
Attribute Column
__key__ represents the message key
__value__ represents the full content of the message
__partition__ represents the partition of the current message
__headers__ represents the headers information of the current message
__offset__ represents the offset of the current message
__timestamp__ represents the timestamp of the current message
Consumer group ID
Avoid duplicating this parameter with other consumer processes to ensure the accuracy of the consumption offset. If this parameter is not specified, the default setting is group.id=WeData_group_${taskID}.
Cycle Starting Offset
When the task cycle runs, each time it reads from Kafka, it starts from the planned scheduling time of the previous cycle by default. Options: Start Offset of Partition, Current Offset of Consumer Group, Specified Time, Offset Specify Offset.
Specific Time: When data is written into Kafka, a unixtime timestamp is automatically generated as the record time for that data. The synchronization task reads the corresponding data from Kafka after converting the user-configured yyyymmddhhmmss value into a unixtimestamp. For example, "beginDateTime": "20210125000000".
Start Offset of Partition:Extract data from the smallest undeleted offset in each partition of the Kafka topic.
Current Offset of Consumer Group: Read data starting from the offset saved by the Consumer Group ID specified in the task configuration. Typically, this is the offset where the process using this Consumer Group ID last stopped (it's best to ensure that only this configured Data Integration task uses the Consumer Group ID to avoid data loss). If using the Consumer Group Current Offset, you must configure the Consumer Group ID. Otherwise, the Data Integration task will generate a random Consumer Group ID, and since the new Consumer Group ID has no saved offsets, it can cause errors or read data from the start or end offset based on the offset reset strategy. Additionally, the group offset is periodically and automatically submitted to the Kafka server by the client, so if the task fails and is rerun later, there may be duplicate or missing data. In wizard mode, records read beyond the end offset are automatically discarded. The discarded data's group offset has already been submitted to the server, making it inaccessible in the next cycle task run.
Cycle End Offset
When the task cycle runs, each time it reads from Kafka, it ends at the scheduled end time. By default, the encoding specified in this configuration item is used to parse strings when keyType or valueType is configured as STRING.
Offset Reading Mode
The starting offset for synchronizing data when manually running synchronization tasks. Two reading modes are provided:
latest: Read from the last offset position.
earliest: Read from the starting offset.
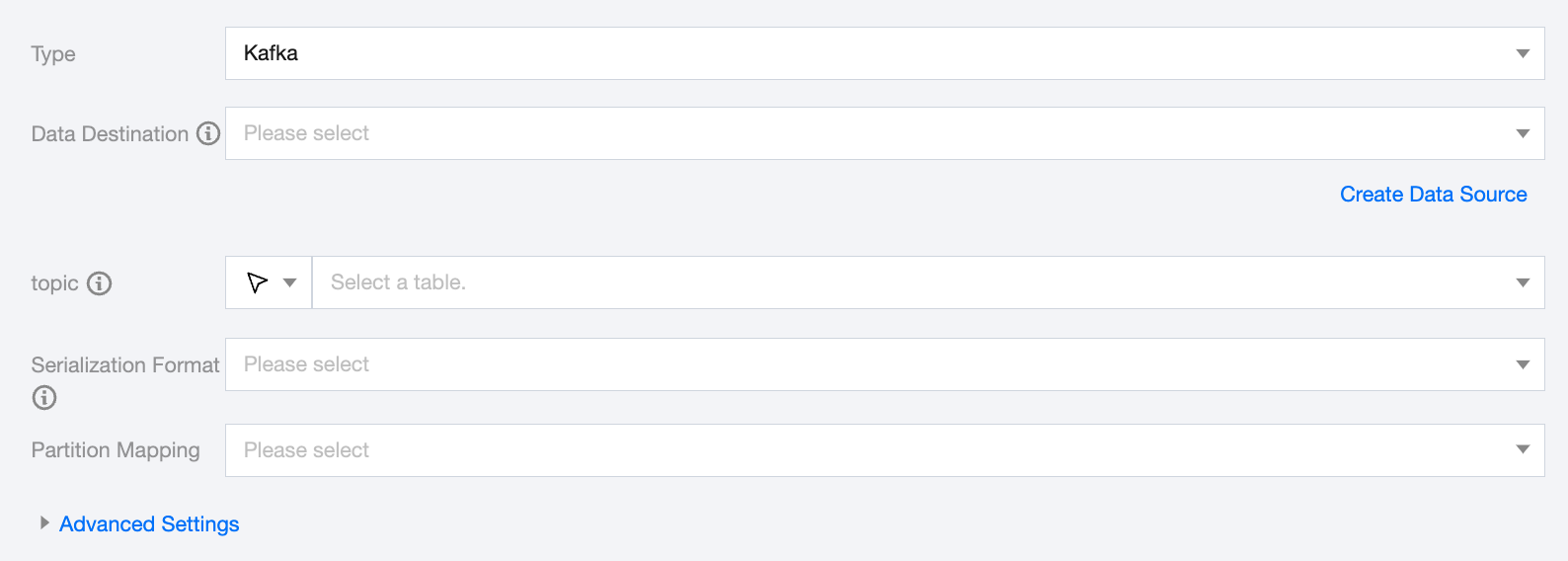
Kafka Offline Single Table Write Node Configuration
Parameters
Description
Data Destination
The Kafka data source type supports Kafka and Ckafka.
Topic
Kafka's Topic is an aggregation of messages sources that Kafka processes.
Serialization Format
Kafka data to be read supports constant columns, data columns, and attribute columns:
Constant Column: Columns wrapped in single quotes are constant columns, e.g., ["'abc'", "'123'"]
Data Column:
If your data is in JSON format, it supports retrieving JSON attributes, e.g., ["event_id"]
If your data is in JSON format, it supports retrieving nested JSON attributes, e.g., ["tag.desc"]
Attribute Column:
__key__ represents the message key.
__value__ represents the full content of the message.
__partition__ represents the partition of the current message.
__headers__ represents the headers information of the current message.
__offset__ represents the offset of the current message.
__timestamp__ represents the timestamp of the current message.
Partition Mapping
Supports round-robin partition write, specified field hash write, and specify partition modes.
If you choose specified field hash write mode, you need to specify the field name.
If you choose specify partition mode, you need to set the partition number.
Advanced Settings (Optional)
You can configure parameters according to business needs.
Data type conversion support
Read
Other data types are converted to String type by default.
Format of the value written to Kafka
Source Field Type
Internal Types
JSON
Integer,Long,BigInteger
Long
Float,Double
Double
Boolean
Bool
JSONArray,JSONObject
String
CSV
Integer,Long,BigInteger
Long
Float,Double
Double
Boolean
Bool
JSONArray,JSONObject
String
AVRO
Integer,Long,BigInteger
Long
Float,Double
Double
Boolean
Bool
JSONArray,JSONObject
String
Write
Other data types are converted to String type by default.