Tencent Cloud WeData
- Product Introduction
- Purchase Guide
- Execute Resource Purchase Description
- Preparations
- Add allowlist /security groups Overview (Optional)
- Operation Guide
- Console Operation
- Execution Resource Group Configuration
- Approval Management
- General Configuration
- Project Management
- Project Execution Resource Group
- Data Integration
- Integration resource configuration and management
- Real-time Synchronization Task Configuration and Operation and Maintenance
- Data Sources Supported by Real-time Synchronization
- Data Source List
- Whole Database Synchronization Task Configuration
- Single Table Synchronization Task Configuration
- Real-time synchronization operation and maintenance
- Real-time OPS
- Monitoring and Alarms
- Offline Synchronization Task Configuration and Operation and Maintenance
- Data Sources Supported by Offline Synchronization
- Data Source List
- DataInLong Offline Synchronization Configuration and Operation and Maintenance
- Data Development:Offline Synchronization, Configuration and Ops
- Offline Synchronization and Ops
- Practical Tutorial
- Data Development
- Engine User Guide
- Task Development
- Task Node Type
- General Node
- Task Scheduling Configuration
- Development Space
- Task Operation and Maintenance
- Data Analysis
- Data Assets
- Data Map
- Metadata Collection
- Metadata Management
- My Data
- My Responsibilities
- Managed by Me
- Configuration Management
- Data Security
- Data protection
- API Documentation
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operations APIs
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- DataInLong APIs
- Platform management related APIs
- Data Source Management APIs
- Asset Data APIs
- Related Agreement

EMR (EMR)

Last updated: 2024-11-01 16:26:14
WeData supports the integration of the EMR computing engine to create tasks such as Hive, MR, Spark, Trino, and Kyuubi, enabling table management and task configuration in EMR. This document introduces the precautions for task development using WeData on an EMR cluster.
Background
Elastic MapReduce (EMR) is a secure, low-cost, and highly reliable open-source big data platform based on cloud native technology and the pan-Hadoop ecosystem. It provides open-source big data components like Hive, Spark, HBase, Flink, StarRocks, Iceberg, and Alluxio, which are easy to deploy and manage, helping clients efficiently build a cloud-based enterprise-grade data lake architecture. Based on WeData and EMR, you can quickly build an open-source big data-based data warehouse. Please refer to the detailed steps in Creating and Managing EMR Clusters.
Use Limits
Limit | Restrictions |
EMR (Elastic MapReduce) Cluster Types | Currently, WeData supports EMR on CVM clusters but does not yet support EMR on TKE clusters. The currently supported versions for EMR creation are as follows: "EMR-V2.0.1" "EMR-V2.2.0" "EMR-V2.3.0" "EMR-V2.5.0" "EMR-V2.6.0" "EMR-V2.7.0" "EMR-V3.0.0" "EMR-V3.1.0" "EMR-V3.2.0" "EMR-V3.2.1" "EMR-V3.3.0" "EMR-V3.4.0" "EMR-V3.5.0" |
WeData feature | The types of EMR tasks supported in WeData data development include HiveSQL, SparkSQL, Spark, MapReduce, PySpark, Shell, Impala, and Trino. For Kyuubi data sources, tasks need to use the SparkSQL type. |
Getting Started
The main steps to use EMR in WeData are as follows:
Preparations
Preparation Category | Operation Description | Reference Links |
EMR (EMR) | To ensure the smooth use of EMR-related table creation and data development features in WeData, it is necessary to ensure that the EMR cluster meets basic configurations. At least, Hive and Spark services need to be installed in the EMR cluster. Other services, if used in WeData, also need to be enabled in EMR, such as Ranger and Kyuubi. | - |
WeData | Bind the EMR cluster and obtain the latest cluster configuration from the EMR cluster. Configure the corresponding authentication method and account mapping. 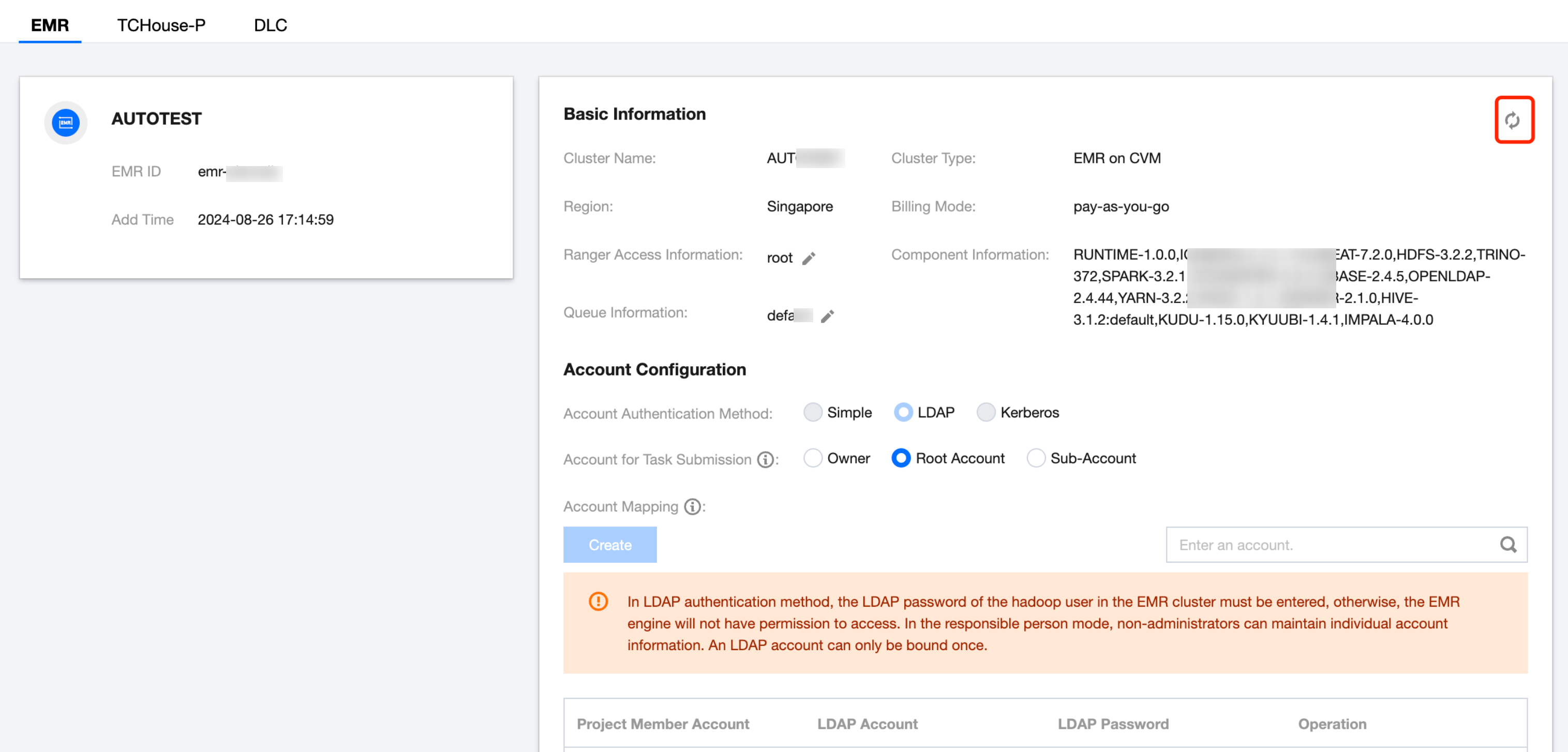 | - |
Task Development
Creating workflow
Task development is based on data workflow orchestration to achieve the procedural execution of computing tasks. Before creating computing tasks, you need to create a data workflow and then orchestrate the computing task execution process within the workflow.
Create EMR Node
WeData performs task development based on the EMR engine. Different types of component services on the EMR cluster are integrated into WeData as default system data sources (Hive, Trino, Kyuubi, and Impala). Users can select appropriate components to create EMR service resources according to business needs and bind EMR clusters to projects in WeData. For details on creating EMR component services, please see Adding EMR Components.
Task Development
After the EMR engine is bound to the WeData project, create the types of computing tasks supported by EMR in the created data workflow. During the task node configuration process, use the system data source provided by EMR for task development and debugging.
Submitting the job
Once debugging with the EMR system source data is verified, save the corresponding computing task, and after submitting and publishing the workflow containing the computing task, it can be scheduled and executed in the Operations Center.
Related Operations
After completing EMR task development, you can perform EMR data asset management, data quality monitoring, and data security management in WeData, ensuring that EMR data is correctly produced and implementing process control for data quality and data security.
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No