DataInLong provides real-time entire database and single table write capabilities for DLC. This article introduces the current capabilities supported for real-time data synchronization using DLC.
Use Limits
Currently, only DLC Iceberg format tables are supported.
When choosing Upsert mode for synchronization, the DLC table must be a V2 table, and the setting write.upsert.enabled=true must be enabled.
When choosing Upsert mode for synchronization, you must specify the primary key. If it is a partition table, the partition field must also be added to the primary key.
Preparing the Database Environment
Check if WeData has permission to access DLC
1. Log in to the Tencent Cloud Console and go to the CAM (CAM) page.
2. In the left menu, select Users and find the user you need to bind the policy to.
3. Click the user's name to enter the user details page. In the Permissions section, search for QcloudWeDataExternalAccess . If this policy is already associated, you can skip the following steps.
4. On the user details page, find the Permission Management module under the Associated Policy section.
5. Click the Associated Policy 's New Association button. Select Select Policy from Policy List , and input QcloudWeDataExternalAccess .
6. Select QcloudWeDataExternalAccess, click the Next button to complete the policy binding.
7. Upon successful binding, the user can use the permissions defined in the QcloudWeDataExternalAccess policy.
Check whether the table is a V1 table or a V2 table (optional)
Real-time synchronization to DLC supports two modes: Append Mode and Upsert Mode . Upsert mode must be for Iceberg V2 tables and the setting write.upsert.enabled=true must be enabled. Append mode supports both Iceberg V1 tables and Iceberg V2 tables in Append mode (write.upsert.enabled=false).
The following command can be used to view the attributes of the created table:
SHOW TBLPROPERTIES `DataLakeCatalog`.`databases_name`.`table_name`;
The returned result is as follows: format-version = 2 indicates that a V2 table is created. If you have created a V1 table and want to change it to a V2 table, you can refer to Modify Table Attributes .
Create a DLC table (optional)
Real-time tasks support automatically creating target tables in DLC if they do not exist during task execution. Users can choose to create the target tables in DLC beforehand or let the real-time migration tasks create them automatically.
1. Create V1 Table
DLC default tables are created as V1 Tables, which do not support Upsert Mode. Refer to the table creation statement below:
Upsert: Update write. When there is no primary key conflict, a new row can be inserted; when there is a primary key conflict, an update is performed. Suitable for scenarios where the target table has a primary key and needs to be updated in real-time based on the source data. There will be some performance overhead.
Append: Append write. Regardless of whether there is a primary key, data is appended by inserting new rows. Whether there is a primary key conflict depends on the target end. Suitable for scenarios where there is no primary key and data duplication is allowed. No performance loss.
Full Append + Incremental Upsert: Automatically switches data writing modes based on the source data synchronization stage. In the full stage, Append write is used to improve performance; in the incremental stage, Upsert write is used for real-time data updates. This mode currently supports data sources from MySQL, TDSQL-C MySQL, TDSQL MySQL, Oracle, and PostgreSQL.
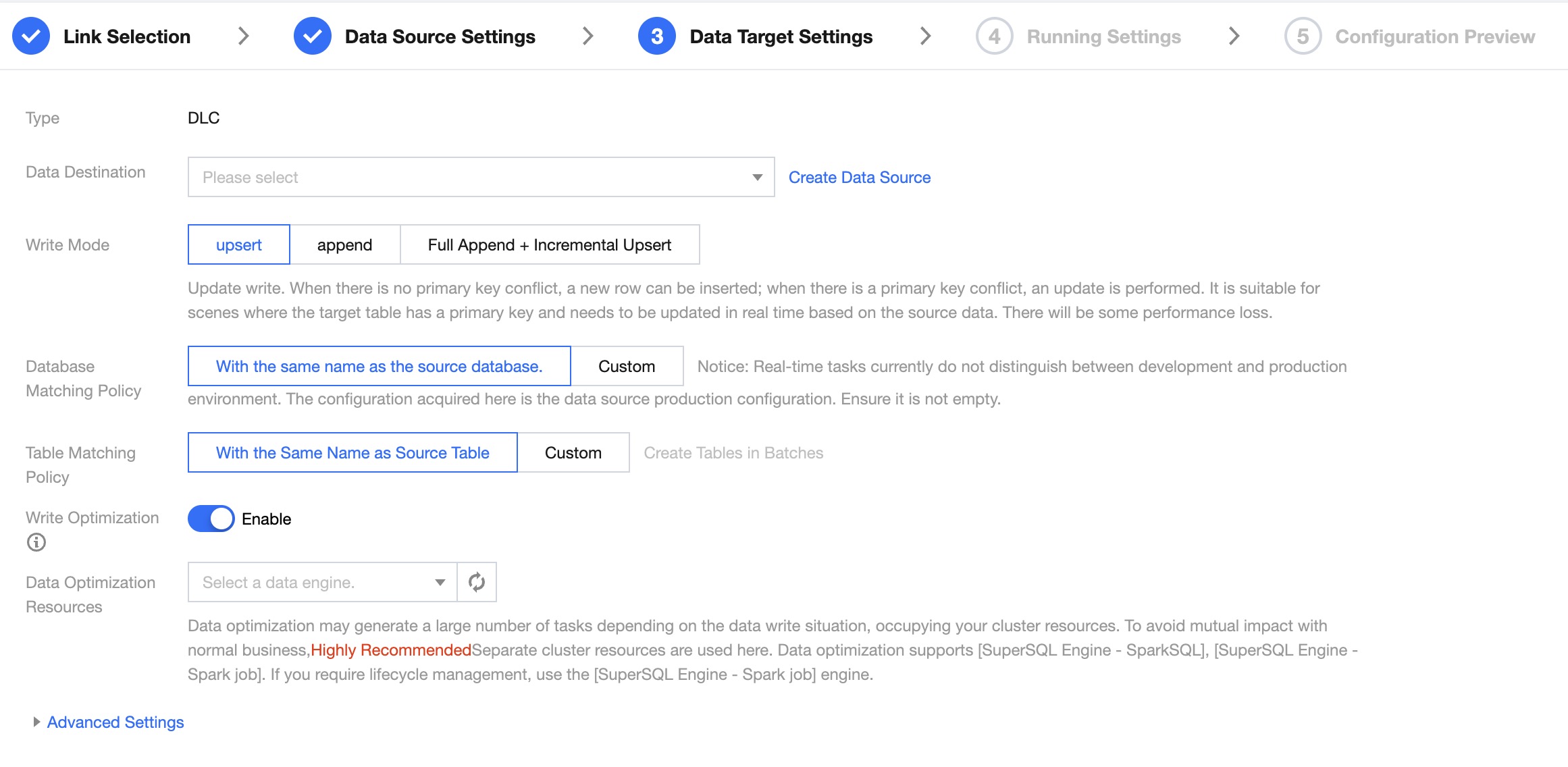
Database/Table Matching Policy
Name matching rules for database and data table objects in DLC.
Write Optimization
Write optimization is suitable for scenarios with frequent or real-time writing. Enabling write optimization will automatically merge files and delete expired snapshots. It is strongly recommended to enable write optimization in real-time Upsert writing scenarios. For details, please refer to Data Optimization.
Note:
Integration tasks currently only support the default configuration of DLC write optimization. If users need to modify the relevant configuration, please go to the DLC page to make changes.
Data Optimization Resources
Data optimization tasks may consume a significant amount of your cluster resources, depending on the data writing situation. To avoid impacting normal business, it is strongly recommended to use separate cluster resources for data optimization. Data optimization supports SuperSQL Engine > SparkSQL, SuperSQL Engine > Spark Jobs. If you require lifecycle management, please use SuperSQL Engine > Spark Jobs engine.
Advanced Settings
You can configure parameters according to business needs.
Single Table Writing Node Configuration
1. On the DataInLong page, in the left sidebar, click Real-time Sync.
2. At the top of the Real-time Sync page, select Single Table Sync to create a new one (you can choose between form and canvas modes) and enter the configuration page.
3. You can refer to the table below to configure parameter information.
Parameters
Description
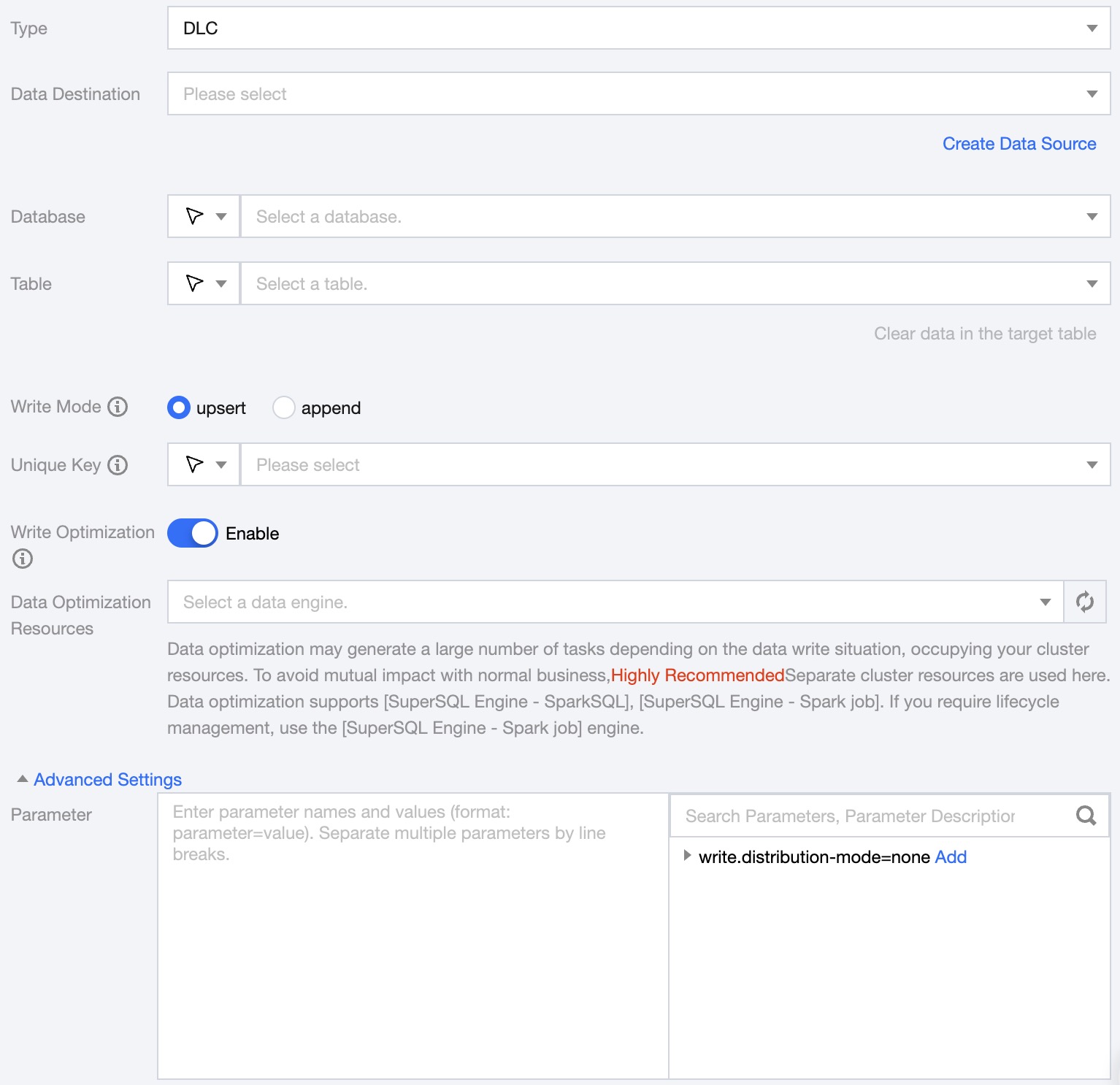
Data Destination
DLC Data Source to be written.
Database
Supports selection or manual input of the database name to write to
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the DataInLong network is connected.
Table
Support selection or manual entry of the table name to be written to.
If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the DataInLong network is connected.
Write Mode
DLC real-time synchronous writing supports two to three modes:
Upsert: Update write. When there is no primary key conflict, a new row can be inserted; when there is a primary key conflict, an update is performed. Suitable for scenarios where the target table has a primary key and needs to be updated in real-time based on the source data. There will be some performance overhead.
Append: Append write. Regardless of whether there is a primary key, data is appended by inserting new rows. Whether there is a primary key conflict depends on the target end. Suitable for scenarios where there is no primary key and data duplication is allowed. No performance loss.
Full Append + Incremental Upsert: Automatically switches data writing modes based on the source data synchronization stage. In the full stage, Append write is used to improve performance; in the incremental stage, Upsert write is used for real-time data updates. This mode currently supports data sources from MySQL, TDSQL-C MySQL, TDSQL MySQL, Oracle, and PostgreSQL.
Unique Key
In Upsert write mode, a unique key needs to be set to ensure data ordering, and multiple selections are supported.
Write Optimization
Write optimization is suitable for scenarios with frequent or real-time writing. Enabling write optimization will automatically merge files and delete expired snapshots. It is strongly recommended to enable write optimization in real-time Upsert writing scenarios. For details, please refer to Data Optimization.
Note:
Integration tasks currently only support the default configuration of DLC write optimization. If users need to modify the relevant configuration, please go to the DLC page to make changes.
Data Optimization Resources
Data optimization may generate a large number of tasks depending on the data writing situation, consuming your cluster resources. To avoid affecting normal business, it is highly recommended to use separate cluster resources here. Data optimization supports SuperSQL Engine > SparkSQL, SuperSQL Engine > Spark Job. If there is a need for lifecycle management, please use SuperSQL Engine > Spark Job.
Advanced Settings
You can configure parameters according to business needs.
Write Data Type Conversion Supported
Internal Types
Iceberg Type
CHAR
STRING
VARCHAR
STRING
STRING
STRING
BOOLEAN
BOOLEAN
BINARY
FIXED(L)
VARBINARY
BINARY
DECIMAL
DECIMAL(P,S)
TINYINT
INT
SMALLINT
INT
INTEGER
INT
BIGINT
LONG
FLOAT
FLOAT
DOUBLE
DOUBLE
DATE
DATE
TIME
TIME
TIMESTAMP
TIMESTAMP
TIMESTAMP_LTZ
TIMESTAMPTZ
INTERVAL
-
ARRAY
LIST
MULTISET
MAP
MAP
MAP
ROW
STRUCT
RAW
-
FAQs
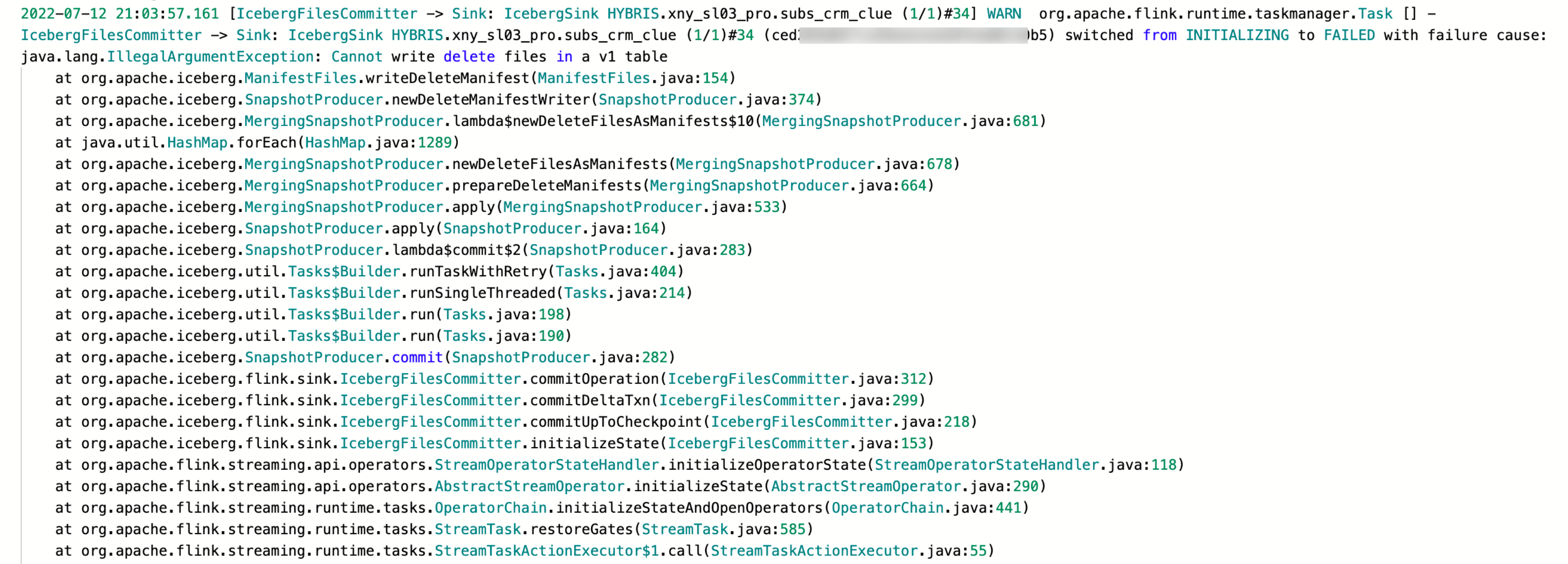
Error synchronizing incremental data (changlog data) to DLC
Error message:
Cause:
The table in DLC is a V1 Table and does not support changlog data.
Solution:
1. Modify the DLC table to V2 Table and enable Upsert support.
2. Enable Upsert support for the table: ALTER TABLE tblname SET TBLPROPERTIES ('write.upsert.enabled'='true').
3. Modify the table to V2 Table: ALTER TABLE tblname SET TBLPROPERTIES ('format-version'='2').
Check if the table properties were set successfully: show tblproperties tblname.
Cannot write incompatible dataset to table with schema
at org.apache.iceberg.types.TypeUtil.checkSchemaCompatibility(TypeUtil.java:364)
at org.apache.iceberg.types.TypeUtil.validateWriteSchema(TypeUtil.java:323)
Reason:
When the user creates a DLC table, the field is set with a NOT NULL constraint.
Solution:
Do not set the NOT NULL constraint when creating the table.
Error during synchronization from mysql2dlc, array out of bounds
Issue details:
java.lang.ArrayIndexOutOfBoundsException:1
at org.apache.flink.table.data.binary.BinarySegmentUtils.getLongMultiSegments(BinarySegmentUtils.java:736)~[flink-table-blink_2.11-1.13.6.jar:1.13.6]
at org.apache.flink.table.data.binary.BinarySegmentUtils.getLong(BinarySegmentUtils.java:726)~[flink-table-blink_2.11-1.13.6.jar:1.13.6]
at org.apache.flink.table.data.binary.BinarySegmentUtils.readTimestampData(BinarySegmentUtils.java:1022)~[flink-table-blink_2.11-1.13.6.jar:1.13.6]
at org.apache.flink.table.data.binary.BinaryRowData.getTimestamp(BinaryRowData.java:356)~[flink-table-blink_2.11-1.13.6.jar:1.13.6]
at org.apache.flink.table.data.RowData.lambda$createFieldGetter$39385f9c$1(RowData.java:260)~[flink-table-blink_2.11-1.13.6.jar:1.13.6]
Reason:
The issue is caused by using the Time Field as the primary key.
Solution:
1. Do not use the Time Field as the primary key.
2. The user still needs a timestamp field to ensure uniqueness. It is recommended to add a redundant string field in DLC, convert the upstream timestamp field using a function, and map it to the redundant field.
DLC task reports it's not an Iceberg Table
Error message:
Reason:
1. The user can execute statements in DLC to check the actual type of the table.
2. Statement: desc formatted table_name.
3. You can check the table type.
Solution:
Choose the correct engine to create an Iceberg type table.
The field order of Flink SQL and the DLC target table is inconsistent, causing an error