By setting this parameter, new tables can be detected after pausing and continuing. The default is false
1. When using this parameter for full incremental synchronization, the new tables will read the existing data first, and then read the incremental data
2. When using this parameter for incremental synchronization, the new tables will only read the incremental data
Read
Single Table + Whole Database
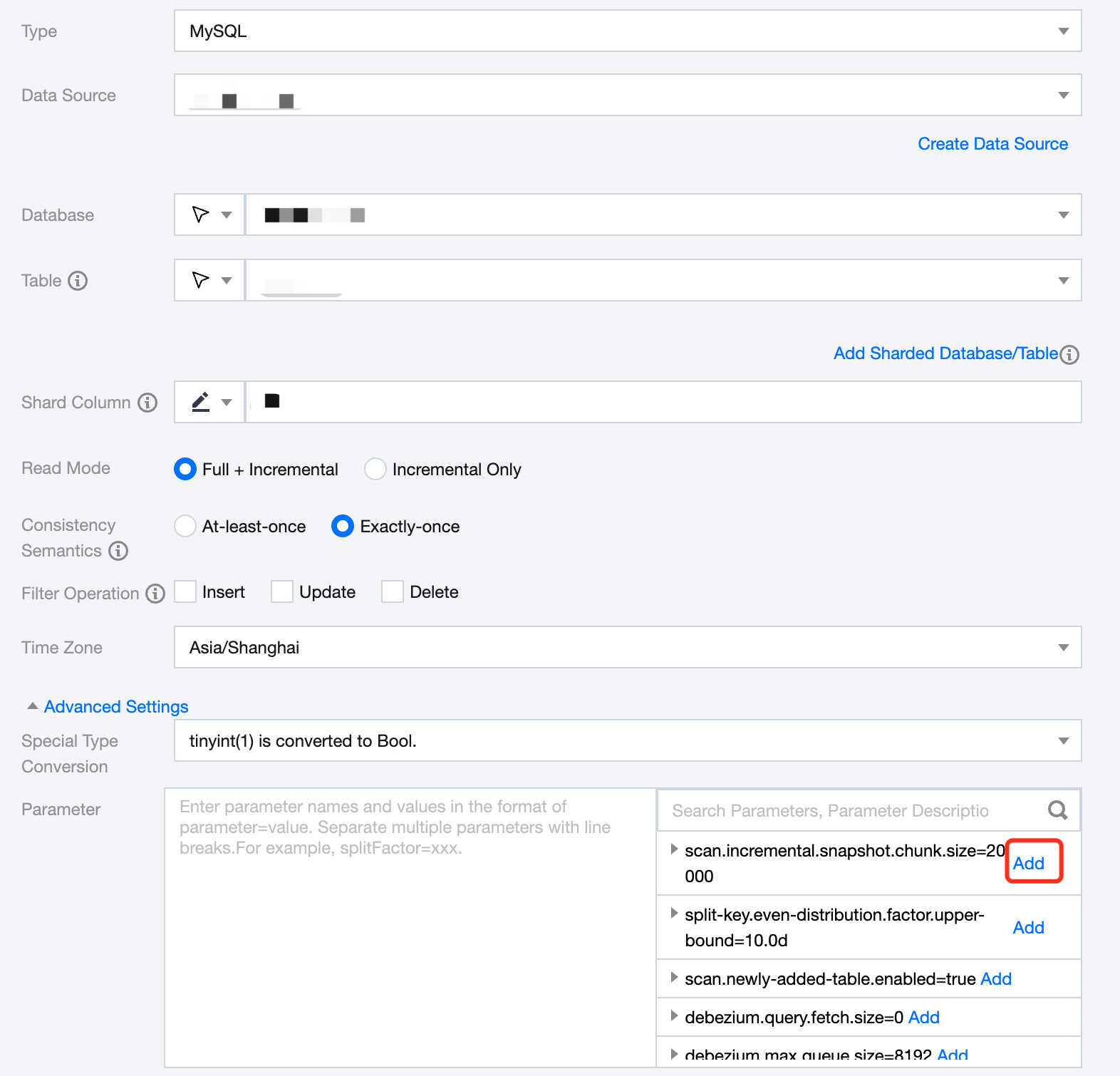
scan.incremental.snapshot.chunk.size=20000
Parameter Description:
For tasks with uniform data distribution, this parameter represents the approximate number of entries within a chunk. You can estimate the number of chunks by dividing the total data volume by the chunk size. The number of chunks affects whether the job manager (jobmanager) runs out of memory (OOM). Currently, with 2CU, it can support more than 100,000 chunks. If the data volume is too large, we can increase the chunk size to reduce the number of chunks
Notes:
For large volume data tasks (e.g., total data volume over 100 million, single record larger than 0.1M), it is generally recommended to set this to 20,000
During the MySQL existing data read phase, if the data is relatively sparse and the maximum value of the primary key field is extremely large, you can modify this parameter to use unequal segmentation, reducing the problem of too many chunks due to the extremely large primary key value, and thus preventing the job manager from running out of memory (OOM)
Notes:
The default value is 10.0d, typically no need to modify it
Read
Single Table + Whole Database
debezium.query.fetch.size=0
Parameter Description:
Represents the number of records fetched from the database each time. The default is 0, representing the jdbc default fetch size
Notes:
1. For large tasks (e.g., total data volume over 100 million, single record larger than 0.1M), it is recommended to fetch 1024 records if there's only one read instance
2. If the task has multiple read instances, it is recommended to lower this value to reduce memory consumption, suggested value is 512 records
Read
Single Table + Whole Database
debezium.max.queue.size=8192
Parameter Description:
The Definition attribute sets the maximum number of events stored in the internal queue. If this limit is reached, Debezium will pause reading new events until the pending events are processed and committed. This attribute helps prevent too many events from piling up in the queue, causing memory exhaustion and performance degradation. The default is 8192
Notes:
1. For large tasks (e.g., total data volume over 100 million, single record larger than 0.1M), if there's only one read instance, it is recommended to fetch 4096 records
2. If the task has multiple read instances, it is recommended to lower this value to reduce memory consumption, suggested value is 1024 records
Job level
-
-
taskmanager.memory.managed.fraction=0.1
Parameter Description:
Adjust the flink program taskmanager managed memory ratio
-
-
table.exec.sink.upsert-materialize=NONE
Parameter Description:
Due to the out-of-order Changelog data caused by shuffle in a distributed system, the data received by the sink may be out of order in the global upsert, so an upsert materialization operator should be added before the upsert sink. This operator receives upstream changelog data and generates an upsert view for downstream. This parameter is used to control the addition of the materialization operator
Notes:
1. By default, this materialization operator will be added when a unique key encounters distributed disorder, but you can choose not to materialize (NONE) or force materialization (FORCE)
2. Optional values are: NONE, AUTO, FORCE
-
-
table.exec.sink.not-null-enforcer=DROP
Parameter Description:
Decides how the task handles null values when a NOT NULL field encounters a null value
Suggested Value and Function:
1. ERROR: Throws a runtime exception when a NOT NULL field encounters a null value.
2. DROP: Discards data directly when a NOT NULL field encounters a null value
It is recommended to set tm cu to 2CU to avoid tm OOM
oracle
Node Level
Read
Single Table + Whole Database
'debezium.log.mining.strategy' = 'online_catalog'
'debezium.log.mining.continuous.mine' = 'true'
Parameter Description:
Enabling this parameter can reduce data synchronization delay and decrease redo log storage. Suitable for single table synchronization + whole database synchronization (specified table)
Notes:
1. After setting, new tables cannot be detected. If you configure to synchronize all database tables / specified databases, new table data cannot be read
2. Not applicable to Oracle19 versions that do not support this parameter. Therefore, it needs to be set to false, otherwise it will cause task failure.
Node Level
Read
Single Table + Whole Database
debezium.lob.enabled=false
Parameter Description:
Whether to synchronize blob type data, default is false
Notes:
1. If set to true, it may affect synchronous performance
2. The default recommended configuration for Oracle is false
mongodb
Node Level
Read
Single Table Only
scan.incremental.snapshot.enabled=true
Parameter Description:
Enable concurrent reads; the default is false
Notes:
Supported only in MongoDB version 4.0 and above
Node Level
Read
Single Table Only
copy.existing=false
Parameter Description:
Copy existing data from the source collection:
1. The default is true, meaning data is read from full volume
2. False means data is read from the increment
Node Level
Read
Single Table Only
poll.await.time.ms
Parameter Description:
Change event pull interval, default is 1500ms
Notes:
1. For collections with frequent changes, the pull interval can be reduced to improve processing timeliness
2. For collections with slow changes, the pull interval can be increased to reduce database pressure
Node Level
Read
Single Table Only
poll.max.batch.size
Parameter Description:
Maximum number of change events pulled per batch, default is 1000
Notes:
Increasing this parameter will speed up pulling change events from the cursor but will increase memory overhead
Node Level
Read
Single Table Only
scan.incremental.snapshot.chunk.size.mb
Parameter Description:
The chunk size for incremental snapshots is 64mb by default, unit is mb
Node Level
Read
Single Table Only
changelog.normalize.enabled
Parameter Description:
Enable changelogNormalize operator; the default is true, meaning it's enabled
Notes:
MongoDB lacks -u message, enabling this operator will supplement the -u message but will consume some performance. Disabling this operator will improve transfer speed, but delete operations cannot be synchronized downstream. Other operations are not affected
Node Level Configuration
Task Level Configuration
Note:
1. One parameter per line; if parameters need to be used together, write them on the same line.