DataInLong provides Oracle read and write capabilities. This article introduces the pre-environment configuration and current capability support for real-time data synchronization using Oracle.
Supported Versions
Currently, DataInLong supports Oracle single table and database-level real-time reading and single table writing. To use real-time synchronization capabilities, the following version limitations must be observed:
Use Limits
Oracle read-only replicas only support logical standby, physical standby is not supported.
Tables without primary keys may have data duplication since exactly once cannot be guaranteed. Therefore, it is best to ensure the table has a primary key for real-time sync tasks.
To monitor table field changes on the Oracle side, do not configure the data source with the system/sys accounts, otherwise, all tables (including newly added tables) must enable log tracking for synchronization.
Preparing the Database Environment
Authorize database permissions
The main tasks are to create basic synchronization users and grant permissions to pull existing data. Grant read permissions for views that need to be used and for tables to be imported.
The main purpose of the ANALYZE ANY privilege is to read the table structure and unique index. When a table does not have a primary key, a unique index can be used instead of a primary key.
sqlplus sys/password@host:port/SID AS SYSDBA;
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
GRANT CREATE SESSION TO flinkuser;
GRANT SET CONTAINER TO flinkuser;
GRANT SELECT ANY TABLE TO flinkuser;
GRANT SELECT_CATALOG_ROLE TO flinkuser;
GRANT ANALYZE ANY TO flinkuser;
Enable log archiving
Enable the generation of logical logs, otherwise Oracle cannot correctly generate part of the logs, making incremental data synchronization impossible.
1. Connect using the DBA account.
sqlplus sys/password@host:port/SID AS SYSDBA
2. Enable log archivingdisabling it will prevent reading incremental data.
alter system set db_recovery_file_dest_size = 10G;
alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
Notes: Enabling log archiving requires a database restart and will occupy disk space
3. Check whether it is enabled.
4. Enable supplemental log
If not enabled, the non-updated fields in an Update will all be empty.
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Alternatively, you can enable it globally:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
5. Create Tablespace
It is recommended to create a separate table space for real-time synchronization users, although an existing table space can also be reused.
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/SID/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE 2048M;
Grant the permissions to read logs via logminer
GRANT SELECT ON V_$DATABASE to flinkuser;
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
GRANT LOGMINING TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
GRANT SELECT ON V_$LOG TO flinkuser;
GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
GRANT SELECT ON V_$LOGFILE TO flinkuser;
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser;
exit;
Database source configuration
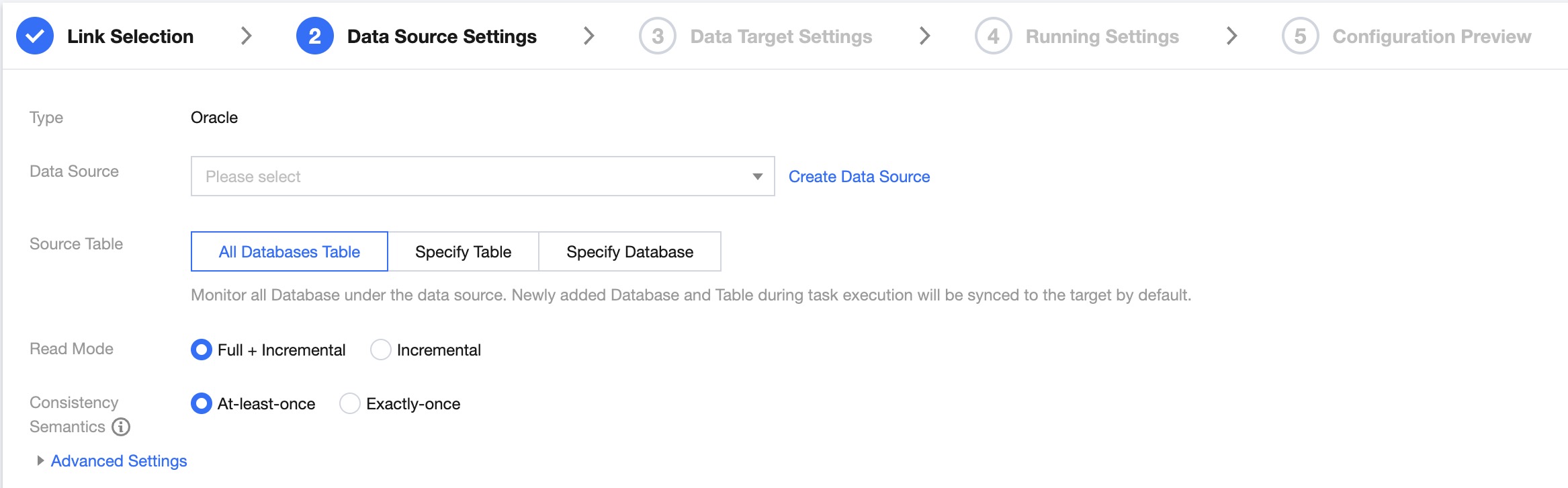
Data source settings
|
Data Source | Select the Oracle data source to be synchronized |
Source Table | According to business needs, choose "All Database Tables", "Specified Table", or "Specified Database" |
| All Database Tables: Monitor all databases under the data source. New databases and tables added during the task run will be synchronized to the target by default Specified Table: Only synchronize the specified table Specified Database: Monitor the specified database and schema. Synchronize all or matching tables under the schema |
|
|
|
|
Read Mode | Full + Increment: Data synchronization is divided into full and increment phases. After the full phase is completed, the task enters the increment phase. The full phase will synchronize historical data in the database, and the incremental phase starts synchronizing from the binlog cdc location after the task starts. Increment: Only synchronize data from the binlog cdc position after the task starts. |
Consistency Semantics | Only represents the consistency semantics of the reading end. Supports At-least-once and Exactly-once. At-least-once: Data may be read more than once, relying on the destination end's deduplication to ensure data consistency. Suitable for scenarios with large data volumes in the full phase and using non-numeric primary keys, with high synchronization performance requirements. Exactly-once: Data is read strictly once, with some performance losses. Tables without a primary key and unique index column are not supported. Suitable for general scenarios where the source table has a numeric primary key or unique index column. The current version's two modes are state-incompatible. If the mode is changed after task submission, stateful restart is not supported. |
Advanced Settings (optional) | You can configure parameters according to business needs |
Note:
To monitor table field changes on the Oracle side, do not configure the data source with the system/sys accounts, otherwise, all tables (including newly added tables) must enable log tracking for synchronization.
Activate Command:
ALTER TABLE SCHEMA_NAME.TBALE_NAME ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Single Table Read Node Configuration
1. In the DataInLong page, click Real-time synchronization on the left directory bar.
2. In the real-time synchronization page, select Single Table Synchronization at the top to create a new one (you can choose either form or canvas mode) and enter the configuration page.
|
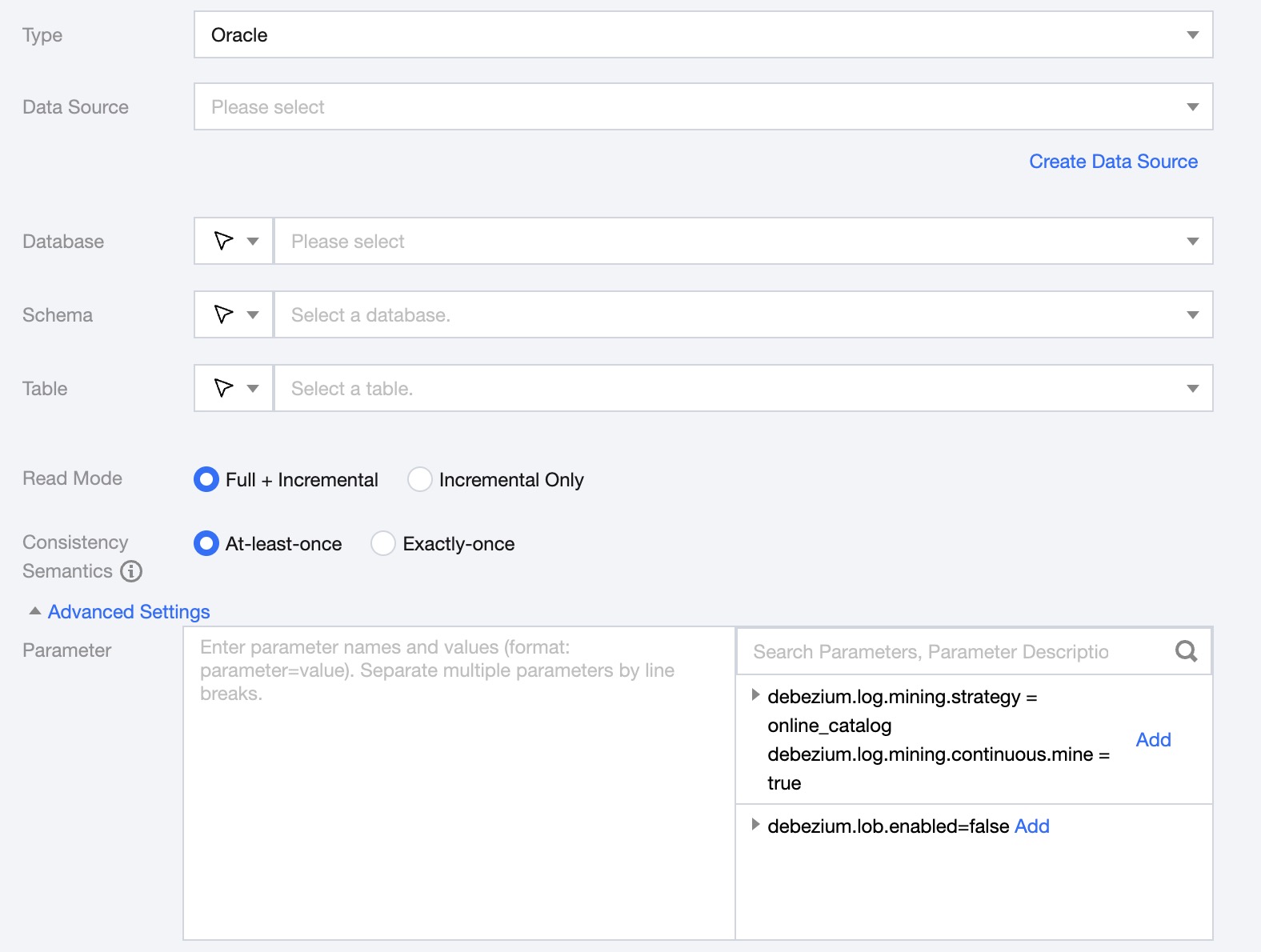
Data Source | Select the data source where the table to be synchronized is located. |
Database | Supports selection or manual input of the library name to read from. By default, the database bound to the data source is used as the default database. Other databases need to be manually entered. If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected. |
Schema | Support selection or manual input of available schema under this data source. |
Table | Supports selecting or manually entering the table name to be read. |
Read Mode | Full + Increment: Data synchronization is divided into full and increment phases. After the full phase is completed, the task enters the increment phase. The full phase will synchronize historical data in the database, and the incremental phase starts synchronizing from the binlog cdc location after the task starts. Increment Only: Only synchronize data from the binlog cdc position after the task starts. |
Consistency Semantics | Only represents the consistency semantics of the reading end. Supports At-least-once and Exactly-once. At-least-once: Data may be read more than once, relying on the destination end's deduplication to ensure data consistency. Suitable for scenarios with large data volumes in the full phase and using non-numeric primary keys, with high synchronization performance requirements. Exactly-once: Data is read strictly once, with some performance losses. Tables without a primary key and unique index column are not supported. Suitable for general scenarios where the source table has a numeric primary key or unique index column. The current version's two modes are state-incompatible. If the mode is changed after task submission, stateful restart is not supported. |
Advanced Settings (Optional) | You can configure parameters according to business needs. |
Single Table Writing Node Configuration
1. In the DataInLong page, click Real-time synchronization on the left directory bar.
2. In the real-time synchronization page, select Single Table Synchronization at the top to create a new one (you can choose either form or canvas mode) and enter the configuration page.
|
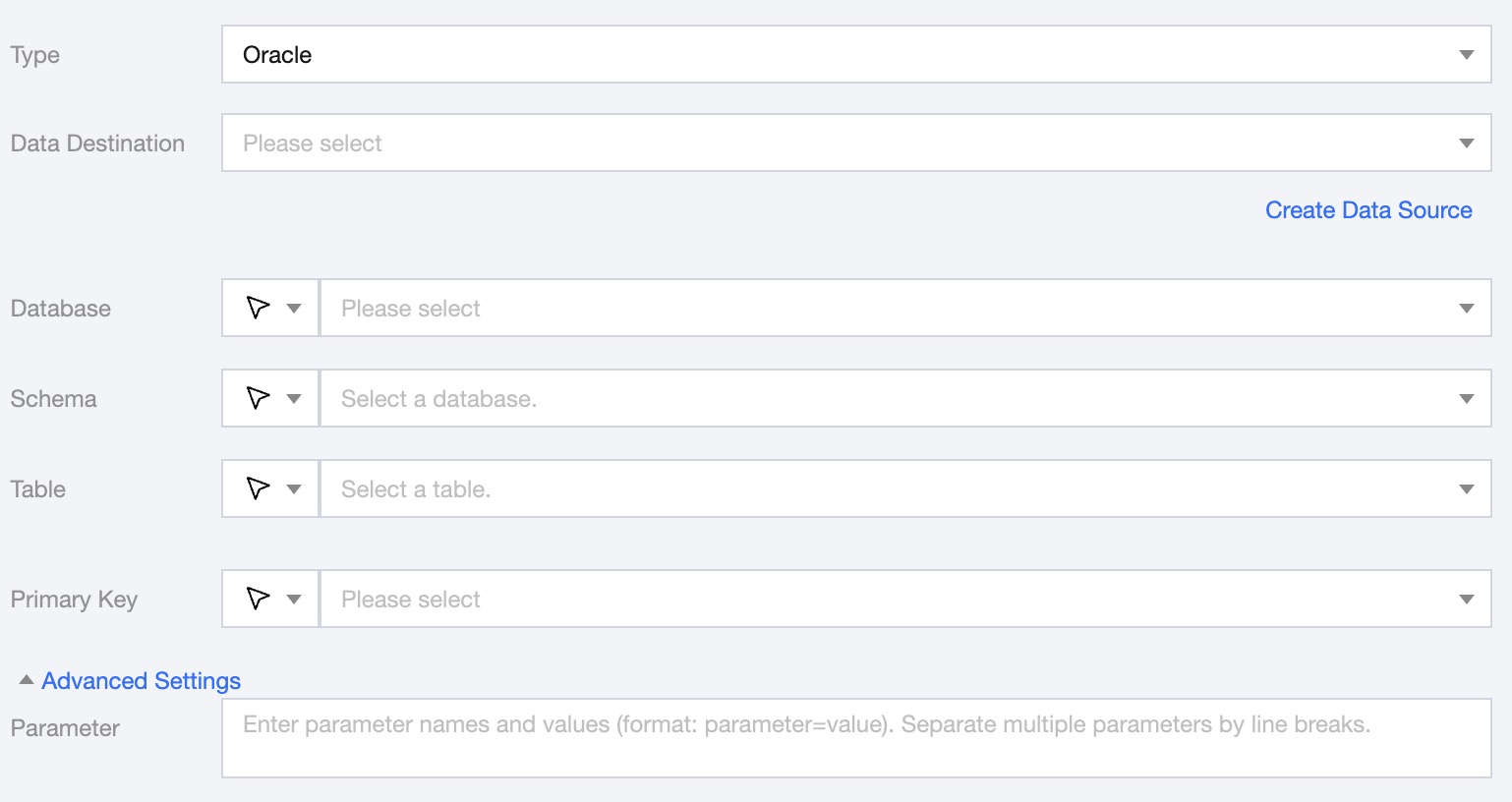
Data Source | The Oracle data source to be written to. |
Database | Supports selection or manual input of the database name to write to By default, the database bound to the data source is used as the default database. Other databases need to be manually entered. If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected. |
Schema | Supports selecting or manually entering the Oracle data mode to be written to. |
Table | Support selection or manual entry of the table name to be written to. If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the Data Integration network is connected. |
Primary key | Select a field as the primary key for the target table. |
Advanced Settings (Optional) | You can configure parameters according to business needs. |
Log collection write node
|
Data Source | Select the available Oracle data source in the current project. |
Database/Table | Select the corresponding database table from this data source. |
Primary key | Select a field as the primary key for the data table. |
Advanced Settings (optional) | You can configure parameters according to business needs. |
Data type conversion support
Read
The supported data types for reading from Oracle and their conversion relationships are as follows (when processing Oracle, the data types from the Oracle data source will first be mapped to the data types of the data processing engine):
|
NUMBER(p, s <= 0), p - s < 3 | TINYINT |
NUMBER(p, s <= 0), p - s < 5 | SMALLINT |
NUMBER(p, s <= 0), p - s < 10 | INT |
NUMBER(p, s <= 0), p - s < 19 | BIGINT |
NUMBER(p, s <= 0), 19 <= p - s <= 38 | DECIMAL(p - s, 0) |
NUMBER(p, s > 0) | DECIMAL(p, s) |
NUMBER(p, s <= 0), p - s > 38 | STRING |
FLOAT,BINARY_FLOAT | FLOAT |
DOUBLE PRECISION,BINARY_DOUBLE | DOUBLE |
NUMBER(1) | BOOLEAN |
DATE,TIMESTAMP [(p)] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] |
TIMESTAMP [(p)] WITH TIME ZONE | TIMESTAMP [(p)] WITH TIME ZONE |
TIMESTAMP [(p)] WITH LOCAL TIME ZONE | TIMESTAMP_LTZ [(p)] |
CHAR(n), NCHAR(n), NVARCHAR2(n), VARCHAR(n), VARCHAR2(n), CLOB, NCLOB, XML types | STRING |
BLOB,ROWID | BYTES |
INTERVAL DAY TO SECOND,INTERVAL YEAR TO MONTH | BIGINT |
Write
The supported data types for writing to Oracle and their conversion relationships are as follows:
|
FLOAT | BINARY_FLOAT |
DOUBLE | BINARY_DOUBLE |
DECIMAL(p, s) | SMALLINT,FLOAT(s),DOUBLE PRECISION,REAL,NUMBER(p, s) |
DATE | DATE |
DECIMAL(20, 0) | - |
FLOAT | REAL,FLOAT4 |
DOUBLE | FLOAT8,DOUBLE PRECISION |
DECIMAL(p, s) | NUMERIC(p, s),DECIMAL(p, s) |
BOOLEAN | BOOLEAN |
DATE | DATE |
TIMESTAMP [(p)][WITHOUT TIMEZONE] | TIMESTAMP [(p)]WITHOUT TIMEZONE |
STRING | CHAR(n),VARCHAR(n),CLOB(n) |
BYTES | RAW(s),BLOB |
ARRAY | - |